pytorch案例代码-3
Posted weixin_43739821
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pytorch案例代码-3相关的知识,希望对你有一定的参考价值。
双向循环神经网络
双向循环神经网络在RNN/LSTM/GRU里都有。比如RNN cell,只是把h0和x1传入做线性变换产生h1继续传入同一个cell做线性变换,线性变换的W和b共享,沿着这个方向就把所有隐层和最后的输出算出来了。
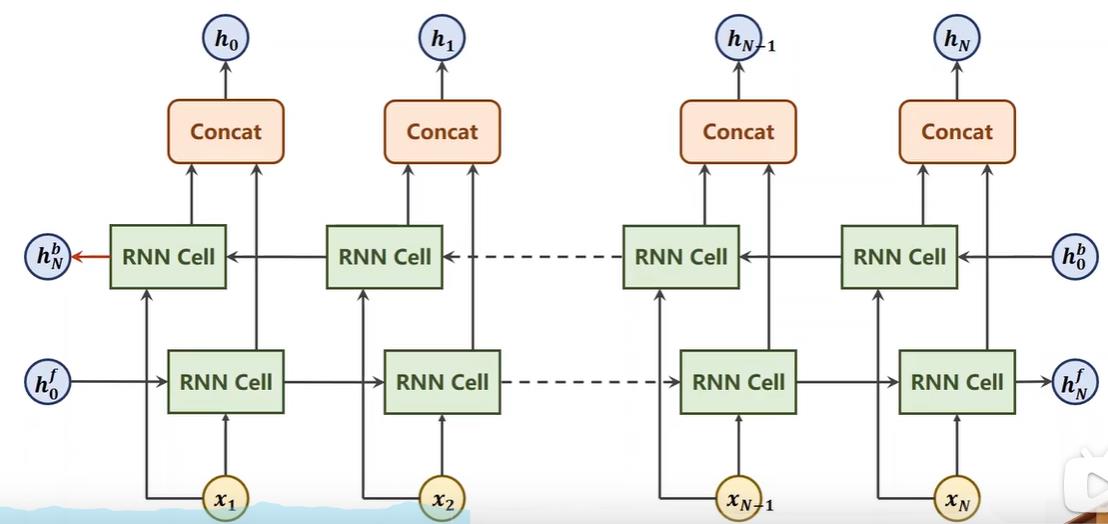
那么其中的每个结点,比如Xn-1的输出只考虑了其之前的信息,即只考虑了过去的所有信息,但实际上有时候在自然语言里我们还需要考虑未来的信息,比如考虑一个词其以后的词会对它产生什么影响。所以双向循环神经网络是在seqlen的forward(与求梯度的forward区别,这里是序列的正向计算)之后,还有一个backward,再往回计算一次,计算的结果与forward的拼接起来得到最终结果。

反向再做一次计算,会将正向和反向的结果做拼接,比如HN包含[H1(b),HN(f)],HN-1是包含[H2(b),HN-1(f)]。反向计算的最终结果是HN(b),比如调用GRU时,会输出out和hidden,hidden就是包含了正向和反向的最终结果HN(f)和HN(b)拼接而成的,out就是上面输出的所有隐层h0到hN。
所以如果是双向的网络,那么最终输出的隐层是以前的俩倍大小,out也是拼接得来的所以也是俩倍。

循环神经网络——实现一个循环神经网络的分类器
解决对名字进行分类的问题,用几千个来自18个语言的人的名字进行训练,模型可以根据拼写来预测人名属于哪种语言。
因为我们只关心最后名字的分类所以模型可以变得更简单,由下面图1转为图2,我们只关心最终的隐层状态,然后在通过一个全连接分成18个类别。


并且我们将定义的模型改成使用gru,这里x虽然看起来只有一个数据,但是实际上一个Maclean的名字,是由多个单词组成,即x1、x2、x3…组成一个单词,我们输入的是x1、x2、x3…这样的序列,因为名字长短不一,所以输入也不一,这是我们需要考虑的。

