大数据仓库技术实训任务2
Posted 陈希瑞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据仓库技术实训任务2相关的知识,希望对你有一定的参考价值。
大数据仓库技术实训——任务2
请按照要求完成以下内容:
1. 启动hadoop,hive
start-all.sh
hive

2. 在hive中创建数据库empdb和empdb1
create database empdb;
create database empdb1;

3. 查看当前的所有数据库
show databases;

4. 切换到数据库empdb
use empdb;

5. 删除数据库empdb1以及其所包含的所有的表
drop database empdb1 cascade;

6. 查看数据库empdb的文件目录位置路径信息
desc database empdb;

7. 在empdb数据库下创建外部表emp_hr1,分别包含字段name(名字,字符串),employee_id(ID,字符串),sin_number(电话,字符串),start_date(入职时间,date), sex(性别,字符串),age(年龄,整形)每个字段之间由[ | ]分割.
create external table emp_hr1(
name string,
employee_id string,
sin_number string,
start_date date,
sex string,
age int
)
row format delimited fields terminated by '|';

8. 将employee_hr1.txt拷贝至表路径下

9. 查看表是否映射成功。
select * from emp_hr1;

10. 拷贝一张跟emp_hr1表结构一样的空表名为emp_hr2
create table emp_hr2 like emp_hr1;

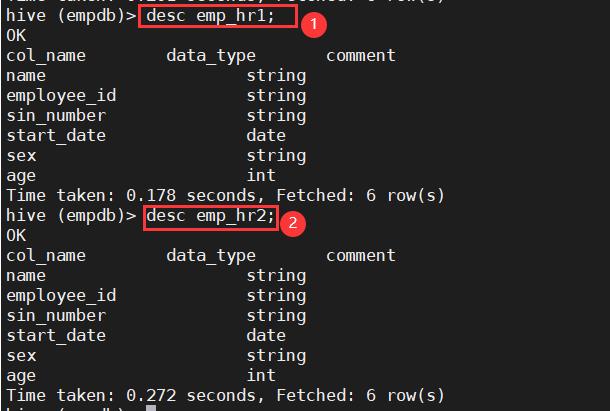
11. 查看emp_hr1和emp_hr2表结构
desc emp_hr1;
desc emp_hr2;
12. 将表emp_hr2重新命名为emp_hr3
alter table emp_hr2 rename to emp_hr3;

13. 将表emp_hr3字段employee_id改为employee_ids
alter table emp_hr3 change employee_id employee_ids string;

14. 为表emp_hr3添加列salary,数据类型为整型
alter table emp_hr3 add columns(salary int) ;

15. 为表emp_hr3删除列salary
alter table emp_hr3 replace columns(
name string,
employee_ids string,
sin_number string,
start_date date,
sex string,
age int
);

16. 创建一个新表emp_hr2,并从已经存在的emp_hr1表中插入数据name,start_date,sex和age 到新表emp_hr2
create table emp_hr2(
name string,
start_date date,
sex string,
age int
);
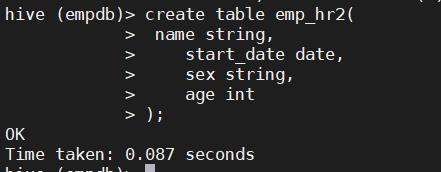
insert into emp_hr2 select name,start_date,sex,age from emp_hr1;

