python处理Excel表格--读取Excel表格
Posted 胜天半月子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python处理Excel表格--读取Excel表格相关的知识,希望对你有一定的参考价值。
文章目录
前言
- python处理Excel的方式
openpyxl
若报错的话,可以下载下面的第三方库
- pip install lxml
- pip install pillow
了解Excel的一些定义:
- 工作簿:一个Excel电子表格文档称为一个工作簿,一个工作簿保存在扩展名为.xisx的文件中
- sheet表:每个工作簿可以包含多个表也称为工作表)
- 活动表:用户当前查看的表(或关闭Excel前最后查看的表),称为活动表(当前操作的sheet表就是活动表)
- 单元格:每个表都有一些列(地址是从A开始的字母)和一些行(
地址是从1开始的数字),在特定行和列的方格称为单元格。每个单元格都包含一个数字或文本值。
本节所有代码均在jupyter notebook中运行使用
一、读取Excel表格
- 用openpyxl模块打开Execl文档
import openpyxl
# 创建一个workbook工作簿对象
wb = openpyxl.load_workbook('./test.xlsx')
wb
<openpyxl.workbook.workbook.Workbook at 0x2246a803208>
- 获取工作簿sheet表的名称
wb.sheetnames
[‘Sheet1’, ‘Sheet2’]
- 获取指定的sheet对象
sheet = wb['Sheet1']
sheet # 最新版本才可以使用 老版本是无法使用的
<Worksheet “Sheet1”>
- 获取活动表【即退出.xlsx文件时最后显示的是哪个Sheet】
wb.active

由于退出xlsx文件时,已经生成了wb对象因此,即时重新进入xlsx文件,选择不同的 sheet表,最后显示的还是第一次运行代码wb.active时显示的表,除非从头到尾重新运行代码
- 从表中取得单元格
有了Worksheet对象后,就可以按名字访问Cell对象
属性:
- value:cell储的值
- row:行索引
- column:列索引
- coordinate:坐标
- 两种访问cell单元格的方式
# 创建单元格对象
cell = sheet['A4'] # 列A行4
cell.value # 'bobo2'
cell.row # 4
cell.column # 1
cell.coordinate # A4
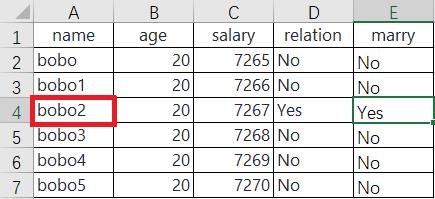

sheet.cell(row=3,column=4).value # 3行4列
‘No’
从工作表中取具体的行和列
- 可以将Worksheet对象进行切片操作,从而取得电子表格中一行、一列或一个矩形区域中的所有Cell对象。
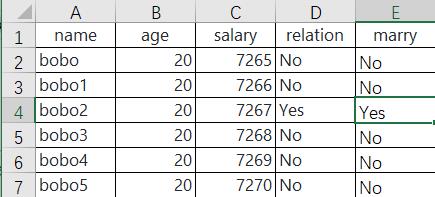
for cell_row in sheet['A2':'E2']:
for cell in cell_row:
print(cell.coordinate,cell.value)
A2 bobo
B2 20
C2 7265
D2 No
E2 No
sheet['A2':'E2'] # 返回元组
((<Cell ‘Sheet1’.A2>,
<Cell ‘Sheet1’.B2>,
<Cell ‘Sheet1’.C2>,
<Cell ‘Sheet1’.D2>,
<Cell ‘Sheet1’.E2>),)
for cell_row in sheet['A2':'E6']:
for cell in cell_row:
print(cell.coordinate,cell.value)
A2 bobo
B2 20
C2 7265
D2 No
E2 No
A3 bobo1
B3 20
C3 7266
D3 No
E3 No
A4 bobo2
B4 20
C4 7267
D4 Yes
E4 Yes
A5 bobo3
B5 20
C5 7268
D5 No
E5 No
A6 bobo4
B6 20
C6 7269
D6 No
E6 No
sheet['A2':'E6']
((<Cell ‘Sheet1’.A2>,
<Cell ‘Sheet1’.B2>,
<Cell ‘Sheet1’.C2>,
<Cell ‘Sheet1’.D2>,
<Cell ‘Sheet1’.E2>),
(<Cell ‘Sheet1’.A3>,
<Cell ‘Sheet1’.B3>,
<Cell ‘Sheet1’.C3>,
<Cell ‘Sheet1’.D3>,
<Cell ‘Sheet1’.E3>),
(<Cell ‘Sheet1’.A4>,
<Cell ‘Sheet1’.B4>,
<Cell ‘Sheet1’.C4>,
<Cell ‘Sheet1’.D4>,
<Cell ‘Sheet1’.E4>),
