不懂 ZooKeeper?没关系,这一篇给你讲的明明白白
Posted π大新
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了不懂 ZooKeeper?没关系,这一篇给你讲的明明白白相关的知识,希望对你有一定的参考价值。
本来想系统回顾下 ZooKeeper的,可是网上没找到一篇合自己胃口的文章,写的差不多的,感觉大部分都是基于《从Paxos到ZooKeeper 分布式一致性原理与实践》写的,所以自己读了一遍,加上项目中的使用,做个整理。加油,奥利给!

前言
面试常常被要求「熟悉分布式技术」,当年搞 “XXX管理系统” 的时候,我都不知道分布式系统是个啥。分布式系统是一个硬件或软件组件分布在不同的网络计算机中上,彼此之间仅仅通过消息传递进行通信和协调的系统。
计算机系统从集中式到分布式的变革伴随着包括分布式网络、分布式事务、分布式数据一致性等在内的一系列问题和挑战,同时也催生了一大批诸如ACID、CAP和 BASE 等经典理论的快速发展。
为了解决分布式一致性问题,涌现出了一大批经典的一致性协议和算法,最为著名的就是二阶段提交协议(2PC),三阶段提交协议(3PC)和Paxos算法。Zookeeper的一致性是通过基于 Paxos 算法的 ZAB 协议完成的。一致性协议之前的文章也有介绍:「走进分布式一致性协议」从2PC、3PC、Paxos 到 ZAB,这里就不再说了。
1. 概述
1.1 定义
ZooKeeper 官网是这么介绍的:”Apache ZooKeeper 致力于开发和维护一个支持高度可靠的分布式协调的开源服务器“
1.2 ZooKeeper是个啥
ZooKeeper 是 Apache 软件基金会的一个软件项目,它为大型「分布式计算」提供开源的分布式配置服务、同步服务和命名注册。
Zookeeper 最早起源于雅虎研究院的一个研究小组。在当时,研究人员发现,在雅虎内部很多大型系统基本都需要依赖一个类似的系统来进行分布式协调,但是这些系统往往都存在分布式单点问题。所以,雅虎的开发人员就试图开发一个通用的无单点问题的分布式协调框架,以便让开发人员将精力集中在处理业务逻辑上,Zookeeper 就这样诞生了。后来捐赠给了 Apache ,现已成为 Apache 顶级项目。
关于“ZooKeeper”这个项目的名字,其实也有一段趣闻。在立项初期,考虑到之前内部很多项目都是使用动物的名字来命名的(例如著名的Pig项目),雅虎的工程师希望给这个项目也取一个动物的名字。时任研究院的首席科学家 RaghuRamakrishnan 开玩笑地说:“再这样下去,我们这儿就变成动物园了!”此话一出,大家纷纷表示就叫动物园管理员吧一一一因为各个以动物命名的分布式组件放在一起,雅虎的整个分布式系统看上去就像一个大型的动物园了,而 Zookeeper 正好要用来进行分布式环境的协调一一于是,Zookeeper 的名字也就由此诞生了。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qZqUP9l7-1600152160349)(https://i01piccdn.sogoucdn.com/dc1f7cde4a337e77)]
ZooKeeper 是用于维护配置信息,命名,提供分布式同步和提供组服务的集中式服务。所有这些类型的服务都以某种形式被分布式应用程序使用。每次实施它们时,都会进行很多工作来修复不可避免的 bug 和竞争条件。由于难以实现这类服务,因此应用程序最初通常会跳过它们,这会使它们在存在更改的情况下变得脆弱并且难以管理。即使部署正确,这些服务的不同实现也会导致管理复杂。
ZooKeeper 的目标是将这些不同服务的精华提炼为一个非常简单的接口,用于集中协调服务。服务本身是分布式的,并且高度可靠。服务将实现共识,组管理和状态协议,因此应用程序不需要自己实现它们。
