基于用户评论情感分析详细设计与技术实现
Posted 沉默着忍受
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于用户评论情感分析详细设计与技术实现相关的知识,希望对你有一定的参考价值。
基于用户评论情感分析详细设计与技术实现
文章目录
前言
随着平台用户的不断扩大,平台的用户生态环境,或多或少是一个平台长期发展的重要因数,如果一个平台中的负面情绪较大,那么该平台就应该注意用户发展动态和思考平台本身的运营是否存在问题。
那么如何去分析用户的情感,通过下面的思路或许可以找到突破口。
提示:以下是本篇文章正文内容,下面案例可供参考
一、技术架构
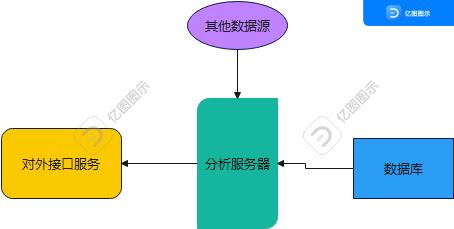
架构介绍:
- 数据库提供分析器目标分析数据;
- 其他数据源可通过爬虫,数据收集等获取数据
- 分析服务器使用python微型web开发框架Flask,flask框架需要pycharm专业版或破解版
- 对外接口服务,可以查看情感分析数据
二、分析服务器构建
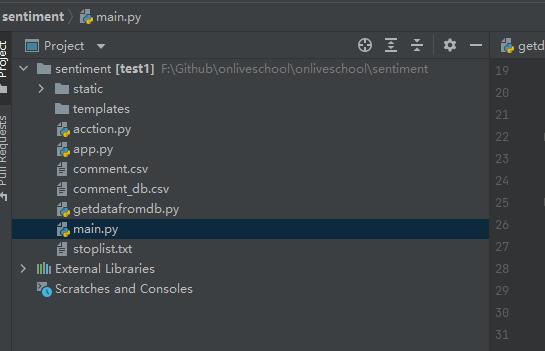
上图为我的flask项目文件目录展示,下面将重点讲解怎么去构建这样一个项目;
1.1 创建flask项目
- 使用pycharm创建一个新项目,项目选择flask
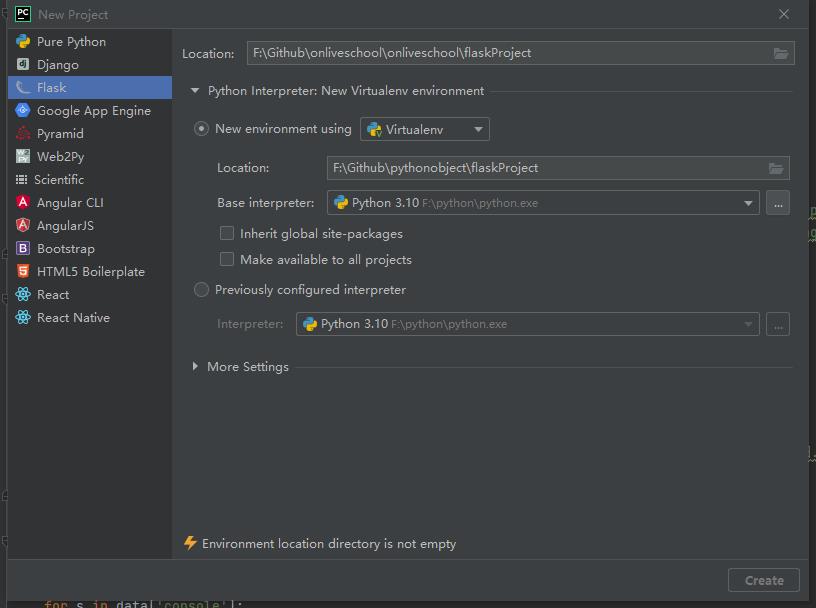
- 选择你想要创建到什么文件夹,然后点击右下角的create,即可创建;
1.2 编写数据库连接脚本,获取用户评论数据;
- 案例如下:
我们想要获取评论数据,就需要负责存储平台上所有的评论数据;我的评论数据时保存在mysql中的comment表中,表结构如下:

我们需要获取console字段的所有评论数据 - 创建getdatafromdb.py文件编写脚本,并且将获得的数据存放到csv文件中;
1.2.1 引入库
import pymysql
import pandas
1.2.2 连接数据库获取数据
class Test_myqsl(object):
# 运行数据库和建立游标对象
def __init__(self):
self.connect = pymysql.connect(host="127.0.0.1", port=3306, user="root", password="318422", database="forum",
charset="utf8")
# 返回一个cursor对象,也就是游标对象
self.cursor = self.connect.cursor(cursor=pymysql.cursors.DictCursor)
# 关闭数据库和游标对象
def __del__(self):
self.connect.close()
self.cursor.close()
def write(self):
# 将数据转化成DataFrame数据格式
data = pandas.DataFrame(self.read())
# 把id设置成行索引
data_1 = data.set_index("id", drop=True)
# 写写入数据数据
pandas.DataFrame.to_csv(data_1, "comment_db.csv", encoding="utf-8")
print("写入成功")
def read(self):
# 读取数据库的所有数据
data = self.cursor.execute("""select id,console from comment""")
field_2 = self.cursor.fetchall()
print(field_2)
return field_2
# 封装
def main():
write = Test_myqsl()
write.write()
1.2.3 测试
['id': 1, 'console': '我喜欢这个帖子',
