源码阅读(21):Java中其它主要的Map结构——TreeMap容器
Posted 说好不能打脸
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了源码阅读(21):Java中其它主要的Map结构——TreeMap容器相关的知识,希望对你有一定的参考价值。
(接上文《源码阅读(20):Java中主要的Map结构——HashMap容器(下2)》)
我们通过解读Java自带的各种Map容器既可以了解到,构成这些原生容器的数据组织结构基本上就只有三种:数组、链表和红黑树。也就是说如果读者想彻底了解Java自带的Map容器的工作细节,就必须首先详细理解这三类数据结构,然后在这个基础上再进行“知识移植”即可。
例如Java自带的Map容器中,有一个叫做TreeMap的容器,后者就是主要基于红黑树构建的一种Map容器,其重要的工作过程和HashMap中基于红黑树工作的部分类似。从本部分开始,我们将对Java自带的除HashMap以外的多种Map容器进行介绍。
1、TreeMap概述和基本使用
TreeMap容器基于红黑树进行构建,其容器内所有的K-V键值对对象都是这个红黑树上的一个节点。至于这些对象的排列顺序如何决定,主要是基于两种逻辑。第一种逻辑是基于K-V键值对中Key信息的Hash值来决定,第二种是基于使用者设定的java.util.Comparator接口的实现来决定,以上两种排列顺序逻辑的选择完全取决于TreeMap容器实例化时使用的构造函数。
由于内部是红黑树结构的原因,TreeMap容器拥有较好的时间复杂度,进行节点查询、添加、移除操作时平均时间复杂度可控制在O(logn)。另外在TreeMap容器类的官方介绍中,有这么一句话:
Algorithms are adaptations of those in Cormen, Leiserson, and Rivest’s Introduction to Algorithms.
这本书的音译是《算法导论》,目前这本书已经发行第四版,全国各大书店/网上书店均有销售。这本书最初初版的时间为2004年,是一本非常经典的计算机算法书籍,建议各位读者有时间的时候可以阅读。

最后请注意,TreeMap容器并非线程安全的容器,且在Java原生的线程安全的容器中并没有类似内部结构的容器可供选择。所以如果使用者需要在线程安全的场景下使用TreeMap容器,可以采用如下方式将一个线程不安全的容器封装为一个线程安全的容器:
// ......
TreeMap<String, Object> currentMap = new TreeMap<>();
// 封装成线程安全的Map容器
Map<String, Object> cMap = Collections.synchronizedMap(currentMap);
// ......
以上代码很简单无需过多说明,主要是Collections工具类的synchronizedMap方法的内部代码如下:
// ......
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m)
return new SynchronizedMap<>(m);
/**
* @serial include
*/
private static class SynchronizedMap<K,V> implements Map<K,V>, Serializable
// 被SynchronizedMap类代理的真实Map对象
// Backing Map
private final Map<K,V> m;
// 用来加同步锁的对象
// Object on which to synchronize
final Object mutex;
SynchronizedMap(Map<K,V> m)
this.m = Objects.requireNonNull(m);
mutex = this;
SynchronizedMap(Map<K,V> m, Object mutex)
this.m = m;
this.mutex = mutex;
public int size()
synchronized (mutex) return m.size();
public boolean isEmpty()
synchronized (mutex) return m.isEmpty();
//......
// 省略了一些代码
//......
public V remove(Object key)
synchronized (mutex) return m.remove(key);
public void clear()
synchronized (mutex) m.clear();
//......
// 省略了一些代码
//......
@Override
public void forEach(BiConsumer<? super K, ? super V> action)
synchronized (mutex) m.forEach(action);
@Override
public V replace(K key, V value)
synchronized (mutex) return m.replace(key, value);
//......
// 省略了一些代码
//......
// ......
