召回和排序模型中的用户行为序列的建模
Posted zhiyong_will
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了召回和排序模型中的用户行为序列的建模相关的知识,希望对你有一定的参考价值。
1. 概述
用户在使用一个APP或者浏览网页的过程中,都是由一些行为构成的,以资讯类为例,通常对一个帖子感兴趣,对于感兴趣的帖子,通常会点击进入查看,或者点击收藏或者对其进行评论,这一系列行为的背后都体现了用户的兴趣,而对用户行为过的帖子的序列的挖掘,能够对用户兴趣的表征。
为了兼顾速度和效果,在推荐系统中通常包含多个模块,如召回和排序模块,更具体点可以将推荐系统分为四个环节,分别为:召回,粗排,精排和重排,这四个环节之间的关系可见下图所示[1]:

召回模块通过对用户兴趣建模,在内容库中找到与用户兴趣相匹配的资讯内容;排序模块通过对用户兴趣建模,根据用户的兴趣,将召回模块返回的资讯根据用户兴趣打分,以判断当前的资讯内容与用户兴趣的匹配程度(得分)。
在深度网络中,对于用户行为过的资讯内容的序列的建模,可以用一个函数 f ( x ) f\\left ( x \\right ) f(x)表示,函数的输入是用户行为过的资讯内容的序列,可以是资讯的ID,也可以融入一些Side Information,如标题,tag,图片等,函数的输出是一个表征(通常用Embedding表示)。
2. 常用的建模方法
对于函数 f ( x ) f\\left ( x \\right ) f(x)通常有如下的一些方法。
2.1. 基于Pooling方法的用户兴趣挖掘
Pooling方法是最简单的一种方法,常用的Pooling方法如mean pooling,sum pooling等,即通过对用户行为过的资讯内容embedding后,将序列中所有的embedding进行Pooling操作。在召回模型DeepMatch[2]中使用的就是Mean Pooling,其模型结构如下图所示:
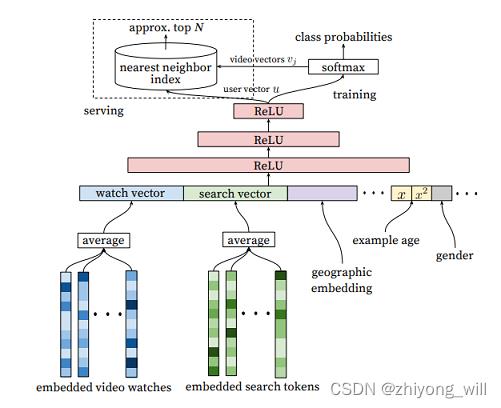
通过Mean Pooling后,用户的兴趣表征 v U \\boldsymbolv_U vU可以表示为:
v U = f ( e 1 , e 2 , ⋯ , e H ) = 1 H ∑ i = 1 H e i \\boldsymbolv_U=f\\left (\\boldsymbole_1,\\boldsymbole_2,\\cdots ,\\boldsymbole_H \\right )=\\frac1H\\sum_i=1^H\\boldsymbole_i vU=f(e1,e2,⋯,eH)=H1i=1∑Hei
其中 e i \\boldsymbole_i ei为行为序列中第 i i i个item。对于排序模型,在[3]中的提及到的Base模型中使用的是Sum Pooling,其模型结构如下图所示:
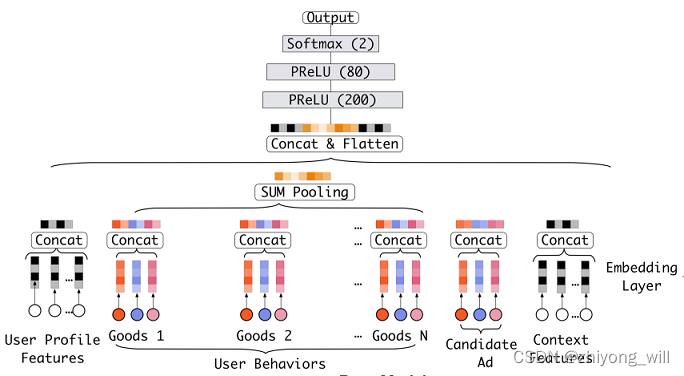
通过Sum Pooling后,用户的兴趣表征 v U \\boldsymbolv_U vU可以表示为:
v U ( A ) = f ( e 1 , e 2 , ⋯ , e H ) = ∑ i = 1 H e i \\boldsymbolv_U\\left ( A \\right )=f\\left (\\boldsymbole_1,\\boldsymbole_2,\\cdots ,\\boldsymbole_H \\right )=\\sum_i=1^H\\boldsymbole_i vU(A)=f(e1,e2,⋯,eH)=i=1∑Hei
2.2. 与当前候选相关的用户兴趣挖掘
上述的Pooling方法是对用户行为序列最简单的操作方式,针对不同的候选时,挖掘出的用户兴趣是不变的,并不能根据不同的候选计算出当前用户的兴趣,在参考[3]中提出DIN模型用于排序过程,根据不同的候选,利用Attention的计算机制计算用户兴趣,其模型结构如下图所示:

