创建博客应用
Posted 一个处女座的测试
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了创建博客应用相关的知识,希望对你有一定的参考价值。
第一章 创建博客应用
欢迎来到Django 2 by example的教程。你看到的是目前全网唯一翻译该书的教程。
本书将介绍如何创建可以用于生产环境的完整Django项目。如果你还没有安装Django,本章在第一部分中将介绍如何安装Django,之后的内容还包括创建一个简单的博客应用。本章的目的是让读者对Django的整体运行有一个概念,理解Django的各个组件如何交互运作,知道创建一个应用的基础方法。本书将指导你创建一个个完整的项目,但不会对所有细节进行详细阐述,Django各个组件的内容会在全书的各个部分内进行解释。
本章的主要内容有:
安装Django并创建第一个项目
设计数据模型和进行模型迁移(migrations)
为数据模型创建管理后台
使用QuerySet和模型管理器
创建视图、模板和URLs
给列表功能的视图添加分页功能
使用基于类的视图
1安装Django
如果已经安装了Django,可以跳过本部分到创建第一个Django项目小节。Django是Python的一个包(模块),所以可以安装在任何Python环境。如果还没有安装Django,本节是一个用于本地开发的快速安装Django指南。
Django 2.0需要Python解释器的版本为3.4或更高。在本书中,采用Python 3.6.5版本,如果使用Linux或者macOS X,系统中也许已经安装Python(部分Liunx发行版初始安装Python2.7),对于Windows系统,从https://www.python.org/downloads/windows/下载Python安装包。
译者在此强烈建议使用基于UNIX的系统进行开发。
如果不确定系统中是否已经安装了Python,可以尝试在系统命令行中输入python然后查看输出结果,如果看到类似下列信息,则说明Python已经安装:
CopyPython 3.6.5 (v3.6.5:f59c0932b4, Mar 28 2018, 03:03:55)
[GCC 4.2.1 (Apple Inc. build 5666) (dot 3)] on darwin
Type "help", "copyright", "credits" or "license"for more information.
>>>如果安装的版本低于3.4,或者没有安装Python,从https://www.python.org/downloads/下载并安装。
由于我们使用Python 3,所以暂时不需要安装数据库,因为Python 3自带一个轻量级的SQLite3数据库可以用于Django开发。如果打算在生产环境中部署Django项目,需要使用更高级的数据库,比如PostgreSQL,mysql或者Oracle数据库。关于如何在Django中使用数据库,可以看官方文档https://docs.djangoproject.com/en/2.0/topics/install/#database-installation。
译者注:在翻译本书和实验代码的时候,译者的开发环境是Centos 7.5 1804 + Python 3.7.0 + Django 2.1.0(最后一章升级到Django 2.1.2),除了后文会提到的一个旧版本第三方库插件冲突的问题之外,未发现任何兼容性问题。
1.1创建独立的Python开发环境
推荐使用virtualenv创建独立的开发环境,这样可以对不同的项目应用不同版本的模块,比将这些模块直接安装为系统Python的第三方库要灵活很多。另一个使用virtualenv的优点是安装Python模块的时候不需要任何管理员权限。在系统命令行中输入如下命令来安装virtualenv:
Copypip install virtualenv在安装完virtualenv之后,通过以下命令创建一个独立环境:
Copyvirtualenv my_env译者注:需要将virtualenv的所在路径添加到系统环境变量PATH中,对于Django也是如此,不然无法直接执行django-admin命令。
这个命令会在当前目录下创建一个my_env/目录,其中放着一个Python虚拟环境。在虚拟环境中安装的Python包实际会被安装到my_env/lib/python3.6/site-packages目录中。
如果操作系统中安装的是Python 2.X,必须再安装Python 3.X,还需要设置virtualenv虚拟Python 3.X的环境。
可以通过如下命令查找Python 3的安装路径,然后创建虚拟环境:
Copyzenx$ which python3
/Library/Frameworks/Python.framework/Versions/3.6/bin/python3
zenx$ virtualenv my_env -p /Library/Frameworks/Python.framework/Versions/3.6/bin/python3根据Linux发行版的不同,上边的代码也会有所不同。在创建了虚拟环境对应的目录之后,使用如下命令激活虚拟环境:
Copysource my_env/bin/activate激活之后,在命令行模式的提示符前会显示括号包住该虚拟环境的名称,如下所示:
Copy(my_env)laptop:~ zenx$开启虚拟环境后,随时可以通过在命令行中输入deactivate来退出虚拟环境。
关于virtualenv的更多内容可以查看https://virtualenv.pypa.io/en/latest/。
virtualenvwrapper这个工具可以方便的创建和管理系统中的所有虚拟环境,需要在系统中先安装virtualenv,可以到https://virtualenvwrapper.readthedocs.io/en/latest/下载。
1.2使用PIP安装Django
推荐使用pip包安装Django。Python 3.6已经预装了pip,也可以在https://pip.pypa.io/en/stable/installing/找到pip的安装指南。
使用下边的命令安装Django:
Copypip install Django==2.0.5译者这里安装的是2.1版。
Django会被安装到虚拟环境下的site-packages/目录中。
现在可以检查Django是否已经成功安装,在系统命令行模式运行python,然后导入Django,检查版本,如下:
Copy>>> import django
>>> django.get_version()
'2.0.5'如果看到了这个输出,就说明Django已经成功安装了。
Django的其他安装方式,可以查看官方文档完整的安装指南:https://docs.djangoproject.com/en/2.0/topics/install/。
2创建第一个Django项目