(<Cell ‘Sheet1’.A5>,
<Cell ‘Sheet1’.B5>,
<Cell ‘Sheet1’.C5>,
<Cell ‘Sheet1’.D5>,
<Cell ‘Sheet1’.E5>),
(<Cell ‘Sheet1’.A6>,
<Cell ‘Sheet1’.B6>,
<Cell ‘Sheet1’.C6>,
<Cell ‘Sheet1’.D6>,
<Cell ‘Sheet1’.E6>))
要访问特定行或列的单元格的值,也可以利用Worksheet对象的rows和columns属性。
sheet.columns # 返回的是一个生成器
<generator object Worksheet._cells_by_col at 0x000002246A7C0318>
生成器是可以转换为一个列表的–>通过list
list(sheet.columns) # 获取所有的列 一列一组
[(<Cell ‘Sheet1’.A1>,
<Cell ‘Sheet1’.A2>,
<Cell ‘Sheet1’.A3>,
<Cell ‘Sheet1’.A4>,
<Cell ‘Sheet1’.A5>,
<Cell ‘Sheet1’.A6>,
<Cell ‘Sheet1’.A7>),
(<Cell ‘Sheet1’.B1>,
<Cell ‘Sheet1’.B2>,
<Cell ‘Sheet1’.B3>,
<Cell ‘Sheet1’.B4>,
<Cell ‘Sheet1’.B5>,
<Cell ‘Sheet1’.B6>,
<Cell ‘Sheet1’.B7>),
(<Cell ‘Sheet1’.C1>,
<Cell ‘Sheet1’.C2>,
<Cell ‘Sheet1’.C3>,
<Cell ‘Sheet1’.C4>,
<Cell ‘Sheet1’.C5>,
<Cell ‘Sheet1’.C6>,
<Cell ‘Sheet1’.C7>),
(<Cell ‘Sheet1’.D1>,
<Cell ‘Sheet1’.D2>,
<Cell ‘Sheet1’.D3>,
<Cell ‘Sheet1’.D4>,
<Cell ‘Sheet1’.D5>,
<Cell ‘Sheet1’.D6>,
<Cell ‘Sheet1’.D7>),
(<Cell ‘Sheet1’.E1>,
<Cell ‘Sheet1’.E2>,
<Cell ‘Sheet1’.E3>,
<Cell ‘Sheet1’.E4>,
<Cell ‘Sheet1’.E5>,
<Cell ‘Sheet1’.E6>,
<Cell ‘Sheet1’.E7>)]
list(sheet.rows) # 获取所有的行 一行一组
[(<Cell ‘Sheet1’.A1>,
<Cell ‘Sheet1’.B1>,
<Cell ‘Sheet1’.C1>,
<Cell ‘Sheet1’.D1>,
<Cell ‘Sheet1’.E1>),
(<Cell ‘Sheet1’.A2>,
<Cell ‘Sheet1’.B2>,
<Cell ‘Sheet1’.C2>,
<Cell ‘Sheet1’.D2>,
<Cell ‘Sheet1’.E2>),
(<Cell ‘Sheet1’.A3>,
<Cell ‘Sheet1’.B3>,
<Cell ‘Sheet1’.C3>,
<Cell ‘Sheet1’.D3>,
<Cell ‘Sheet1’.E3>),
(<Cell ‘Sheet1’.A4>,
<Cell ‘Sheet1’.B4>,
<Cell ‘Sheet1’.C4>,
<Cell ‘Sheet1’.D4>,
<Cell ‘Sheet1’.E4>),
(<Cell ‘Sheet1’.A5>,
<Cell ‘Sheet1’.B5>,
<Cell ‘Sheet1’.C5>,
<Cell ‘Sheet1’.D5>,
<Cell ‘Sheet1’.E5>),
(<Cell ‘Sheet1’.A6>,
<Cell ‘Sheet1’.B6>,
<Cell ‘Sheet1’.C6>,
<Cell ‘Sheet1’.D6>,
<Cell ‘Sheet1’.E6>),
(<Cell ‘Sheet1’.A7>,
<Cell ‘Sheet1’.B7>,
<Cell ‘Sheet1’.C7>,
<Cell ‘Sheet1’.D7>,
<Cell ‘Sheet1’.E7>)]
# 获取第一列的所有内容
for cell in list(sheet.columns)[0]:
print(cell.value)
name
bobo
bobo1
bobo2
bobo3
bobo4
bobo5
# 获取第二行的所有内容
for cell in list(sheet.rows)[1]:
print(cell.value)
bobo
20
7265
No
No
- 获取工作表中的最大行和最大列的数量
- max_row
- max_column
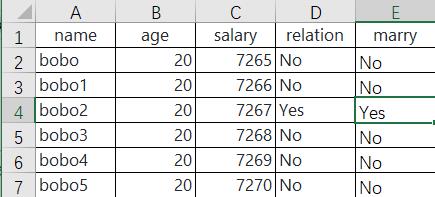
sheet.max_row
7
sheet.max_column
5
二、项目:2010年美国人口普查数据自动化处理
2.1 做什么、如何做?