1.3 ZooKeeper工作机制
ZooKeeper 从设计模式角度来理解:就是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,ZK 就将负责通知已经在 ZK 上注册的那些观察者做出相应的反应,从而实现集群中类似 Master/Slave 管理模式。
1.4 特性
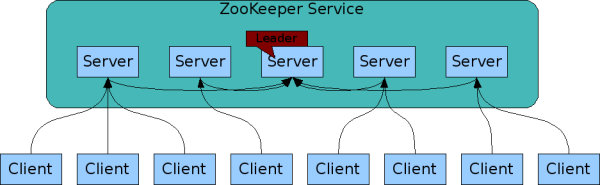
-
ZooKeeper:一个领导者(leader),多个跟随者(follower)组成的集群。
-
Leader 负责进行投票的发起和决议,更新系统状态。
-
Follower 用于接收客户请求并向客户端返回结果,在选举 Leader 过程中参与投票。
-
集群中只要有半数以上节点存活,Zookeeper 集群就能正常服务。
-
全局数据一致(单一视图):每个 Server 保存一份相同的数据副本,Client 无论连接到哪个 Server,数据都是一致的。
-
顺序一致性: 从同一客户端发起的事务请求,最终将会严格地按照顺序被应用到 ZooKeeper 中去。
-
原子性: 所有事务请求的处理结果在整个集群中所有机器上的应用情况是一致的,也就是说,要么整个集群中所有的机器都成功应用了某一个事务,要么都没有应用。
-
实时性,在一定时间范围内,client 能读到最新数据。
-
可靠性: 一旦一次更改请求被应用,更改的结果就会被持久化,直到被下一次更改覆盖。
1.5 设计目标
- 简单的数据结构 :Zookeeper 使得分布式程序能够通过一个共享的树形结构的名字空间来进行相互协调,即Zookeeper 服务器内存中的数据模型由一系列被称为
ZNode的数据节点组成,Zookeeper 将全量的数据存储在内存中,以此来提高服务器吞吐、减少延迟的目的。 - 可以构建集群 : Zookeeper 集群通常由一组机器构成,组成 Zookeeper 集群的每台机器都会在内存中维护当前服务器状态,并且每台机器之间都相互通信。
- 顺序访问 : 对于来自客户端的每个更新请求,Zookeeper 都会分配一个全局唯一的递增编号,这个编号反映了所有事务操作的先后顺序。
- 高性能 :Zookeeper 和 Redis 一样全量数据存储在内存中,100% 读请求压测 QPS 12-13W
1.6 数据结构
Zookeeper 数据模型的结构与 Unix 文件系统的结构相似,整体上可以看做是一棵树,每个节点称作一个 「ZNode」。每个 ZNode 默认能存储 1MB 的数据,每个 ZNode 都可以通过其路径唯一标识。

1.7 应用场景
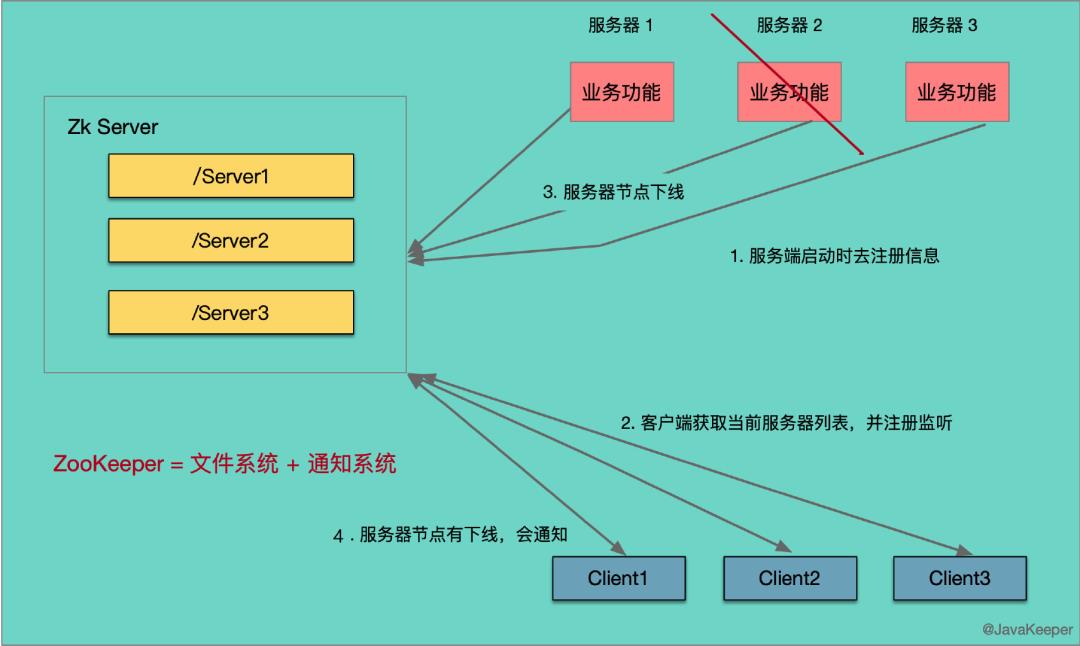
ZooKeeper 是一个典型的分布式数据一致性解决方案,分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能
统一命名服务
在分布式系统中,通过使用命名服务,客户端应用能够根据指定名字来获取资源或服务的地址,提供者等信息。被命名的实体通常可以是集群中的机器,提供的服务地址,进程对象等等——这些我们都可以统称他们为名字(Name)。其中较为常见的就是一些分布式服务框架(如RPC、RMI)中的服务地址列表。通过调用 Zookeeper 提供的创建节点的 API,能够很容易创建一个全局唯一的 path,这个 path 就可以作为一个名称。
阿里巴巴开源的分布式服务框架 Dubbo 就使用 ZooKeeper 来作为其命名服务,维护全局的服务地址列表。
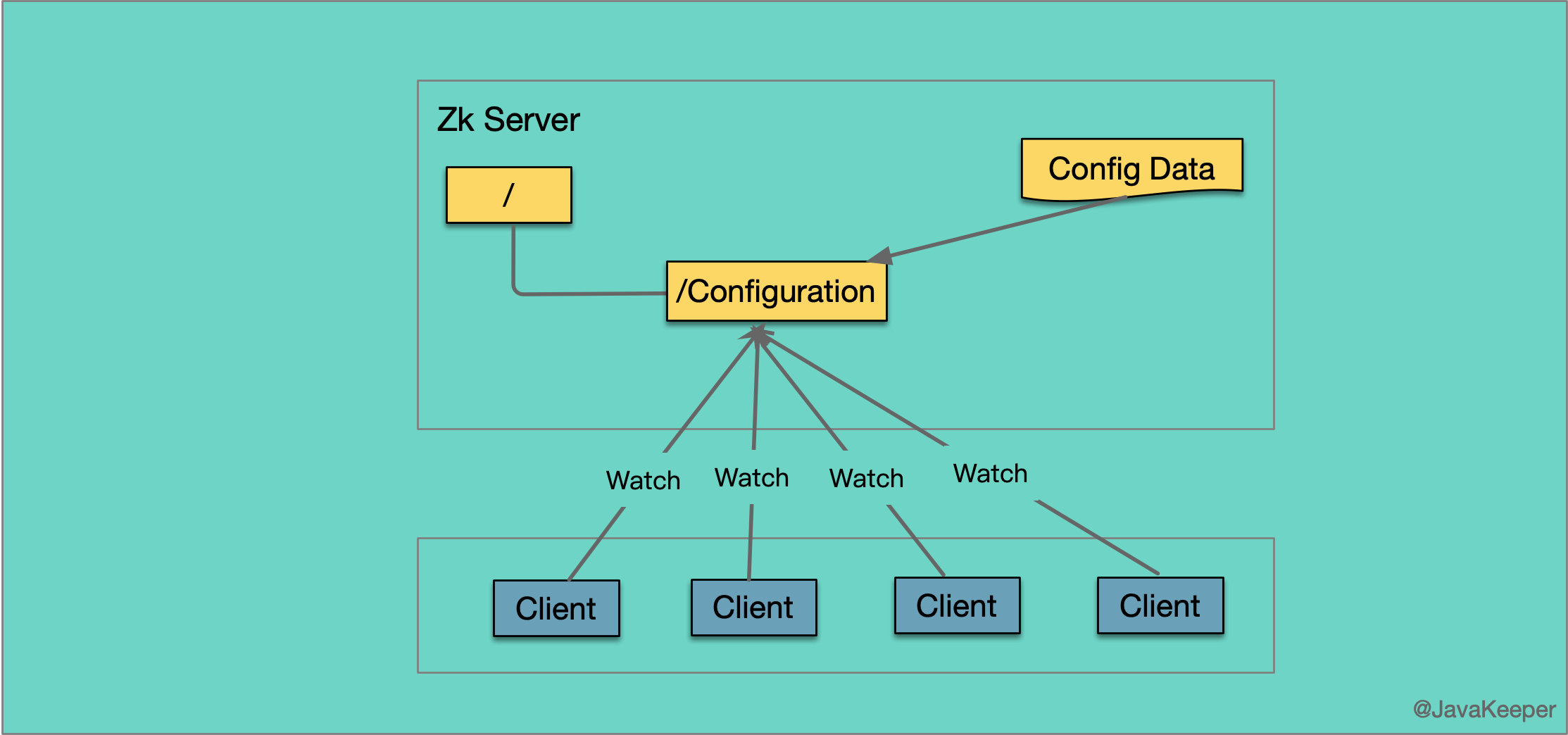
数据发布与订阅(配置中心)