在加入Attention后,用户的兴趣表征 v U \\boldsymbolv_U vU不再是不变的Embedding,而是根据候选 v A \\boldsymbolv_A vA变化的,最周用户的兴趣表征 v U ( A ) \\boldsymbolv_U\\left ( A \\right ) vU(A)可以表示为:
v U ( A ) = f ( v A , e 1 , e 2 , ⋯ , e H ) = ∑ j = 1 H a ( e j , v A ) e j = ∑ j = 1 H w j e j \\boldsymbolv_U\\left ( A \\right )=f\\left ( \\boldsymbolv_A,\\boldsymbole_1,\\boldsymbole_2,\\cdots ,\\boldsymbole_H \\right )=\\sum_j=1^Ha\\left ( \\boldsymbole_j,\\boldsymbolv_A \\right )\\boldsymbole_j=\\sum_j=1^H\\boldsymbolw_j\\boldsymbole_j vU(A)=f(vA,e1,e2,⋯,eH)=j=1∑Ha(ej,vA)ej=j=1∑Hwjej
2.3. 基于时序建模的用户兴趣挖掘
在对用户行为序列提取用户兴趣的过程中,上述的方法中都忽视了一点,即在用户行为序列中,是有时间顺序的。这一点对应到用户的兴趣上来说,可以理解为用户的兴趣随着时间也是在不断变化的。对于序列数据的挖掘,在NLP中有很多的方法,如CNN,RNN,LSTM,GRU到目前使用较多的Transformer,在参考[4]中提出GRU4Rec模型用于排序过程,在GRU4Rec中,使用GRU对行为序列建模,其模型结构如下图所示:

其中,输入是用户的行为序列和候选的组合: e 1 , e 2 , ⋯ , e H , v A \\left \\ \\boldsymbole_1,\\boldsymbole_2,\\cdots ,\\boldsymbole_H,\\boldsymbolv_A \\right \\ e1,e2,⋯,eH,vA,其中 e 1 , e 2 , ⋯ , e H \\left \\ \\boldsymbole_1,\\boldsymbole_2,\\cdots ,\\boldsymbole_H \\right \\ e1,e2,⋯,eH是用户的历史行为序列, v A \\boldsymbolv_A vA是候选;输出是分数,可以理解为CTR。
基于Transformer的模型在多个NLP任务中得到了提升,能够很好的挖掘序列数据,在参考[5]中提出了BST模型用于排序过程,在BST模型中,使用Transformer中的Encoding部分对用户行为序列挖掘,其模型结构如下图所示:

与参考[4]中不同的是在对行为序列的模型上,在参考[4]中使用的是GRU,在参考[5]中使用的是Transformer中的Encoding部分。在参考[6]中提出DIEN模型用于排序过程,在DIEN模型中,将序列的挖掘和候选的Attention相结合,得到用户随时间演化的兴趣表征,同时这个表征还是与当前的候选是相关的,其模型结构如下图所示:
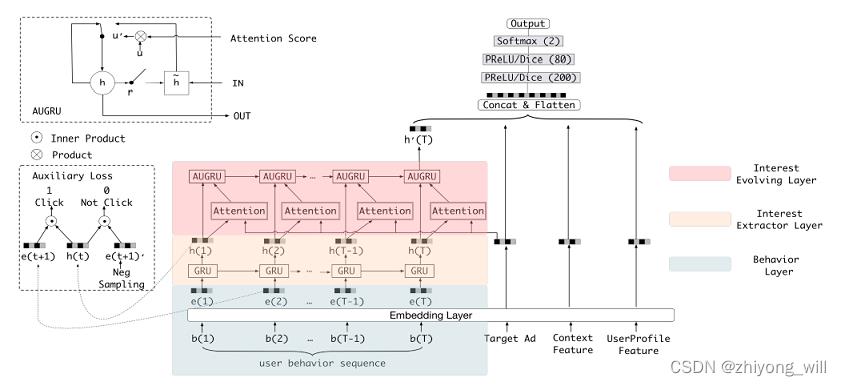
在DIEN中,对于用户兴趣的挖掘包括两个方面,一方面是兴趣提取层,另一个方面是兴趣演化层。在兴趣提取层中主要是使用GRU算法对用户行为序列数据挖掘,在兴趣演化层中,参考[6]中提出了三种方式,分别为:
- GRU with attentional input (AIGRU)
- Attention based GRU(AGRU)
- GRU with attentional update gate (AUGRU)
这三种方式都是在尝试不同的方式充分使用Attention的得分。
2.4. 用户多兴趣挖掘
DIN模型虽然能够根据当前的候选,通过用户历史行为数据挖掘到用户当前的兴趣,但是还是以单个embedding的形式表达用户兴趣,通常不足以捕获用户不同阶段、不同性质的兴趣分布。在现实中,用户的兴趣也不是单一的,在同一时刻也是会有多种兴趣并存的。参考[7]中提出MIND模型用于召回过程,在MIND中,Multi-Interest Extractor Layer对用户历史行为序列挖掘,提取出多个用户兴趣表征,这其中最终要的是称为Dynamic Routing的方法,该方法可以从用户行为和用户属性信息中动态学习出多个表示用户兴趣的向量,这是一种基于胶囊路径机制的多兴趣提取层,对历史行为聚类,从而提取到不同的兴趣。MIND模型结构如下图所示:

3. 总结
用户历史行为数据对用户兴趣的挖掘至关重要,无论是召回阶段,还是排序阶段,都需要使用到这部分的数据,随着深度学习的发展,对行为数据的挖掘也在不断深入,从最初的简单的Pooling操作,到序列挖掘,到Attention的计算,到多兴趣的挖掘,对这部分数据的挖掘也会进一步提升模型的效果。
参考文献
[1] Wang Z, Zhao L, Jiang B, et al. Cold: Towards the next generation of pre-ranking system[J]. arXiv preprint arXiv:2007.16122, 2020.
[2] Covington P, Adams J, Sargin E. Deep neural networks for youtube recommendations[C]//Proceedings of the 10th ACM conference on recommender systems. 2016: 191-198.
[3] Zhou G, Zhu X, Song C, et al. Deep interest network for click-through rate prediction[C]//Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 2018: 1059-1068.
[4] Hidasi B, Karatzoglou A, Baltrunas L, et al. Session-based recommendations with recurrent neural networks[J]. arXiv preprint arXiv:1511.06939, 2015.
[5] Chen Q, Zhao H, Li W, et al. Behavior sequence transformer for e-commerce recommendation in alibaba[C]//Proceedings of the 1st International Workshop on Deep Learning Practice for High-Dimensional Sparse Data. 2019: 1-4.
[6] Zhou G, Mou N, Fan Y, et al. Deep interest evolution network for click-through rate prediction[C]//Proceedings of the AAAI conference on artificial intelligence. 2019, 33(01): 5941-5948.
[7] Li C, Liu Z, Wu M, et al. Multi-interest network with dynamic routing for recommendation at Tmall[C]//Proceedings of the 28th ACM International Conference on Information and Knowledge Management. 2019: 2615-2623.
以上是关于召回和排序模型中的用户行为序列的建模的主要内容,如果未能解决你的问题,请参考以下文章