本书的第一个项目是创建一个完整的博客项目。Django提供了一个创建项目并且初始化其中目录结构和文件的命令,在命令行模式中输入:
Copydjango-admin startproject mysite这会创建一个项目,名称叫做mysite。
避免使用Python或Django的内置名称作为项目名称。
看一下项目目录的结构:
Copymysite/
manage.py
mysite/
__init__.py
settings.py
urls.py
wsgi.py这些文件解释如下:
manage.py:是一个命令行工具,可以通过这个文件管理项目。其实是一个django-admin.py的包装器,这个文件在创建项目过程中不需要编辑。
mysite/:这是项目目录,由以下文件组成:
__init__.py:一个空文件,告诉Python将mysite看成一个包。
settings.py:这是当前项目的设置文件,包含一些初始设置
urls.py:这是URL patterns的所在地,其中的每一行URL,表示URL地址与视图的一对一映射关系。
wsgi.py:这是自动生成的当前项目的WSGI程序,用于将项目作为一个WSGI程序启动。
自动生成的settings.py是当前项目的配置文件,包含一个用于使用SQLite 3 数据库的设置,以及一个叫做INSTALLED_APPS的列表。INSTALLED_APPS包含Django默认添加到一个新项目中的所有应用。在之后的项目设置部分会接触到这些应用。
为了完成项目创建,还必须在数据库里创建起INSTALLED_APPS中的应用所需的数据表,打开系统命令行输入下列命令:
Copycd mysite
python manage.py migrate会看到如下输出:
CopyApplying contenttypes.0001_initial... OK
Applying auth.0001_initial... OK
Applying admin.0001_initial... OK
Applying admin.0002_logentry_remove_auto_add... OK
Applying contenttypes.0002_remove_content_type_name... OK
Applying auth.0002_alter_permission_name_max_length... OK
Applying auth.0003_alter_user_email_max_length... OK
Applying auth.0004_alter_user_username_opts... OK
Applying auth.0005_alter_user_last_login_null... OK
Applying auth.0006_require_contenttypes_0002... OK
Applying auth.0007_alter_validators_add_error_messages... OK
Applying auth.0008_alter_user_username_max_length... OK
Applying auth.0009_alter_user_last_name_max_length... OK
Applying sessions.0001_initial... OK这些输出表示Django刚刚执行的数据库迁移(migrate)工作,在数据库中创建了这些应用所需的数据表。在本章的创建和执行迁移部分会详细介绍migrate命令。
2.1运行开发中的站点
Django提供了一个轻量级的Web服务程序,无需在生产环境即可快速测试开发中的站点。启动这个服务之后,会检查所有的代码是否正确,还可以在代码被修改之后,自动重新载入修改后的代码,但部分情况下比如向项目中加入了新的文件,还需要手工关闭服务再重新启动。
在命令行中输入下列命令就可以启动站点:
Copypython manage.py runserver应该会看到下列输出:
CopyPerforming system checks...
System check identified no issues (0 silenced).
May 06, 2018 - 17:17:31
Django version 2.0.5, using settings 'mysite.settings'
Starting development server at http://127.0.0.1:8000/
Quit the server with CONTROL-C.现在可以在浏览器中打开http://127.0.0.1:8000/,会看到成功运行站点的页面,如下图所示:
能看到这个页面,说明Django正在运行,如果此时看一下刚才启动站点的命令行窗口,可以看到浏览器的GET请求:
Copy[15/May/2018 17:20:30] "GET / HTTP/1.1" 200 16348站点接受的每一个HTTP请求,都会显示在命令行窗口中,如果站点发生错误,也会将错误显示在该窗口中。
在启动站点的时候,还可以指定具体的主机地址和端口,或者使用另外一个配置文件,例如:
Copypython manage.py runserver 127.0.0.1:8001 --settings=mysite.settings如果站点需要在不同环境下运行,单独为每个环境创建匹配的配置文件。
当前这个站点只能用作开发测试,不能够配置为生产用途。想要将Django配置到生产环境中,必须通过一个Web服务程序比如Apache,Gunicorn或者uWSGI,将Django作为一个WSGI程序运行。使用不同web服务程序部署Django请参考:https://docs.djangoproject.com/en/2.0/howto/deployment/wsgi/。本书的第十三章 上线会介绍如何配置生产环境。
2.2项目设置
打开settings.py看一下项目设置,其中列出了一些设置,但这只是Django所有设置的一部分。可以在https://docs.djangoproject.com/en/2.0/ref/settings/查看所有的设置和初始值。
文件中的以下设置值得注意:
DEBUG是一个布尔值,控制DEBUG模式的开启或关闭。当设置为True时,Django会将所有的日志和错误信息都打印在窗口中。在生产环境中则必须设置为False,否则会导致信息泄露。
ALLOWED_HOSTS在本地开发的时候,无需设置。在生产环境中,DEBUG设置为False时,必须将主机名/IP地址填入该列表中,以让Django为该主机/IP提供服务。
INSTALLED_APPS列出了每个项目当前激活的应用,Django默认包含下列应用:
django.contrib.admin:管理后台应用
django.contrib.auth:用户身份认证
django.contrib.contenttypes:追踪ORM模型与应用的对应关系
django.contrib.sessions:session应用