我们使用自己定义的分类器RNNClassfier,传入的参数分别是,传入的字符数量(名字有多少个字母),隐层数量 (gru输出结果大小),分类数量,用几层的gru。
下面代码会定义一个time变量就可传入定义的time_since函数用于打印距离开始训练时训练时间有多长。
在循环里面可以分别将训练和测试封装调用,然后把测试结果添加到列表这样就可以把记录下来的准确率用于绘图


数据准备方面,由于输入的是序列,所以要先把字符串转为一个个字符,由于字符正好可以在ascii上对应,也可以采用128维的ascii表,我们只需要告诉嵌入层每个字符对应的独热向量第几个维度是1,让嵌入层帮我们转成稠密的形式就行,所以我们只需要把其ascii码值传入就行。
由于数据长短不一,所以我们还需要做一个padding,因为训练的inputs是一个个数据组成的batch_size,这种数据长短不一的不能组成张量批量运算,padding的长度与最长的字符串对齐。
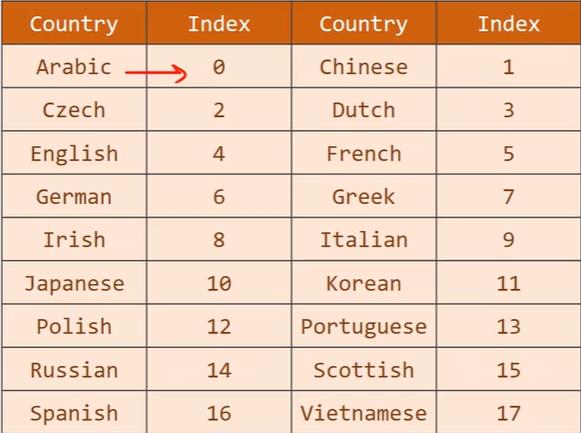
国家的名字也要做一个索引。
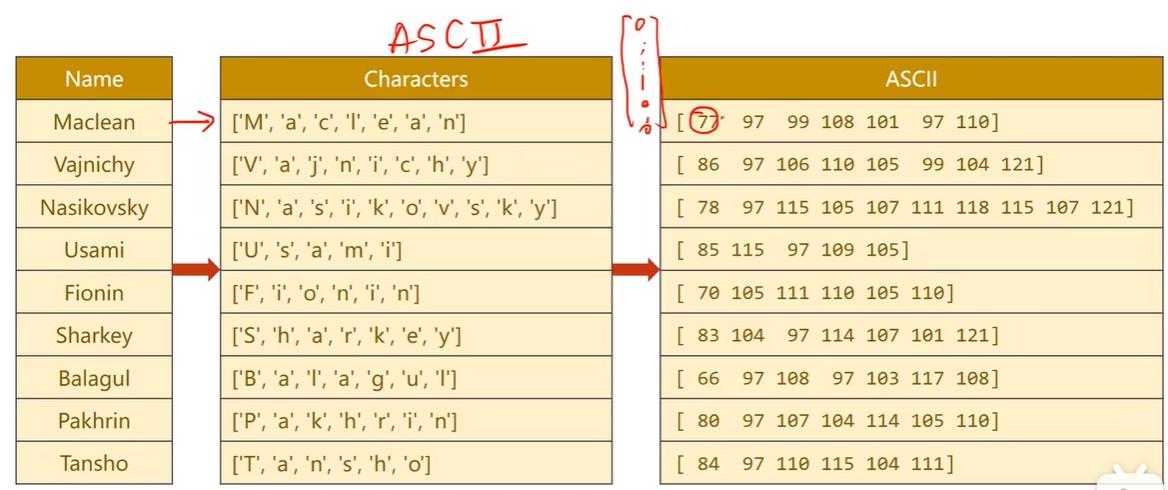

