Hadoop核心--HDFS
Posted 走出自己的未来
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop核心--HDFS相关的知识,希望对你有一定的参考价值。
什么是HDFS?
HDFS(Hadoop Distributed File System),分布式文件存储系统。源自于Google的GFS论文,是GFS的克隆版。与其他分布式文件系统相比,它具有很高的容错能力,适合部署在廉价的机器上;另外它能提供高吞吐量的数据访问,适合海量数据的存储。
HDFS特点
易于扩展
运行在普通廉价的机器上,提供容错机制
为大量用户提供高性能的海量数据存储服务
HDFS架构体系
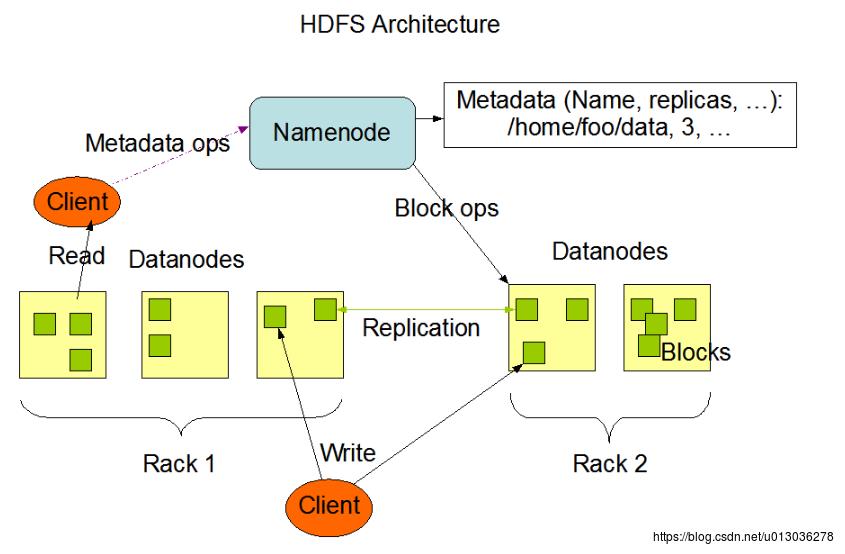
HDFS架构主要包括一个NameNode、多个DataNode、Block等。
一、数据块 Block
HDFS上的文件被切分成块进行存储,每个块的默认大小为64M,它是文件存储处理的逻辑单元。每个块有多个副本存储在不同的机器上,这是Hadoop的容错机制。
二、节点
1、NameNode
HDFS也是一种主从架构,而NameNode就属于主节点,主要负责管理文件系统的命名空间以及客户端对文件的访问。
2、DataNode
属于从节点,主要负责处理文件内容的读写请求。数据块在DataNode上是以文件形式存储在磁盘上,包括数据本身和元数据两部分。
3、SecondaryNameNode
辅助NameNode工作,它可以节省NameNode读取FsImage的时间(后面会介绍)
三、数据管理
NameNode中存储的是元数据,记录了数据所在DataNode的Block。当向HDFS写入数据时,首先是NameNode记录元数据,并告知要写入的DataNode节点地址,然后真正进行数据写入的是DataNode节点。而写入DataNode节点的block,也会复制备份到邻近DataNode节点上,这也是数据安全性的一个重要保障。
四、数据容错
读取数据时,即DataNode读取Block,首先会计算checksum,如果此时的checksum与初始建立的值不一致时,则认为该Block已损坏。此时会重新从最近的备份DataNode上读取Block,同时NameNode也会标记该Block已损坏,并从其他DataNode节点将数据进行修复,然后还需要继续验证其checksum。
五、启动流程
1、NameNode格式化,然后在持久化fsimage(镜像)和edits(日志)
2、启动NameNode,并且加载fsimage和edits文件
3、启动DataNode,并向NameNode进行注册,发送Block report
4、创建目录,此时会伴随fsimage和edits文件的更新
5、存放文件,也会伴随fsimage和edits文件的更新
以上就是HDFS启动的基本流程,在这个过程中,还有一个概念是安全模式。这是HDFS在启动过程中的一个文件保护模式,具体流程是,当NameNode启动时,需要加载fsimage和edits文件信息,其实就是更新NameNode元数据的过程。此时HDFS就进入了安全模式,在该模式下,只能从HDFS读取文件,但是无法写入,目的就是防止对NameNode载入产生影响。当NameNode加载fsimage和edits文件完成后,30s后会自动退出安全模式。
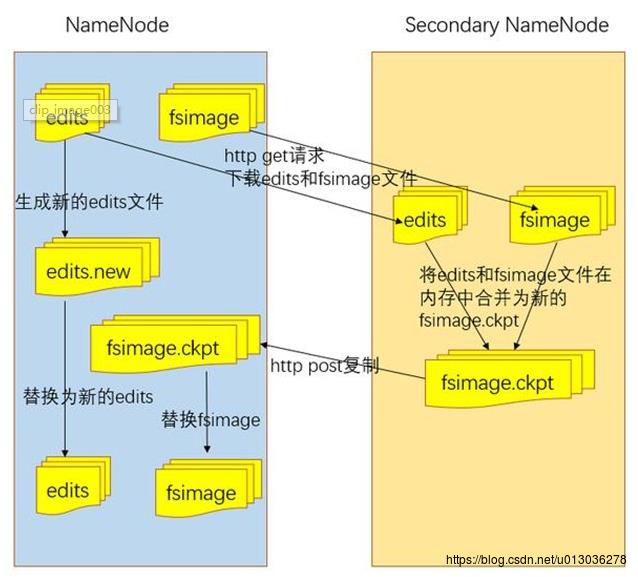
在介绍HDFS节点时,还提到了一个SecondaryNameNode节点,它的作用是辅助NameNode,具体的流程是:在NameNode启动时,需要加载fsimage和edits文件,那么如何缩短读取时间呢?SecondaryNameNode就起作用了,它会定期(默认1h)对fsimage和edits文件进行合并,这样当再次启动NameNode时,读取的是合并后的fsimage和edits文件,效率就提高了,读取时间相对缩短。具体流程如下:
以上是关于Hadoop核心--HDFS的主要内容,如果未能解决你的问题,请参考以下文章