Keras深度学习实战——使用深度Q学习进行SpaceInvaders游戏
Posted 盼小辉丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Keras深度学习实战——使用深度Q学习进行SpaceInvaders游戏相关的知识,希望对你有一定的参考价值。
Keras深度学习实战——使用深度Q学习进行SpaceInvaders游戏
0. 前言
在《深度Q学习算法详解》一节中,我们使用了深度 Q 学习来进行 Cart-Pole 游戏。在本节中,我们将利用深度Q学习来玩“太空侵略者”游戏 (SpaceInvaders),这是一个比 Cart-Pole 更复杂的环境。
1. 问题与模型分析
“太空侵略者”游戏的屏幕截图示例如下所示,智能体的目标是使单个游戏回合中获得的分数最大化。
为了能够最大化智能体的得分,我们采用的模型构建策略如下:
- 初始化
Space Invaders-Atari2600游戏环境 - 预处理图像帧:
- 删除不影响动作预测的像素,例如,玩家位置下方的像素
- 归一化输入图像
- 调整图像尺寸,以输入到神经网络模型
- 根据gym环境的要求堆叠游戏画面帧
- 使智能体在多个回合中进行游戏:
- 在初始回合中,将进行深入探索,并随着回合的增加而衰减
- 在某一状态下需要采取的动作取决于探索系数
- 将游戏状态和在该状态下采取的动作的相应奖励存储在
memory数组中 - 根据先前回合获得的奖励来更新模型
下载包含 Space Invaders 游戏的 ROM,并安装 Retro 库:
$ wget http://www.atarimania.com/roms/Roms.rar && unrar x Roms.rar && unzip Roms/ROMS.zip
$ pip3 install gym-retro
$ python3 -m retro.import ROMS/
2. 使用深度 Q 学习进行 SpaceInvaders 游戏
(1) 创建环境并查看状态空间大小:
env = gym.make('SpaceInvaders-v0')
print("Size of our state space",env.observation_space)
print("Action Size",env.action_space.n)
possible_actions=np.array(np.identity(env.action_space.n,dtype=int).tolist())
(2) 定义用于预处理游戏画面帧的函数:
def preprocess_frame(frame):
# 转换为灰度图像
gray = rgb2gray(frame)
# 裁剪无用像素
cropped_frame = gray[8:-12, 4:-12]
# 归一化
normalized_frame = cropped_frame / 255.
# 整形
preprocess_frame = transform.resize(normalized_frame, [110, 84])
return preprocess_frame
(3) 构建用于将给定状态的帧堆叠起来的函数:
stack_size = 4 # 每次堆叠4帧
# 初始化双端队列
stacked_frames = deque([np.zeros((110,84), dtype=np.int) for i in range(stack_size)], maxlen=4)
def stack_frames(stacked_frames, state, is_new_episode):
# 预处理
frame = preprocess_frame(state)
if is_new_episode:
# 初始化stacked_frames
stacked_frames = deque([np.zeros((110,84), dtype=np.int) for i in range(stack_size)], maxlen=4)
stacked_frames.append(frame)
stacked_frames.append(frame)
stacked_frames.append(frame)
stacked_frames.append(frame)
# 堆叠帧
stacked_state = np.stack(stacked_frames, axis=2)
else:
# 将新帧添加到双端队列中,并移除时间最久的帧
stacked_frames.append(frame)
# 堆叠帧
stacked_state = np.stack(stacked_frames, axis=2)
return stacked_state, stacked_frames
(4) 初始化模型超参数:
state_size = [110, 84, 4] # Our input is a stack of 4 frames hence 110x84x4 (Width, height, channels)
action_size = env.action_space.n # 8 possible actions
learning_rate = 0.00025 # Alpha (aka learning rate)
total_episodes = 50 # Total episodes for training
max_steps = 50000 # Max possible steps in an episode
batch_size = 32 # Batch size
explore_start = 1.0 # exploration probability at start
explore_stop = 0.01 # minimum exploration probability
decay_rate = 0.00001 # exponential decay rate for exploration prob
gamma = 0.9 # Discounting rate
pretrain_length = batch_size # Number of experiences stored in the Memory when initialized for the first time
memory_size = 1000000 # Number of experiences the Memory can keep
stack_size = 4 # Number of frames stacked
training = False
episode_render = False
(5) 定义用于从 memory 数组中采样数据样本的函数:
memory = deque(maxlen=100000)
def sample(memory, batch_size):
buffer_size = len(memory)
index = np.random.choice(np.arange(buffer_size),
size = batch_size,
replace = False)
return [memory[i] for i in index]
(6) 定义函数,用于返回智能体需要执行的动作:
def predict_action(model,explore_start, explore_stop, decay_rate, decay_step, state, actions):
exp_exp_tradeoff = np.random.rand()
explore_probability = explore_stop + (explore_start - explore_stop) * np.exp(-decay_rate * decay_step)
if (explore_probability > exp_exp_tradeoff):
choice = random.randint(1,len(possible_actions))-1
action = possible_actions[choice]
else:
Qs = model.predict(state.reshape((1, *state.shape)))