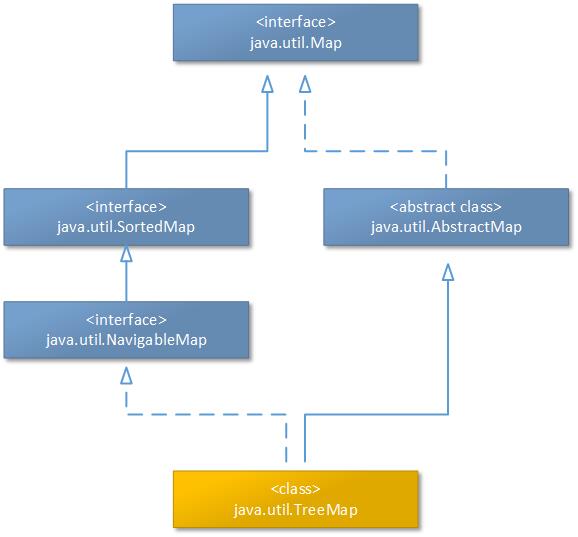
虽然Java中有这种SynchronizedMap代理类,可以将一个线程不安全的容器封装为一个线程安全的容器,但是由于SynchronizedMap内部使用的是悲观锁机制的实现,所以推荐在较高并发的场景下还是优先选择使用java.util.concurrent包下的相关数据结构类。下图展示了TreeMap容器类的主要继承体系:
2、TreeMap容器中的典型方法
由于之前的文章已经介绍过红黑树的特性了(可参见文章《源码阅读(17):红黑树在Java中的实现和应用》),所以本小节就直接介绍TreeMap容器中的几个典型操作方法,顺便和读者一起复习红黑树的工作特点。在介绍这些方法前,我们首先给出TreeMap容器中重要的变量信息:
public class TreeMap<K,V> extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
// ......
// 这个比较器非常重要,它记录了红黑树中各节点排列顺序的判定逻辑;
// 该比较器对象可以为null,如果为null的情况那么在判定红黑树节点排列顺序时,
// 将采用TreeMap容器原生的基于K-V键值对Key-Hash值的判定方式。
private final Comparator<? super K> comparator;
// 该变量记录当前TreeMap容器中红黑树的根节点
private transient Entry<K,V> root;
// 该变量记录当前TreeMap容器中的K-V键值对对象数量
private transient int size = 0;
// modCount变量记录当前TreeMap容器执行“写”操作的次数
private transient int modCount = 0;
// ......
2.1、TreeMap构造方式
TreeMap容器中一共有四个构造函数,这四个构造函数实际上都在完成同一个工作,即根据调用情况决定comparator变量的赋值情况,以及TreeMap容器初始时的红黑树结构状态。
public class TreeMap<K,V> extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
// ......
// 该默认的构造函数,将设定TreeMap容器中的comparator比较器为null
// 基于上文的介绍我们就知道,这样实例化的TreeMap容器对象将采用K-V键值对自身Key-Hash值完成排序比较
public TreeMap()
comparator = null;
// 该构造函数将为当前TreeMap容器对象设定一个比较器
public TreeMap(Comparator<? super K> comparator)
this.comparator = comparator;
// 该构造函数将一个K-V键值对容器的所有对象设定到新的TreeMap容器中
// 并且由于原容器没有实现SortedMap接口,所以设定当前TreeMap容器的comparator比较器为null
public TreeMap(Map<? extends K, ? extends V> m)
comparator = null;
putAll(m);
// 该构造函数将一个实现了SortedMap接口的K-V键值对容器的所有对象设定到新的TreeMap容器中
// 并且由于原容器实现了SortedMap接口,所以将原SortedMap容器使用的comparator比较器设定到当前容器
public TreeMap(SortedMap<K, ? extends V> m)
comparator = m.comparator();
try
buildFromSorted(m.size(), m.entrySet().iterator(), null, null);
catch (java.io.IOException cannotHappen)
catch (ClassNotFoundException cannotHappen)
// ......
请注意以上代码片段中的buildFromSorted方法,这个方法的主要意义是基于一个有序的数据集合(可能是某个有序的Map容器中基于Map.Entries的迭代器,也可能是有序Map容器中基于K-V键值对中所有Key信息的迭代器等等)构建一颗红黑树树。这个方法在TreeMap容器的方法定义中有两个重载的方法,其中的代码内容如下所示:
// ......
