《Redis开发与运维》- API的使用-2-五种常用数据结构
Posted zczpeng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Redis开发与运维》- API的使用-2-五种常用数据结构相关的知识,希望对你有一定的参考价值。
《Redis开发与运维》- API的使用-2-五种常用数据结构
1:字符串(String)
字符串类型的值可以使字符串(简单的字符串;复杂的字符串如JSON、XML;数字如整数、浮点数;甚至二进制如:图片、音频、视频),但最大值不能超过512M。
常用命令
1:设置值:
>set key value [ex seconds] [px milliseconds] [nx|xx]
选项:
ex seconds:设置秒级过期时间。
px millisecods:设置毫秒级过期时间。
nx:键必须不存在才能设置成功,用于添加。
xx:与nx相反,必须存在才能设置成功,用于更新。
【setnx命令的使用场景:由于redis的单线程命令处理机制,如果有多个客户端同时执行setnx key value,根据特性只有一个客户端可以设置成功,所以可以作为分布式锁的一种实现。官方分布式锁的方法:https://redis.io/topics/distlock】
2:获取值:
> get key
【如果不存在则返回nil】
3:批量设置值
>mset key value [key value …]
4:批量获取值
>mget key [key …]
如果有些key不存在,则他的值是nil
5:计数
>incr key
incr命令用于对值做自增操作,返回结果分为三种情况:
值不是整数,返回错误。
值是整数,返回自增后的结果。
键不存在,按照值为0自增,返回结果为1。
除了incr命令,redis提供了decr(自减)、incrby(自增指定数字)、decrby(自减指定数字)、incrbyfloat(自增浮点数):
decr key
incrby key increment
decrby key decrement
incrbyfloat key increment
不常用命令
1:追加值
>append key value
【可以向字符串尾部追加值】
2:字符串长度
>strlen key
【每个中文占用3个字节】
3:设置并返回原值
>getset key value
内部编码
字符串类型的内部编码有3种:
int:8个字节的长整型
embstr:小于等于39个字节的字符串
raw:大于39个字节的字符串
【redis会根据当前值的类型和长度决定使用哪种内部编码实现】
使用场景
1:缓存功能
2:计数
【真实的技术系统要考虑的问题有很多:防作弊、按照不用维度计数、数据持久化到底层数据源等】
3:共享session
4:限速
【利用自增实现多长时间操作多少次】
2:哈希(hash)
命令
1:设置值
hset key field value
【redis也提供了 hsetnx命令,作用域为field】
2:获取值
hget key value
3:删除field
hdel key field [field … ]
hdel 会删除一个或多个field,返回结果为成功删除的field的个数。
4:计算field个数
hlen key
5:批量设置获取field-value
hmget key field [field …]