发布与订阅模型,即所谓的配置中心,顾名思义就是发布者将数据发布到 ZooKeeper 节点上,供订阅者动态获取数据,实现配置信息的集中式管理和动态更新。例如全局的配置信息,服务式服务框架的服务地址列表等就非常适合使用。
-
分布式环境下,配置文件管理和同步是一个常见问题
-
一个集群中,所有节点的配置信息是一致的,比如 Hadoop 集群、集群中的数据库配置信息等全局配置
-
对配置文件修改后,希望能够快速同步到各个节点上。
-
-
配置管理可交由 ZooKeeper 实现
- 可将配置信息写入 ZooKeeper 上的一个 Znode
- 各个节点监听这个 Znode
- 一旦 Znode 中的数据被修改,ZooKeeper 将通知各个节点
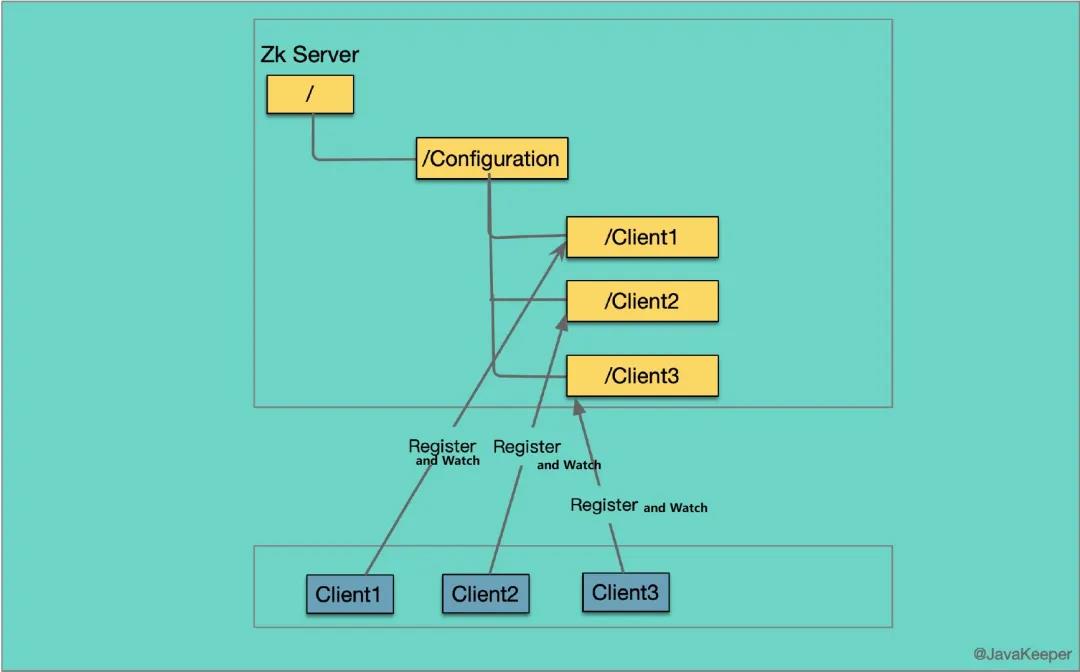
统一集群管理
所谓集群管理无在乎两点:是否有机器退出和加入、选举 Master。
管理节点
-
分布式环境中,实时掌握每个节点的状态是必要的,比如我们要知道集群中各机器状态、收集各个机器的运行时状态数据、服务器动态上下线等。
-
交由 ZooKeeper 实现的方式
- 可将节点信息写入 ZooKeeper 上的一个 Znode
- 监听这个 Znode 可获取它的实时状态变化
- 典型应用:HBase 中 Master 状态监控和选举。
Master选举
在分布式环境中,相同的业务应用分布在不同的机器上,有些业务逻辑(例如一些耗时的计算,网络I/O处理),往往只需要让整个集群中的某一台机器进行执行,其余机器可以共享这个结果,这样可以大大减少重复劳动,提高性能,于是这个master选举便是这种场景下的碰到的主要问题。
利用 Zookeeper 的强一致性,能够很好的保证在分布式高并发情况下节点的创建一定是全局唯一的,即:同时有多个客户端请求创建 /currentMaster 节点,最终一定只有一个客户端请求能够创建成功。Zookeeper 通过这种节点唯一的特性,可以创建一个 Master 节点,其他客户端 Watcher 监控当前 Master 是否存活,一旦 Master 挂了,其他机器再创建这样的一个 Master 节点,用来重新选举。
软负载均衡
分布式系统中,负载均衡是一种很普遍的技术,为了保证高可用性,通常同一个应用或同一个服务的提供方都会部署多份,达到对等服务。可以是硬件的负载均衡,如 F5,也可以是软件的负载,我们熟知的 nginx,或者这里介绍的 Zookeeper。
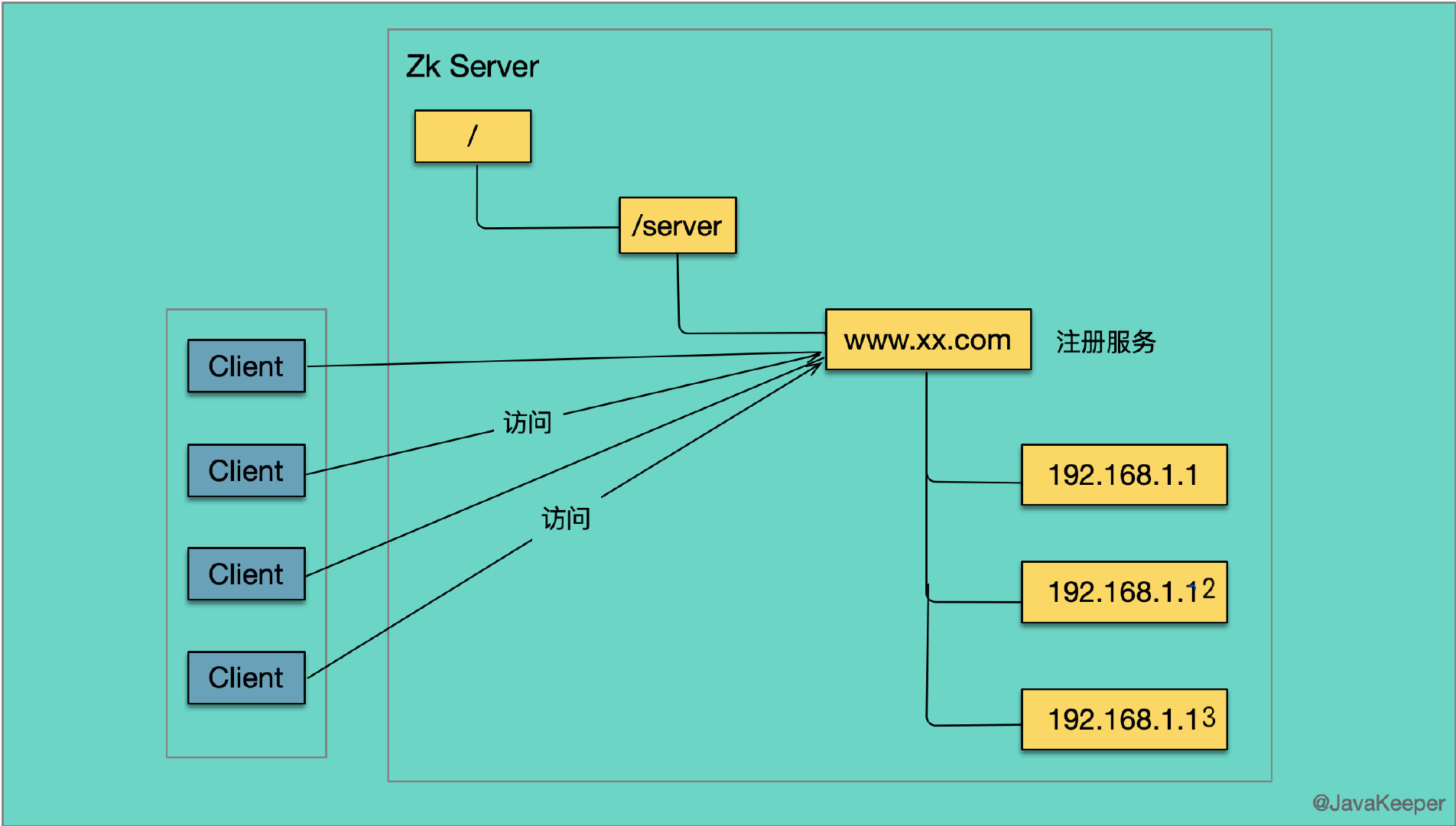
分布式协调/通知
Zookeeper 中特有的 「Watcher」 注册与异步通知机制,能够很好的实现分布式环境下不同机器,甚至不同系统之间的协调和通知,从而实现对数据变更的实时处理。
使用方法通常是不同系统都对 ZK 上同一个 znode 进行注册,监听 znode 的变化(包括 znode 本身内容及子节点的),其中一个系统 update 了 znode,那么另一个系统能够收到通知,并作出相应处理。
- 心跳检测中可以让检测系统和被检测系统之间并不直接关联起来,而是通过 ZK 上某个节点关联,减少系统耦合;
- 系统调度模式中,假设某系统有控制台和推送系统两部分组成,控制台的职责是控制推送系统进行相应的推送工作。管理人员在控制台作的一些操作,实际上是修改了 ZK 上某些节点的状态,而 ZK 就把这些变化通知给他们注册 Watcher 的客户端,即推送系统,于是,作出相应的推送任务。
分布式锁
分布式锁,这个主要得益于 ZooKeeper 为我们保证了数据的强一致性。
锁服务可以分为两类,一个是保持独占,另一个是控制时序。
-
所谓保持独占,就是所有试图来获取这个锁的客户端,最终只有一个可以成功获得这把锁。通常的做法是把 zk 上的一个 znode 看作是一把锁,通过
create znode的方式来实现。所有客户端都去创建/distribute_lock节点,最终成功创建的那个客户端也即拥有了这把锁。 -
