Python爬取美女图片,看到了意想不到的场景
Posted 不想秃头的晨晨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬取美女图片,看到了意想不到的场景相关的知识,希望对你有一定的参考价值。
最近使用Python,写了几个爬虫练练手,网上的教程有很多,但是有的已经不能爬了,主要是网站经常改,可是爬虫还是有通用的思路的,即下载数据、解析数据、保存数据。下面一一来讲。
python练手项目——爬取网页美女图片
1.下载数据
首先打开要爬的网站,分析URL,每打开一个网页看URL有什么变化,有可能带上上个网页的某个数据,例如xxID之类,那么我们就需要在上一个页面分析html,找到对应的数据。如果网页源码找不到,可能是ajax异步加载,去xhr里去找。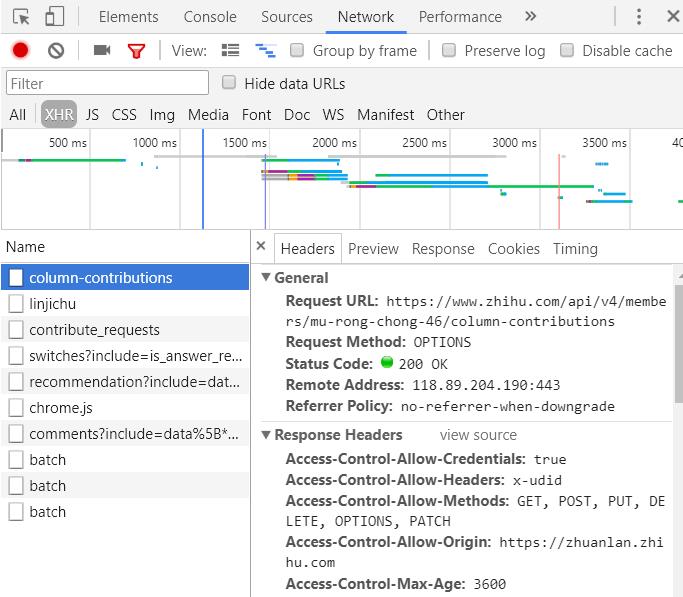
有的网站做了反爬的处理,可以添加User-Agent :判断浏览器
self.user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
# 初始化 headers
self.headers = 'User-Agent': self.user_agent
如果不行,在Chrome上按F12分析请求头、请求体,看需不需要添加别的信息,例如有的网址添加了referer当前网页的来源,那么我们在请求的时候就可以带上。按Ctrl + Shift + C,可以定位元素在HTML上的位置
动态网页
有一些网页是动态网页,我们得到网页的时候,数据还没请求到呢,当然什么都提取不出来,用Python 解决这个问题只有两种途径:直接从JavaScript 代码里采集内容,或者用Python 的第三方库运行JavaScript,直接采集你在浏览器里看到的页面。
1.找请求,看返回的内容,网页的内容可能就在这里。然后可以复制请求,复杂的网址中,有些乱七八糟的可以删除,有意义的部分保留。切记删除一小部分后先尝试能不能打开网页,如果成功再删减,直到不能删减。
2.Selenium:是一个强大的网络数据采集工具(但是速度慢),其最初是为网站自动化测试而开发的。近几年,它还被广泛用于获取精确的网站快照,因为它们可以直接运行在浏览器上。Selenium 库是一个在WebDriver上调用的API。有点儿像可WebDriver以加载网站的浏览器,但是它也可以像BeautifulSoup对象一样用来查找页面元素,与页面上的元素进行交互(发送文本、点击等),以及执行其他动作来运行网络爬虫。
PhantomJS:是一个“无头”(headless)浏览器。它会把网站加载到内存并执行页面上的javascript,但是它不会向用户展示网页的图形界面。把Selenium和PhantomJS 结合在一起,就可以运行一个非常强大的网络爬虫了,可以处理cookie、JavaScript、header,以及任何你需要做的事情。
下载数据的模块