'id': 2, 'console': '我想笑了',
'id': 3, 'console': '你好帅啊,我好喜欢',
'id': 4, 'console': '没有什么东西,毫无价值',
'id': 5, 'console': '大佬,yyds',
'id': 6, 'console': '兄弟们,真的感动哭了',
'id': 7, 'console': '不觉得很酷吗?',
'id': 8, 'console': '我好喜欢你',
'id': 9, 'console': '我会在这里等你!',
'id': 10, 'console': '好家伙,给我整破防了。',
'id': 11, 'console': '讨厌这次的疫情,改变了我的梦想',
'id': 12, 'console': '你们都是最棒的',
'id': 13, 'console': '没有什么不能完成的任务',
'id': 14, 'console': '我的梦想丢了',
'id': 15, 'console': '搞笑!你是不是傻。',
'id': 16, 'console': '哈哈哈',
'id': 17, 'console': '嘿嘿嘿',
'id': 18, 'console': '学代码好难啊!']
写入成功
当前数据已经写入到comment_db.csv文件中

1.3 编写情感分析脚本
- wordcloud安装参考:下载安装wordcloud
- snownlp安装参考:https://blog.csdn.net/cuixinyang19_/article/details/82318033
- jieba安装参考:pip install jieba
- wordcloud强调python版本,snownlp和jieba不强调版本,我装的都是python3.6下的。
- 创建main.py文件编写s数据分析脚本
1.3.1 引入库
import pandas as pd
from snownlp import SnowNLP
import matplotlib.pyplot as plt
import numpy as np
from wordcloud import WordCloud
import jieba
from jieba import analyse
import getdatafromdb
这里我们主要依赖的是snownlp库进行数据分析:
SnowNLP是一个python写的类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和TextBlob不同的是,这里没有用NLTK,所有的算法都是自己实现的,并且自带了一些训练好的字典。注意本程序都是处理的unicode编码,所以使用时请自行decode成unicode。
snownlp库: https://github.com/isnowfy/snownlp
可参考学习技术资料:https://zhuanlan.zhihu.com/p/26331196
1.3.2 情感分直方图实现
getdatafromdb.main()
data = pd.read_csv('comment_db.csv')#读取csv文件数据
def read_file():
data.head(2)
data1 = data[['id', 'console']]
data1.head(10)
data1['emotion'] = data1['console'].apply(lambda x: SnowNLP(x).sentiments)
data1.head(10)
data1.describe()
return data1
def getping_chart(data1):
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
bins = np.arange(0, 1.1, 0.1)