hmset key field value [field value …]
6:判断field是否存在
hexists key field
7:获取所有field
hkeys key
8:获取所有value
hvals key
9:获取所有field-value
hgetall key
【有渐进式遍历哈希类型的命令scan,可以避免hgetall 一个field很多的key造成的堵塞】
10:对field自增
hincrby key field
hincrbyfloat key field
内部编码
哈希类型的编码有两种:
1:ziplist(压缩列表)
当哈希类型元素少于 hash-max-ziplist-entries 配置(默认512个)、同时所有值都小于 hash-max-ziplist-value配置(默认64字节)时,redis会使用ziplist作为哈希的内部实现,结构更加紧凑,节省内存占用。
2:hashtable(哈希表)
当不满足上面ziplist的条件时,redis会使用hashtable作为内部实现,因为此时的ziplist的读写效率会下降,而hashtable的读写时间复杂度为O(1)。
3:列表(List)
列表中的每个字符串元素成为元素,一个列表最多可以存储2^32 -1个元素。可以对列表两端插入(push)和弹出(pop)。可以获取指定范围的元素列表,可以获取指定索引下标的元素等,可以充当栈和队列的角色。

命令
1:添加
右插:
rpush key value [value …]
左插:
lpush key value [value …]
向某个元素前或者后插入元素:
linsert key before|after pivot value
linsert命令会从列表中找到 pivot的元素, 在其前面或者后面 插入一个新的 元素value。
2:查找
获取指定范围内的元素列表
lrange key start end
索引下标从左到右分别是 0到N-1,但从右到左分别是 -1到 -N
lrange中的end选项包含了自身。
获取列表指定索引下标的元素
lindex key index
获取列表长度
llen key
删除
lpop key 删除最左边元素
rpop key 删除最右边元素
修改
修改指定索引下标的元素
lset key index newvalue
堵塞操作
blpop key [key …] timeout
brpop key [key …] timeout
【1:列表为空,如果timeout=3,那么客户端要等到3秒后返回,如果timeout=0,那么客户端会一直堵塞下去。
2:列表不为空,客户端会立即返回。】
内部编码
列表类型的内部编码有两种
ziplist:当元素个数小于 list-max-ziplist-entries配置(默认512个),同时小于 list-max-ziplist-value配置(默认64字节),redis会采用ziplist作为内部实现。
linkedlist:当元素无法满足ziplist的条件时。
使用场景
消息队列
lpush+brpop命令组合可以实现堵塞队列,生产者客户端用lpush从左侧列表插入元素,多个消费者客户端使用brpop命令堵塞式的抢到列表尾部元素,多个客户端保证了消费的负载均衡和高可用性。
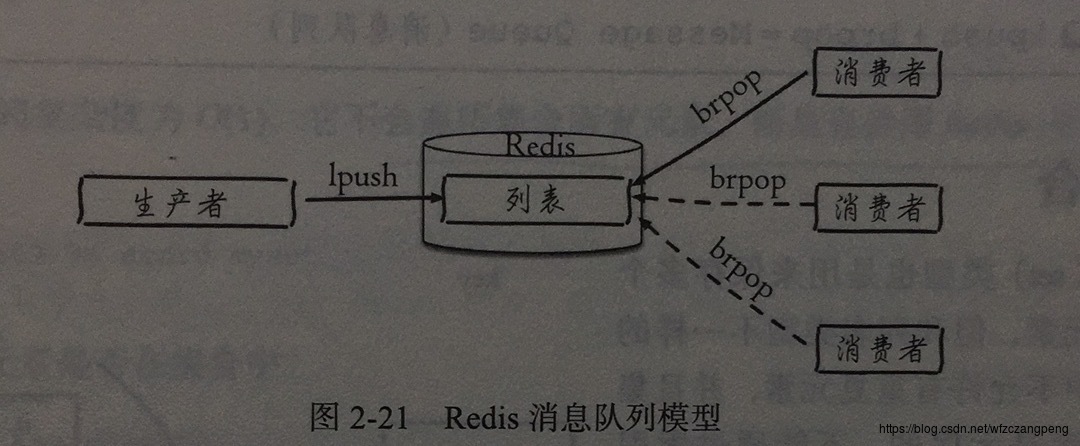