简单方法:
create table emp_hr2 as select name,start_date,sex,age from emp_hr1;
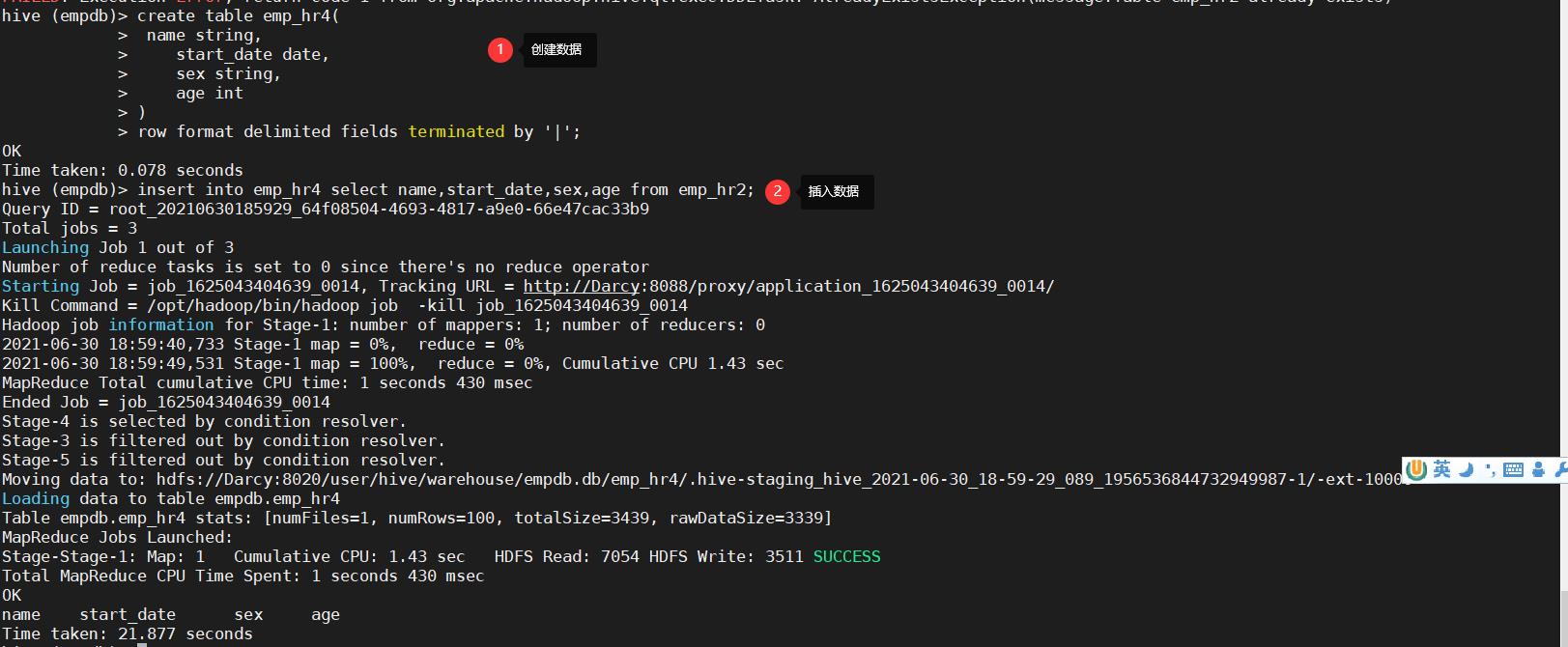
17. 创建新表emp_hr4,包含字段name(名字,字符串), start_date(入职时间,date), sex(性别,字符串),age(年龄,整形)每个字段之间由[ | ]分割,从emp_hr2中向emp_hr4表中插入数据。
--创建新表emp_hr4
create table emp_hr4(
name string,
start_date date,
sex string,
age int
)
row format delimited fields terminated by '|';
--插入数据
insert into emp_hr4 select name,start_date,sex,age from emp_hr2;
18. 求emp_hr2的总行数(count)
select count(*) cnt from emp_hr2;

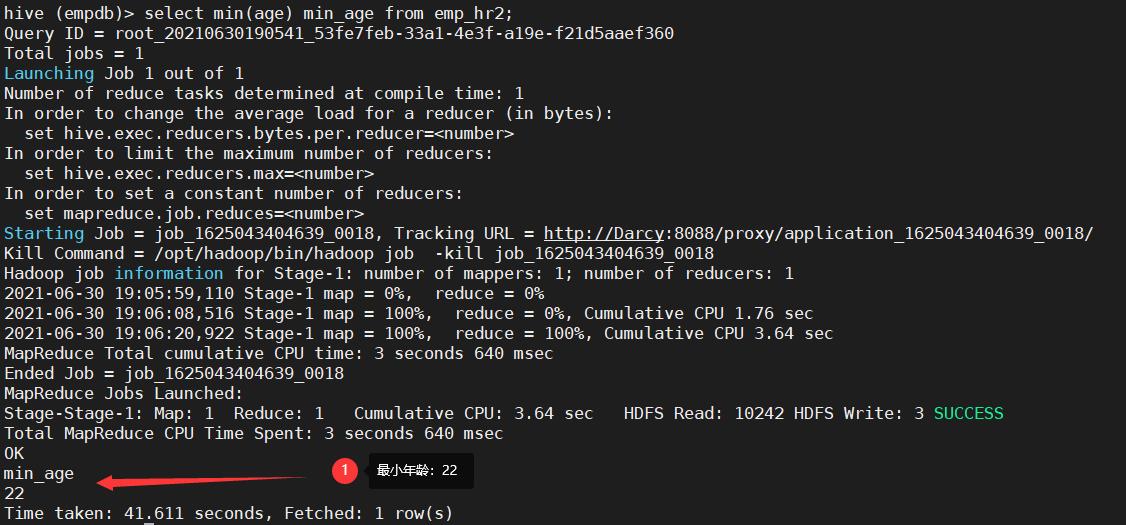
19. 求emp_hr2中年龄最大值和最小的值
select max(age) max_age from emp_hr2;
select min(age) min_age from emp_hr2;