django.contrib.messages:消息应用
django.contrib.staticfiles:管理站点静态文件
MIDDLEWARE是中间件列表。
ROOT_URLCONF指定项目的根URL patterns配置文件。
DATABASE是一个字典,包含不同名称的数据库及其具体设置,必须始终有一个名称为default的数据库,默认使用SQLite 3数据库。
LANGUAGE_CODE站点默认的语言代码。
USE_TZ是否启用时区支持,Django可以支持根据时区自动切换时间显示。如果通过startproject命令创建站点,该项默认被设置为True。
如果目前对这些设置不太理解也没有关系,在之后的章节中这里的设置都会使用到。
2.3项目(projects)与应用(applications)
在整本书中,这两个词会反复出现。在Django中,像我们刚才那样的一套目录结构和其中的设置就是一个Django可识别的项目。应用指的就是一组Model(数据模型)、Views(视图)、Templates(模板)和URLs的集合。Django框架通过使用应用,为站点提供各种功能,应用还可以被复用在不同的项目中。你可以将一个项目理解为一个站点,站点中包含很多功能,比如博客,wiki,论坛,每一种功能都可以看作是一个应用。
2.4创建一个应用
我们将从头开始创建一个博客应用,进入项目根目录(manage.py文件所在的路径),在系统命令行中输入以下命令创建第一个Django应用:
Copypython manage.py startapp blog这条命令会在项目根目录下创建一个如下结构的应用:
Copyblog/
__init__.py
admin.py
apps.py
migrations/
__init__.py
models.py
tests.py
views.py这些文件的含义为:
admin.py:用于将模型注册到管理后台,以便在Django的管理后台(Django administration site)查看。管理后台也是一个可选的应用。
apps.py:当前应用的主要配置文件
migrations这个目录包含应用的数据迁移记录,用来追踪数据模型的变化然后和数据库同步。
models.py:当前应用的数据模型,所有的应用必须包含一个models.py文件,但其中内容可以是空白。
test.py:为应用增加测试代码的文件
views.py:应用的业务逻辑部分,每一个视图接受一个HTTP请求,处理这个请求然后返回一个HTTP响应。
3设计博客应用的数据架构(data schema)
schema是一个数据库名词,一般指的是数据在数据库中的组织模式或者说架构。我们将通过在Django中定义数据模型来设计我们博客应用在数据库中的数据架构。一个数据模型,是指一个继承了django.db.models.Model的Python 类。Django会为在models.py文件中定义的每一个类,在数据库中创建对应的数据表。Django为创建和操作数据模型提供了一系列便捷的API(Django ORM):
我们首先来定义一个Post类,在blog应用下的models.py文件中添加下列代码:
Copyfrom django.db import models
from django.utils import timezone
from django.contrib.auth.models import User
classPost(models.Model):
STATUS_CHOICES = (('draft', 'Draft'), ('published', 'Published'))
title = models.CharField(max_length=250)
slug = models.SlugField(max_length=250, unique_for_date='publish')
author = models.ForeignKey(User, on_delete=models.CASCADE, related_name='blog_posts')
body = models.TextField()
publish = models.DateTimeField(default=timezone.now())
created = models.DateTimeField(auto_now_add=True)
updated = models.DateTimeField(auto_now=True)
status = models.CharField(max_length=10, choices=STATUS_CHOICES, default='draft')
classMeta:
ordering = ('-publish',)
def__str__(self):
return self.title这是我们为了博客中每一篇文章定义的数据模型:
title:这是文章标题字段。这个字段被设置为Charfield类型,在SQL数据库中对应VARCHAR数据类型
slug:该字段通常在URL中使用。slug是一个短的字符串,只能包含字母,数字,下划线和减号。将使用slug字段构成优美的URL,也方便搜索引擎搜索。其中的unique_for_date参数表示不允许两条记录的publish字段日期和title字段全都相同,这样就可以使用文章发布的日期与slug字段共同生成一个唯一的URL标识该文章。
author:是一个外键字段。通过这个外键,告诉Django一篇文章只有一个作者,一个作者可以写多篇文章。对于这个字段,Django会在数据库中使用外键关联到相关数据表的主键上。在这个例子中,这个外键关联到Django内置用户验证模块的User数据模型上。on_delete参数表示删除外键关联的内容时候的操作,这个并不是Django特有的定义,而是SQL 数据库的标准操作;将其设置为CASCADE意味着如果删除一个作者,将自动删除所有与这个作者关联的文章,对于该参数的设置,可以查看https://docs.djangoproject.com/en/2.0/ref/models/fields/#django.db.models.ForeignKey.on_delete。related_name参数设置了从User到Post的反向关联关系,用blog_posts为这个反向关联关系命名,稍后会学习到该关系的使用。
body:是文章的正文部分。这个字段是一个文本域,对应SQL数据库的TEXT数据类型。
publish:文章发布的时间。使用了django.utils.timezone.now作为默认值,这是一个包含时区的时间对象,可以将其认为是带有时区功能的Python标准库中的datetime.now方法。
created:表示创建该文章的时间。auto_now_add表示当创建一行数据的时候,自动用创建数据的时间填充。
updated:表示文章最后一次修改的时间,auto_now表示每次更新数据的时候,都会用当前的时间填充该字段。
statues:这个字段表示该文章的状态,使用了一个choices参数,所以这个字段的值只能为一系列选项中的值。