lrange 命令在列表两端性能较好,但是如果列表较大,获取列表中间范围的元素性能就会变差。quicklist内部编码,获取列表中间范围的元素时也可以高效完成。
实际上列表的使用场景很多:
lpush + lpop = Stack(栈)
lpush + rpop = Queue(队列)
4:集合(set)
不可重复,元素无序。一个集合中最多可以存储2^32 -1个元素,除了支持集合内的增删改查,还支持多个集合取交集、并集、差集,合理的使用好集合可以解决实际开发中的很多问题。
命令
集合内操作:
1:添加
sadd key element [element …]
2:删除
srem key element [element…]
【返回结果为成功删除元素的个数】
3:计算元素个数
scard key
【scard的时间复杂度是O(1),它不会遍历集合内的所有元素,而是直接使用Redis内部的变量】
4:判断元素是否在集合中
sismember key element
【如果给定的元素在集合内,返回1,否则返回0】
5:随机从集合中返回指定个数的元素
srandmember key [count]
【count是可选参数,不写默认为1】
6:从集合中随机弹出元素
spop key
【redis从3.2版本开始,spop也支持count参数】
【srandmember和spop都是随机从集合选出元素,两者不同的是spop命令会把选出的元素从集合中删除,srandmember则不会】
7:获取所有元素
smembers key
【smembers和lrange、hgetall都属于比较重的命令,如果元素比较多可能存在堵塞的可能性,这时候可以使用sscan来完成,后面介绍】
集合间操作:
1:求多个集合交集
sinter key [key …]
2:求多个集合的并集
sunion key [key …]
3:求多个集合的差集
sdiff key [key …]
4:将交集、并集、差集的结果保存
sinterstore destination key [key …]
sunionstore destination key [key …]
sdiffstore destination key [key…]
【集合间的运算在元素较多的情况下会比较耗时,所以 (原命令+store) 将集合间的交集、并集、差集的结果保存在destination key 中 】
内部编码
intset(整数集合):当集合中的元素都是整数且元素个数小于set-max-intset-entries配置(默认512个)时,redis会选用intset来作为集合的内部编码,减少内存使用。
hashtable(哈希表):当集合类型无法满足intset的条件时,Redis会使用hashtable作为集合的内部实现。
使用场景
比较典型的场景就是标签。
给用户添加标签,给标签添加用户 sadd
spop/srandmember = Random item(生成随机数,如抽奖)
sadd+sinter = Social Graph (社交需求)
5:有序集合(zset)
不可重复,但是元素可以排序,它不是和列表使用索引作为排序依据,而是给每一个元素设置一个score作为排序依据。
有序集合中的元素不能重复,但是score可以重复。
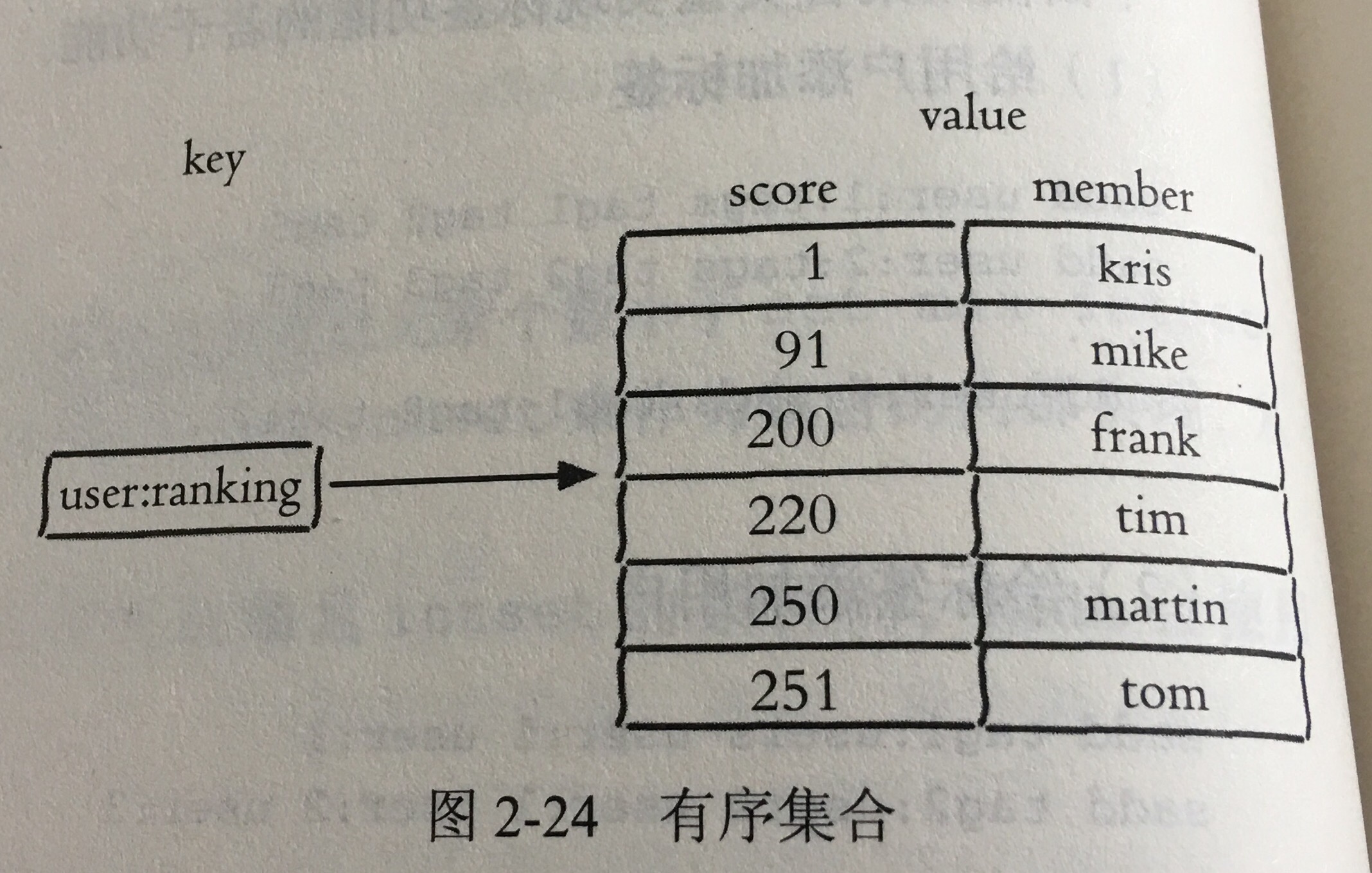

命令
集合内
1:添加