// size参数、it参数和defaultVal参数的含义将在后续的代码阅读内容中进行说明
private void buildFromSorted(int size, Iterator<?> it, ObjectInputStream str, V defaultVal)
this.size = size;
// 递归进行处理
root = buildFromSorted(0, 0, size-1, computeRedLevel(size), it, str, defaultVal);
// 该方法中level:表示当前正在构建的满树深度
// lo:表示当前子树的第一个节点索引位,第一次递归时从0号索引位开始
// hi:表示当前子树的最后一个节点索引位,第一次递归时从size-1号索引位开始
// redLevel:表示红黑树中红节点的起始深度
private final Entry<K,V> buildFromSorted(int level, int lo, int hi, int redLevel,
Iterator<?> it, ObjectInputStream str, V defaultVal)
// 如果条件成立,说明满二叉树的构造完成,返回null
if (hi < lo)
return null;
// 找到本次遍历集合的中间索引位,代码很好理解:无符号右移一位既是“除以2”操作。
int mid = (lo + hi) >>> 1;
Entry<K,V> left = null;
// 如果当前子树的最小索引位小于当前确定的中间索引位,则继续构建下一级子树(以当前mid索引位为根节点的左子树)
// 下一级左子树构造时,指定的满二叉树深度 + 1,子树的起始索引位为0,子树的结束索引位为mid-1。
if (lo < mid)
left = buildFromSorted(level+1, lo, mid - 1, redLevel, it, str, defaultVal);
// extract key and/or value from iterator or stream
K key;
V value;
// 以上代码我们只是确定了子树的索引定位,还没有真正开始将集合构建满二叉树
// 所以这里开始进行满二叉树的构建:这里一共有四种可能的场景
// 当it != null,defaultVal == null:以Map.Entry的形式取得对象,构建本次红黑树的节点
// 当it != null,defaultVal != null:以K-V键值对的形式取得对象,构建本次红黑树的节点,且key的值来源于it迭代器,value值默认为defaultVal
// 当it == null,defaultVal == null:以对象反序列化的形式取得对象,构建本次红黑树的节点,key值来源于str反序列化读取的对象信息,value值也来源于str反序列化读取的对象信息
// 当it == null,defaultVal != null:以对象反序列化的形式取得对象,构建本次红黑树的节点,key值来源于str反序列化读取的对象信息,但是Value值默认为defaultVal
if (it != null)
if (defaultVal==null)
Map.Entry<?,?> entry = (Map.Entry<?,?>)it.next();
key = (K)entry.getKey();
value = (V)entry.getValue();
else
key = (K)it.next();
value = defaultVal;
else // use stream
key = (K) str.readObject();
value = (defaultVal != null ? defaultVal : (V) str.readObject());
Entry<K,V> middle = new Entry<>(key, value, null);
// color nodes in non-full bottommost level red
// 如果当前正在构建的满二叉树的深度刚好是开始前计算出的红色节点的深度
// 则将本次构建的middle节点的颜色标红
if (level == redLevel)
middle.color = RED;
// 如果当前节点的左子树不为null,则将当前节点和它的左子树进行关联
if (left != null)
middle.left = left;
left.parent = middle;
// 如果之前计算得到的当前节点子树的结束索引位大于计算得到的中间索引位
// 则进行当前middle节点的右子树构建
if (mid < hi)