控制时序,就是所有试图来获取这个锁的客户端,最终都是会被安排执行,只是有个全局时序了。做法和上面基本类似,只是这里
/distribute_lock已预先存在,客户端在它下面创建临时有序节点(这个可以通过节点的属性控制:CreateMode.EPHEMERAL_SEQUENTIAL来指定)。ZK 的父节点(/distribute_lock)维持一份 sequence,保证子节点创建的时序性,从而也形成了每个客户端的全局时序。
个人感觉还是用 Redis 实现分布式锁更加方便。
PS:阿里中间件团队:“其实,ZK 并非天生就是为这些应用场景设计的,都是后来众多开发者根据其框架的特性,利用其提供的一系列API接口(或者称为原语集),摸索出来的典型使用方法。”
2. Hello ZooKeeper
ZooKeeper 的三种部署方式:
- 单机模式,即部署在单台机器上的一个 ZK 服务,适用于学习、了解 ZK 基础功能
- 伪分布模式,即部署在一台机器上的多个(原则上大于3个)ZK 服务,伪集群,适用于学习、开发和测试
- 全分布式模式(复制模式),即在多台机器上部署服务,真正的集群模式,生产环境中使用
计划写三篇的,第二篇会实战 coding,运用各种 API,到时候再装集群,本节先来个单机玩~~
2.1 本地模式安装部署
2.1.1 安装前准备
-
安装 Jdk
-
拷贝或下载 Zookeeper 安装包到 Linux 系统下(这里有个小问题,如果你下载 ZK 版本是3.5+ 的话,要下载 bin.tar.gz,愚笨的我最先没看到官网说明,一顿操作各种报错找不到 Main 方法)
-
解压到指定目录
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
2.1.2 配置修改
-
将 zookeeper-3.5.7/conf 这个路径下的
zoo_sample.cfg修改为zoo.cfg;mv zoo_sample.cfg zoo.cfg -
打开 zoo.cfg 文件,修改 dataDir 路径:
dataDir=XXX/zookeeper-3.5.7/zkData
2.1.3 操作 Zookeeper
- 启动 Zookeeper:
bin/zkServer.sh start
/usr/local/bin/java
ZooKeeper JMX enabled by default
Using config: /home/sync360/test/apache-zookeeper-3.5.7-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
- 查看进程是否启动:
jps
4020 Jps
4001 QuorumPeerMain
- 查看状态:
bin/zkServer.sh status
/usr/local/bin/java
ZooKeeper JMX enabled by default
Using config: /home/apache-zookeeper-3.5.7-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: standalone
- 启动客户端:
bin/zkCli.sh
Connecting to localhost:2181
2020-03-25 15:41:19,112 [myid:] - INFO [main:Environment@109] - Client environment:zookeeper.version=3.5.7-f0fdd52973d373ffd9c86b81d99842dc2c7f660e, built on 02/10/2020 11:30 GMT
...
