常用编码格式整理
Posted Flytiger1220
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了常用编码格式整理相关的知识,希望对你有一定的参考价值。
什么是字符集,字符编码,编码和解码:
字符集:
将一些自然语言中的字符组成一个集合;
字符编码:
字符编码,就是建立一套自然语言中的“字符”跟计算机能够存储 处理的二进制数的映射的规则。
即在一个字符集内,用一个特定的二进制数表示一个唯一“字符”,类似于学号跟学生的映射关系。
为什么需要编码:
当数据不利于处理、存储的时候,就需要对它们进行编码。
对字符进行编码是因为自然语言中的字符不利于计算机处理和存储。
编码和解码:
根据实际需求的差异,编码、解码算法有可能会很复杂,也有可能非常的简单,
但是从根本上来讲,编码、解码只是在做翻译工作,将一种形式的数据翻译为另一种形式的数据,
如,最简单的编码、解码就是相当于从一个Map中根据key查找value,然后使用value代替实际数据中的key的值。
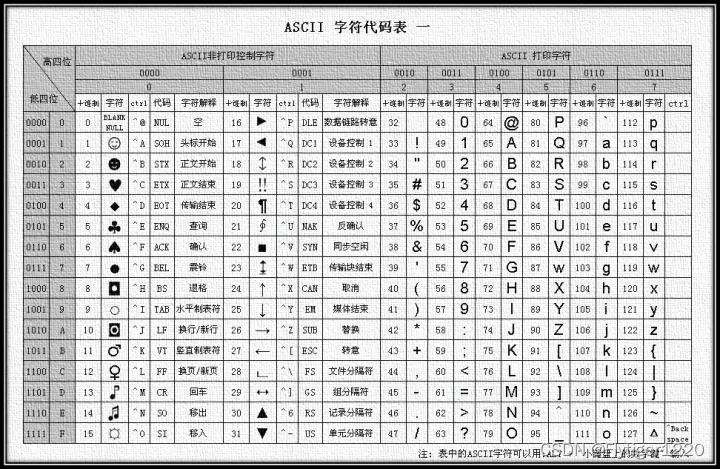
ASCII编码
ASCII 码一共定义了 128 个字符,例如大写的字母 A 是 65(这是十进制数,对应二进制是0100 0001)。这 128 个字符只使用了 8 位二进制数中的后面 7 位,最前面的一位统一规定为 0。
GBK编码
中国人为了能够正常使用计算机这一伟大方明,做出了多方面的努力。GB2312 就是这一努力的成果, 该标准于1980年发布,1981年5月1日开始实施。它标志着我国在使用电子计算机方面迈出了重要的一步。GB2312 编码共收录了6763个汉字,同时还兼容 ASCII。这一字符编码基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆 99.75% 的使用频率,然而对一些古汉语和繁体字 GB2312 没法处理。
1995 年发布的GBK 的编码,是对 GB2312 的补充和扩展。GBK 不仅收录了 GB2312 中的全部汉字、非汉字符号,同时还收录了日韩语中出现的汉字,如韩国著名围棋手李世乭中的乭 GBK 编码是 0x8168(0x表示16进制)。这里可以查询汉字对应的 GBK 编码。
GBK 编码一般用两个字节表示一个字符,如果是英文字母,则使用一个字符,与ASCII编码相同,因此,GBK 也是兼容 ASCII 编码的,但并不与任何扩展的ASCII编码兼容。这可以从它的编码序列看出来。
GBK 采用双字节表示,总体编码范围为 0x8140-0xFEFE(1000000101000000-1111111011111110),首字节在 0x81-0xFE 之间,尾字节在 0x40-0xFE之间。可以看出首字节最高位都为1,这样一来,如果一个连续的二进制串中,尾字节之后的字节最高位为0,那么就可以解析为一个ASCII编码字符,否则就是一个连续的二字节字符。