Entry<K,V> right = buildFromSorted(level+1, mid+1, hi, redLevel, it, str, defaultVal);
middle.right = right;
right.parent = middle;
return middle;
// ......
应该注意的是以上代码第一个最关键的步骤,并不是读取当前正在处理结点的K值和V值,并形成一个新的TreeMap.Entry对象,而是通过递归的方式找到需要构建的红黑树的第一个节点索引位,相关的代码内容可以用下图进行描述:
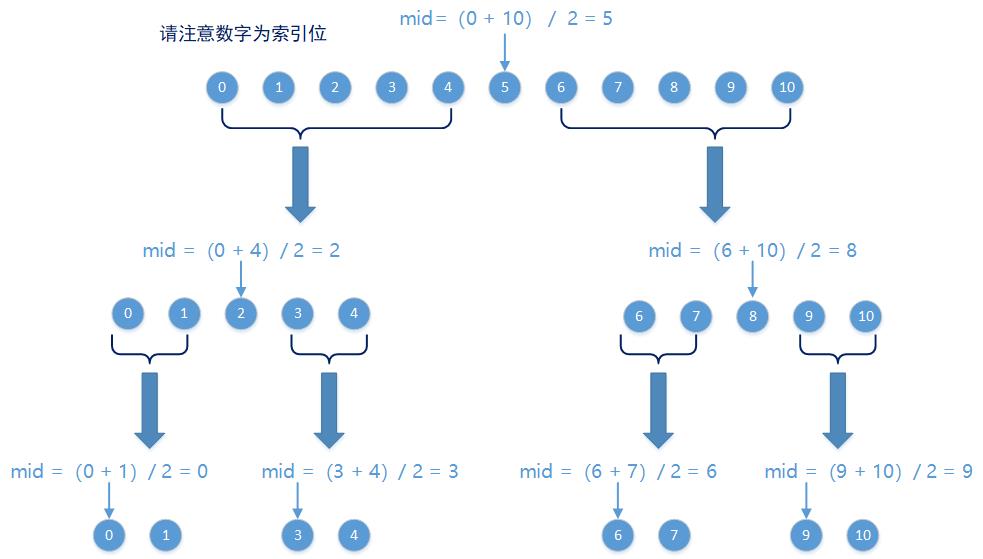
递归方法中构建的红黑树中,第一个被初始化的TreeMap.Entry对象的位置,是索引号为0的节点位置;第二个被初始化的TreeMap.Entry对象的位置,是索引号为1的节点位置,它将作为第一个节点的右子树存在。
从图中可以看出每次递归进行红黑树构造时,都是以当前计算得到的mid索引为的节点作为根节点来进行其左子树和右子树的构建。而当前节点的左子树可能是没有的,但是其右子树一定会有节点,如下图所示:
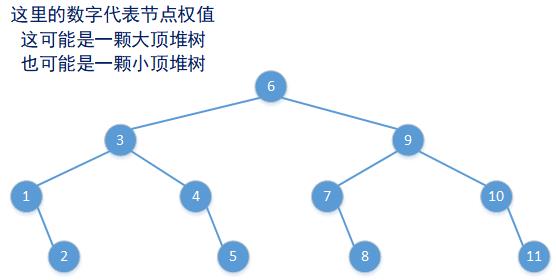
当构造指定索引位上红黑树的节点时,每一个节点都是一个TreeMap.Entry对象,这个新对象中Key信息的来源和Value信息的来源根据size参数、it参数、str参数、defaultVal参数的传值效果有所区别
- 当it != null,defaultVal == null:那么说明构造TreeMap.Entry对象是参考另一个TreeMap.Entry对象。
- 当it != null,defaultVal != null:那么说明构造TreeMap.Entry对象时,key值来源于it迭代器,value值默认为defaultVal。
- 当it == null,defaultVal == null:说明构造TreeMap.Entry对象时,key值来源于str反序列化读取的对象信息,value值也来源于str反序列化读取的对象信息
- 当it == null,defaultVal != null:以对象反序列化的形式取得对象,构建本次满二叉树的节点,key值来源于str反序列化读取的对象信息,但是value值默认为defaultVal
2.2、TreeMap中的批量添加操作
我们可以使用TreeMap容器提供的putAll(Map<? extends K, ? extends V> map)方法批量添加K-V键值对数据,根据当前TreeMap容器已有的K-V键值对的数量情况,添加步骤又不一样。
public void putAll(Map<? extends K, ? extends V> map)
int mapSize = map.size();
// 如果当前TreeMap容器中K-V键值对数量为0,并且将要添加的K-V键值对数量不为0
// 并且当前传入的map容器实现了SortedMap接口(说明是有序的Map容器)
if (size==0 && mapSize!=0 && map instanceof SortedMap)
// 取得传入的有序map容器的comparator比较器对象(记为对象c)
Comparator<?> c = ((SortedMap<?,?>)map).comparator();
// 如果比较器对象c,和当前TreeMap容器使用的比较器是同一对象
// 则使用上文中已将介绍的buildFromSorted方法构建一颗新的红黑树
// 这也就意味着之前treemap容器中已有的K-V键值对将不再进行维护——但好在之前treemap容器中并没有K-V键值对信息。
if (c == comparator || (c != null && c.equals(comparator)))
++modCount;
try
buildFromSorted(mapSize, map.entrySet().iterator(), null, null);
catch (java.io.IOException cannotHappen)
catch (ClassNotFoundException cannotHappen)
return;
// 如果当前TreeMap容器的状态不能使以上两个嵌套的if条件成立
// 则对当前批量添加的K-V键值对信息,逐一进行操作
super.putAll(map);
============
(接下文《源码阅读(22):Java中其它主要的Map结构——TreeMap容器(2)》)
以上是关于源码阅读(21):Java中其它主要的Map结构——TreeMap容器的主要内容,如果未能解决你的问题,请参考以下文章