20. 求emp_hr2中年龄的平均值
select avg(age) avg_age from emp_hr2;

21. 查询emp_hr2的前5行的名字和年龄
select name,age from emp_hr2 limit 5;

22. 查询出年龄大于50的所有员工名字与年龄
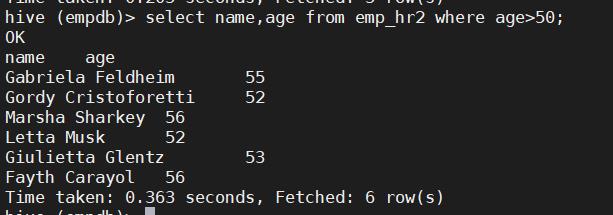
select name,age from emp_hr2 where age>50;
23. 查询出年龄介于20到30之间的所有员工名字与年龄
select name,age from emp_hr2 where age between 20 and 30;

24. 查询出到退休年龄55岁的所有员工名字与年龄
select name,age from emp_hr2 where age=55;

25. 查询出年龄在25到55岁以外的所有员工名字与年龄
select name,age from emp_hr2 where age not between 20 and 55;

26. 查找年龄以5开头的员工姓名和性别信息
select name,sex from emp_hr2 where age like '5%';

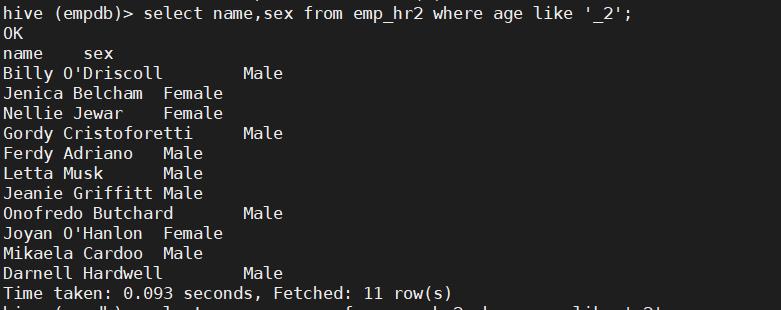
27. 查找年龄第二位为2的员工姓名和性别信息
select name,sex from emp_hr2 where age like '_2';
28. 在emp_hr2中查询年龄大于40且性别是Male的员工信息
select * from emp_hr2 where age>40 and sex='Male';

29. 在emp_hr2中查询性别除了Male以外的员工信息
select * from emp_hr2 where sex!='Male';
--或者
select * from emp_hr2 where sex='Female';