Unicode编码
Unicode编码是为了囊括所有语言中的字符制定的,它规定了每一个字符所对应的唯一的二进制代码,称之为码点(code point)。Unicode是一个很大的集合,目前的规模可以容纳100多万个符号。
这么多符号,Unicode不是一次性定义的,而是分区定义。每个区可以存放 65536个( 216 )字符,称为一个平面(plane)。目前,一共有17个平面。
最前面的65536个字符位,称为基本平面(缩写BMP),它的码点范围是从0一直到 216 -1,写成16进制就是从U+0000到U+FFFF。所有最常见的字符都放在这个平面,这是Unicode最先定义和公布的一个平面。
剩下的字符都放在辅助平面(缩写SMP),码点范围从U+010000一直到U+10FFFF。
每个符号的编码都不一样,这么多的字符,想要以二进制形式表示,就需要比较多的字节才能够一一对应。标准的 Unicode(也就是第一个平面,BMP)采用4个字节表示一个字符串。比如,U+0639 表示阿拉伯字母 Ain,U+0041 表示英语的大写字母 A,U+4E6D 表示汉字"乭 "。显然,Unicode 和 GBK 是不兼容的。
Unicode 没有规定字符对应的二进制码如何存储。以汉字“汉”为例,它的 Unicode 码点是u+0x6c49,对应的二进制数是 110110001001001,二进制数有 15 位,这也就说明了它至少需要 2 个字节来表示。可以想象,在 Unicode 字典中往后的字符可能就需要 3 个字节或者 4 个字节,甚至更多字节来表示了。
这就导致了一些问题,计算机怎么知道你这个 2 个字节表示的是一个字符,而不是分别表示两个字符呢?这里我们可能会想到,那就取个最大的,假如 Unicode 中最大的字符用 4 字节就可以表示了,那么我们就将所有的字符都用 4 个字节来表示,不够的就往前面补 0。这样确实可以解决编码问题,但是却造成了空间的极大浪费,如果是一个英文文档,那文件大小就大出了 3 倍,这显然是无法接受的。
于是,为了较好的解决 Unicode 的编码问题, UTF-8 和 UTF-16 两种当前比较流行的编码方式诞生了。当然还有一个 UTF-32 的编码方式,也就是上述那种定长编码,字符统一使用 4 个字节,虽然看似方便,但是却不如另外两种编码方式使用广泛。
UTF-8
UTF-8 是 Unicode 的一种实现方式,它规定了使用 Unicode 编码的字符如何存储和传输。UTF-8 是目前互联网上使用最广泛的一种 Unicode 编码方式,它的最大特点就是可变长。它可以使用 1 - 4 个字节表示一个字符,根据字符的不同变换长度。编码规则如下:
1、对于单个字节的字符,第一位设为 0,后面的7位对应这个字符的 Unicode 码点。因此,对于英文中的 0 - 127 号字符,与 ASCII 码完全相同。这意味着 ASCII 码那个年代的文档用 UTF-8 编码打开完全没有问题。
2、对于需要使用 N 个字节来表示的字符(N > 1),第一个字节的前 N 位都设为 1,第 N + 1 位设为0,剩余的 N - 1 个字节的前两位都设位 10,剩下的二进制位则使用这个字符的 Unicode 码点来填充。
编码规则如下:
Unicode 十六进制码点范围 UTF-8 二进制
0000 0000 - 0000 007F 0xxxxxxx
0000 0080 - 0000 07FF 110xxxxx 10xxxxxx
0000 0800 - 0000 FFFF 1110xxxx 10xxxxxx 10xxxxxx
0001 0000 - 0010 FFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
根据上面编码规则对照表,进行 UTF-8 编码和解码就简单多了。下面以汉字“汉”为利,具体说明如何进行 UTF-8 编码和解码。
“汉”的 Unicode 码点是 0x6c49(110 1100 0100 1001),通过上面的对照表可以发现,0x0000 6c49 位于第三行的范围,那么得出其格式为 1110xxxx 10xxxxxx 10xxxxxx。接着,从“汉”的二进制数最后一位开始,从后向前依次填充对应格式中的 x,多出的 x 用 0 补上。这样,就得到了“汉”的 UTF-8 编码为 11100110 10110001 10001001,转换成十六进制就是 0xE6 0xB1 0x89。
解码的过程也十分简单:如果一个字节的第一位是 0 ,则说明这个字节对应一个字符;如果一个字节的第一位1,那么连续有多少个 1,就表示该字符占用多少个字节。
html实体编码(HTML_ENTITY)
在 HTML 中,某些字符是预留的,在 HTML 中不能使用小于号(<)和大于号(>),这是因为浏览器会误认为它们是标签。 如果希望正确地显示预留字符,我们必须在 HTML 源代码中使用字符实体(character entities)。
HTML实体编码主要用于输出某些无法作为普通文本显示的字符。HTML 实体是一段以连字号(&)开头、以分号(;)结尾的文本(字符串)。实体常常用于显示保留字符(这些字符会被解析为 HTML 代码)和不可见的字符(如“不换行空格”)。
(1)部分字符在html文件中作为html结构解析
(2)某些字符被特殊处理,比如空格
(3)某些字符无法直接输入,比如带声调符号
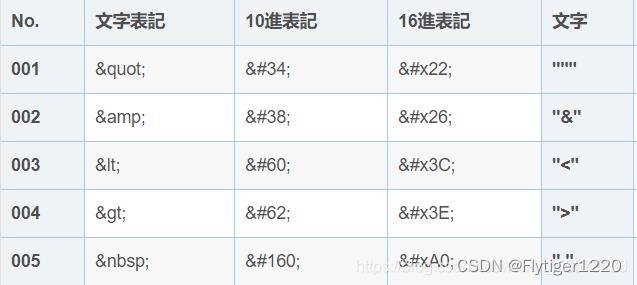