2020-03-25 15:41:19,183 [myid:] - INFO [main:ClientCnxn@1653] - zookeeper.request.timeout value is 0. feature enabled=
Welcome to ZooKeeper!
...
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
-
退出客户端:
quit -
停止 Zookeeper:
bin/zkServer.sh stop
2.2 常用命令
| 命令基本语法 | 功能描述 |
|---|---|
| help | 显示所有操作命令 |
| ls path [watch] | 使用 ls 命令来查看当前znode中所包含的内容 |
| ls2 path [watch] | 查看当前节点数据并能看到更新次数等数据 |
| create | 普通创建-s 含有序列-e 临时(重启或者超时消失) |
| get path [watch] | 获得节点的值 |
| set | 设置节点的具体值 |
| stat | 查看节点状态 |
| delete | 删除节点 |
| rmr | 递归删除节点 |
ls 查看当前 zk 中所包含的内容
[zk: localhost:2181(CONNECTED) 1] ls /
[lazyegg, zookeeper]
create 创建一个新的 znode
[zk: localhost:2181(CONNECTED) 2] create /test
Created /test
get 查看新的 znode 的值
[zk: localhost:2181(CONNECTED) 4] get /test
null
可以看到值为 null,我们刚才设置了一个没有值的节点,也可以通过 create /zoo dog 直接创建有内容的节点
set 对 zk 所关联的字符串进行设置
set /test hello
delete 删除节点
delete /test
2.3 配置参数解读
在 Zookeeper 的设计中,如果是集群模式,那所有机器上的 zoo.cfg 文件内容应该都是一致的。
Zookeeper 中的配置文件 zoo.cfg 中参数含义解读如下:
-
tickTime =2000:通信心跳数
Zookeeper 使用的基本时间,服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime时间就会发送一个心跳,时间单位为毫秒
它用于心跳机制,并且设置最小的 session 超时时间为两倍心跳时间。(session的最小超时时间是2*tickTime);
-
initLimit =10:主从初始通信时限,集群中的 Follower 跟随者服务器与 Leader 领导者服务器之间初始连接时能容忍的最多心跳数(tickTime的数量),用它来限定集群中的 ZK 服务器连接到 Leader 的时限;
-
syncLimit =5:主从同步通信时限,集群中 Leader 与 Follower 之间的最大响应时间单位,假如响应超过
syncLimit * tickTime,Leader 认为 Follwer 死掉,从服务器列表中删除 Follwer; -
dataDir:数据文件目录+数据持久化路径;
-
clientPort =2181:客户端连接端口
3. 你要知道的概念
- ZooKeeper 本身就是一个分布式程序(只要半数以上节点存活,ZooKeeper 就能正常服务)。
- 为了保证高可用,最好是以集群形态来部署 ZooKeeper,这样只要集群中大部分机器是可用的(能够容忍一定的机器故障),那么 ZooKeeper 本身仍然是可用的。
- ZooKeeper 将数据保存在内存中,这也就保证了高吞吐量和低延迟(但是内存限制了能够存储的容量不太大,此限制也是保持 znode 中存储的数据量较小的进一步原因)。
- ZooKeeper 是高性能的。 在“读”多于“写”的应用程序中尤其的高性能,因为“写”会导致所有的服务器间同步状态。(“读”多于“写”是协调服务的典型场景。)
- ZooKeeper 底层其实只提供了两个功能:
- 管理(存储、读取)用户程序提交的数据
- 为用户程序提交数据节点监听服务
这里引入一个简单的例子,逐个介绍一些 ZK 中的概念。
在分布式系统中经常会遇到这种情况,多个应用读取同一个配置。例如:Client1,Client2 两个应用都会读取配置 B 中的内容,一旦 B 中的内容出现变化,就会通知 Client1 和 Client2。
一般的做法是在 Client1,Client2 中按照时钟频率询问 B 的变化,或者使用观察者模式来监听 B 的变化,发现变化以后再更新两个客户端。那么 ZooKeeper 如何协调这种场景?
