推荐系统中的MRR指标
Posted 甘木甘木
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统中的MRR指标相关的知识,希望对你有一定的参考价值。
MRR(Mean reciprocal rank)
MRR最早是在搜索场景下衡量,返回结果的质量。
其基于一个假设“每一个query Q只有一个与其相关(relevant)的结果A”
指标反应的是我们找到的这些item是否摆在用户更明显的位置,强调位置关系,顺序性。公式如下,N表示推荐次数,1/p表示用户真实访问的item在结果列表中的位置,如果没在结果序列中,则p为无穷大,1/p为0。
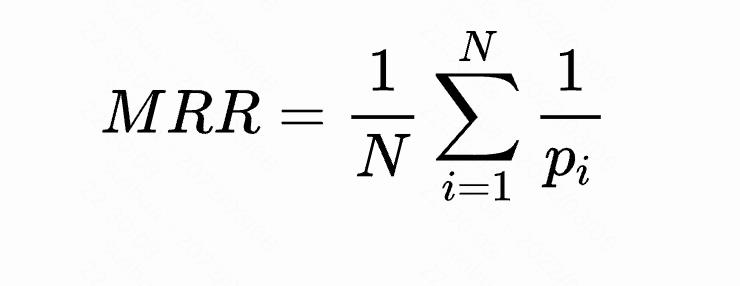
如上图,有N次搜索,p_i是第i次搜索的结果中最相关结果的位置,其倒数就是返回结果的质量。
python实现:
'''reference: https://gist.github.com/bwhite/3726239'''
def mean_reciprocal_rank(rs):
'''默认rs是根据相关度排好序的,从高到低'''
"""Score is reciprocal of the rank of the first relevant item
First element is 'rank 1'. Relevance is binary (nonzero is relevant).
Example from http://en.wikipedia.org/wiki/Mean_reciprocal_rank
>>> rs = [[0, 0, 1], [0, 1, 0], [1, 0, 0]]
>>> mean_reciprocal_rank(rs)
0.61111111111111105
>>> rs = np.array([[0, 0, 0], [0, 1, 0], [1, 0, 0]])
>>> mean_reciprocal_rank(rs)
0.5
>>> rs = [[0, 0, 0, 1], [1, 0, 0], [1, 0, 0]]
>>> mean_reciprocal_rank(rs)
0.75
Args:
rs: Iterator of relevance scores (list or numpy) in rank order
(first element is the first item)
Returns:
Mean reciprocal rank
"""
rs = (np.asarray(r).nonzero()[0] for r in rs)
return np.mean([1. / (r[0] + 1) if r.size else 0. for r in rs])
推荐场景与搜索的不一样
现在很多论文中将推荐结果看作一个ranking的结果,所以也用搜索中的排序指标来衡量推荐结果,比如MRR。
一个常见的场景:推荐系统给用户展示一个列表的物品(想象一个六宫格场景),其中可能有多个用户感兴趣的物品,用户可能点击了其中两个item。
搜索中认为与query 相关的文档只有一个,但是在推荐下用户点击过的都认为是有兴趣,所以这里有两个相关的物品,那么mrr如何计算?
对于每一个相关的item都计算一次,然后再取平均值。这是微软举办的MIND比赛中mrr的计算方法。
具体计算方式如下:
def mrr_score(y_true):
'''y_true是根据推荐模型预测的score从高到低排序后的结果,其中元素为1或0,代表是否点击'''
rr_score = y_true / (np.arange(len(y_true)) + 1)
return np.sum(rr_score) / np.sum(y_true)
以上是关于推荐系统中的MRR指标的主要内容,如果未能解决你的问题,请参考以下文章