常用实体编码:
实体编号(HTML_CODE)和实体编码作用相同,也可以用来帮助浏览器识别预留字符。对于ASCLL码的转换前127都可以�~127;实体编号来一一对应。
十六进制实体编号(HEX_CODE)将实体编号改成16进制格式。
在前端,一般为了避免 XSS 攻击,会将 <> 编码为 < 与 >,这些就是 HTML 实体编码。网站后台的识别仅仅针对字符串,而浏览器解析的时候又可以将其还原,因此可以达到绕过的效果。
浏览器总是会截短 HTML 页面中的空格,如果您在文本中写 10 个空格,在显示该页面之前,浏览器会删除它们中的 9 个,如需在页面中增加空格的数量,您需要使用 字符实体。
URL编码
URL 之所以需要编码,是因为 URL 中的某些字符会引起歧义,比如若 URL 查询参数中包含”&”或者”%”就会造成服务器解析错误,再比如,URL 的编码格式采用的是 ASCII 码而非 Unicode,这表明 URL 中不允许包含任何非 ASCII 字符(比如中文),否则就会造成 URL 解析错误。URL 编码的原则是使用安全字符(即没有特殊用途或者特殊意义的字符)去表示那些不安全的字符。
对于非ASCII字符,RFC文档建议使用utf-8对其进行编码得到相应的字节,然后对每个字节执行百分号编码。如"中文"使用UTF-8字符集得到的字节为0xE4 0xB8 0xAD 0xE6 0x96 0x87,经过URL编码之后得到"%E4%B8%AD%E6%96%87"。
由于URL中好多字符是保留字,他们在URL中具有特殊的含义。如“&”表示参数分隔符,如果想要在URL中使用这些保留字,那就得对他们进行编码。
1、对URL中属于ASCII字符集的非保留字不做编码;
2、对URL中的保留字需要取其ASCII内码,然后加上“%”前缀将该字符进行替换(编码);
3、对URL中的非ASCII字符需要取其Unicode内码,然后加上“%”前缀将该字符进行替换(编码)。
由于这种编码是采用“%”加上字符内码的方式,所以,有些地方也称其为“百分号编码”。URL中的保留字符包括:! * ’ ( ) ; : @ & = + $ , / ? # [ ]
CSS特殊符号
CSS中有一些特殊符号,需要在编号前面加上反斜杠“”进行转义,比如说“向左箭头”符号对应的CSS编号是:“21E0”,那么在文档中需要写成“\\21E0”;
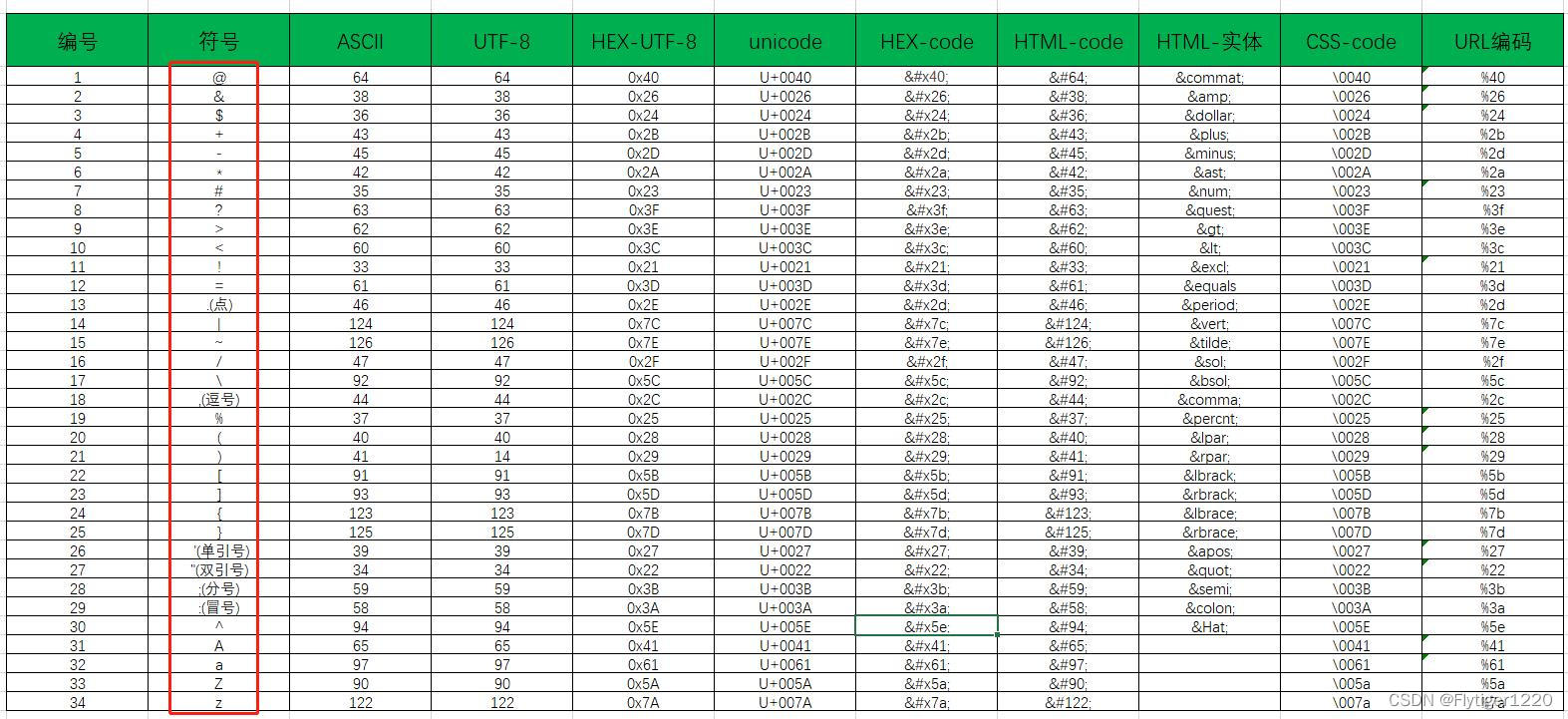
常用字符编码对照表
彻底弄懂 Unicode 编码
HTML特殊字符编码对照表(最全特殊字符编码)
Unicode 字符百科
你所不知道的unicode字符编码
URL编码是什么?
基础概念——URL编码
以上是关于常用编码格式整理的主要内容,如果未能解决你的问题,请参考以下文章