源码阅读(12):Java中主要的QueueDeque结构——PriorityQueue集合(上)
Posted 说好不能打脸
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了源码阅读(12):Java中主要的QueueDeque结构——PriorityQueue集合(上)相关的知识,希望对你有一定的参考价值。
(接上文《源码阅读(11):Java中主要的Queue、Deque结构——ArrayDeque集合(下)》)
3. Java.util.PriorityQueue集合结构解析
PriorityQueue集合是线程不安全的,但这不影响它成为Java体系统非常重要的Quere性质的集合。PriorityQueue集合很好展示了树结构向数组结构的降维,并如何将其引入到实现中的方式。要深入理解PriorityQueue集合的工作方式和工作原理,首先就需要读者具备一些前置知识——树的知识,那么本文首先对这些前置知识点进行介绍:
3.1、准备知识
3.1.1、准备知识:树、二叉树、完全二叉树
我们首先需要大致介绍一下计算机体系中的树结构,树结构是计算机体系中一种非常重要的非线性结构,其中的重要定义包括:
- 层次和深度
设树的根结点层次为1,其他结点的层次是其父结点层次加1。一棵树中所有结点的层次的最大值就是这棵树的深度。

- 儿子结点和双亲结点(父结点)
一个结点数量为n(n > 1)的树结构,其中的任意结点的上层结点就是这个结点的双亲结点(父结点),树结构中的任意结点都最多只有一个双亲结点。如果以上这个条件不成立,则整个结构就不是树结构。
- 根结点
树结构中没有双亲结点(父结点)的结点就是这个树结构的根结点。
- 子树
树结构中任意结点如果存在儿子结点,以其儿子结点为新的根结点,都可以构成相互独立的新的树结构。这些新的树结构称为子树。如果以上条件不成立,则整个结构就不是树结构。比如说以下基于“B”结点为根结点的新的树中,其下有两个子树,这两个子树相对独立,不会有任何连接关系。

- 度、叶子结点、分支结点
以树中任意结点为子树根结点,其拥有的子树的数量为当前结点的度。度为0的结点是叶结点,度不为0的结点为分支结点。树的所有结点中度最大的值,就是这个数的度。
- 二叉树
所谓二叉树是指整个树结构中,不存在任何度大于2的结点的树。也就是说二叉树最多有两个子树,我们称之为“左子树”和“右子树”。如下图所示:

- 满二叉树
二叉树还是许多特殊场景下的表达,例如我们定义一棵深度为k的二叉树,当它有 2k-1 个结点时,它就是满二叉树。类似的满二叉树只能呈现如下图所示的这些结构:

- 完全二叉树
还有一种常见的二叉树,称为完全二叉树。完全二叉树是由满二叉树引申:对于深度为K的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点依顺序对应时。简单来说就是完全二叉树的所有非叶子结点可构成一颗满二叉树,且所有叶子结点都从最左侧的非叶子结点开始关联。如果用图形方式进行表达,那么完全二叉树会呈现如下图所示的这些图形结构:

3.1.2、准备知识:堆、小顶堆、大顶堆
堆树满足以下特点:
- 堆树是一颗完全二叉树
- 堆树中某个非叶子结点的值,总是不大于或不小于其任意叶子结点的值
- 堆树中每个结点的子树都是堆树
这里解释一下以上第二个要点。详细来说如果堆树中某个非叶子结点的值,总是小于或等于其任意叶子结点的值,这个堆树就称为小顶堆;如果堆树中某个非叶子结点的值,总是大于或者等于其任意叶子结点的值,这个堆树就称为大顶堆。下图展示了一些标准的大顶堆和小顶堆:
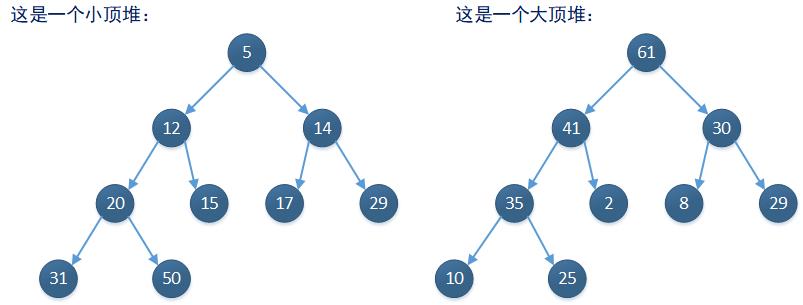
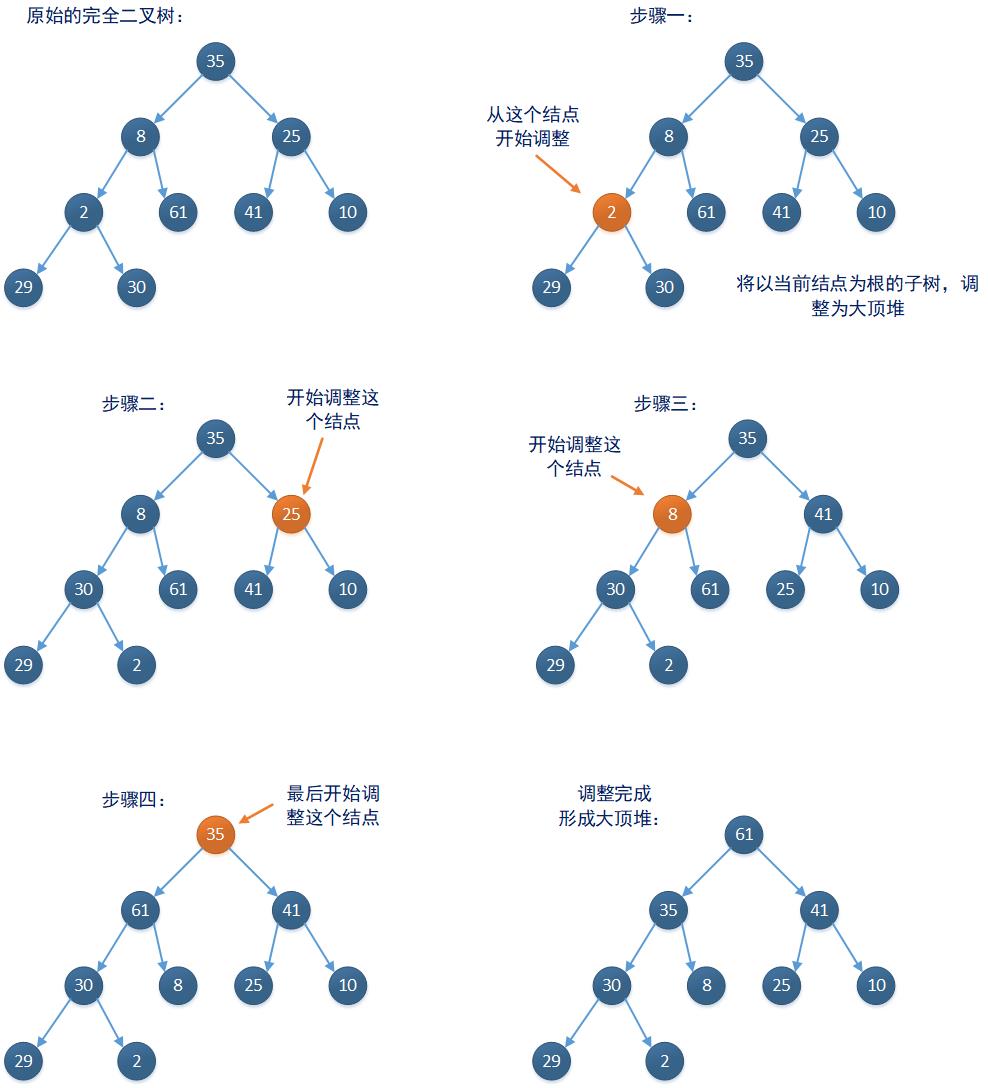
以大顶堆为例,只要是一个完全二叉树,就可以依据相关算法得到一个大顶堆。算法大概的过程是,从当前完全二叉树的最后一个非叶子结点开始,将基于每一个非叶子结点构造的子树都调整为大顶堆:
3.1.3、准备知识:堆的降维——使用数组表示堆结构
完全二叉树可以使用数组结构进行表达,也就是说非线性的数据结构可以降维成某种线性结构表达。而堆树的描述基础就是完全二叉树,所以对完全二叉树的降维就是对堆树的降维。降维操作的可行性实际上完全和二叉树的组织特点有关,如下图所示:

由于完全二叉树(总结点数记为n)是在其满二叉树的数值范围内进行的依次存储,所以完全二叉树的根节点存放在数组的0号索引位,完全二叉树的左儿子结点存放在数组的1号索引位。以此类推,完全二叉树的第一个叶子结点从“(n >> 1)- 1”计算得到的索引位开始,并且我们可以推导出以下公式:
- 当前非叶子结点的左儿子索引位 = 当前节点索引位 * 2 + 1,实际上更准确的说法是:当前节点索引位 << 1 + 1
- 当前非叶子结点的右儿子索引位 = 当前节点索引位 * 2 + 2,实际上更准确的说法是:当前节点索引位 << 1 + 2
- 当前结点的父节点索引位 = (当前节点索引位 - 1) / 2,实际上更准确的说法是:(当前节点索引位 - 1) >> 1
另一个关键点是,完全二叉树降维后形成的数组长度为n,只有数组的后半段是叶子节点,计算公式为 (n >> 1) - 1。
3.1.3、准备知识:堆排序
一个显而易见事实是:堆树可以用来排序,这个排序过程称为堆排序;而另一个事实是:线性结构的数组通常来说比非线性结构的树更易于编程。所以使用完全二叉树的数组表示进行排序,既方便理解又具有较高的处理性能。下图展示了基于大顶堆的排序过程:
-
设当前参与排序的数据量为n,首先从堆树最后一个非叶子结点开始排序,计算公式为:最后一个非叶子节点索引位 = (n >> 1) - 1:
-
使用上文介绍过的大顶堆算法,进行一轮数据调整,将当前数组范围(0到n-1)中最大的数字调整到0号索引位。
-
将目前0号索引位上数值最大的元素和数组n-1索引为的元素进行交换。
-
设定当前参与排序的数据量为n = n - 1。如果新的n值依然大于1,那么继续以上的步骤2和步骤3,直到需要参与排序的数据总量为1为止。
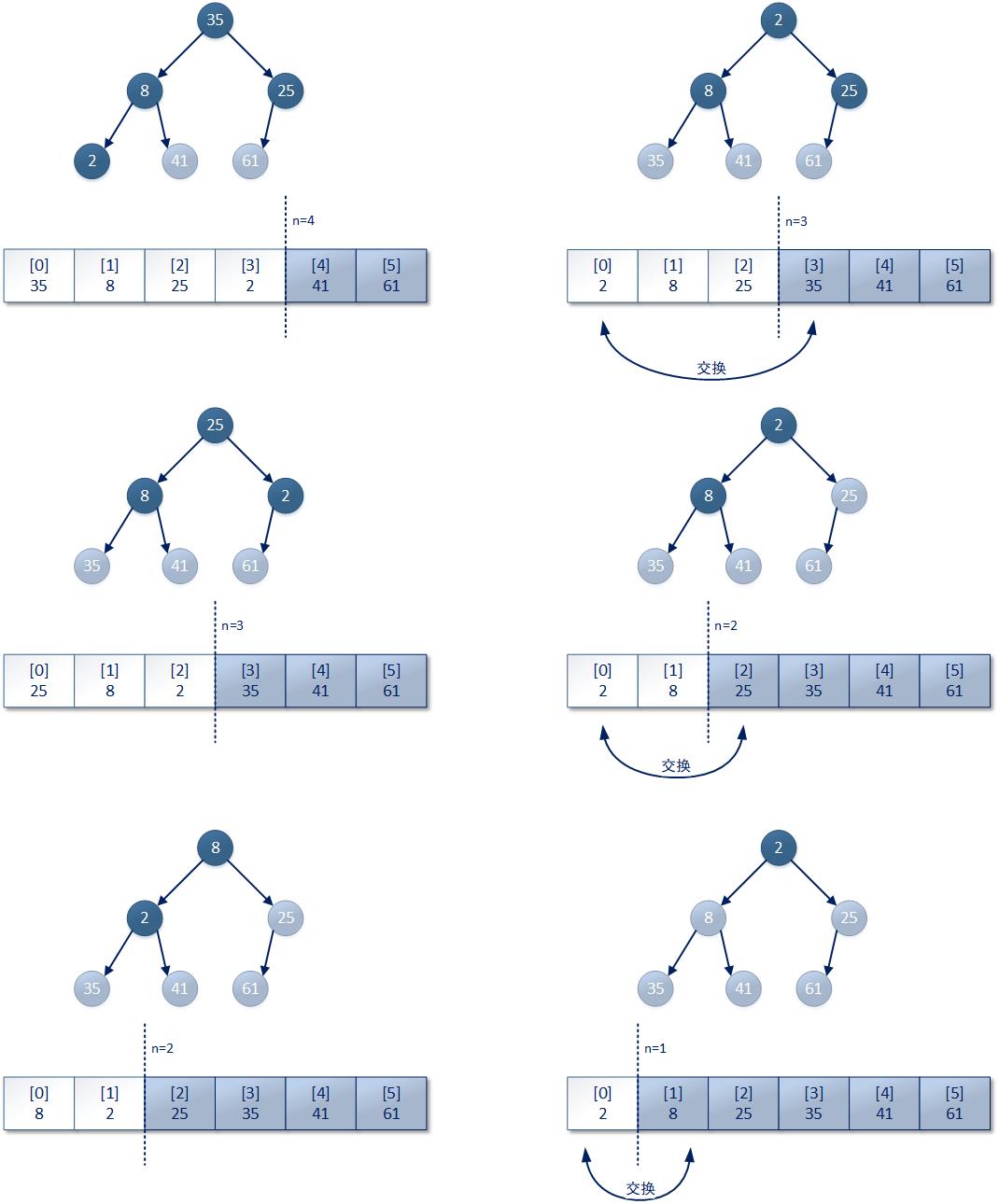
下面我们使用图形结构,将以上文字描述过程进行展现:

如上图所示,一个总结点数为6的完全二叉树进行第一次堆排序过程,使用基于大顶堆的计算方式。在第一次排序操作中当前数据中的所有索引位都参与排序计算过程(记为n=6)。经过多次基于大顶堆算法的交换操作后,我们数组中最大的值61放到了完全二叉树的根结点,用数组表示就是第0号索引位。
最后,我们将0号索引位为上的数值和本次参与排序操作的最后一个索引位上的数值进行交换,保证参与本次排序计算的最后一个索引位上的值是本次排序操作的最大值。如上图所示,整个数组都参与排序操作,所以最大值61从当前0号索引位被交换到了数组的最后一个索引位。就这样第一次大顶堆的排序过程就完成了,整个参与排序的数组有效索引位中,最大值被找了出来并被记录在了最后一个索引位上。下一次大顶堆的排序过程就不需要再将当前最后一个索引位纳入进来参与排序了,所以参与排序的结点总数减一。
接着进行第二次大顶堆排序过程,如下图所示:

通过以上步骤完成了基于完全二叉树的第二次排序,将参与排序的所有结点中最大数值41找到,并交换到参与本次排序的最后一个有效索引位上去。从以上关于算法步骤的示意图中,我们还可以发现大顶堆的排序操作次数明显减少、需要的交换操作次数明显减少,这是因为在第一次排序操作中大部分数值已经完成了比较和操作过程,也是因为参与排序的结点总数量逐渐减少。接下来通过以上的方式完成剩余索引位上的数值排序,如下图所示:
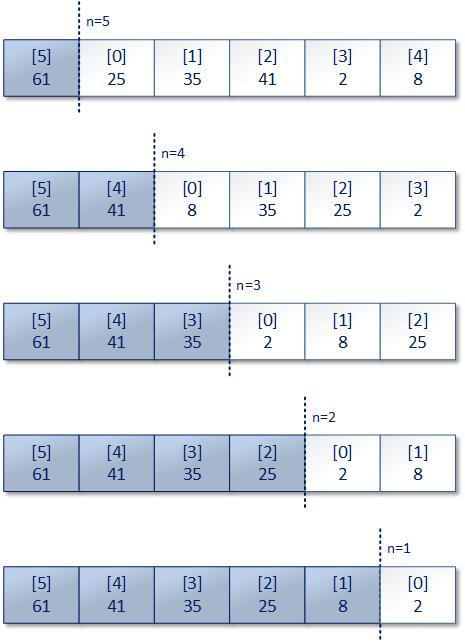
堆排序算法是非常灵活的,只要掌握以上提到的降维方式和结点与其左右儿子的对应关系,开发人员就可以根据自己的需要调整堆排序算法的次要步骤。例如以上描述的堆排序算法中,最后一步的交换操作就不是必须的:开发人员完全可以把已经找到的参与排序操作的结点中的最大值放在最前面,如下图所示:
3.1.4、准备知识:完成一个堆排序
以上小节叙述了很多堆排序的内容,这里我们就通过代码的方式向读者展示一个完整的堆排序算法,代码片段如下:
// 这是堆排序算法的一个实现,类名在这里并不重要
public class XXXXX
/**
* 这是一个堆排序算法
*/
private static void heapify(int[] beSorteds)
int size = beSorteds.length;
/*
* 1、首先从当前参与排序的 完全二叉树的最后一个非叶子节点开始进行计算,也就是 (effectiveScope >> 1) - 1的索引位
* 2、依次遍历这些非叶子节点,并基于大顶堆算法将当前非叶子节点、非叶子节点的左儿子、右儿子,进行比较交换
* 3、第2步是需要循环完成的,每次完成以上过程后,0号索引位上的值就是最大了,然后和effectiveScope - 1的索引位进行交换
* */
// 步骤1:
// effectiveScope变量,代表参与当前排序过程所有结点的总数量
for(int effectiveScope = size ; effectiveScope > 1 ; effectiveScope--)
// 步骤2:
for(int currentParent = (effectiveScope >> 1) - 1 ; currentParent >= 0 ; currentParent--)
// 获取左儿子和右儿子的理论索引位
int leftChild = (currentParent << 1) + 1;
int rightChild = leftChild + 1;
int n;
// 首先看左儿子的值大,还是右儿子的值大
if(rightChild < effectiveScope && beSorteds[rightChild] > beSorteds[leftChild])
n = rightChild;
else
n = leftChild;
// 然后比较,值较大的这个儿子和父节点哪个更大,如果后者更大就不进行交换了,否则就要交换
if(beSorteds[n] > beSorteds[currentParent])
int c = beSorteds[currentParent];
beSorteds[currentParent] = beSorteds[n];
beSorteds[n] = c;
// 步骤3:
int c = beSorteds[effectiveScope - 1];
beSorteds[effectiveScope - 1] = beSorteds[0];
beSorteds[0] = c;
// 通过以上堆排序算法的计算,输入的原始数组
// 11 , 88 , 8 , 19 , 129 , 33 , 44 , 22 , 77 , 55 , 505 , 15 , 198 , 189 , 200
// 输出的排序后的数组值为:
// 8 , 11 , 15 , 19 , 22, 33, 44, 55, 77 , 88 , 129 , 189 , 198 , 200 , 505
以上的堆排序算法,充分利用了本小节我们介绍的这些知识点。例如使用“(当前参与排序的结点总数 >> 1) - 1” 的计算公式,找到完全二叉树中最后一个非叶子节点;使用“(当前索引位 << 1)+ 1”和“(currentParent << 1) + 2”的计算公式,找到当前结点的左儿子节点和右儿子节点(后一个公式使用了"左儿子节点 + 1"的计算方式进行了简化)。另外请注意,以上基于大顶堆的排序算法中,由于把每一次查找到的最大值都交换到了尾部索引位上,所以最终排序得到的数组,最小值在数组的第0号索引位上。
3.2、PriorityQueue集合的基本使用
PriorityQueue集合基于堆树进行构建,具体来说是基于数组形式描述的小顶堆进行构建。它保证了每次添加新的数据、移除已有数据后,集合都能维持小顶堆的结构特点。首先我们来看一下PriorityQueue集合最基本的使用方式:
// ......
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();
// 向priorityQueue集合添加数据
priorityQueue.add(11);
priorityQueue.add(88);
priorityQueue.add(8);
