Hadoop大数据框架思想及组成
Posted JOSON.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop大数据框架思想及组成相关的知识,希望对你有一定的参考价值。
文章目录
Google三大论文
第一篇论文:GFS
2003年谷歌发表了“The Google File System”(谷歌文件系统,简称GFS)论文,GFS的架构能够满足在网页爬取和索引过程中产生的超大文件的存储需求。
在2004年Nutch团队开始做GFS的开源版本实现,也就是Nutch分布式文件系统(NDFS)。
第二篇论文:MapReduce
2004年谷歌发表了“MapReduce:Simplified Data Processing on Large Cluster”(大型集群的数据简化处理)论文。
2005年,Nutch团队在Nutch上实现了MapReduce。
2006年2月,Nutch开发人员将NDFS和MapReduce移除Nutch形成一个独立的项目,命名为Hadoop。
第三篇:BigTable
2006年谷歌发表了“BigTable:A Distributed Storage System for Structured Data”(一个结构化数据的分布式存储系统)论文。
Powerset公司根据BigTable的思想,发起了HBase,即Hadoop Database。
2008年1月,Hadoop成为Apache的顶级项目。背后主要的公司为雅虎,主要用Hadoop来支撑雅虎的搜索引擎系统。
2011年 Hadoop 1.0版本发布
2013年 Hadoop 2.0版本发布
2017年 Hadoop 3.0版本发布
文献参考:Google三大论文、Hadoop官网文档
Hadoop模块构成
三大版本区别
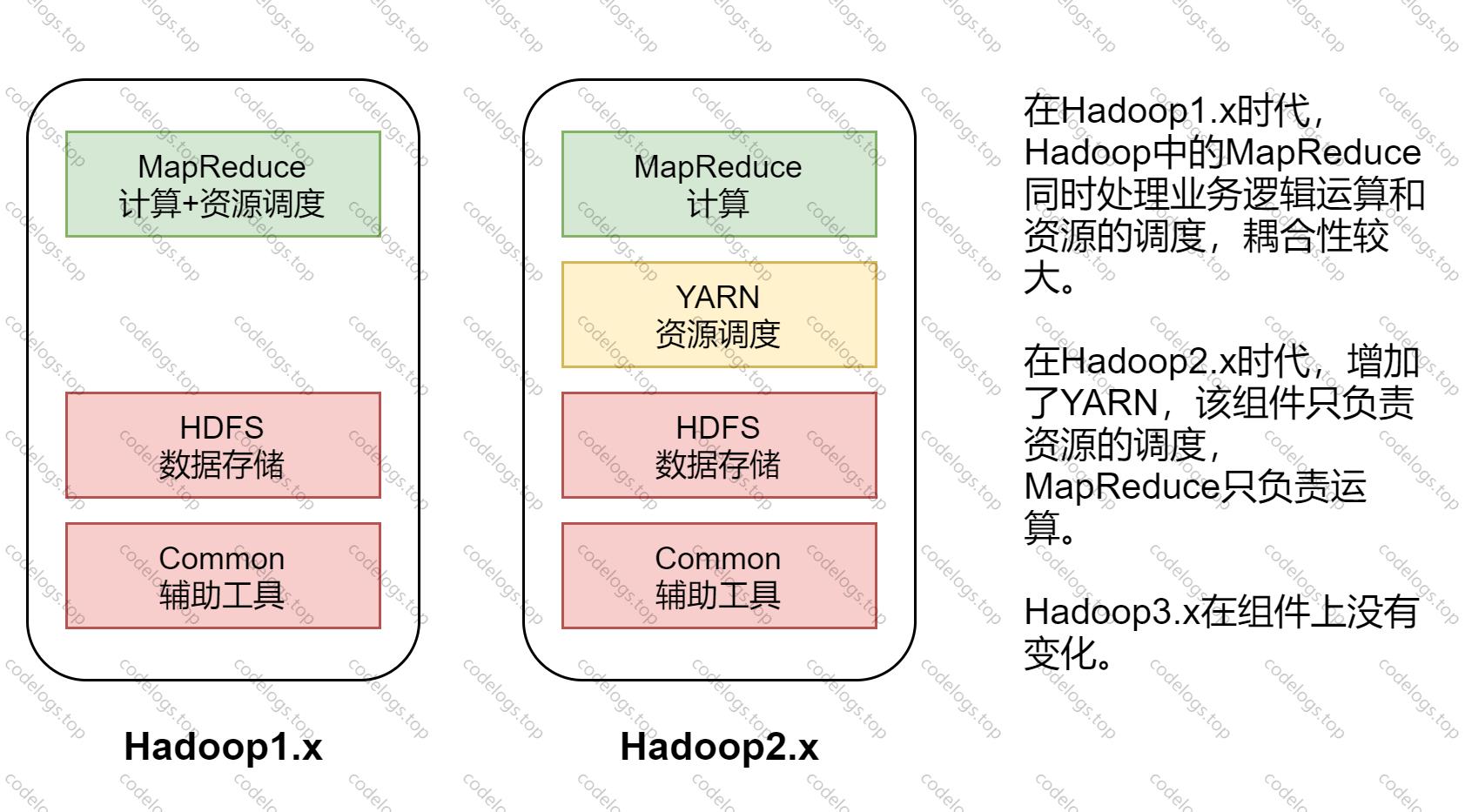