choice = np.argmax(Qs)
action = possible_actions[choice]
return action, explore_probability
(7) 构建用于训练神经网络模型的函数:
def replay(agent,batch_size,memory):
minibatch = sample(memory,batch_size)
for state, action, reward, next_state, done in minibatch:
target = reward
if not done:
target = reward + gamma*np.max(agent.predict(next_state.reshape((1,*next_state.shape)))[0])
target_f = agent.predict(state.reshape((1,*state.shape)))
target_f[0][action] = target
agent.fit(state.reshape((1,*state.shape)), target_f, epochs=1, verbose=0)
return agent
(8) 定义神经网络模型:
def DQNetwork():
model=Sequential()
model.add(Conv2D(32,input_shape=(110,84,4),kernel_size=8, strides=4, padding='valid',activation='elu'))
model.add(Conv2D(64, kernel_size=4, strides=2, padding='valid',activation='elu'))
model.add(Conv2D(128, kernel_size=3, strides=2, padding='valid',activation='elu'))
model.add(Flatten())
model.add(Dense(units=512))
model.add(Dense(units=3,activation='softmax'))
model.compile(optimizer=Adam(0.01),loss='mse')
return model
模型简要架构信息如下:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 20, 32) 8224
_________________________________________________________________
conv2d_1 (Conv2D) (None, 12, 9, 64) 32832
_________________________________________________________________
conv2d_2 (Conv2D) (None, 5, 4, 128) 73856
_________________________________________________________________
flatten (Flatten) (None, 2560) 0
_________________________________________________________________
dense (Dense) (None, 512) 1311232
_________________________________________________________________
dense_1 (Dense) (None, 6) 3078
=================================================================
Total params: 1,429,222
Trainable params: 1,429,222
Non-trainable params: 0
_________________________________________________________________
(9) 循环运行多个回合,在更新模型的同时继续进行游戏:
agent = DQNetwork()
agent.summary()
rewards_list=[]
rewards = []
for episode in range(1000):
# 游戏环境初始化
decay_step=0
step = 0
episode_rewards = []
state = env.reset()
state, stacked_frames = stack_frames(stacked_frames, state, True)
while step < max_steps:
step += 1
decay_step +=1
# 预测动作
action, explore_probability = predict_action(agent,explore_start, explore_stop, decay_rate, decay_step, state, possible_actions)
# 执行动作,进入新状态
next_state, reward, done, _ = env.step(action)
# 将奖励追加到episode_rewards列表中
episode_rewards.append(reward)
if done:
next_state = np.zeros((110,84), dtype=np.int)
next_state, stacked_frames = stack_frames(stacked_frames, next_state, False)
step = max_steps
total_reward = np.sum(episode_rewards)
print('Episode: '.format(episode),
'Total reward: '.format(total_reward),
'Explore P: :.4f'.format(explore_probability))
rewards_list.append((episode, total_reward))
rewards.append(total_reward)
memory.append((state, action, reward, next_state, done))
else:
next_state, stacked_frames = stack_frames(stacked_frames, next_state, False)
memory.append((state, action, reward, next_state, done))
state = next_state
replay(agent,32,memory,explore_start,explore_stop,decay_rate)
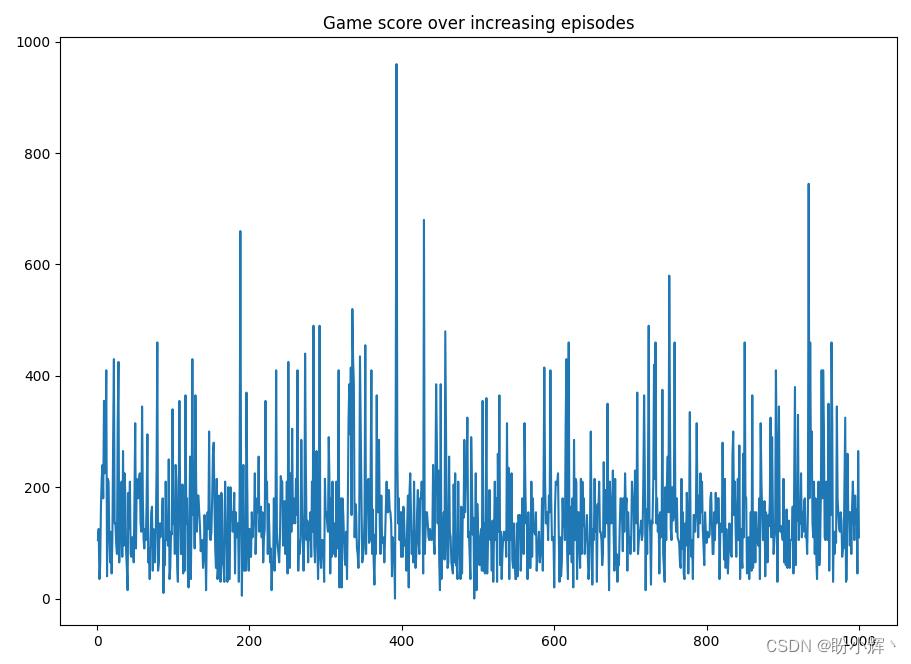
(10) 绘制智能体在每个回合中获得的奖励,可以看到,该模型在某些回合中的得分可以超过 800:
import matplotlib.pyplot as plt
plt.plot(range(1,len(rewards)+1), rewards)
plt.title('Game score over increasing episodes')
plt.show()
相关链接
Keras深度学习实战(1)——神经网络基础与模型训练过程详解
Keras深度学习实战(2)——使用Keras构建神经网络
Keras深度学习实战(3)——神经网络性能优化技术
Keras深度学习实战(4)——深度学习中常用激活函数和损失函数详解
Keras深度学习实战(6)——深度学习过拟合问题及解决方法
Keras深度学习实战(7)——卷积神经网络详解与实现
Keras深度学习实战(42)——强化学习基础
Keras深度学习实战(43)——深度Q学习算法
以上是关于Keras深度学习实战——使用深度Q学习进行SpaceInvaders游戏的主要内容,如果未能解决你的问题,请参考以下文章