Django提供了很多不同类型的字段可以用于数据模型,具体可以参考:https://docs.djangoproject.com/en/2.0/ref/models/fields/。
在数据模型中的Meta类表示存放模型的元数据。通过定义ordering = ('-publish',),指定了Django在进行数据库查询的时候,默认按照发布时间的逆序将查询结果排序。逆序通过加在字段名前的减号表示。这样最近发布的文章就会排在前边。
__str__()方法是Python类的功能,供显示给人阅读的信息,这里将其设置为文章的标题。Django在很多地方比如管理后台中都调用该方法显示对象信息。
如果你之前使用的是Python 2.X,注意在Python 3中,所有的字符串都已经是原生Unicode格式,所以只需要定义__str__()方法,__unicode__()方法已被废弃。
3.1激活应用
为了让Django可以为应用中的数据模型创建数据表并追踪数据模型的变化,必须在项目里激活应用。要激活应用,编辑settings.py文件,添加blog.apps.BlogConfig到INSTALLED_APPS设置中:
CopyINSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'blog.apps.BlogConfig',
]BlogConfig类是我们应用的配置类。现在Django就已经知道项目中包含了一个新应用,可以载入这个应用的数据模型了。
3.2创建和执行迁移
创建好了博客文章的数据模型,之后需要将其变成数据库中的数据表。Django提供数据迁移系统,用于追踪数据模型的变动,然后将变化写入到数据库中。我们之前执行过的migrate命令会对INSTALLED_APPS中的所有应用进行扫描,根据数据模型和已经存在的迁移数据执行数据库同步操作。
首先,我们需要来为Post模型创建迁移数据,进入项目根目录,输入下列命令:
Copypython manage.py makemigrations blog会看到如下输出:
CopyMigrations for'blog':
blog/migrations/0001_initial.py
- Create model Post该命令执行后会在blog应用下的migrations目录里新增一个0001_initial.py文件,可以打开该文件看一下迁移数据是什么样子的。一个迁移数据文件里包含了与其他迁移数据的依赖关系,以及实际要对数据库执行的操作。
为了了解Django实际执行的SQL语句,可以使用sqlmigrate加上迁移文件名,会列出要执行的SQL语句,但不会实际执行。在命令行中输入下列命令然后观察数据迁移的指令:
Copypython manage.py sqlmigrate blog 0001输出应该如下所示:
CopyBEGIN;
--
-- Create model Post
--
CREATE TABLE "blog_post" ("id"integer NOT NULL PRIMARY KEY AUTOINCREMENT,
"title" varchar(250) NOT NULL, "slug" varchar(250) NOT NULL, "body" text NOT
NULL, "publish" datetime NOT NULL, "created" datetime NOT NULL, "updated"
datetime NOT NULL, "status" varchar(10) NOT NULL, "author_id"integer NOT
NULL REFERENCES "auth_user" ("id"));
CREATE INDEX "blog_post_slug_b95473f2" ON "blog_post" ("slug");
CREATE INDEX "blog_post_author_id_dd7a8485" ON "blog_post" ("author_id");
COMMIT;具体的输出根据你使用的数据库会有变化。上边的输出针对SQLite数据库。可以看到表名被设置为应用名加上小写的类名(blog_post)也可以通过在Meta类中使用db_table属性设置表名。Django自动为每个模型创建了主键,也可以通过设置某个模型字段参数primary_key=True来指定主键。默认的主键列名叫做id,和这个列同名的id字段会自动添加到你的数据模型上。(即Post类被Django添加了Post.id属性)。
然后来让数据库与新的数据模型进行同步,在命令行中输入下列命令:
Copypython manage.py migrate会看到如下输出:
CopyApplying blog.0001_initial... OK这样就对INSTALLED_APPS中的所有应用执行完了数据迁移过程,包括我们的blog应用。在执行完迁移之后,数据库中的数据表就反映了我们此时的数据模型。
如果之后又编辑了models.py文件,对已经存在的数据模型进行了增删改,或者又添加了新的数据模型,必须重新执行makemigrations创建新的数据迁移文件然后执行migrate命令同步数据库。
4为数据模型创建管理后台站点(administration site)
定义了Post数据模型之后,可以为方便的管理其中的数据创建一个简单的管理后台。Django内置了一个管理后台,这个管理后台动态的读入数据模型,然后创建一个完备的管理界面,从而可以方便的管理数据。这是一个可以“拿来就用”的方便工具。
管理后台功能其实也是一个应用叫做django.contrib.admin,默认包含在INSTALLED_APPS设置中。
4.1创建超级用户
要使用管理后台,需要先注册一个超级用户,输入下列命令:
Copypython manage.py createsuperuser会看到下列输出,输入用户名、密码和邮件:
CopyUsername (leave blank to use 'admin'): admin
Email address: admin@admin.com
Password:
Password (again):
Superuser created successfully.4.2Django 管理后台
使用python manage.py runserver启动站点,然后打开http://127.0.0.1:8000/admin/,可以看到如下的管理后台登录页面:
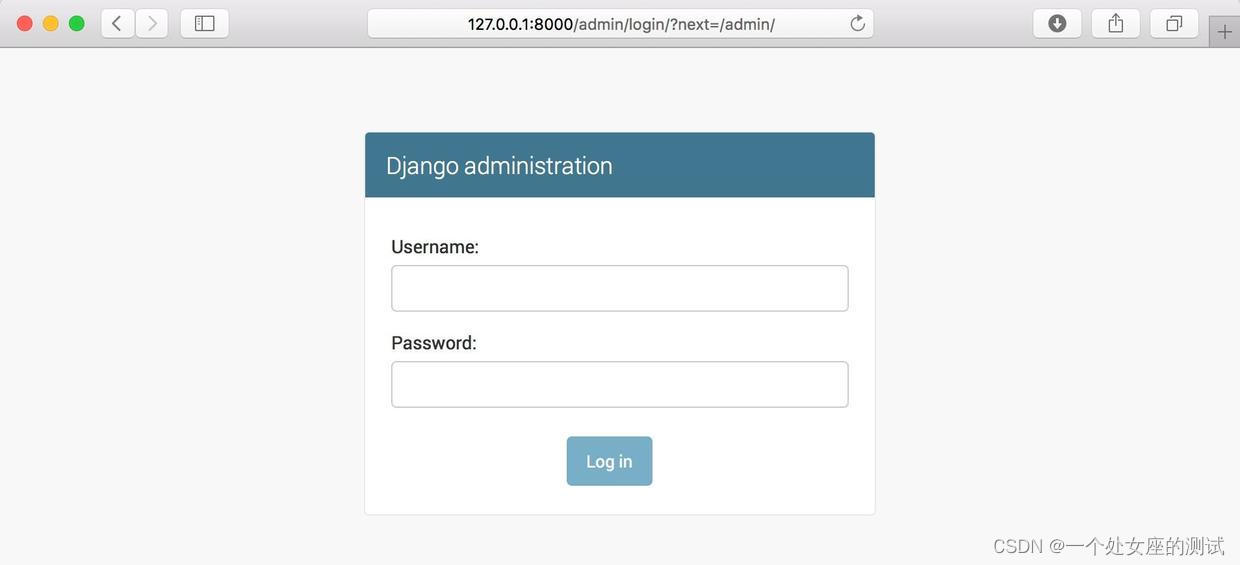
输入刚才创建的超级用户的用户名和密码,可以看到管理后台首页,如下所示:
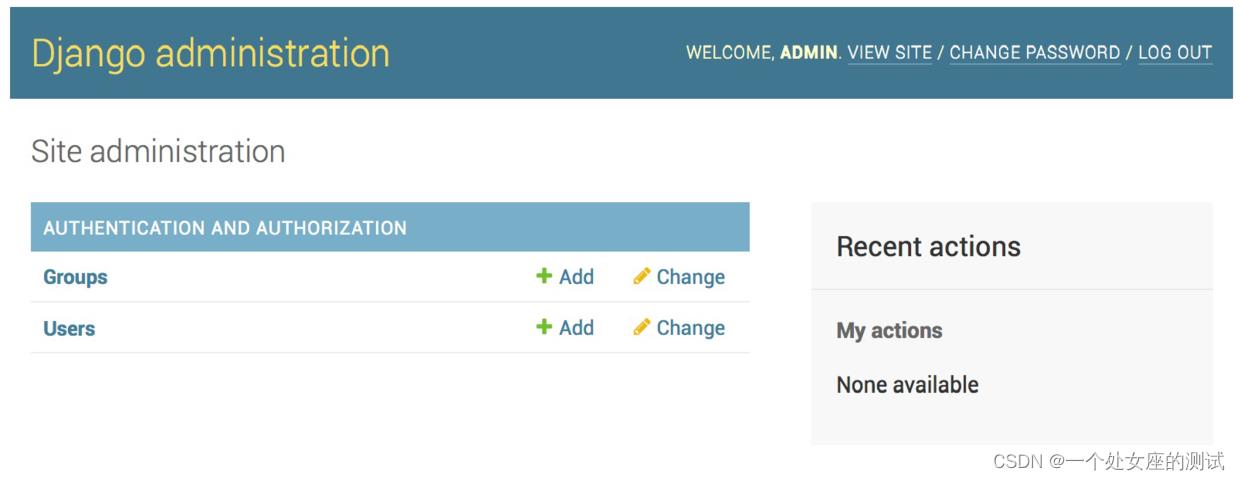
Group和User已经存在于管理后台中,这是因为设置中默认启用了django.contrib.auth应用的原因。如果你点击Users,可以看到刚刚创建的超级用户。还记得blog应用的Post模型与User模型通过author字段产生外键关联吗?