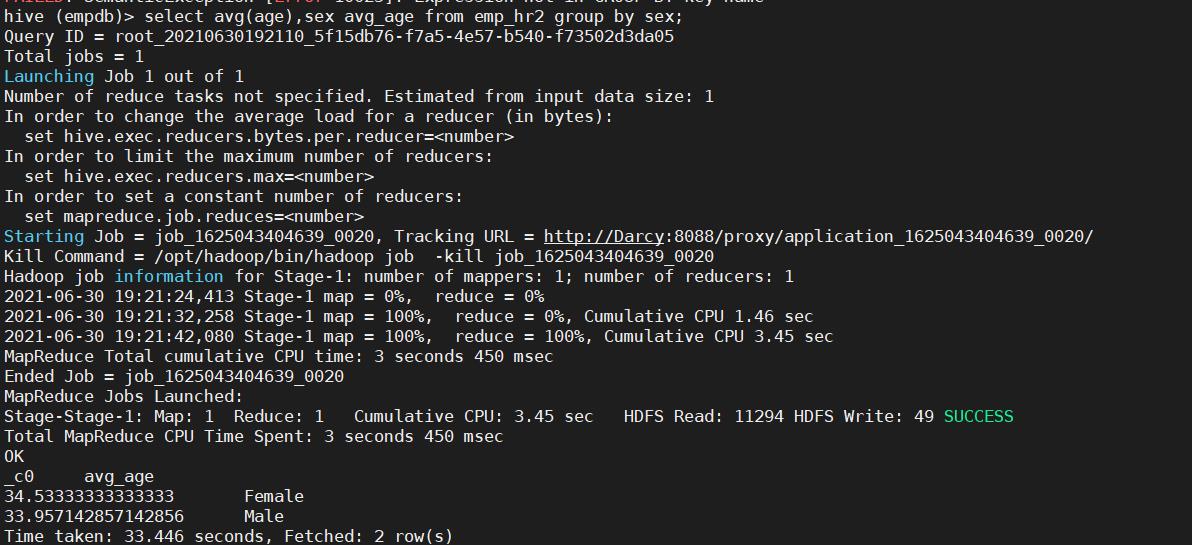
30. 计算emp_hr2表平均年龄按照男女分组
select avg(age), sex from emp_hr2 group by sex;
31. 计算emp_hr2表男女的最高,最低年龄
select max(age) max_age,min(age) min_age, sex from emp_hr2 group by sex;

32. 计算emp_hr2表平均年龄大于34的性别
select sex from emp_hr2 group by sex having avg(age)>34;

33. 查询emp_hr2表中姓名,按照员工离退休年龄55岁的相差岁数,降序排序。(大于55岁的为返聘人员不计入排序)
select name,(55-age) new_age from emp_hr2 where age=<55 order by new_age desc;
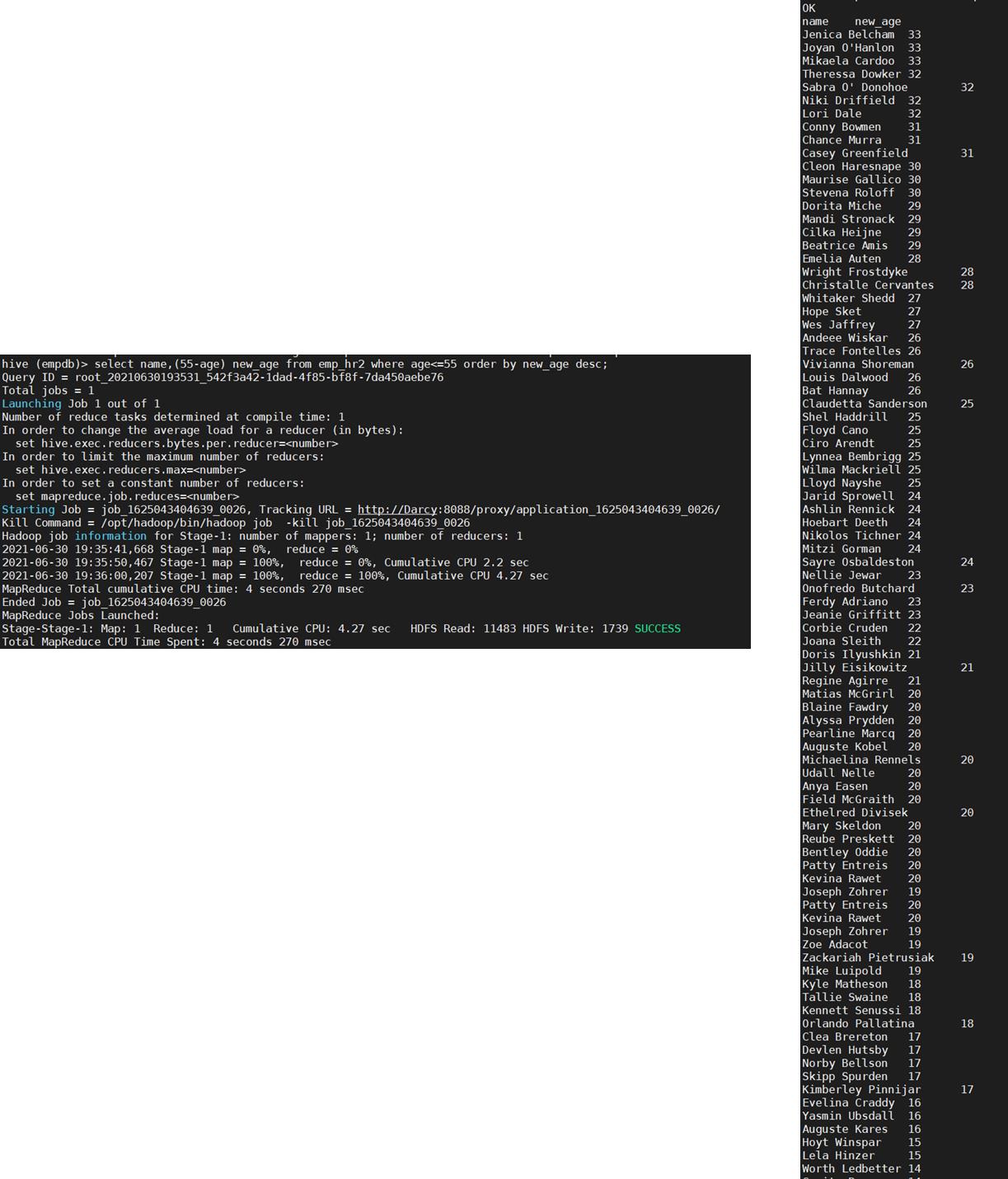
注:返回数据过多,仅截取了部分数据。
34. 查询emp_hr2表中姓名,性别,年龄,按照性别进行分区,年龄升序排序。
select name, sex, age from emp_hr2 distribute by sex sort by age;