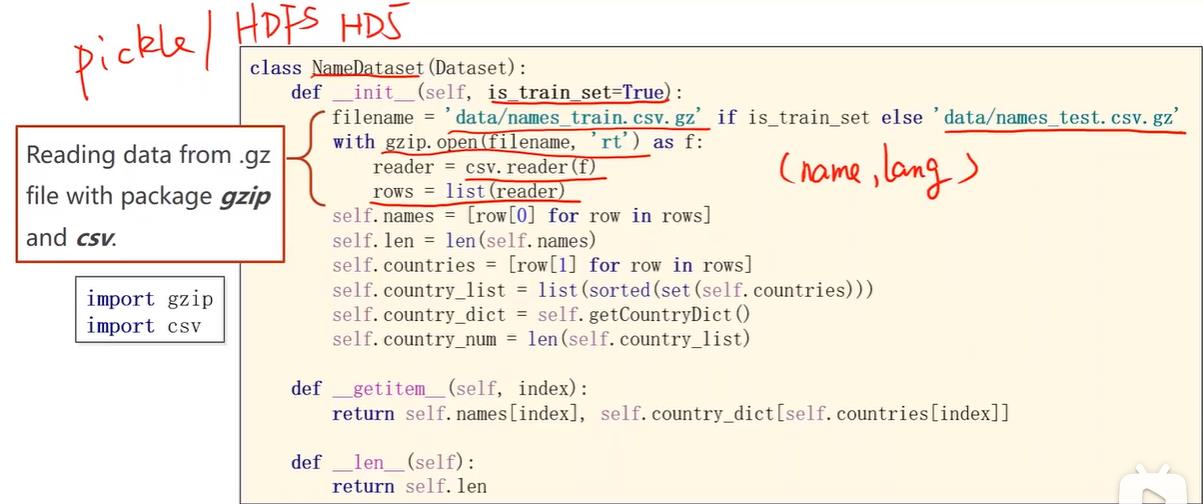
名字的数据读取方面,由于几千个名字占不了多少内存,所以可以一次性读入,当然如果一次全部转成张量数据量会比较大。传入is_train_set决定是读入训练集还是测试集,gz是linux中压缩文件格式,可以通过gzip读压缩包。
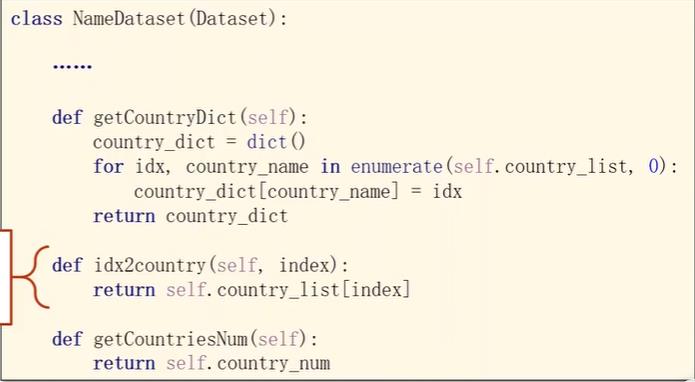
把csv的所有行读入到rows中,每一行是一个元组包含名字和国家,将名字和国家读出。其中国家因为要做索引,所以用set把列表变成集合去除重复元素,然后排序之后形成列表,然后调用getCountryDict将列表转变成上面一张图中的索引词典,便于在getitem中索引访问可以输出名字和国家对应的索引。

参数见下图,每一批数据采用 256的大小,隐层100大小,用俩层gru,训练100轮,字符长度根据ascii码设置成128的大小。

模型的设计,看一下传入的参数,hidden_size是GRU的输入和输出大小,n_layers是GRU的层数,imput_size(表示输入字典长度)和hidden_size也是嵌入层的构造参数,别忘记嵌入层的构造参数和输入参数是不一样的概念,构造参数是构造这个嵌入层时使用的,输入参数是使用这个嵌入层处理传入的数据的时候使用的数据参数,其输入参数如图二所示 。 bidirectional这个参数用来表示GRU是单向还是双向的。最后还需要一个全连接把hidden_size转成output_size,如果是双向的还需要乘上n_bidirections。 然后就是初始化h0的函数,注意如果有多层GRU,H0则构造时要乘上n_layers。



