Kafka节点万兆网卡打满,揭晓集群安然无恙的秘诀
Posted 中间件兴趣圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka节点万兆网卡打满,揭晓集群安然无恙的秘诀相关的知识,希望对你有一定的参考价值。
想必大家都看过笔者Kafka集群故障的排查经验,并通过优化参数使得Kafka集群应对洪峰流量的能力提升N倍,网卡流量几乎打满,集群写入稳如泰山,无独有偶,菜鸟的一个故障导致集群单个topic从5W/tps直接飙升到50W/tps,但集群稳如狗,相当于做了一次“突然的压测”,让我们一起回顾一下这次惊心动魄的过程吧。
在进入本文的探讨之前,强烈推荐一下笔者最近的得意之作:Kafka集群中大部分消费组无端被重置到最新位点开始消费的故障排查经验:
1、业务场景介绍
数据同步的业务流程简化如下:
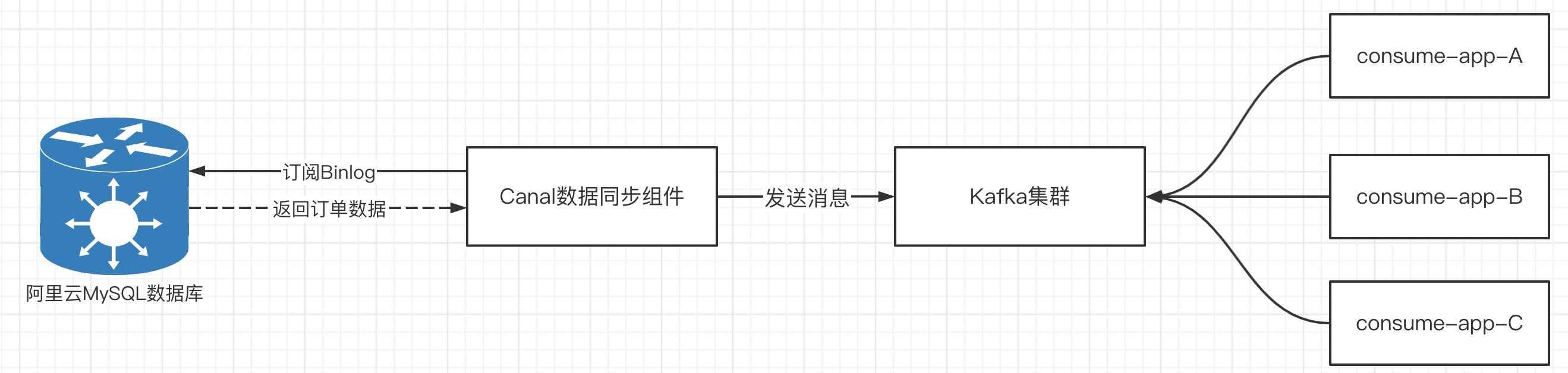
通过数据同步组件,通过订阅mysql数据库的binlog日志,将订单数据先写入到kafka集群,然后下游系统根据不同的业务处理逻辑,订阅该主题,进行对应的下游业务处理。
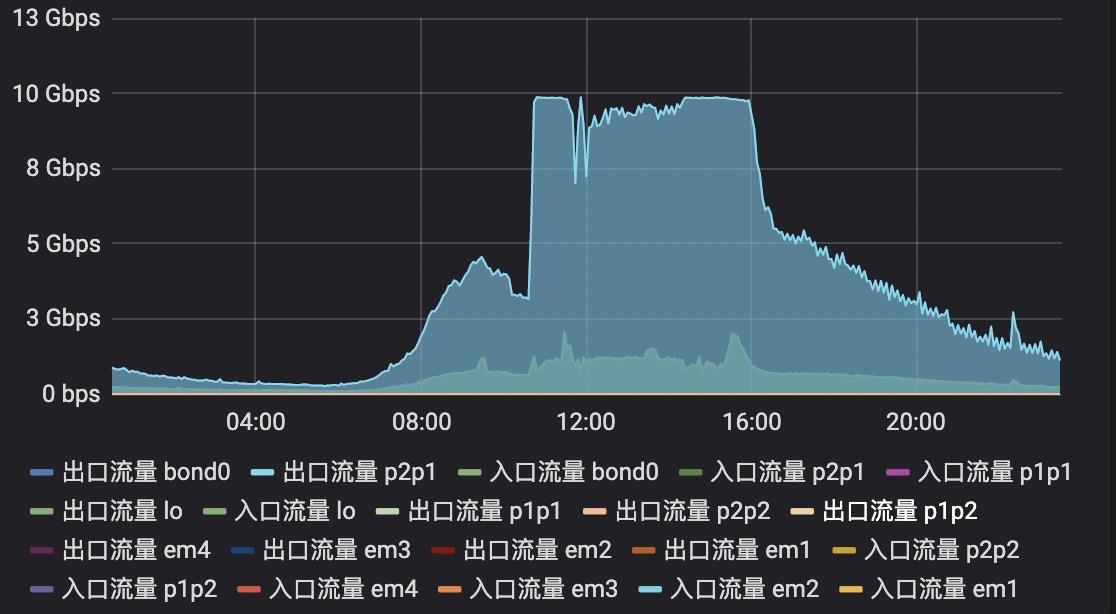
某一天,我们通过业务监控监测出某一段时间菜鸟这边订单异常,几乎下降到0,持续半个小时左右后订单流量突增,是往常的10倍,此时Kafka集群各个节点的流量将网卡打满,达到了10G,如下图所示:
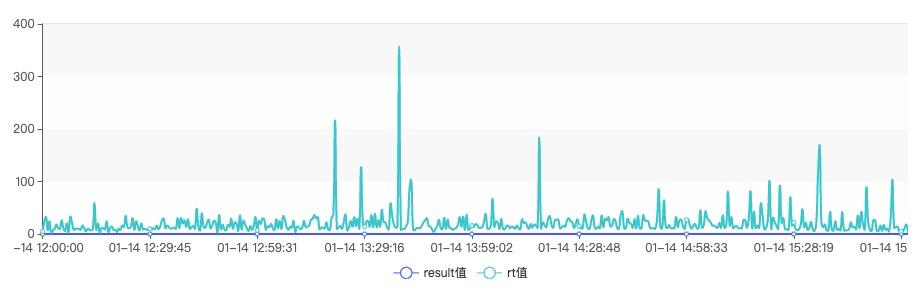
但从消息的监控平台发现,节点的写入延迟在如此大流量的冲击下保持的还不错,如下图所示:
为啥部分集群在双十一流量冲击下不堪一击,仅仅过去2个月,我们的集群表现为哈突然这么优秀了呢?
得意于从生产故障|Kafka ISR频繁伸缩引发性能急剧下降这个故障中吸取了经验教训,从而对集群的参数进行了优化,其中最重要的几个优化参数如下:
- replica.lag.time.max.ms