priorityQueue.add(19);
priorityQueue.add(129);
priorityQueue.add(33);
priorityQueue.add(44);
priorityQueue.add(22);
priorityQueue.add(77);
priorityQueue.add(55);
priorityQueue.add(505);
priorityQueue.add(15);
priorityQueue.add(198);
priorityQueue.add(189);
priorityQueue.add(200);
// 从priorityQueue集合移除数据
for (int index = 0 ; index < priorityQueue.size() ; )
System.out.println("priorityQueue item = " + priorityQueue.poll());
// ......
// 以上代码的数据输出效果如下:
// priorityQueue item = 8
// priorityQueue item = 11
// priorityQueue item = 15
// priorityQueue item = 19
// priorityQueue item = 22
// priorityQueue item = 33
// priorityQueue item = 44
// priorityQueue item = 55
// priorityQueue item = 77
// priorityQueue item = 88
// priorityQueue item = 129
// priorityQueue item = 189
// priorityQueue item = 198
// priorityQueue item = 200
// priorityQueue item = 505
请注意priorityQueue集合存储的数据类型,要么这个数据类型实现了java.lang.Comparable接口,那么就是在实例化priorityQueue集合时使用者自行实现了java.lang.Comparable接口。否则在进行数据添加时,就会报出“cannot be cast to java.lang.Comparable”异常。
java.lang.Comparable接口主要实现了两个相同类型对象的值对比过程。如以上的代码片段中,Integer类型就实现了Comparable接口,我们常使用的java.lang.String类也实现了Comparable接口。下篇文章将详细介绍PriorityQueue集合中的核心方法,例如堆排序、结点上升和结点下降等。
============
(接下文《源码阅读(13):Java中主要的Queue、Deque结构——PriorityQueue集合(下)》)
以上是关于源码阅读(12):Java中主要的QueueDeque结构——PriorityQueue集合(上)的主要内容,如果未能解决你的问题,请参考以下文章