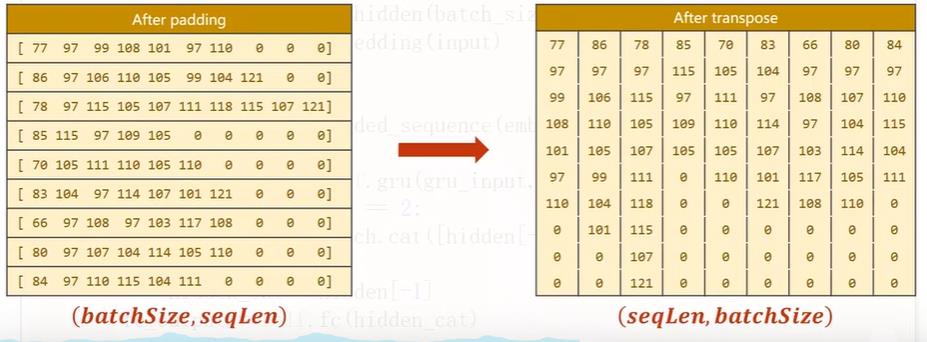
然后看一下forward的过程,首先将数据转置,此时二维矩阵横向是batch,纵向是seq,将输入数据由(batch_size,seq_len)转为(seq_len,batch_size),因为这是嵌入层需要的维度,同时保存batch_size数据以便构造最初始的隐层。
再将数据丢入嵌入层,数据转变为(seq_len,batch_size,hidden_size)
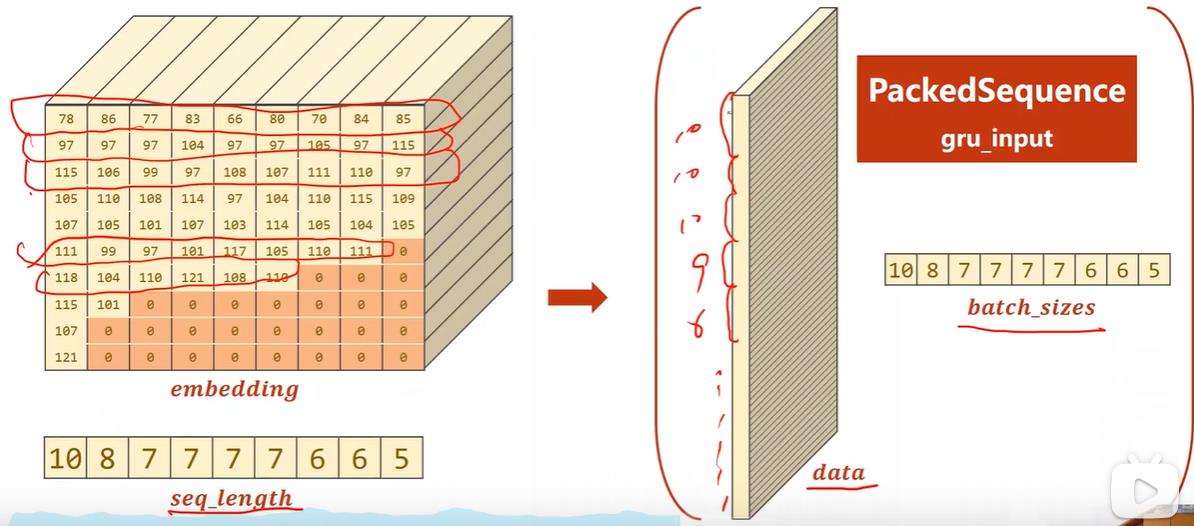
下面用到pytorch提供的pack_padded_sequence函数,当在使用LSTM、GRU或RNN进行语义分析遇到数据长短不一的情况时这个函数可以加快运算,因为较短的数据填充的都是0,这些数据没有必要参与运算。
如图三~五所示,需要先将padding之后的数据按长短进行排序,排序之后再经过嵌入层转成稠密向量,拿到数据后再传入函数打包返回最终的PackedSquence object来传入GRU进行运算得到我们想要的最终结果即hidden。
如果是双休循环神经网络,要注意有俩个hidden,所以要把这俩个拼接起来,最后放到fc层变换到我们想要的维度。