这两个客户端连接到 ZooKeeper 的服务器,并获取其中存放的 B。保存 B 值的地方在 ZooKeeper 服务端中就称为 ZNode。
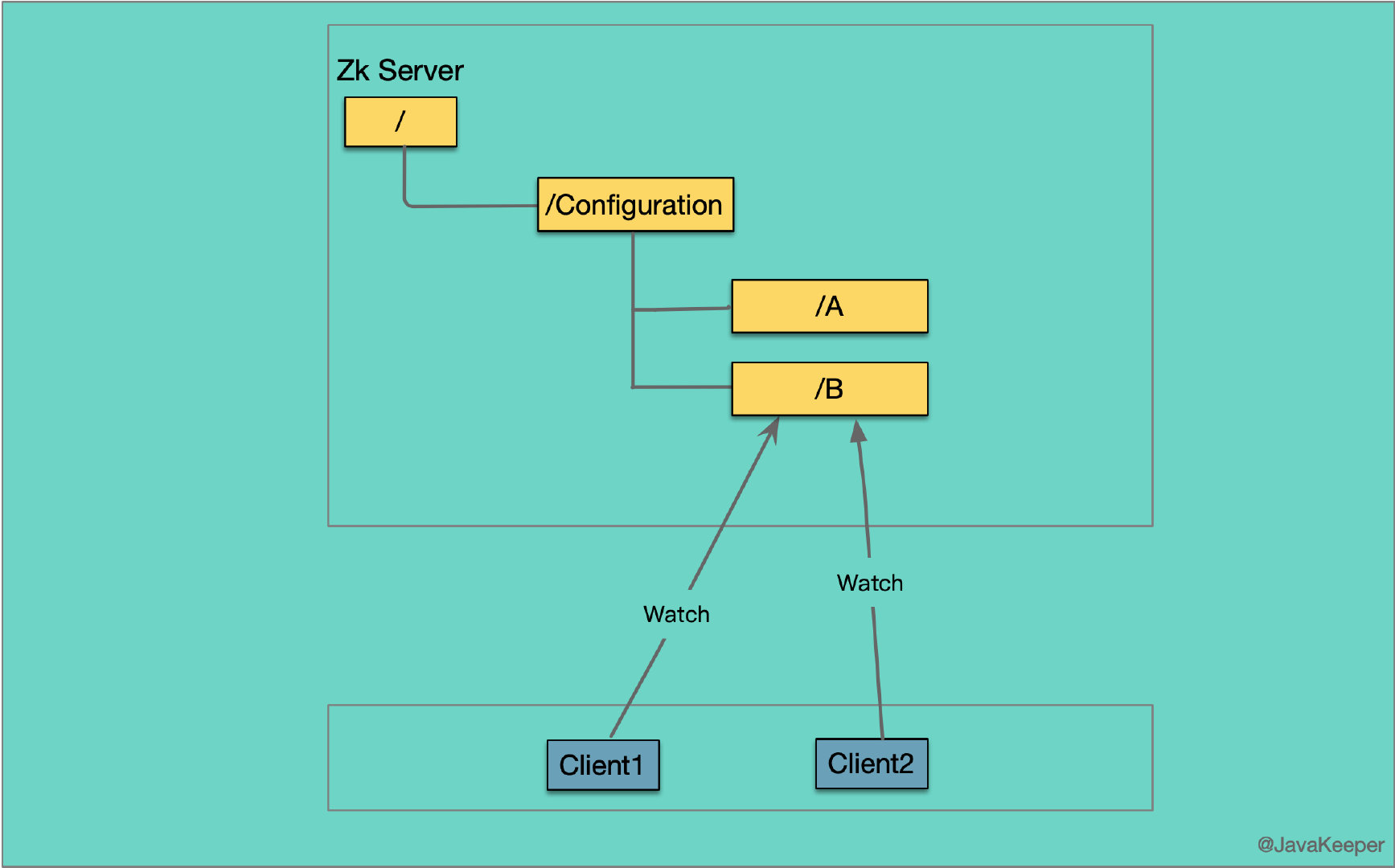
3.1 数据节点(Znode)
在谈到分布式的时候,我们通常说的“节点"是指组成集群的每一台机器。然而,在 Zookeeper 中,“节点"分为两类,第一类同样是指构成集群的机器,我们称之为「机器节点」;第二类则是指数据模型中的数据单元,我们称之为「数据节点」一一ZNode。上图中的 A、B 就是一个数据结点。
Zookeeper 将所有数据存储在内存中,数据模型是一棵树(Znode Tree),由斜杠(/)进行分割的路径,就是一个 Znode,例如 /Configuration/B。每个 Znode 上都会保存自己的数据内容,同时还会保存一系列属性信息。
在 Zookeeper 中,Znode 可以分为持久节点和临时节点两类。
- 所谓持久节点是指一旦这个 ZNode 被创建了,除非主动进行 ZNode 的移除操作,否则这个 ZNode 将一直保存在 Zookeeper 上。
- 而临时节点就不一样了,它的生命周期和客户端会话绑定,一旦客户端会话失效,那么这个客户端创建的所有临时节点都会被移除。
另外,ZooKeeper 还允许用户为每个节点添加一个特殊的属性:**SEQUENTIAL。**也被叫做 顺序结点,一旦节点被标记上这个属性,那么在这个节点被创建的时候,Zookeeper 会自动在其节点名后面追加上一个整型数字,这个整型数字是一个由父节点维护的自增数字。
3.2 事件监听器(Watcher)
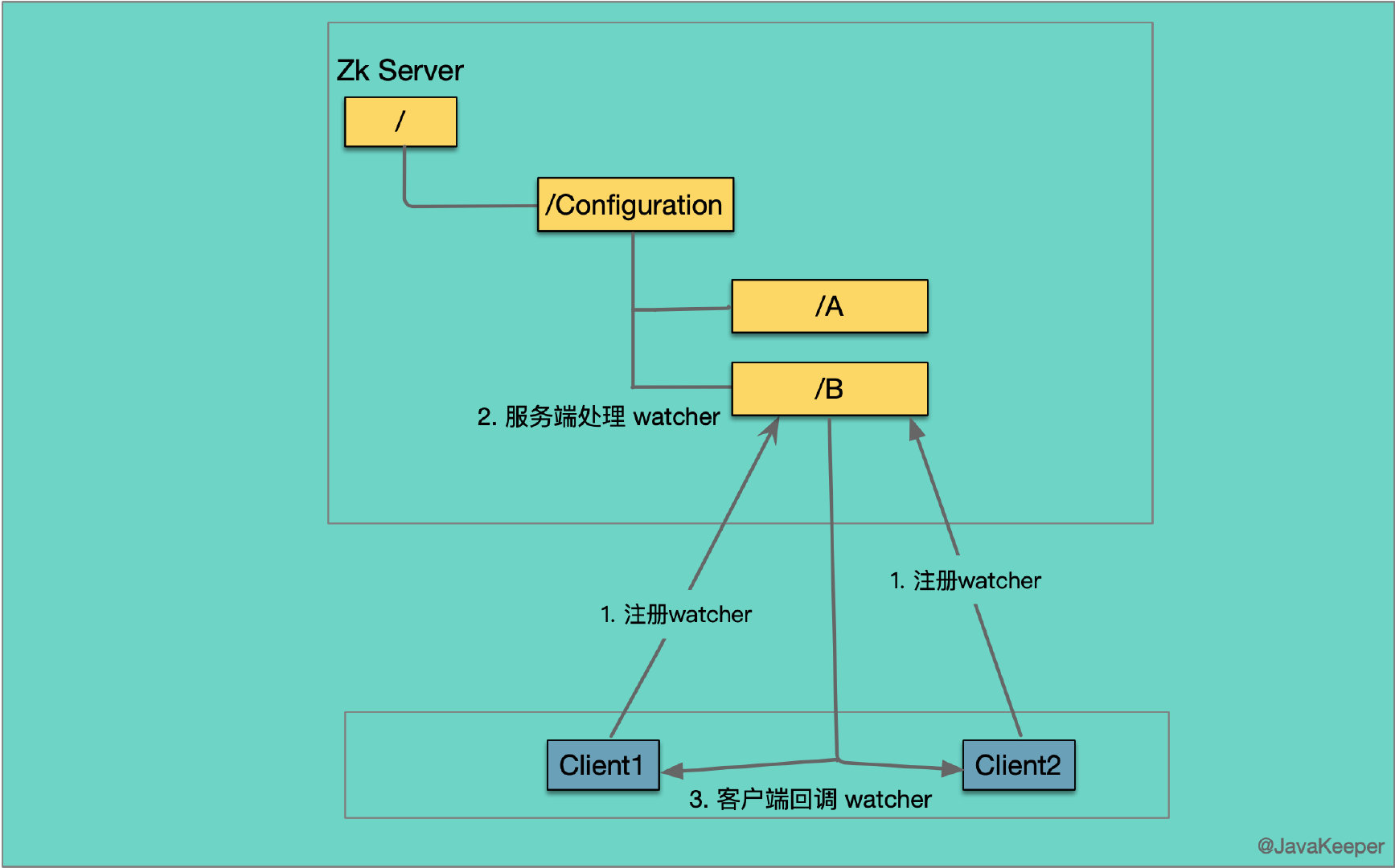
上面说了 ZooKeeper 用来存放数据的 ZNode,并且把 B 的值存储在里面。如果 B 被更新了,两个客户端(Client1、Client2)如何获得通知呢?