zadd key score member [score member …]
【返回结果代表成功添加成员的个数】
【Redis3.2为zadd命令添加了 nx,xx,ch,ch四个选项
nx : member必须不存在才可以设置成功,用于添加。
xx:member必须存在,才可以设置成功,用于更新。
ch:返回此次操作后,有序集合和分数发生变化的个数。
incr:对score做增加,相当于zincrby】
【有序集合相比集合提供了排序字段,但也产生了代价,zadd的时间复杂度为O(log(n)),sadd的时间复杂度为O(1)】
2:计算成员个数
zcard key
3:计算某个成员的分数
zscore key member
【成员不存在返回nil】
4:计算成员的排名
zrank key member 【分数从低到高返回排名】
zrevrank key member 【从高到低返回排名】
【排名从0开始计算】
5:删除成员
zrem key member [member …]
【返回成功删除的个数】
6:增加成员的分数
zincrby key increment member
:> zincrby user:ranking 9 tom
7:返回指定排名范围的成员
zrange key start end [withscoes]
zrevrange key start end [withscores]
【加上withscores同时会返回成员的分数】
8:返回指定分数范围的成员
zrangebyscore key min max [withscores] [limit offset count]
zrevrangebyscore key min max [withscores] [limit offset count]
【[limit offset count]选项可以限制输出的起始位置和个数】
【同时min和max 还支持开区间(小括号)和闭区间(中括号),-inf和 +inf分别代表无限小和无限大】
:>zrangebyscore user:ranking (200 +inf withscores
9:返回指定分数范围的成员个数
zcount key min max
10:删除指定排名内的升序元素
zremrangebyrank key start end
11:删除指定分数范围的成员
zremrangebyscore key min max
集合间操作
1:交集
2:并集
此处略。
内部编码
有序集合的内部编码有两种
1:ziplist(压缩列表) 当有序集合的元素个数小于 zset-max-ziplist-entries配置(默认128个),同时每个元素的值都小于zset-max-ziplist-value配置(默认64字节)时,Redis会使用ziplist来作为有序集合的内部实现,可以有效减少内存的使用。
2:skiplist(跳跃表) 当ziplist 条件不满足时,有序集合会使用skiplist作为内部实现,此时ziplist的读写效率会下降。
使用场景
有序集合比较典型的场景就是 排行榜。
如视频网站需要对用户上传的视频做排行榜,榜单的维度可以使多个方面的:按时间、播放量、获得赞数。
如添加用户赞数:zadd 和 zincrby
取消赞:zrem.
以上是关于《Redis开发与运维》- API的使用-2-五种常用数据结构的主要内容,如果未能解决你的问题,请参考以下文章