从默认的10s调整为60s。 - num.replica.fetchers
从默认的1调整为10。
这个两个参数为何具有这么大魔力呢?
2、这次为什么“扛住”了呢?
首先这里再来简单回顾一下笔者在双十一遇到故障的原因:频繁发生ISR收缩与扩张。
ISR收缩与扩张过程:
- 当Follower副本从落后Leader副本的数据超过replica.lag.time.max.ms设置的值,默认为10s后,该Follower副本就会从ISR集合中被移除,此时ISR集合中的副本减少,俗称“收缩”。
- 副本从ISR集合中移除后,会继续向Leader副本同步数据,当落后的数据小于10s后,该副本又会重新加入到ISR集合中,此时此时ISR集合中的副本增加,俗称“扩张”。
但Kafka在处理ISR收缩与扩张时,在更新高水位线时会加写锁,而Kafka Broker在处理消息写入、处理消息读取时更新Kafka高水位线,需要申请leaderIsrUpdateLock的读锁,ISR的伸缩、扩张与消息读取、消息消费,从节点从主节点复制这几个动作是互斥的,并发急剧下降,造成集群吞吐直线下降,从而影响Kafka集群的可用性。
故核心关键是要避免ISR的频繁发生ISR收缩与扩张,关键之关键在于频繁二字。
在大流量急剧冲击Kafka集群时,并没有频繁发生ISR,是不是副本之间数据没有延迟,这个我相信不难想到,网卡流量都打满了,要想确保Leader与Follower副本之间的数据没有延迟,还是比较困难的。
从kafka-manager系统上去观察对应topic的分区情况,发现所有分区的ISR集合中都只包含Leader,其他副本全部被剔除,但由于调高了replica.lag.time.max.ms的值,使得副本落后后,在网卡打满的情况下,想要跟上Leader节点就没这么容易,所以只出现了ISR集合的剔除(每一个分区只剩下leader本身),并没有反复出现,共消息的写入并未收到大的影响,集群健康度良好。
当然部分对kafka比较了解的读者可能会问,ISR集合中只有Leader一个节点,还能写入消息?