Hadoop Common:公共工具,为其他模块提供支撑。
Hadoop Distributed File System (HDFS™):提供对应用程序数据的高吞吐量访问的分布式文件系统。
Hadoop YARN:用于作业调度和集群资源管理的框架。
Hadoop MapReduce:一个基于 YARN 的系统,用于并行处理大型数据集。
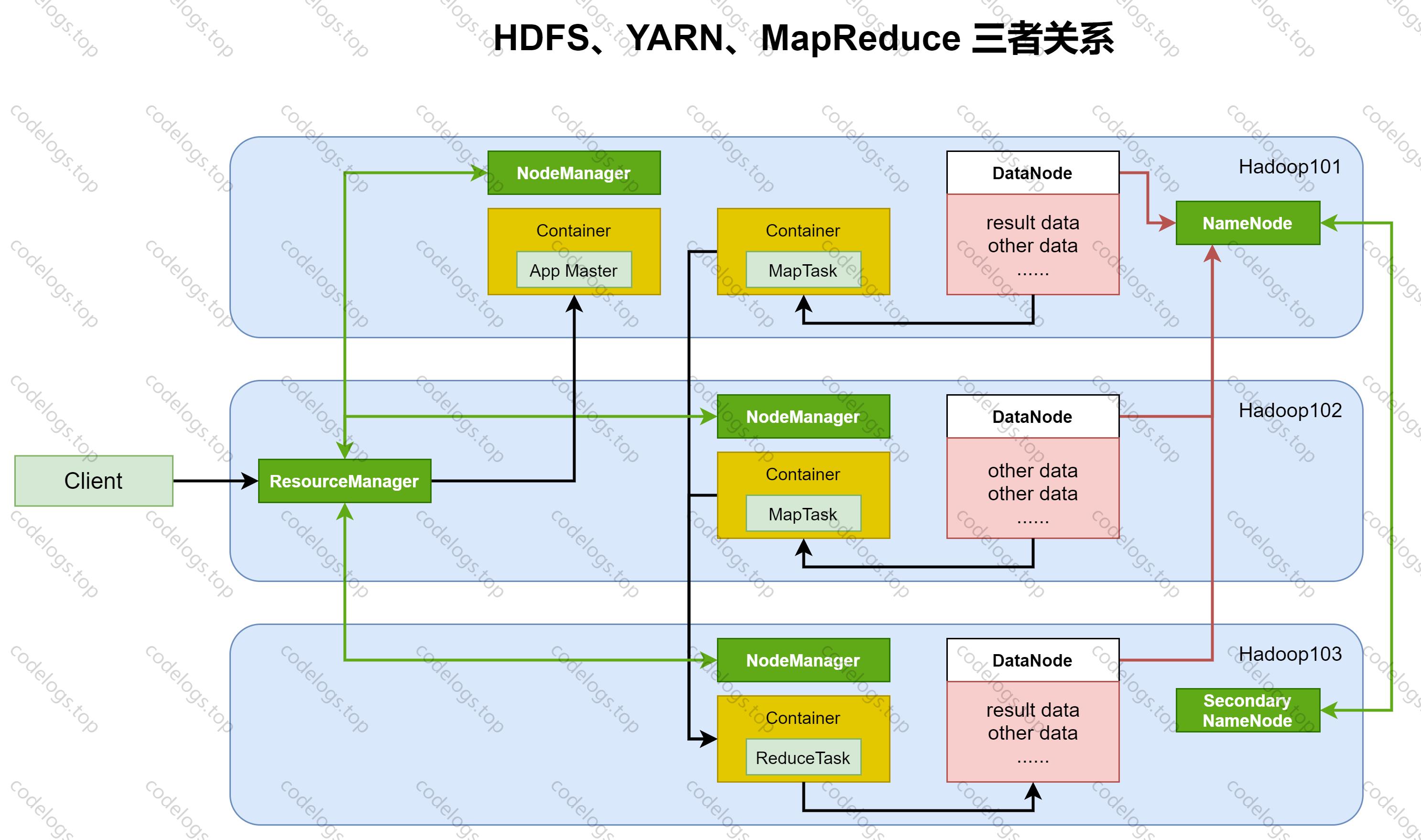
组件一:HDFS
HDFS是一个主/从(Master/Slave)体系结构,由四部分组成,HDFS Client、NameNode、DataNode和Secondary NameNode。
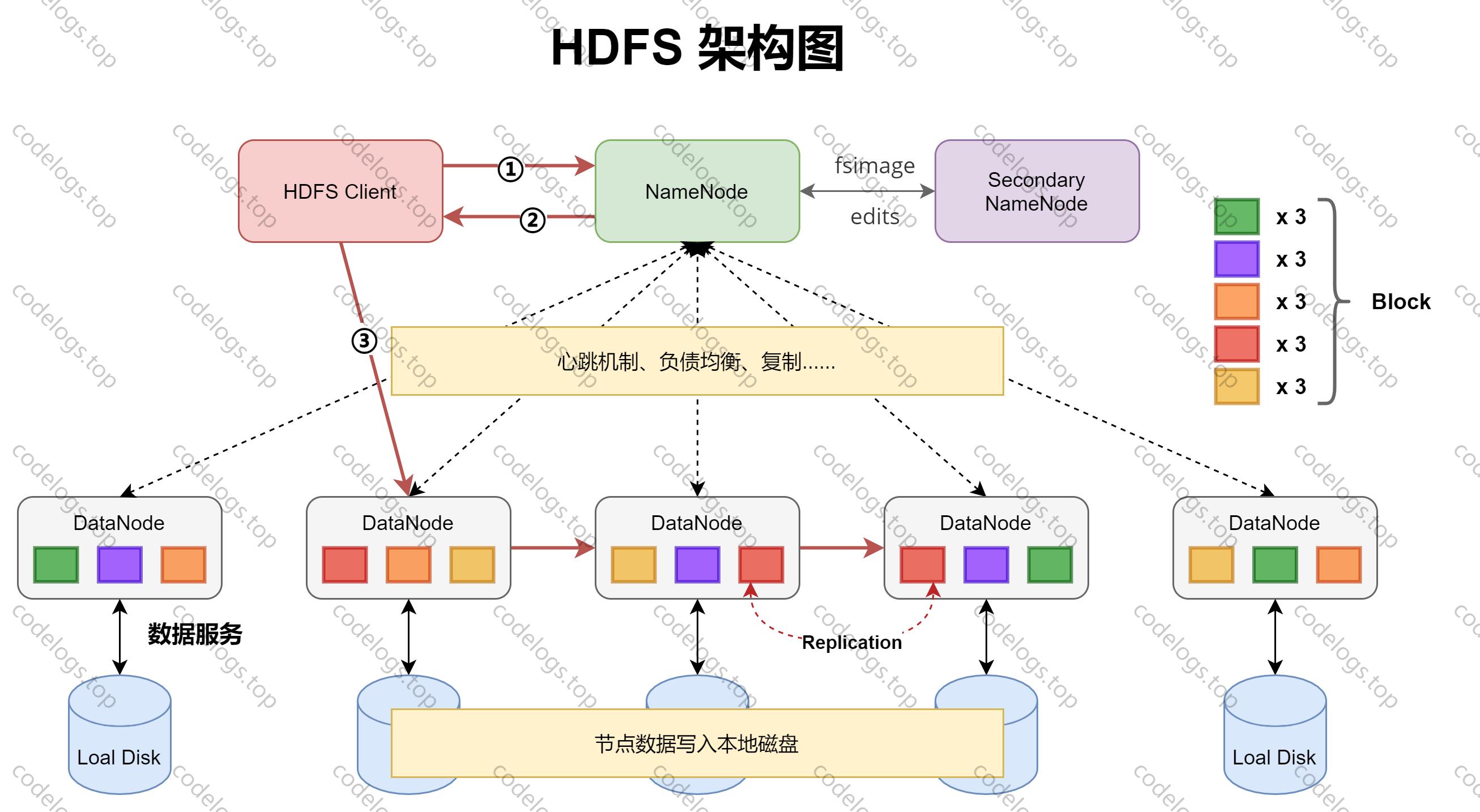
HDFS Client
Client指的是客户端,当上传文件时,Client会将文件切分成一个一个数据块(Block),然后进行存储。
