原来Python爬虫还可以这么玩!python爬虫自动化实现B站自动登录
Posted 夜斗小神社
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了原来Python爬虫还可以这么玩!python爬虫自动化实现B站自动登录相关的知识,希望对你有一定的参考价值。
从新开始吧,而不是重新开始

哈喽,大家好呐,很久不见,甚是想念!
小夜斗又和大家见面啦,距离小夜斗上次更新爬虫文章又过去了很久辽!
因为在学校的时候有太多事情要做了,就疏忽了博客的更新呐,感觉以后还是要日常更新,知识需要输入,更需要输出,这样子才能吸收其中的精华所在!
趁这次暑假期间给自己充能的同时,给大伙们分享一下自己的学习项目,一方面可以加强自己对知识的印象,另一方面可以给大伙们做一个参考,这就是双赢呐!
本期小夜斗给大家伙带来的是一篇破解B站滑块验证实现自动登录的项目,仅供学习参考使用呐,切不可做违法乱纪的事情!
获取图片模块参考了这位大佬CoreJT的博客(感兴趣的小伙伴可以去阅读原作呐,Python爬虫实战 | (15) 破解bilibili登陆滑动验证码):

想要获取这个项目源码的小伙伴们文末自行获取呐!
一:破解滑块验证码项目所使用的库
from PIL import Image
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC, wait
from selenium.webdriver.common.by import By
import time
from selenium.webdriver.common.action_chains import ActionChains # 引入Action
import base64
- from PIL import Image :对图像的基本处理
- from selenium import webdriver:实例化浏览器对象实现自动化
- from selenium.webdriver.support.wait import WebDriverWait :等待
- from selenium.webdriver.support import expected_conditions as EC:等待条件
- from selenium.webdriver.common.by import By:定位方式
- import time:睡眠时间
- from selenium.webdriver.common.action_chains import ActionChains:动作链,拖动滑块
- import base64:处理图片,编码
二:初始化参数
class BliBli():
def __init__(self, url, username, password):
"""
:param url: 登录网址
:param username: 账号
:param password: 密码
"""
self.url = url
self.username = username
self.password = password
上述代码中声明了一个BliBli类对象,初始化参数需要传入登录网址url,以及你的账号和密码,B站登录入口网址如下所示:
https://passport.bilibili.com/loginfrom_spm_id=333.851.top_bar.login_window
三:登录接口
def login(self):
"""
模拟浏览器
自动化插件配置,登录接口
:return:
"""
# 浏览器对象
path = r'L:\\python package\\jupyter learn record\\Spider chong\\chromedriver.exe'
browser = webdriver.Chrome(path)
# 登录
browser.get(self.url)
# 窗口最大化
browser.maximize_window()
# 账号密码接口
wait = WebDriverWait(browser, 10)
username = wait.until(EC.presence_of_element_located((By.ID, 'login-username')))
password = wait.until(EC.presence_of_element_located((By.ID, 'login-passwd')))
# 输入账号密码
username.send_keys(self.username)
password.send_keys(self.password)
# 点击登录按钮
# TODO: 登录没反应
login_press = wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="geetest-wrap"]/div/div[5]/a[1]')))
print("正在点击登录按钮")
login_press.click()
print("登录按钮点击完毕")
# 停顿
time.sleep(1000)
这个login函数是登录接口一部分代码,因为还有一部分牵扯到另一些函数接口,就没有全部弄上来了,下文会给大家伙展示!
首先我们实例化了一个浏览器对象browser,用它模拟人来实现自动登录,首先输入账号,然后密码,点击登录!




在输入账号密码点击登录后,会弹出来一个滑动验证码,这时你需要通过移动相应的图形到对应的缺口,如下图所示:
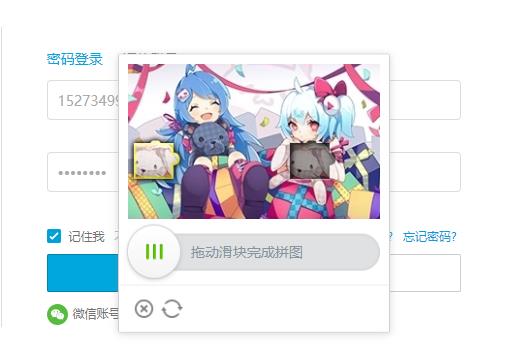
四:破解滑动验证核心模块
小夜斗个人感觉这个滑动验证模块其实没有那么难,我们所需要做的事情无非就是计算这个滑块到那个缺口所需要移动的距离,然后用浏览器模拟人去拖动就行了,然后最关键的地方,拖动到最后我们人为都是会停留一段时间的,想象一下你自己拖动模块时的感受,是不是很快的拖动过去,然后在停留1s到2s左右,最后都是能验证成功的!
那如何计算我们滑块所需要移动的距离呢?
我们先来看下面三张滑块验证图片,如下图所示:
第一张:即包含缺口又包含移动滑块