plt.hist(data1['emotion'], bins, color='#4F94CD', alpha=0.9)
plt.xlim(0, 1)
plt.xlabel('情感分')
plt.ylabel('数量')
plt.title('情感分直方图')
plt.savefig('F:\\Github\\onliveschool\\onliveschool\\sentiment\\static\\情感分直方图.png')
picpath = 'F:\\Github\\online\\onlineexam-main\\onlineexam\\onlinewx\\miniprogram\\images\\情感分直方图.png'
return picpath
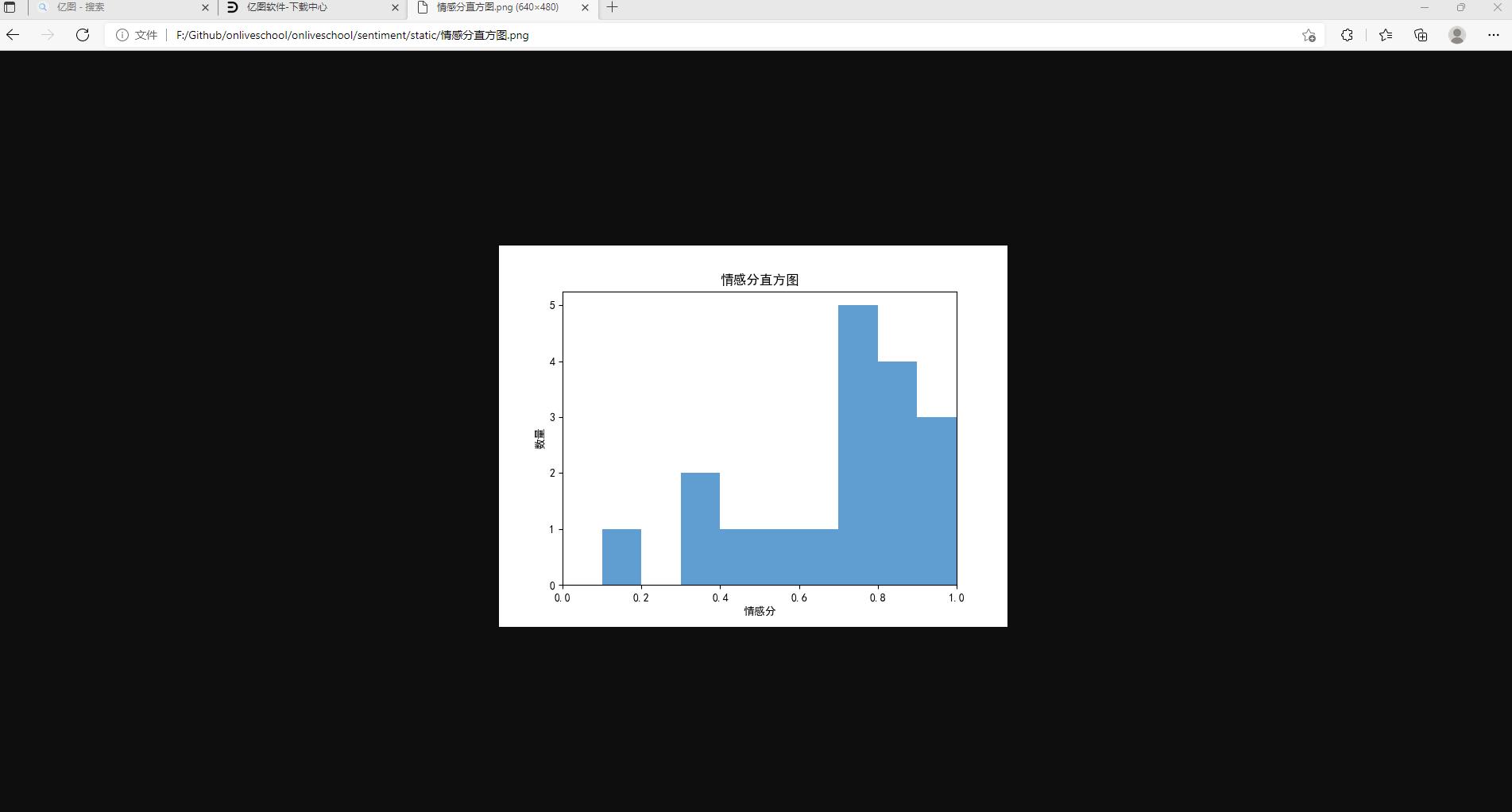
打印的各个评论的情感分数如下:
id console emotion
0 1 我喜欢这个帖子 0.418492
1 2 我想笑了 0.714930
2 3 你好帅啊,我好喜欢 0.980900
3 4 没有什么东西,毫无价值 0.332192
4 5 大佬,yyds 0.782665
5 6 兄弟们,真的感动哭了 0.890965
6 7 不觉得很酷吗? 0.732578
7 8 我好喜欢你 0.799730
8 9 我会在这里等你! 0.740741
9 10 好家伙,给我整破防了。 0.517992
10 11 讨厌这次的疫情,改变了我的梦想 0.970619
11 12 你们都是最棒的 0.961800
12 13 没有什么不能完成的任务 0.369391
13 14 我的梦想丢了 0.873836
14 15 搞笑!你是不是傻。 0.184189

我们可以看出大部分情感数值集中在0.4-0.8。
1.3.3 态度比例图;
我们将大于情感分数大于0.5的视为积极的
def getattion_chart(data1):
# 计算积极评论与消极评论各自的数目
pos = 0
neg = 0
for i in data1['emotion']:
if i >= 0.5:
pos += 1
else:
neg += 1
# 积极评论占比
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
pie_labels = 'postive', 'negative'
plt.pie([pos, neg], labels=pie_labels, autopct='%1.1f%%', shadow=True)
path = 'F:\\Github\\onliveschool\\onliveschool\\sentiment\\static\\积极评论占比图.png'
plt.savefig(path)
picpath = 'F:\\Github\\onliveschool\\onliveschool\\sentiment\\static\\积极评论占比图.png'
return picpath
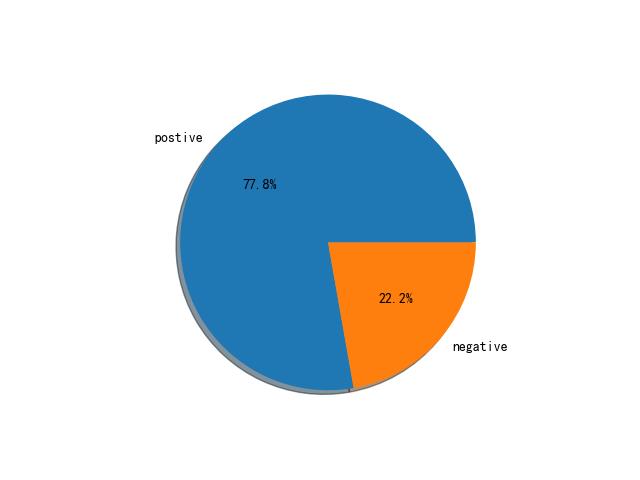
这里就可以直观的看出该平台积极正向的评论和消极的比例
1.3.4 用户高频词云;
def getap10_chart():
# 关键词top10
text = ''
for s in data['console']:
text += s
key_words = jieba.analyse.extract_tags(sentence=text, topK=10, withWeight=True, allowPOS=())
print(key_words)
# 参数说明 :
# sentence
# 需要提取的字符串,必须是str类型,不能是list
# topK
# 提取前多少个关键字
# withWeight
# 是否返回每个关键词的权重
# allowPOS是允许的提取的词性,默认为allowPOS =‘ns’, ‘n’, ‘vn’, ‘v’,提取地名、名词、动名词、动词
def getcloud_chart():
