Spark入门
Posted Lenskit
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark入门相关的知识,希望对你有一定的参考价值。
本篇是介绍Spark的入门系列文章,希望能帮你初窥Spark的大门。
一、 Spark概述
1 首先回答什么是Spark?
Spark是一种基于内存的快速,通用,可扩展的大数据计算引擎。
那有的同学可能会问,大数据计算引擎,MapReduce不就是吗?为什么又来个Spark?
其中最大的原因还是MapReduce自身的短板导致:
1. 基本运算规则从存储介质中采集数据,然后进行计算,最后将结果存储到介质中,所以主要应用于一次性计算,不适合于数据挖掘和机器学习这样的迭代计算和图形挖掘计算;
2. MR基于文件存储介质的操作(涉及大量IO),所以性能非常的慢;
3. MR和Hadoop紧密耦合在一起,无法动态替换。
在大家急需一种新的计算引擎出现的情况下,Spark应运而生,不过Spark真正与Hadoop产生联系,还需要Yarn帮忙。
在2013年10月发布Hadoop2.X之前,Hadoop1.x是没有Yarn存在的,存储和计算紧密耦合,并且负责调度任务和资源的JobTracker苦不堪言,所有工作都堆在了它身上。在2.X之后,Yarn作为资源管理器闪亮登场,通过ResourceManager和NodeManager将任务调度和资源调度的职责分开,再通过ApplicationMaster和Cotainer,实现ResourceManager和NodeManager的解耦合。
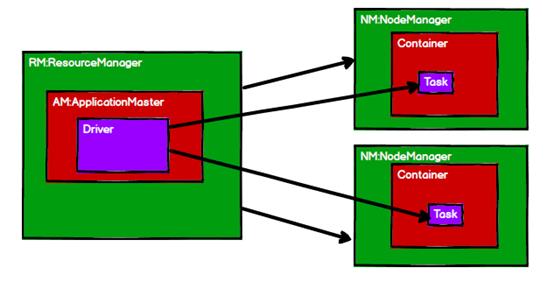
于是,Hadoop1.x中的hdfs+mr,变成了Hadoop2.x中的ResourceManager+ApplicationMaster+NodeManager,实现了存储和计算的解耦合,并且实现了Container(可以理解为电脑上装的虚拟机)中计算引擎的可插拔替换(MR,Spark,Tez,Presto等),至此,Spark可以一展身手了。
二、 Spark的四大组件
它的内置模块主要是以下四部分:
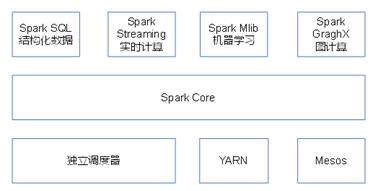
Spark Core:实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简称RDD)的API定义。
Spark SQL:是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用 SQL或者Apache Hive版本的SQL方言(HQL)来查询数据。Spark SQL支持多种数据源,比如Hive表、Parquet以及JSON等。
Spark Streaming:是Spark提供的对实时数据进行流式计算的组件。提供了用来操作数据流的API,并且与Spark Core中的 RDD API高度对应。
Spark MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。
集群管理器:Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark支持在各种集群管理器(Cluster Manager)上运行,包括Hadoop YARN、Apache Mesos,甚至可以在Spark自带的简易调度器上运行。
三、Spark运行模式
Spark的运行模式模式,一般分为Local模式,Standalone模式及Yarn模式(重点),Mesos模式(此模式国内基本不用)。
Local模式:运行在一台计算机上的模式,通常用于本机练手和测试;
Standalone模式:构建一个由Master+Slaver构成的Spark集群;
Yarn模式:Spark客户端直接连接Yarn,不需要额外构建Spark集群。有yarn-client和yarn-cluster两种模式,主要区别在于:Driver程序的运行节点。
yarn-client:Driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出yarn-cluster:Driver程序运行在由RM(ResourceManager)启动的AP(APPMaster)适用于生产环境。
Mesos模式(了解):Spark客户端直接连接Mesos;不需要额外构建Spark集群。国内应用比较少,更多的是运用yarn调度。
四 、Spark及相应环境安装
4.1 Mac:
下载安装jdk1.8并配置环境变量,下载scala的压缩包后解压(我使用的是scala-2.11.12),;以及spark-2.3.1-bin-hadoop2.7压缩包解压。
最后记得vim .bash_profile配置三者的环境:
export SCALA_HOME=/User/xxx/xxx/scala-2.11.12
export PATH=$PATH:$SCALA_HOME/bin
SPARK_LOCAL_IP=127.0.0.1
export JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk1.8_0_221.jdk/Contents/Home"
配置后更新环境变量source .bash_profile
若能在console输入java -version返回版本则为成功;
若能在console输出scala -version返回版本则为成功
操作完之后,在spark文件夹下,输入./bin/spark-shell若成功打印出:
Welcome to
____ __
/ __/__ ___ _____/ /__
_\\ \\/ _ \\/ _ `/ __/ '_/
/___/ .__/\\_,_/_/ /_/\\_\\ version 2.3.1
/_/
则表示成功。
4.2 Windows:
安装jdk1.8并配置环境变量,若能在cmd输入java -version返回版本则为成功;解压scala-2.11.12并配置环境变量,若能在cmd输出scala -version返回版本则为成功;解压spark-2.3.2-bin-hadoop2.7并配置环境变量,若能在cmd输入spark-shell出现welcome语则为成功;解压hadoop-2.7.7并配置环境变量(winutils.exe已放置hadoop-2.7.7\\bin目录下)
4.3 用IDEA跑WordCount,此案例等同于其他语言的Hello World。
打开IDEA,新建scala项目,选择之前安装的jdk和scala版本,进入项目后,右击项目,选择Open Module Settings,选择Libraries,点击加号,java,把我们解压缩的spark-2.3.2-bin-hadoop2.7的 jars目录下所有jar包选中,点击ok,给依赖包重取个名字,再次点击ok,这样所有依赖的jar包就都有了。
在你的项目下新建input文件夹,里面可以新建一个或两个txt文件,里面写上hello world,hello spark等文字,再新建一个WordCount的object文件,输入以下内容(我们的程序会自动读取input文件夹里的文件):
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object WordCount
def main(args: Array[String]): Unit =
// local模式
// 创建SparkConf对象
// 设定Spark计算框架的运行环境
// app id
val config:SparkConf = new SparkConf().setMaster("local[2]").setAppName("WordCount")
// 创建spark上下文对象
val sc = new SparkContext(config)
// 读取文件,将文件内容一行行的读取出来
val unit: RDD[String] = sc.textFile("input")
// 将一行行的数据分解为一个个的单词
val unit1: RDD[String] = unit.flatMap(_.split(" "))
// 为了统计方便,将单词数据进行结构的转换
val unit2: RDD[(String, Int)] = unit1.map((_,1))
// 对转换结构后的数据进行分组聚合
val unit3: RDD[(String, Int)] = unit2.reduceByKey(_+_)
// 收集结果并循环打印
unit3.collect().foreach(println)
右击run,如果能正确地在控制台打印出结果,那么恭喜你,你的第一个Spark程序已经运行成功了!
五、Spark中的rdd和算子
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象。代码中是一个抽象类,它代表一个不可变、可分区、里面的元素可并行计算的集合。
在Spark中,RDD被表示为对象,主要操作方法有转换及动作两大方面。
通过对象上的方法调用来对RDD进行转换。经过一系列的transformations定义RDD之后,就可以调用actions触发RDD的计算,action可以是向应用程序返回结果(count, collect等),或者是向存储系统保存数据(saveAsTextFile等)。在Spark中,只有遇到action,才会执行RDD的计算(即延迟计算),这样在运行时可以通过管道的方式传输多个转换。
5.1 RDD转换(transformations)
整体上分为Value类型和Key-Value类型;
a、Value类型主要有:
map(func);
mapPartitions(func);
mapPartitionsWithIndex(func);
flatMap(func);
glom;
groupBy(func);
filter(func);
sample(withReplacement,fraction,seed);
distinct([numTasks]));
coalesce(numPartitions);
sortBy(func,[ascending], [numTasks]);
pipe(command, [envVars])
b、双Value类型主要有:
union(otherDataset);
subtract (otherDataset);
intersection(otherDataset);
cartesian(otherDataset);
zip(otherDataset)
c、Key-Value类型主要有:
partitionBy;
groupByKey;
reduceByKey(func,[numTasks]);
aggregateByKey;
foldByKey;
combineByKey[C];
sortByKey([ascending], [numTasks]);
mapValues;
join(otherDataset, [numTasks]);
cogroup(otherDataset, [numTasks])
5.2 RDD的执行(actions),主要有:
reduce(func);
collect();
count();
first();
take(n);
takeOrdered(n);
aggregate;
fold(num)(func);
saveAsTextFile(path);
saveAsSequenceFile(path);
saveAsObjectFile(path);
countByKey();
foreach(func)
每个算子都有其不同的用法,由于篇幅关系,关于RDD的内容就先聊到这里,相关算子介绍请看下期~
以上是关于Spark入门的主要内容,如果未能解决你的问题,请参考以下文章