在这里不得不和大家脑补一下Kafka中一个非常重要的参数:acks,可选值:
- 0
表示生产者不关系该条消息在 broker 端的处理结果,只要调用 KafkaProducer 的 send 方法返回后即认为成功,显然这种方式是最不安全的,因为 Broker 端可能压根都没有收到该条消息或存储失败。 - all 或 -1
表示消息不仅需要 Leader 节点已存储该消息,并且要求其副本(准确的来说是 ISR 中的节点)全部存储才认为已提交,才向客户端返回提交成功。这是最严格的持久化保障,当然性能也最低。 - 1
表示消息只需要写入 Leader 节点后就可以向客户端返回提交成功。
首先,在我们的场景中,acks设置的是1,只要Leader节点写入成功即可,但又有人会问,这样可能会造成消息丢失,那为什么我们还在如此重要的场景(订单场景)使用acks为1呢?
因为就算集群由于断电等异常因素造成了数据丢失,这部分数据我们能够非常容易的恢复,只需要将数据同步组件回溯一下,重新解析Binlog,将数据重新写入到kafka集群即可。
这里再强调一下acks设置为all时,只需要ISR集合中的副本写入成功即可,既然选择了all,说明对数据丢失的容忍度极低,此时需要考虑如何保证不丢失消息?
只要ISR集合中的副本写入成功就成功,这取决于ISR副本中的个数,更直白一点就是如果ISR集合中只有Leader节点,那该机制不是退化为acks=1了吗?
故Kafka还提供了另外一个topic级别的参数min.insync.replicas,用来控制当acks为all时,能够往该topic写入消息必备条件:ISR集合中的最小副本数,该参数默认为1,在topic的副本数为3的情况下,通常建议将该值设置为2,表示容忍一个副本不在ISR,还能成功写入,因为数据至少会存储2份。
本文就介绍到这里了,欢迎你的点赞,彩蛋来了,彩蛋来了👎
**有想和我成为同事的朋友没?我负责的小组招人啦,
Base上海青浦,全日制本科,提供单身宿,可申请廉价人才公寓,入职后与我一个团队,共同承担消息中间件、数据同步产品、全链路压测、缓存等产品的研发与运维工作,目前消息集群的规模(日均消息流转千万级)。
不要问我招聘JD,坚持看我文章的粉丝朋友,通过面试绝对没有问题,欢迎自荐与推荐。
原文首发:Kafka节点万兆网卡打满,揭晓集群安然无恙的秘诀
一键三连(关注、点赞、留言)是对我最大的鼓励。
各位技术朋友们,我是《RocketMQ技术内幕》一书作者,CSDN2020博客之星TOP2,热衷于中间件领域的技术分享,维护「中间件兴趣圈」公众号,旨在成体系剖析Java主流中间件,构建完备的分布式架构体系,欢迎大家大家关注我,回复「专栏」可获取15个专栏;回复「PDF」可获取海量学习资料,回复「加群」可以拉你入技术交流群,零距离与BAT大厂的大神交流。
以上是关于Kafka节点万兆网卡打满,揭晓集群安然无恙的秘诀的主要内容,如果未能解决你的问题,请参考以下文章