- 获取数据
censuspopdata.xlsx 提取码:q7gt
在这个项目中,你要编写一个脚本,从人口普查电子表备文件中读取数据,并在几秒钟内计算出每个县的统计值(可以根据县的名称快速计算出县的总人口和普查区的数量)
下面是程序要做的事:
- 从Excel电子表格中读取数据。
- 计算每个县中普查区的数目
- 计算每个县的总人口。打印结果。
这意味着代码需要完成下列任务:- 用openpyxl模块打开Excel文档并读取单元格。
- 计算所有普查区和人口数据,将它保存到一个数据结构中
- 利用
pprint模块,将该数据结构写入一个扩展名为.py的文本文件。
- 数据说明
censuspopdata.xlsx电子表格中只有一张表,名为’Population by Census Tract’
每一行都保存了一个普查区的数据。
列分别是普查区的编号(A),州的简称(B),县的名称(C),普查区的人口(D)。
- 注意:一个县会设定多个普查区,D列表示县中所有普查区对应每一个普查区的人口数量。
2.2 print()与pprint()
print()和pprint()都是python的打印模块,功能基本一样,唯一的区别就是pprint()模块打印出来的数据结构更加完整,每行为一个数据结构,更加方便阅读打印输出结果。特别是对于特别长的数据打印,print()输出结果都在一行,不方便查看,而pprint()采用分行打印输出,所以对于数据结构比较复杂、数据长度较长的数据,适合采用pprint()打印方式。当然,一般情况多数采用print().
python美化打印的标准库
2.3 完整源码及分析
import openpyxl,pprint
print('Opening workbook...')
wb = openpyxl.load_workbook('./censuspopdata.xlsx')
# sheet = wb.get_sheet_by_name('Population by Census Tract') # 老版本方法
sheet = wb.['Population by Census Tract'] # 新版本 建议使用
#countyData countyData将包含你计算的每个县的总人口和普查区数目。但在它里面存储任何东西之前,你应该确定它内部的数据结构
countyData =
# TODO: Fill in countyData with each county's population and tracts.
print('Reading rows...')
# 第2行才是真正的数据
for row in range(2, sheet.max_row + 1): # 从第2行开始计算 到最大行 由于右边是开区间所以加1
# Each row in the spreadsheet has data for one census tract.
state = sheet['B' + str(row)].value # 取出州的名称
county = sheet['C' + str(row)].value # 取出县的名称
pop = sheet['D' + str(row)].value # 取出人口的数量
# 创建州的字典
countyData.setdefault(state, ) # 即字典state:
# Make sure the key for this county in this state exists.
countyData[state].setdefault(county, 'tracts': 0,'pop': 0)# state:county:'tracts': 0, 'pop': 0
# Each row represents one census tract, so increment by one.
countyData[state][county]['tracts'] += 1
# Increase the county pop by the pop in this census tract.
countyData[state][county]['pop'] += int(pop)
print('Writing results...')
resultFile = open('census_2010.py', 'w')
#使用pprint.pformat()函数,将变量字典的值作为一个巨大的字符串,写入文件census2010.py
resultFile.write('allData = ' + pprint.pformat(countyData))
resultFile.close()
print('Done.')
- 字典值的获取
countyData = 'AK': 'Aleutians East': 'pop': 3141, 'tracts': 1,
'Aleutians West': 'pop': 5561, 'tracts': 2,
'Anchorage': 'pop': 291826, 'tracts': 55,
'Bethel': 'pop': 17013, 'tracts': 3,
'Bristol Bay': 'pop': 997, 'tracts': 1
# 字典countyData的使用
countyData['AK']['Anchorage']['pop']
291826
countyData['AK']['Anchorage']['tracts']
55
- setdefault()函数
state = 'AK'
county =
county.setdefault(state, )
county
‘AK’:
将countyData输出到文本文件census_2010.py,你就通过Python程序生成了一个Python程序这样做的好处是现在可以导入census_2010.py,就像任何其他Python模块一样
import os
import census_2010
# 查看AK州Anchorage县的人口普查数据
census_2010.allData['AK']['Anchorage']
‘pop’: 291826, ‘tracts’: 55
以上是关于python处理Excel表格--读取Excel表格的主要内容,如果未能解决你的问题,请参考以下文章