第二张:只包含缺口

第三张:一副完整的验证图片

很简单的思路:我只需要将第二张和第三张图片像素点进行对比,设置一个误差范围阙值,这样子是不是就可以知道缺口的大致位置
而且我们拖动滑动是左右拖动,因此我们只需要获取其x轴方向的位置即可
(一):首先我们来获取上述的三张图片
def get_screen_image(self, wait, browser):
# 带阴影的图片
im = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.geetest_canvas_bg')))
time.sleep(2)
im.screenshot('./image1.png')
# 执行JS代码并拿到base64数据
# 不带阴影的完整图片
JS = 'return document.getElementsByClassName("geetest_canvas_fullbg")[0].toDataURL("image/png");'
# 获取图片信息
im_info = browser.execute_script(JS)
print(im_info)
# 拿到base64编码的图片信息
im_base64 = im_info.split(',')[1]
print(im_base64)
# 转为bytes类型
captcha_1 = base64.b64decode(im_base64)
# 保存图片
with open('captcha_1.png', 'wb') as f:
f.write(captcha_1)
# 执行JS代码并拿到图片base64数据
# 带阴影的图
c_js = 'return document.getElementsByClassName("geetest_canvas_bg")[0].toDataURL("image/png");'
im_info_1 = browser.execute_script(c_js)
print(im_info_1)
# 拿到base64编码的图片信息
im_base64_1 = im_info_1.split(',')[1]
# 转为bytes类型
captcha_2 = base64.b64decode(im_base64_1)
# 将图片保存在本地
with open('captcha_2.png', 'wb') as f:
f.write(captcha_2)
captcha1 = Image.open('./captcha_1.png')
captcha2 = Image.open('./captcha_2.png')
return captcha1, captcha2
当滑块验证码弹出来,按f12检查元素,可以分别看到属性:


然后执行相应的JS代码拿到对应的图片,进行切割编码,将图片进行保存,用于后续的像素对比操作!
小夜斗在看滑块标签属性的时候发现:display属性后面的block改为none滑块为消失,另一个标签的none改为block缺口为消失,还有一个none改为block滑块和缺口都消失


(二):像素对比,寻找缺口位置
def position(self, image1, image2):
# 缺口离左侧的位置
left = 60
# x轴方向
for i in range(left, image1.size[0]):
# y轴方向
for j in range(image1.size[1]):
if not self.pixel_euqal(image1, image2, i, j):
left = i # 找到缺口左边边界在x轴方向上的位置
return left
return left
函数position功能是寻找缺口的x轴位置,传入参数image1与image2分别为不带缺口的图片和只带缺口的图片,为上述的第二张图和第三张图
我们定义了一个参数left,即缺口离最左侧的距离(人为的初始化一个距离,一定为60或者0都是可以的),x轴方向像素变量,y轴方向像素遍历,然后我们调用pixel_euqal函数来比对两张图片image1与image2,从而找到缺口对应的x轴位置赋值给left,最终返回left即滑块所需移动的x轴位置
def pixel_euqal(self, image1, image2, x, y):
# 获取两张图片像素点
pixel1 = image1.load()[x, y]
pixel2 = image2.load()[x, y]
# 设置一个误差阙值
threshold = 60
# 每个位置的像素点有三个通道
if (abs(pixel1[0] - pixel2[0]) < threshold and abs(pixel1[1] - pixel2[1]) < threshold and
abs(pixel1[2] - pixel2[2]) < threshold):
return True
else:
return False
(三)拖动滑块,完成自动登录
def drag(self, browser, wait, gap):
"""
拖动滑块方法
:return:
"""
# 定位圆形滑块的位置
circle = wait.until(EC.presence_of_element_located((By.XPATH,'/html/body/div[2]/div[2]/div[6]/div/div[1]/div[2]/div[2]')))
print(circle)
# 拖到某个位置后松开
# TODO:方法需要perform执行
print("开始拖动滑块")
ActionChains(browser).click_and_hold(circle).perform()
# for i in track:
# ActionChains(browser).move_by_offset(i, 0).perform()
ActionChains(browser).move_by_offset(gap, 0).perform()
time.sleep(1)
print("滑块移动结束")
ActionChains(browser).release().perform()
定义了一个drag拖拉的方法,首先找到对应的原型滑块位置circle,然后用动作链去移动circle对象,我们移动的时候并不需要先加速后减速,直接移动过去即可,因为网站后台检测的是你最后的停留时间,如果你按照先快后慢那种移动,成功率还没有直接移过去然后停留一秒来的快
想象一下我们人是怎么移的,直接移过去,然后停留一下,同样的道理放在浏览器对象也是一样的
哦对了,缺口移动的位置left,还需要根据你自己的调整减去一个参数,这里小夜斗调整的参数为10,即滑块自己本身的大小,根据移动的需求人工微调即可,下面为login函数后半部分代码
# TODO: 获取两张验证码图片
captcha1, captcha2 = self.get_screen_image(wait, browser)
# TODO: 缺口位置如何寻找?
left = self.position(captcha1,captcha2)
left = left - 10
print(left)
# TODO: 如何拖动滑块?
self.drag(browser, wait, left)
# 停顿
time.sleep(1000)
本期博客就到此啦,感兴趣的小伙伴们不烦点赞收藏一波!
源码数据:关注微信公众号"夜斗小神社"后台回复"008滑块验证"
- 在这个星球上,你很重要,请珍惜你的珍贵! ~~~夜斗小神社

以上是关于原来Python爬虫还可以这么玩!python爬虫自动化实现B站自动登录的主要内容,如果未能解决你的问题,请参考以下文章