Zookeeper 允许用户在指定节点上注册一些 Watcher,当 Znode 发生变化时,将触发并删除一个 watch。当 watch 被触发时客户端会收到一个数据包,指示 znode 已经被修改。如果客户端和 ZooKeeper 服务器之间的连接中断,客户端将收到本地通知。该机制是 Zookeeper 实现分布式协调服务的重要特性。
3.6.0中的新增功能:客户端还可以在 znode 上设置永久性的递归监视,这些监视在触发时不会删除,并且会以递归方式触发已注册 znode 以及所有子 znode 的更改。
ZooKeeper 客户端(Client)会在指定的节点(/Configuration/B)上注册一个 Watcher,ZNode 上的 B 被更新的时候,服务端就会通知 Client1 和 Client2。
3.3 版本
有了 Watcher 机制,就可以实现分布式协调/通知了,假设有这样的场景,两个客户端同时对 B 进行写入操作,这两个客户端就会存在竞争关系,通常需要对 B 进行加锁操作,ZK 通过 version 版本号来控制实现乐观锁中的“写入校验”机制。
Zookeeper 的每个 ZNode 上都会存储数据,对应于每个 ZNode,Zookeeper 都会为其维护一个叫作 Stat 的数据结构,Stat 中记录了这个 ZNode 的三个数据版本,分别是 version(当前ZNode的版本)、cversion(当前ZNode 子节点的版本)和 aversion(当前ZNode的ACL版本)。
znode 里都有些啥呢?
3.4 Stat 结构体
Znodes 维护了一个 stat 结构,其中包含数据更改、ACL更改的版本号、时间戳等。
| 状态属性 | 说明 |
|---|---|
| czxid | 创建节点的事务zxid。 每次修改 ZK 状态都会收到一个zxid形式的时间戳,也就是 ZK 事务ID。事务ID是 ZK 中所有修改总的次序。每个修改都有唯一的zxid,如果zxid1小于zxid2,那么zxid1在zxid2之前发生 |
| ctime | znode被创建的毫秒数(从1970年开始) |
| mzxid | znode最后更新的事务zxid |
| mtime | znode最后修改的毫秒数(从1970年开始) |
| pzxid | znode最后更新的子节点zxid |
| version | 数据节点版本号 |
| cversion | 子节点版本号,znode子节点修改次数 |
| aversion | znode访问控制列表的变化号 |
| ephemeralOwner | 如果是临时节点,这个是znode拥有者的session id。如果不是临时节点则是0 |
| dataLength | znode的数据长度 |
| numChildren | znode子节点数量 |
3.5 会话(Session)
Session 指的是 ZooKeeper 服务器与客户端会话。
在 ZooKeeper 中,一个客户端连接是指客户端和服务器之间的一个 TCP 长连接。客户端启动的时候,首先会与服务器建立一个 TCP 连接,从第一次连接建立开始,客户端会话的生命周期也开始了。通过这个连接,客户端能够通过心跳检测与服务器保持有效的会话,也能够向 Zookeeper 服务器发送请求并接受响应,同时还能够通过该连接接收来自服务器的 Watch 事件通知。
Session 作为会话实体,用来代表客户端会话,其包括 4 个属性:
- SessionID,用来全局唯一识别会话;
- TimeOut,会话超时事件。客户端在创造 Session 实例的时候,会设置一个会话超时的时间。当由于服务器压力太大、网络故障或是客户端主动断开连接等各种原因导致客户端连接断开时,只要在 sessionTimeout 规定的时间内能够重新连接上集群中任意一台服务器,那么之前创建的会话仍然有效;
- TickTime,下次会话超时时间点;
- isClosing,当服务端如果检测到会话超时失效了,会通过设置这个属性将会话关闭。
3.6 ACL
Zookeeper 采用 ACL(Access Control Lists)策略来进行权限控制,类似于 UNIX 文件系统的权限控制。Zookeeper 定义了如下 5 种权限:
- CREATE: 创建子节点的权限
- READ: 获取节点数据和子节点列表的权限
- WRITE: 更新节点数据的权限
- DELETE: 删除子节点的权限
- ADMIN: 设置节点ACL的权限
其中尤其需要注意的是,CREATE 和 DELETE 这两种权限都是针对子节点的权限控制。
3.7 集群角色
最典型集群模式:Master/Slave 模式(主备模式)。在这种模式中,通常 Master 服务器作为主服务器提供写服务,其他的 Slave 从服务器通过异步复制的方式获取 Master 服务器最新的数据提供读服务。
但是,在 ZooKeeper 中没有选择传统的 Master/Slave 概念,而是引入了Leader、Follower 和 Observer 三种角色。
- Leader: 为客户端提供读和写的服务,负责投票的发起和决议,更新系统状态
- Follower: 为客户端提供读服务,如果是写服务则转发给 Leader。在选举过程中参与投票
- Observer: 为客户端提供读服务器,如果是写服务则转发给 Leader。不参与选举过程中的投票,也不参与“过半写成功”策略。在不影响写性能的情况下提升集群的读性能。此角色是在 zookeeper3.3 系列新增的角色。
server 状态
- LOOKING:寻找Leader状态
- LEADING:领导者状态,表明当前服务器角色是 Leader
- FOLLOWING:跟随者状态,表明当前服务器角色是 Follower
- OBSERVING:观察者状态,表明当前服务器角色是 Observer
选举机制

- 服务器1启动,此时只有它一台服务器启动了,它发出去的报文没有任何响应,所以它的选举状态一直是LOOKING 状态。