下载数据的模块有urllib、urllib2及Requests
Requests相比其他俩个的话,支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自 动确定响应内容的编码,支持国际化的 URL 和 POST数据自动编码,而且api相对来说也简单,但是requests直接使用不能异步调用,速度慢。
html = requests.get(url, headers=headers) #没错,就是这么简单
urllib2以我爬取淘宝的妹子例子来说明
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = 'User-Agent': user_agent
# 注意:form data请求参数
params = 'q&viewFlag=A&sortType=default&searchStyle=&searchRegion=city%3A&searchFansNum=¤tPage=1&pageSize=100'
def getHome():
url = 'https://mm.taobao.com/tstar/search/tstar_model.do?_input_charset=utf-8'
req = urllib2.Request(url, headers=headers)
# decode(’utf - 8’)解码 把其他编码转换成unicode编码
# encode(’gbk’) 编码 把unicode编码转换成其他编码
# ”gbk”.decode(’gbk’).encode(’utf - 8')
# unicode = 中文
# gbk = 英文
# utf - 8 = 日文
# 英文一 > 中文一 > 日文,unicode相当于转化器
html = urllib2.urlopen(req, data=params).read().decode('gbk').encode('utf-8')
# json转对象
peoples = json.loads(html)
for i in peoples['data']['searchDOList']:
#去下一个页面获取数据
getUseInfo(i['userId'], i['realName'])
2.解析数据
解析数据也有很多方式,我只看了beautifulsoup和正则,这个例子是用正则来解析的
def getUseInfo(userId, realName):
url = 'https://mm.taobao.com/self/aiShow.htm?userId=' + str(userId)
req = urllib2.Request(url)
html = urllib2.urlopen(req).read().decode('gbk').encode('utf-8')
pattern = re.compile('<img.*?src=(.*?)/>', re.S)