注:返回数据过多,仅截取了部分数据。
35. 在数据库empdb下新建分区表emp_hr1_part1, 分别包含字段name(名字,字符串),employee_id(ID,字符串),sin_number(电话,字符串),start_date(入职时间,date),age(年龄,整形),以sex_m(性别,字符串)来分区,每个字段之间由[ | ]分割.
create table emp_hr1_part1(
name string,
employee_id string,
sin_number string,
start_date date,
sex string,
age int
)
partitioned by (sex_m string)
row format delimited fields terminated by '|';

36. 从emp_hr1中将name, employee_id, sin_number, start_date, age和sex=’Male’的数据插入到分区表emp_hr1_part1的分区sex_m=‘Male’中。
--打开动态分区
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
insert into emp_hr1_part1 partition(sex_m='Male')
select * from emp_hr1 where sex='Male';

37. 为表emp_hr1_part1增加分区sex_m=’Female’
alter table emp_hr1_part1 add partition(sex_m='Female');

38. 从emp_hr1中将name, employee_id, sin_number, start_date, age和sex=’Female’的数据插入到分区表emp_hr1_par1的分区sex_m=‘Female’中。
insert into emp_hr1_part1 partition(sex_m='Female')
select * from emp_hr1 where sex='Female';

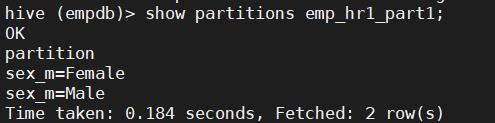
39. 使用show partitions语句查看emp_hr1_part1有哪些分区
show partitions emp_hr1_part1;
40. 查看emp_hr1_part1表中分区数据(sex_m=’Male’)
select * from emp_hr1_part1 where sex_m='Male';

41. 为表emp_hr1_part1增加分区sex_m=’Middle’,然后删除分区sex_m=’Middle’
--增加分区
ALTER TABLE emp_hr1_part1 ADD IF NOT EXISTS PARTITION (sex_m='Middle');
--删除分区
ALTER TABLE emp_hr1_part1 DROP IF EXISTS PARTITION (sex_m='Middle');

41. 为表emp_hr1_part1增加分区sex_m=’Middle’,然后删除分区sex_m=’Middle’
--增加分区
ALTER TABLE emp_hr1_part1 ADD IF NOT EXISTS PARTITION (sex_m='Middle');
--删除分区
ALTER TABLE emp_hr1_part1 DROP IF EXISTS PARTITION (sex_m='Middle');
以上是关于大数据仓库技术实训任务2的主要内容,如果未能解决你的问题,请参考以下文章