- 服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以 id 值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1、2还是继续保持 LOOKING 状态。
- 服务器3启动,根据前面的理论分析,服务器3成为服务器1、2、3中的老大,而与上面不同的是,此时有三台服务器选举了它,所以它成为了这次选举的Leader。
- 服务器4启动,根据前面的分析,理论上服务器4应该是服务器1、2、3、4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能接受当小弟的命了。
- 服务器5启动,同4一样当小弟。
Watcher 监听器
Zookeeper 中最有特色且最不容易理解的是监视(Watches)。
Zookeeper 所有的读操作——getData(),getChildren(), 和 exists() 都可以设置监视(watch),监视事件可以理解为一次性的触发器, 官方定义如下: a watch event is one-time trigger, sent to the client that set the watch, which occurs when the data for which the watch was set changes。对此需要作出如下理解:
-
One-time trigger(一次性触发)
当设置监视的数据发生改变时,该监视事件会被发送到客户端,例如,如果客户端调用了
getData("/znode1", true)并且稍后/znode1节点上的数据发生了改变或者被删除了,客户端将会获取到/znode1发生变化的监视事件,而如果/znode1再一次发生了变化,除非客户端再次对/znode1设置监视,否则客户端不会收到事件通知。(3.6之后可以设置永久监视) -
Sent to the client(发送至客户端)
Zookeeper 客户端和服务端是通过 socket 进行通信的,由于网络存在故障,所以监视事件很有可能不会成功到达客户端,监视事件是异步发送至监视者的,Zookeeper 本身提供了保序性(ordering guarantee):即客户端只有首先看到了监视事件后,才会感知到它所设置监视的 znode 发生了变化(a client will never see a change for which it has set a watch until it first sees the watch event)。 网络延迟或者其他因素可能导致不同的客户端在不同的时刻感知某一监视事件,但是不同的客户端所看到的一切具有一致的顺序。
-
The data for which the watch was set(被设置 watch 的数据)
这意味着 znode 节点本身具有不同的改变方式。你也可以想象 Zookeeper 维护了两条监视链表:数据监视和子节点监视(data watches and child watches),
getData()和exists()设置数据监视,getChildren()设置子节点监视。 或者,你也可以想象 Zookeeper 设置的不同监视返回不同的数据,getData()和exists()返回 znode 节点的相关信息,而getChildren()返回子节点列表。因此,setData()会触发设置在某一节点上所设置的数据监视(假定数据设置成功),而一次成功的create()操作则会触发当前节点上所设置的数据监视以及父节点的子节点监视。一次成功的delete()操作将会触发当前节点的数据监视和子节点监视事件,同时也会触发该节点父节点的child watch。
Zookeeper 中的监视是轻量级的,因此容易设置、维护和分发。当客户端与 Zookeeper 服务器端失去联系时,客户端并不会收到监视事件的通知,只有当客户端重新连接后,若在必要的情况下,以前注册的监视会重新被注册并触发,对于开发人员来说这通常是透明的。只有一种情况会导致监视事件的丢失,即:通过 exists() 设置了某个 znode 节点的监视,但是如果某个客户端在此 znode 节点被创建和删除的时间间隔内与 zookeeper 服务器失去了联系,该客户端即使稍后重新连接 zookeepe r服务器后也得不到事件通知。
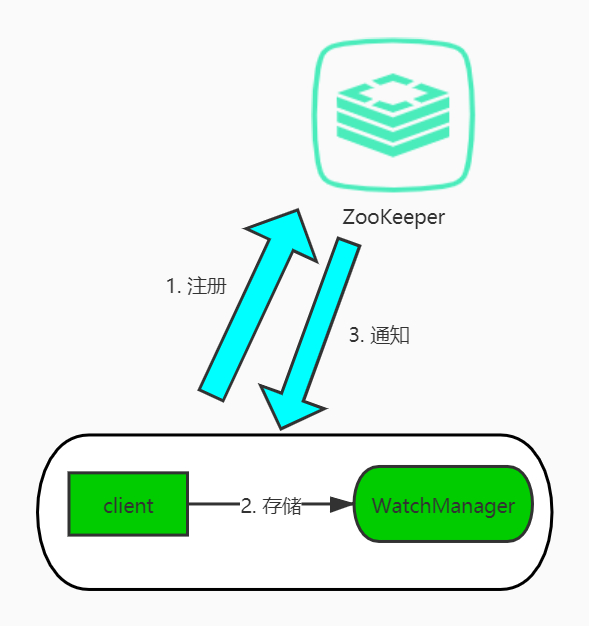
从上图可以看到,Watcher 机制包括三个角色:客户端线程、客户端的 WatchManager 以及 ZooKeeper 服务器。Watcher 机制就是这三个角色之间的交互,整个过程分为注册、存储和通知三个步骤:
- 客户端向 ZooKeeper 服务器注册一个 Watcher 监听;
- 把这个监听信息存储到客户端的 WatchManager 中;
- 当 ZooKeeper 中的节点发生变化时,会通知客户端,客户端会调用相应 Watcher 对象中的回调方法。
文章持续更新,可以微信搜「 JavaKeeper 」第一时间阅读,无套路领取 500+ 本电子书和 30+ 视频教学和源码,本文 GitHub github.com/JavaKeeper 已经收录,Javaer 开发、面试必备技能兵器谱,有你想要的。
参考:
《从Paxos到ZooKeeper 分布式一致性原理与实践》
《阿里中间件团队博客》http://jm.taobao.org/2011/10/08/1232/
《Zookeeper官方文档》https://zookeeper.apache.org/doc/
《尚硅谷Zookeeper》
https://cloud.tencent.com/developer/article/1578401
以上是关于不懂 ZooKeeper?没关系,这一篇给你讲的明明白白的主要内容,如果未能解决你的问题,请参考以下文章