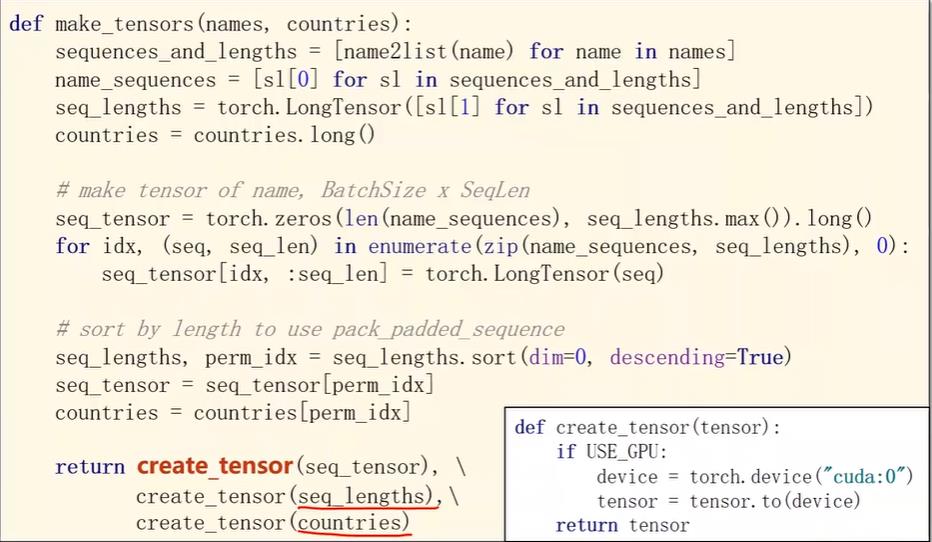
接下来看看数据处理过程,数据需要转成张量,且嵌入层要求所有数据是长整型的。 首先name2list如下,其把每一个名字变成一个列表,过程就是把每一个字符的ascii码值取出生成ascii码列表,返回名字对应的列表和列表长度的元组
def name2list(name):
arr = [ord(c) for c in name]
return arr, len(arr)
然后单独把名字和长度提取成俩个列表,将长度转成长整型,名字对应的国家传入就是整数所以直接转成长整型。
接下来就是padding的过程,我们先做一个全0的张量,然后用复制的操作把名字列表贴到全0张量上去。
做完padding之后是排序,按照序列长度进行排序,用排序得到的索引下标对名字和国家进行排序。最后经过一个是否使用gpu的判断函数输出数据。
然后就是训练过程,跟以前没有太大区别。 测试过程也跟以前一样,分类器分完之后找概率最大值的国家,然后算一共预测对了多少


训练结果如下,可以看到当训练到20轮时达到最好的效果,可以使用模型.save来保存,测试当前模型是不是准确率最高,如果是最高的就保存当前模型。

PS:训练好的模型,比如写诗的模型,根据标题写作文的模型,不想要每次固定输入一个值得到的一定是同一个结果的话,可以采用“重要性采样”,因为线性层输出的是各个结果的概率,每次一定采用概率最大的结果,使用重要性采样使得那些概率小的结果也可能被采纳,但是相对来说还是概率大一些的结果容易被选中,这样就保证了输入同一个值可能会得到不同的结果。
以上是关于pytorch案例代码-3的主要内容,如果未能解决你的问题,请参考以下文章