4.3向管理后台内添加模型
我们把Post模型添加到管理后台中,编辑blog应用的admin.py文件为如下这样:
Copyfrom django.contrib import admin
from .models import Post
admin.site.register(Post)之后刷新管理后台页面,可以看到Post类出现在管理后台中:
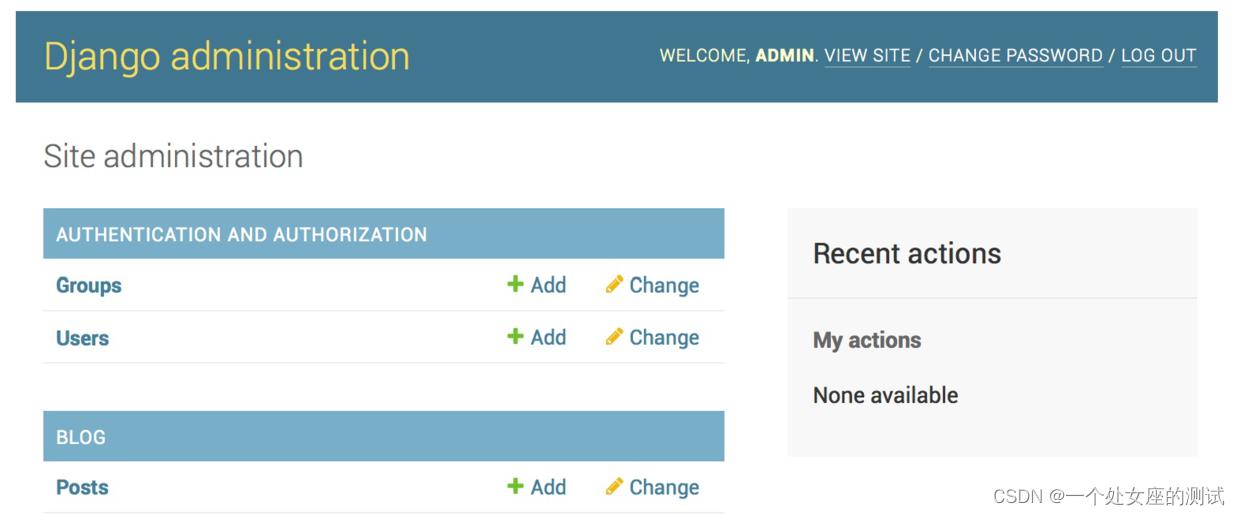
看上去好像很简单。每当在管理后台中注册一个模型,就能迅速在管理后台中看到它,还可以对其进行增删改查。
点击Posts右侧的Add链接,可以看到Django根据模型的具体字段动态的生成了添加页面,如下所示:
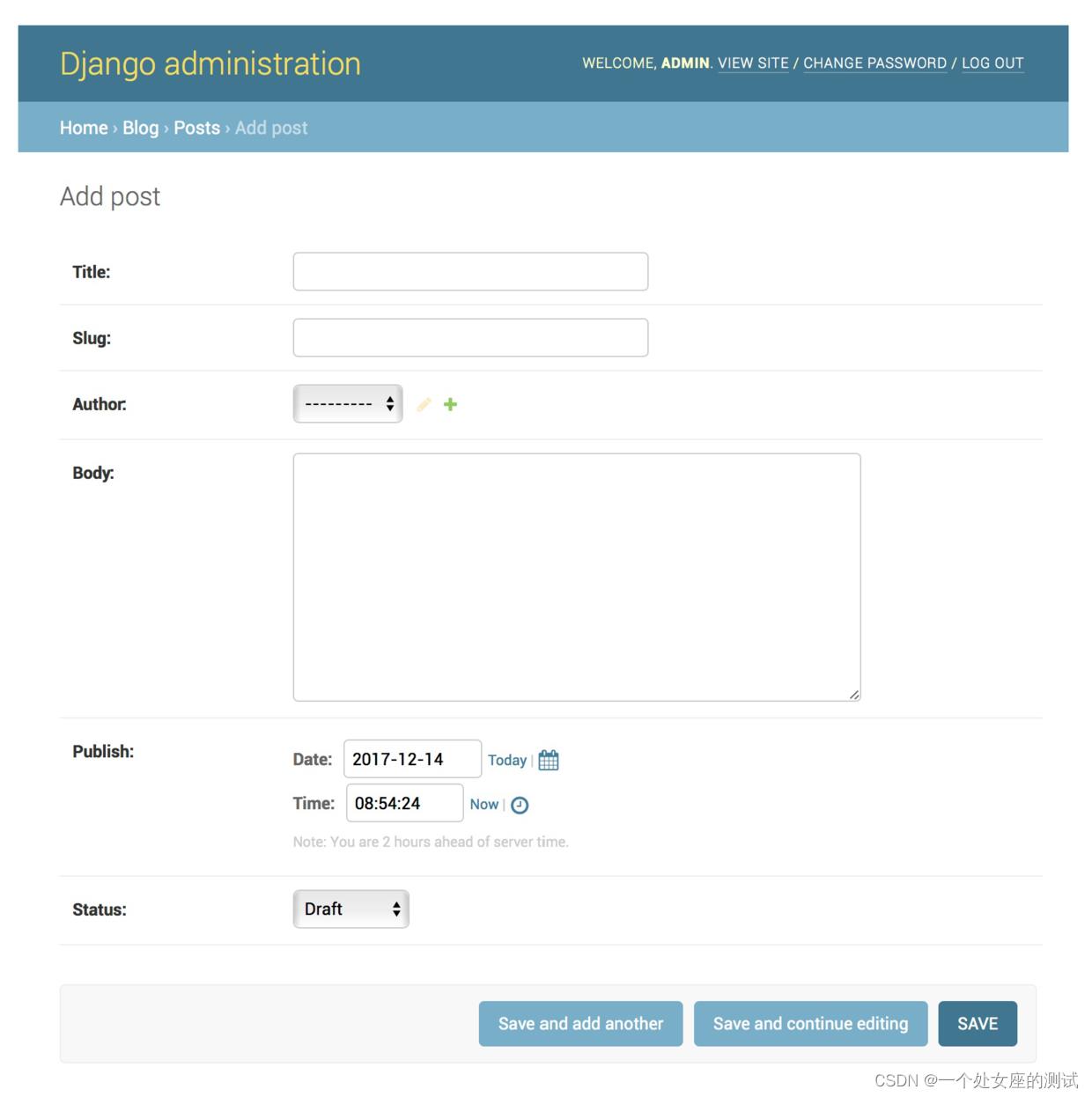
Django对于每个字段使用不同的表单插件(form widgets,控制该字段实际在页面上对应的html元素)。即使是比较复杂的字段比如DateTimeField,也会以简单的界面显示出来,类似于一个javascript的时间控件。
填写完这个表单然后点击SAVE按钮,被重定向到文章列表页然后显示一条成功信息,像下面这样:
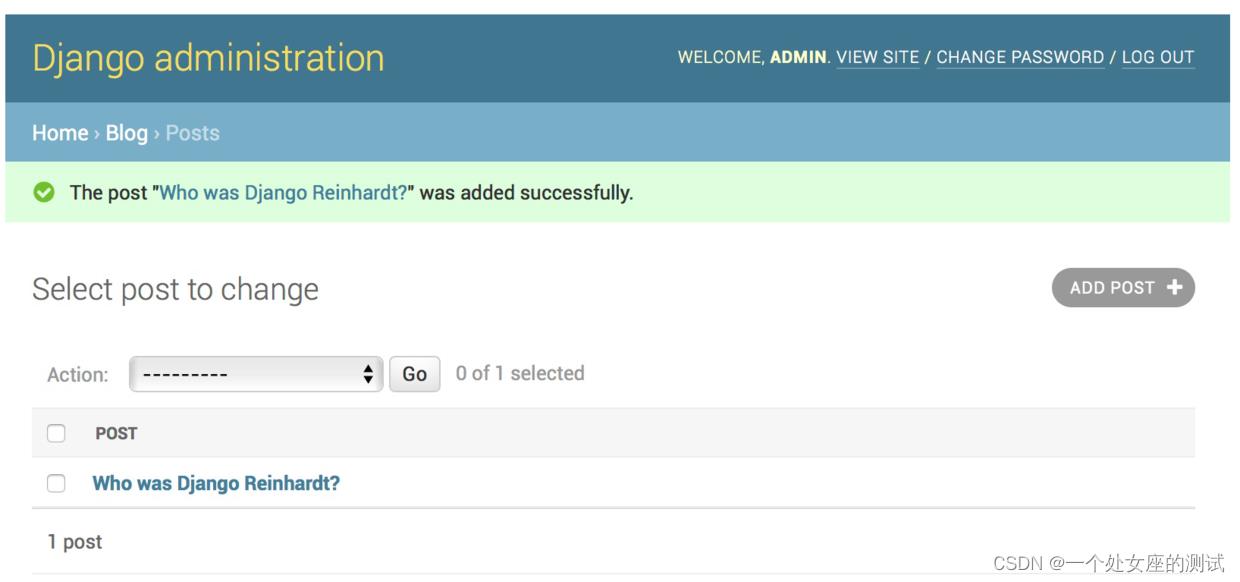
可以再录入一些文章数据,为之后数据库相关操作做准备。
4.4自定义模型在管理后台的显示
现在我们来看一下如何自定义管理后台,编辑blog应用的admin.py,修改成如下:
Copyfrom django.contrib import admin
from .models import Post
@admin.register(Post)classPostAdmin(admin.ModelAdmin):
list_display = ('title', 'slug', 'author', 'publish', 'status')这段代码的意思是将我们的模型注册到管理后台中,并且创建了一个类继承admin.ModelAdmin用于自定义模型的展示方式和行为。list_display属性指定那些字段在详情页中显示出来。@admin.register()装饰器的功能与之前的admin.site.register()一样,用于将PostAdmin类注册成Post的管理类。
再继续添加一些自定义设置,如下所示:
Copy@admin.register(Post)classPostAdmin(admin.ModelAdmin):
list_display = ('title', 'slug', 'author', 'publish', 'status',)
list_filter = ('status', 'created', 'publish', 'author',)
search_fields = ('title', 'body',)
prepopulated_fields = 'slug': ('title',)
raw_id_fields = ('author',)
date_hierarchy = 'publish'
ordering = ('status', 'publish',)回到浏览器,刷新一下posts的列表页,会看到如下所示:
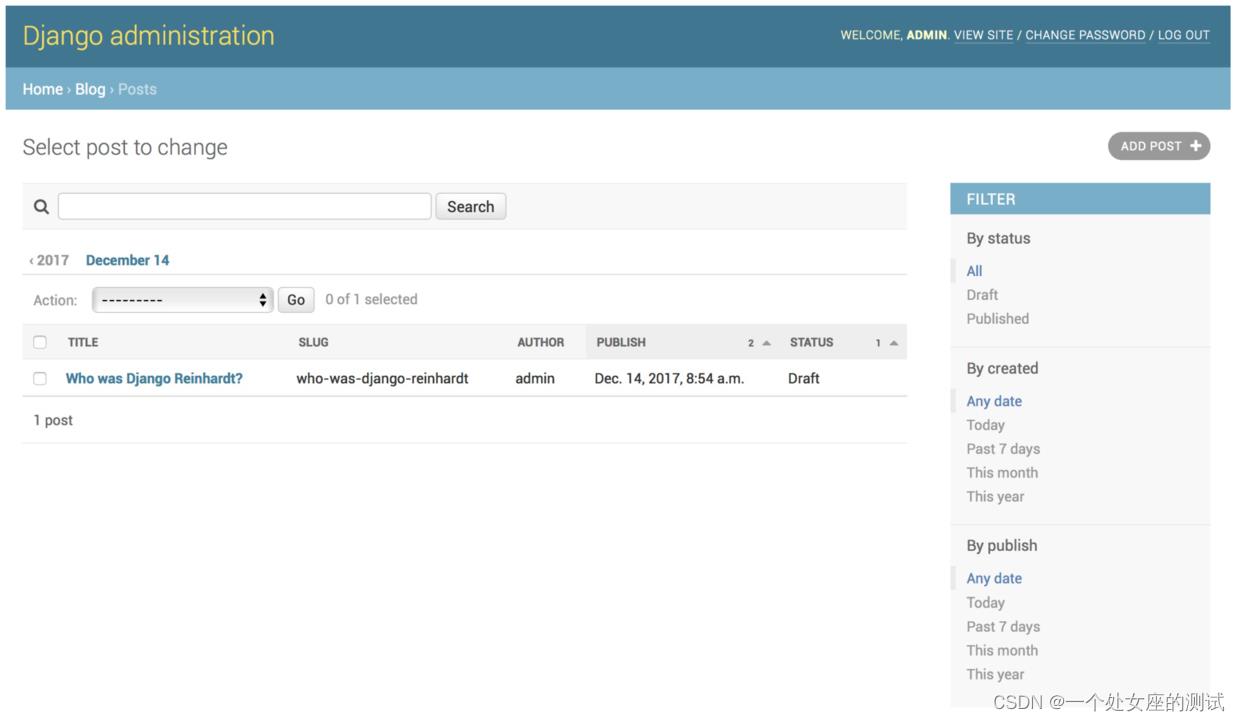
可以看到在该页面上显示的字段就是list_display中的字段。页面出现了一个右侧边栏用于筛选结果,这个功能由list_filter属性控制。页面上方出现了一个搜索栏,这是因为在search_fields中定义了可搜索的字段。在搜索栏的下方,出现了时间层级导航条,这是在date_hierarchy中定义的。还可以看到文章默认通过Status和Publish字段进行排序,这是由ordering属性设置的。