首先与NameNode交互取得元数据,然后定位到对应的DataNode,进行读写操作。
Client提供了命令来管理和访问HFDS,比如关闭或启动HDFS。
NameNode
担任Master管理者角色,管理HDFS的名称空间,各个Block的映射信息,配置副本策略以及处理客户端的读写请求。
定期更新fsimage(镜像文件)和edits(日志文件)。
因为容错安全考虑,默认的副本策略会备份3份,块副本称为Replication。
DataNode
Slave从属角色,NameNode下达命令,由DataNode执行实际操作,如执行块创建,删除和复制。
对Block存储,并进行读写操作。
Secondary NameNode
辅助NameNode,分担其工作量,紧急情况下可辅助恢复NameNode,并非NameNode的热备份,当NameNode挂掉时,不能马上替换并提供服务。
定期合并fsimage(镜像文件)和edits(日志文件),并推送给NameNode。
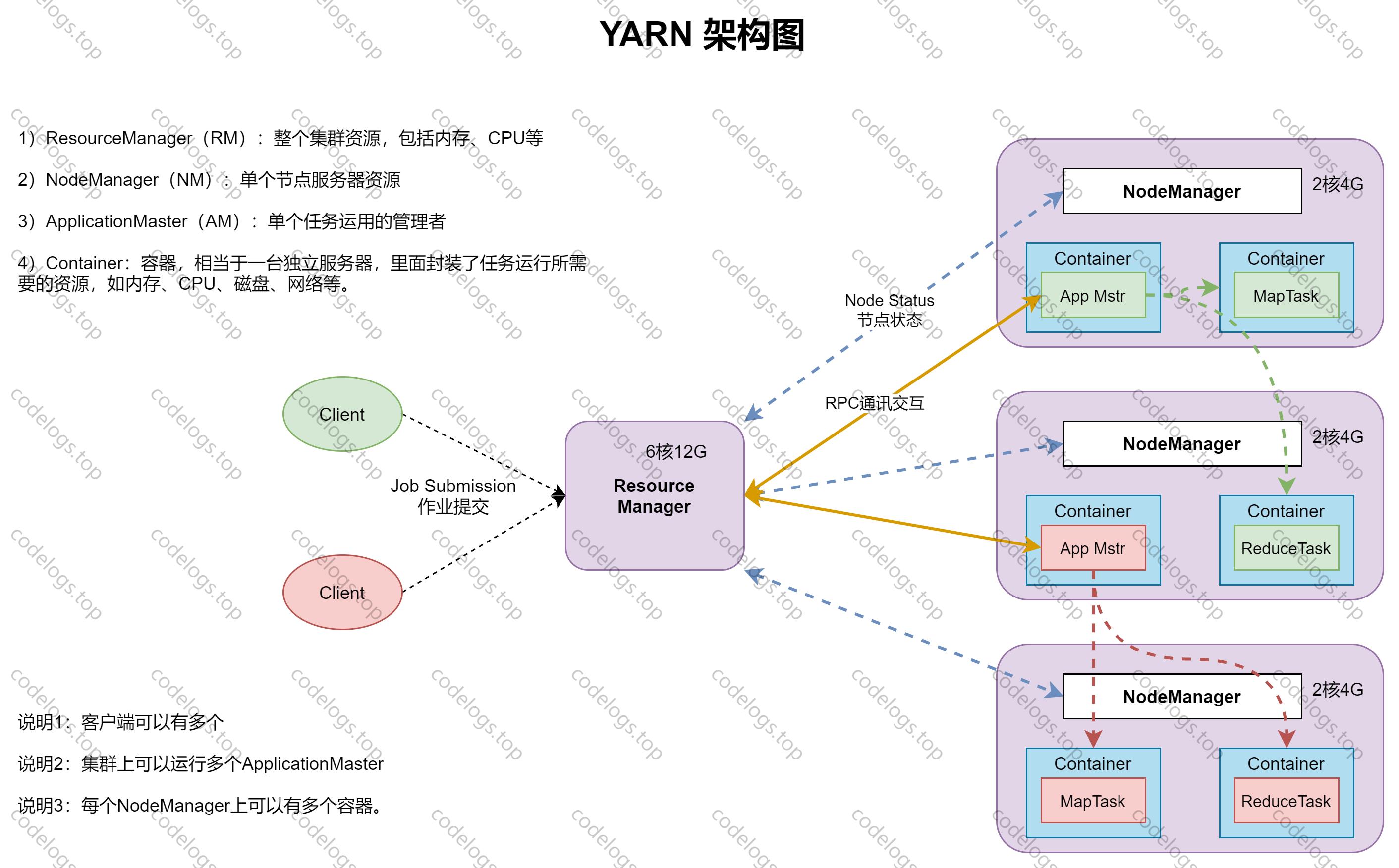
组件二:YARN
YARN 的全称是 Yet Another Resource Negotiator,意思是“另一种资源调度器“。Yarn从整体上还是属于主从体系。
Master(ResourceManager)/Slave(NodeManager)
应用程序与YARN交互流程:
第一步:用户向YARN中提交应用程序,其中包括ApplicationManager程序。
第二步:ResourceManager为该应用程序分配第一个Container,并与对应的NodeManager通讯,并要求它在这个Container中启动应用程序的ApplicationMaster。
第三步:ApplicationMaster首先向ResourceManager注册,完成后用户可以直接通过ResourceManager查看应用程序的运行状态,然后它将为各个任务申请资源,并监控运行状态,直到运行结束,即重复步骤4~7。