items = re.findall(pattern, html)
x = 0
for item in items:
if re.match(r'.*(.jpg")$', item.strip()):
tt = 'http:' + re.split('"', item.strip())[1]
down_image(tt, x, realName)
x = x + 1
print('下载完毕')
正则表达式说明
- match:匹配string 开头,成功返回Match object, 失败返回None,只匹配一个。
- search:在string中进行搜索,成功返回Match object, 失败返回None, 只匹配一个。
- findall:在string中查找所有 匹配成功的组, 即用括号括起来的部分。返回list对象,每个
list item是由每个匹配的所有组组成的list。
1).? 是一个固定的搭配,*.**和代表可以匹配任意无限多个字符,加上?表示使用非贪婪模式进行匹配,也就是我们会尽可能短地做匹配 2)(.?)代表一个分组,如果有5个(.*?)就说明匹配了五个分组
3) 正则表达式中,“.”的作用是匹配除“\\n”以外的任何字符,也就是说,它是在一行中进行匹配。这里的“行”是以“\\n”进行区分的。HTML标签每行的末尾有一个“\\n”,不过它不可见。 如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始,不会跨行。而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,将“\\n”当做一个普通的字符加入到这个字符串中,在整体中进行匹配。
3.保存数据
数据解析后可以保存到文件或数据库中,这个例子是保存到了文件中,很简单了。
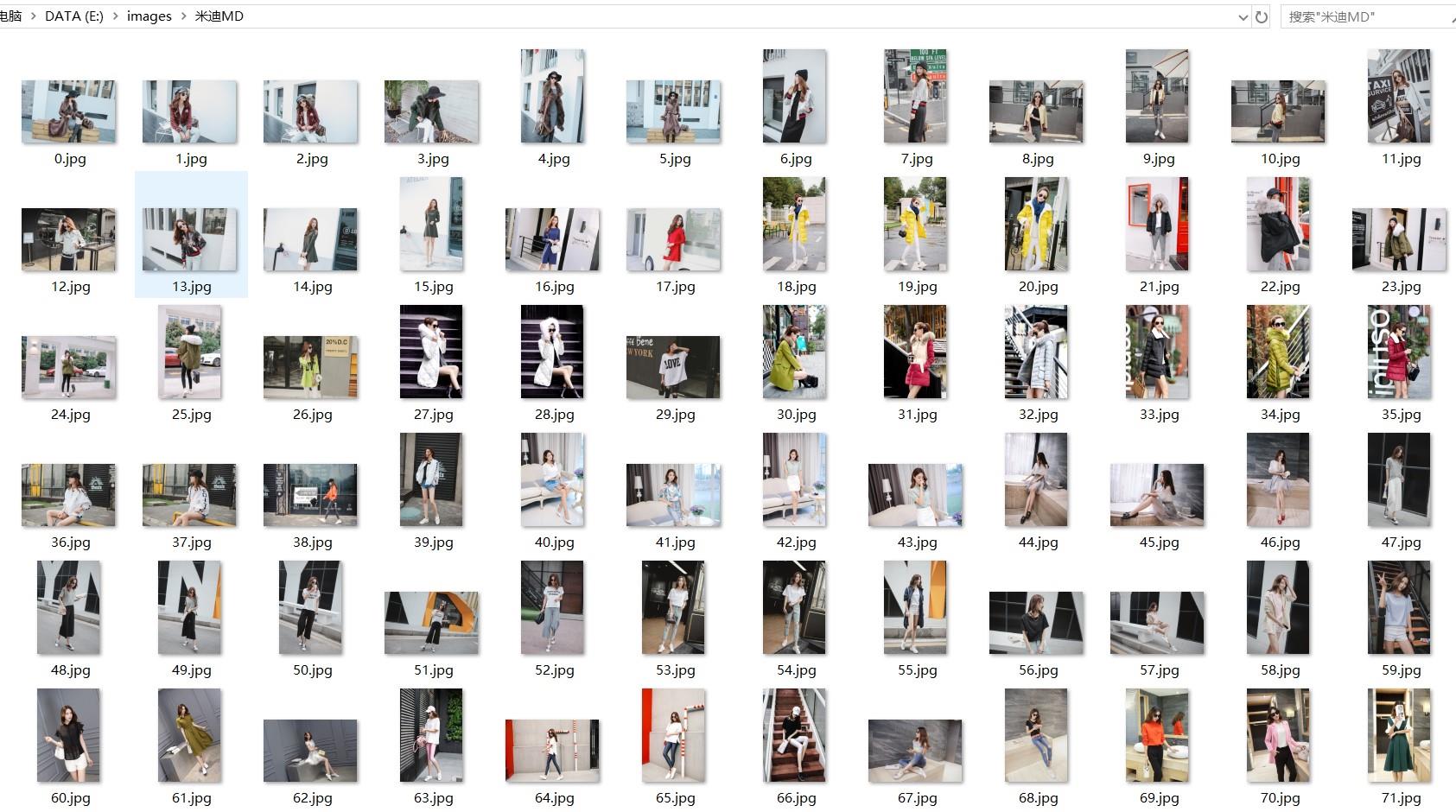
def down_image(url, filename, realName):
req = urllib2.Request(url=url)
folder = 'e:\\\\images\\\\%s' % realName
if os.path.isdir(folder):
pass
else:
os.makedirs(folder)
f = folder + '\\\\%s.jpg' % filename
if not os.path.isfile(f):
print f
binary_data = urllib2.urlopen(req).read()
with open(f, 'wb') as temp_file:
temp_file.write(binary_data)
最后,感谢您的阅读。您的每个点赞、留言、分享都是对我们最大的鼓励,笔芯~
如有疑问,欢迎在评论区一起讨论!
如有不正确的地方,欢迎指导!
以上是关于Python爬取美女图片,看到了意想不到的场景的主要内容,如果未能解决你的问题,请参考以下文章