这个时候点击Add Post,可以发现也有变化。当输入文章标题时,slug字段会根据标题自动填充,这是因为设置了prepopulated_fields属性中slug字段与title字段的对应关系。现在author字段旁边出现了一个搜索图标,并且可以按照ID来查找和显示作者,如果在用户数量很大的时候,这就方便太多了。
通过短短几行代码,就可以自定义模型在管理后台中的显示方法,还有很多自定义管理后台和扩展管理后台功能的方法,会在以后的各章中逐步遇到。
5使用QuerySet和模型管理器(managers)
现在我们有了一个功能齐备的管理后台用于管理博客的内容数据,现在可以来学习如何从数据库中查询数据并且对结果进行操作了。Django具有一套强大的API,可以供你轻松的实现增删改查的功能,这就是Django Object-relational-mapper即Django ORM,可以兼容MySQL,PostgreSQL,SQLite和Oracle,可以在settings.py的DATABASES中修改数据库设置。可以通过编辑数据库的路由设置让Django同时使用多个数据库。
一旦你创建好了数据模型,Django就提供了一套API供你操作数据模型,详情可以参考https://docs.djangoproject.com/en/2.0/ref/models/。
5.1创建数据对象
打开系统的终端窗口,运行如下命令:
Copypython manage.py shell然后录入如下命令:
Copyfrom django.contrib.auth.models import User
>>>from blog.models import Post
>>>user = User.objects.get(username='admin')
>>>post = Post(title='Another post', slug='another-post', body='Post body', author = user)
>>>post.save()让我们来分析一下这段代码做的事情:我们先通过用户名admin取得user对象,就是下边这条命令:
Copyuser = User.objects.get(username='admin')get()方法允许从数据库中取出单独一个数据对象。如果找不到对应数据,会抛出DoseNotExist异常,如果结果超过一个,会抛出MultipleObjectsReturn异常,这两个异常都是被查找的类的属性。
然后我们通过下边这条命令,使用了标题,简称和文章内容,以及指定author字段为刚取得的User对象,新建了一个Post对象:
Copypost = Post(title='Another post', slug='another-post', body='Post body', author = user)这个对象暂时保存在内存中,没有被持久化(写入)到数据库中。
最后,我们通过save()方法将Post对象写入到数据库中:
Copypost.save()这条命令实际会转化成一条INSERT SQL语句。现在我们已经知道了如何在内存中先创建一个数据对象然后将其写入到数据库中的方法,我们还可以使用create()方法一次性创建并写入数据库,像这样:
CopyPost.objects.create(title='One more post', slug='One more post', body='Post body', author=user)5.2修改数据对象
现在,修改刚才的post对象的标题:
Copy post.title = 'New title'>>> post.save()这次save()方法实际转化为一个UPDATESQL语句。
对数据对象做的修改直到调用save()方法才会被存入数据库。
5.3查询数据
Django ORM的全部使用都基于QuerySet(查询结果集对象,由于该术语使用频繁,因此在之后的文章中不再进行翻译)。一个查询结果集是一系列从数据库中取得的数据对象,经过一系列的过滤条件,最终组合到一起构成的一个对象。
之前已经了解了使用Post.objects.get()方法从数据库中取出一个单独的数据对象,每个模型都有至少一个管理器,默认的管理器叫做objects。通过使用一个模型管理器,可以得到一个QuerySet,想得到一个数据表里的所有数据对象,可以使用默认模型管理器的all()方法,像这样:
Copy all_posts = Post.objects.all()这样就取得了一个包含数据库中全部post的Queryset,值得注意的是,QuerySet还没有被执行(即执行SQL语句),因为QuerySet是惰性求值的,只有在确实要对其进行表达式求值的时候,QuerySet才会被执行。惰性求值特性使得QuerySet非常有用。如果我们不是把QuerySet的结果赋值给一个变量,而是直接写在Python命令行中,对应的SQL语句就会立刻被执行,因为会强制对其求值:
Copy Post.objects.all()译者注:原书一直没有非常明确的指出这几个概念,估计是因为本书不是面向Django初学者所致。这里译者总结一下:数据模型Model类=数据表,数据模型类的实例=数据表的一行数据(不一定是来自于数据库的,也可能是内存中创建的),查询结果集=包装一系列数据模型类实例的对象。
5.3.1使用filter()方法
可以使用模型管理器的filter()过滤所需的数据,例如,可以过滤出所有2017年发布的博客文章:
CopyPost.objects.filter(publish__year=2017)还可以同时使用多个字段过滤,比如选出所有admin作者于2017年发布的文章:
CopyPost.objects.filter(publish__year=2017, author__username='admin')这和链式调用QuerySet的结果一样:
CopyPost.objects.filter(publish__year=2017).filter(author__username='admin')QuerySet中使用的条件查询采用双下划线写法,比如例子中的publish__year,双下划线还一个用法是从关联的模型中取其字段,例如author__username。
5.3.2使用exclude()方法
使用模型管理器的exclude()从结果集中去除符合条件的数据。例如选出2017年发布的所有标题不以Why开头的文章:
CopyPost.objects.filter(publish__year=2017).exclude(title__startswith='Why')5.3.3使用order_by()方法
对于查询出的结果,可以使用order_by()方法按照不同的字段进行排序。例如选出所有文章,使其按照title字段排序:
CopyPost.objects.order_by('title')默认会采用升序排列,如果需要使用降序排列,在字符串格式的字段名前加一个减号:
CopyPost.objects.order_by('-title')译者注:如果不指定order_by的排序方式,但在Meta中指定了顺序,则默认会优先以Meta中的顺序列出。
5.4删除数据
如果想删除一个数据,可以对一个数据对象直接调用delete()方法:
Copypost = Post.objects.get(id=1)