第四步:ApplicationMaster通过RPC协议向ResourceManager申请和领取资源。
第五步:一旦ApplicationManager申请到资源后,ResouceManager便与对应的NodeManager通信,要求它启动任务。
第六步:NodeManager接收到任务启动命令后,为任务设置好运行环境(可理解为Contianer)正式启动任务。
第七步:各个任务通过RPC协议向ApplicationMaster汇报自己的状态和进度。在应用程序运行过程中,用户可以随时通过RPC向ApplicationMaster查询应用程序当前的运行状态。
第八步:应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭自己。
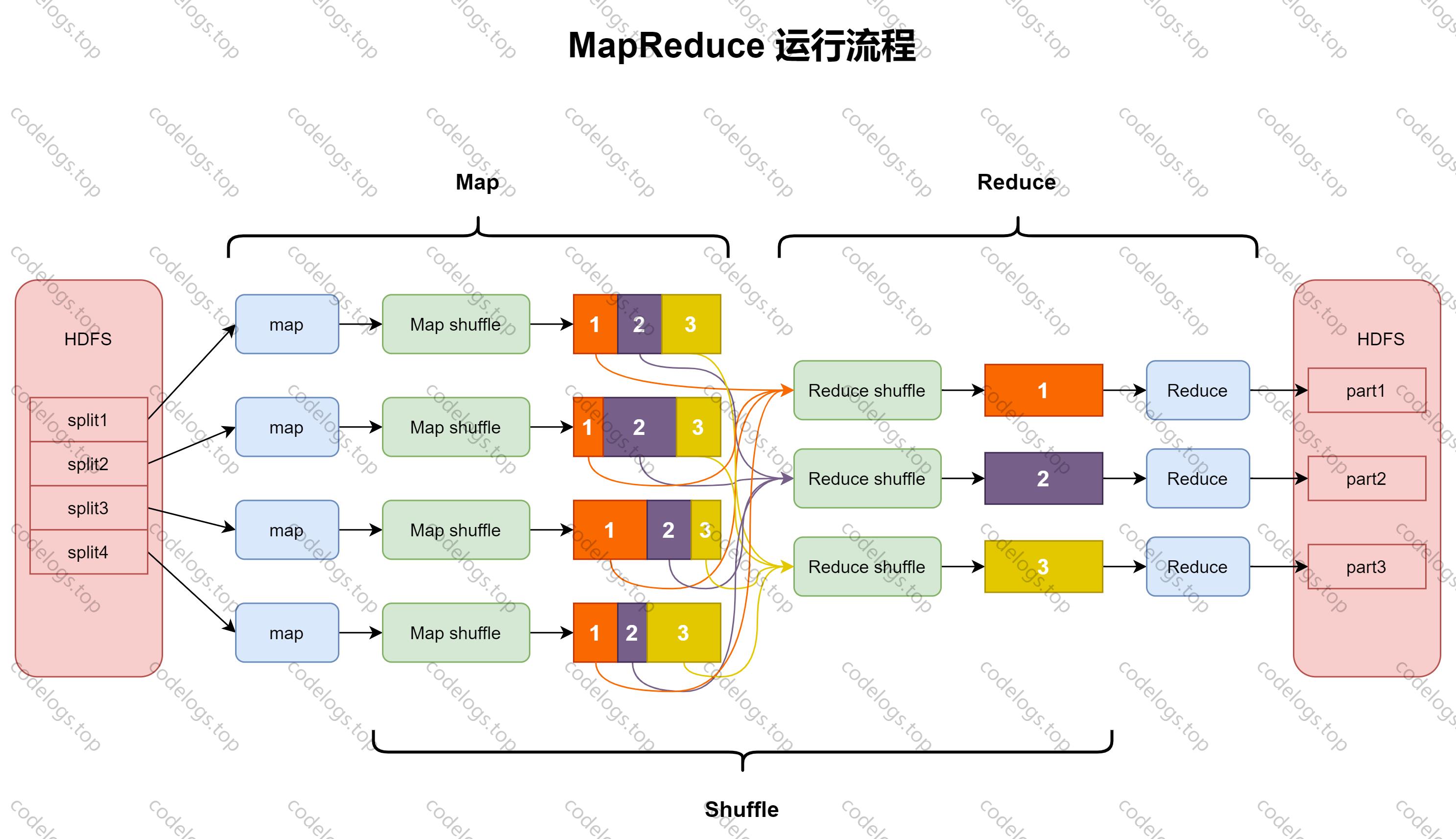
组件三:MapReduce
Hadoop MapReduce是一个分布式运算程序的软件框架,核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上。
在运行一个mapreduce任务时,任务过程被分为两个阶段:Map阶段和Reduce阶段。
Mapper 将一个任务拆分为若干个”小任务“,可以理解为任务计算规模的拆分缩小,相互之间几乎没有依赖关系,并行运算。
Reducer 将各个map阶段的结果进行汇总。
上述两者之间转换的过程称为Shuffle,其核心机制包括:数据分区,排序,局部聚合,缓存,拉取,合并。
三大组件关联关系
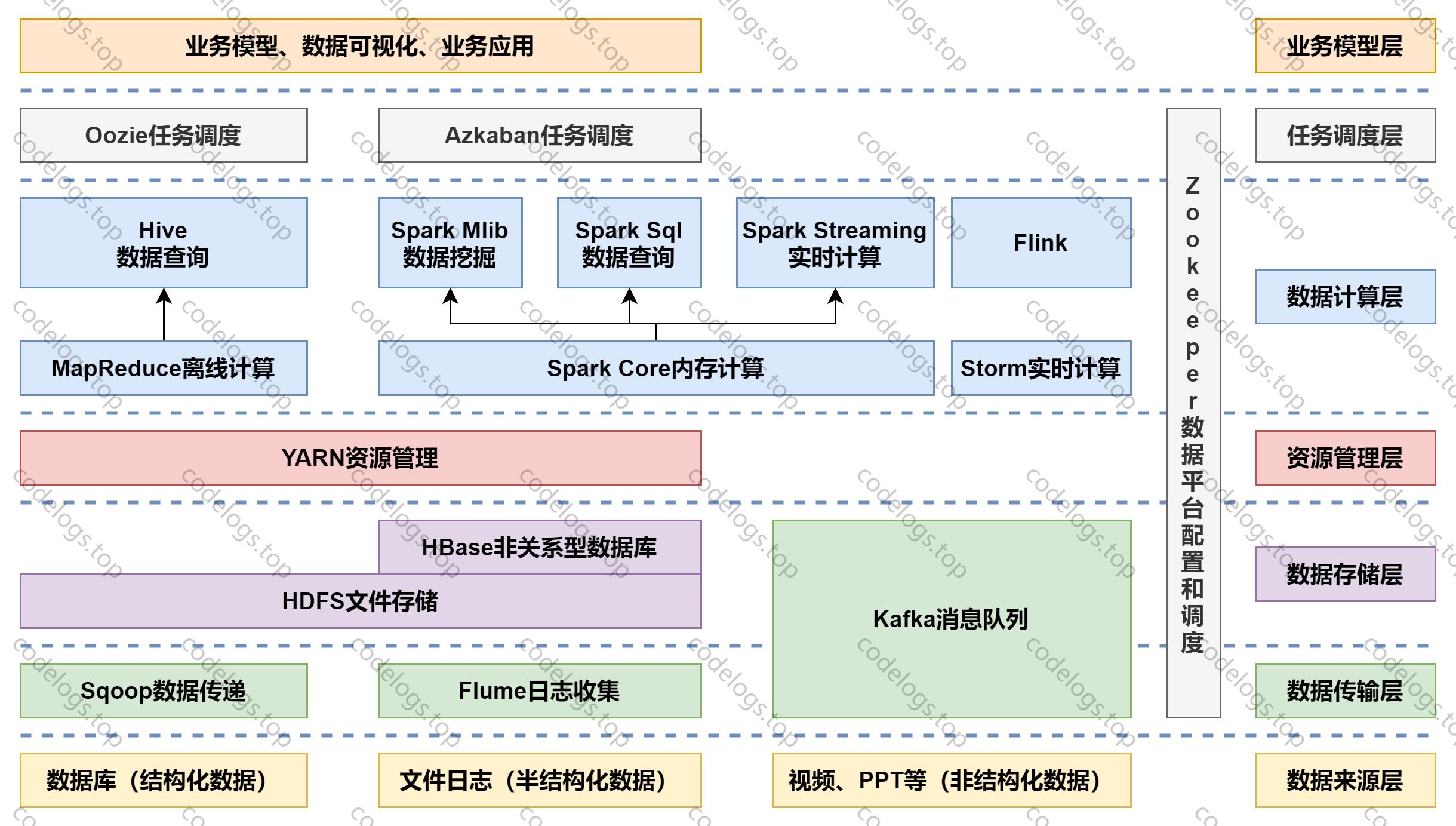
大数据技术生态体系
以上是关于Hadoop大数据框架思想及组成的主要内容,如果未能解决你的问题,请参考以下文章