w = WordCloud(font_path="msyh.ttc") # font_path="msyh.ttc",设置字体,否则显示不出来
text = ''
for s in data['console']:
text += s
data_cut = ' '.join(jieba.lcut(text))
w.generate(data_cut)
image = w.to_file('F:\\Github\\onliveschool\\onliveschool\\sentiment\\static\\词云图.png')
picpath = 'F:\\Github\\onliveschool\\onliveschool\\sentiment\\static\\词云图.png'
return picpath
首先分析前10条词条:
[('喜欢', 0.42769413022650005),
('梦想', 0.3875037441765),
('很酷', 0.330188261785),
('好难', 0.330188261785),
('yyds', 0.2988691875725),
('我整', 0.2988691875725),
('破防', 0.2988691875725),
('嘿嘿嘿', 0.27390596682),
('毫无价值', 0.26806559554),
('搞笑', 0.26333454555)]
Loading model cost 1.393 seconds.
词云图片如下:

1.4 flask实现web接口服务
- 在flask项目app.py编写接口方法
- 运行app.py文件,调用web服务
- 打开浏览器访问接口
- 查看返回图片文件地址
相关代码:
from flask import Flask
import main
app = Flask(__name__)
@app.route('/')
def hello_world(): # put application's code here
return 'Hello World!'
# 获得用户态度比例表
@app.route('/api/py/acctionchart')
def getacction_chart():
# 获取最新表
path = main.getattion_chart(main.read_file())
return path
# 获得用户词云
@app.route('/api/py/getcloudchart')
def getcloud_chart():
path = main.getcloud_chart()
return path
# 情感分直方图
@app.route('/api/py/getpingchart')
def getpingbu_chart():
path = main.getping_chart(main.read_file())
return path
if __name__ == '__main__':
app.run()
- 点击http://127.0.0.1:5000/,会展示Hello World!页面
-
输入http://127.0.0.1:5000/api/py/getpingchart,获得用户情感分布直方图文件路径;

-
访问该路径图片
-
扩展说明
我们有了接口,并且接口也返回了当前保存图片的文件路径,如果项目有前端的话,就直接将保持图片的路径设置到前端文件夹中,前端固定好图片路径,运行该flask项目,并且调用接口,就可以在前端管理页面看到展示数据。这里也可以实现一些其他性格相关的操作,比如可以将情感值在细化分析。
三、总结
以上就是今天要讲的内容,本文仅仅简单情感分析服务架构的创建和使用,如果在学习时有问题,可在评论区提出来!
以上是关于基于用户评论情感分析详细设计与技术实现的主要内容,如果未能解决你的问题,请参考以下文章