post.delete()当外键中的on_delete参数被设置为CASCADE时,删除一个对象会同时删除所有对其有依赖关系的对象,比如删除作者的时候该作者的文章会一并删除。
译者注:filter(),exclude(),all()这三个方法都返回一个QuerySet对象,所以可以任意链式调用。
5.5QuerySet何时会被求值
可以对一个QuerySet串联任意多的过滤方法,但只有到该QuerySet实际被求值的时候,才会进行数据库查询。QuerySet仅在下列时候才被实际执行:
第一次迭代QuerySet
执行切片操作,例如Post.objects.all()[:3]
pickled或者缓存QuerySet的时候
调用QuerySet的repr()或者len()方法
显式对其调用list()方法将其转换成列表
将其用在逻辑判断表达式中。比如bool(),or,and和if
如果对结构化程序设计中的表达式求值有所了解的话,就可以知道只有表达式被实际求值的时候,QuerySet才会被执行。译者在这里推荐伯克利大学的CS 61A: Structure and Interpretation of Computer ProgramsPython教程。
5.6创建模型管理器
像之前提到的那样,类名后的.objects就是默认的模型管理器,所有的ORM方法都通过模型管理器操作。除了默认的管理器之外,我们还可以自定义这个管理器。我们要创建一个管理器,用于获取所有status字段是published的文章。
自行编写模型管理器有两种方法:一是给默认的管理器增加新的方法,二是修改默认的管理器。第一种方法就像是给你提供了一个新的方法例如:Post.objects.my_manager(),第二种方法则是直接使用新的管理器例如:Post.my_manager.all()。我们想实现的方式是:Post.published.all()这样的管理器。
在blog的models.py里增加自定义的管理器:
CopyclassPublishedManager(models.Manager):
defget_queryset(self):
returnsuper(PublishedManager, self).get_queryset().filter(status='published')
classPost(models.Model):
# ......
objects = models.Manager() # 默认的管理器
published = PublishedManager() # 自定义管理器模型管理器的get_queryset()方法返回后续方法要操作的QuerySet,我们重写了该方法,以让其返回所有过滤后的结果。现在我们已经自定义好了管理器并且将其添加到了Post模型中,现在可以使用这个管理器进行数据查询,来测试一下:
启动包含Django环境的Python命令行模式:
Copypython manage.py shell现在可以取得所有标题开头是Who,而且已经发布的文章(实际的查询结果根据具体数据而变):
CopyPost.published.filter(title__startswith="Who")6创建列表和详情视图函数
在了解了ORM的相关知识以后,就可以来创建视图了。视图是一个Python中的函数,接受一个HTTP请求作为参数,返回一个HTTP响应。所有返回HTTP响应的业务逻辑都在视图中完成。
首先,我们会创建应用中的视图,然后会为每个视图定义一个匹配的URL路径,最后,会创建HTML模板将视图生成的结果展示出来。每一个视图都会向模板传递参数并且渲染模板,然后返回一个包含最终渲染结果的HTTP响应。
6.1创建视图函数
来创建一个视图用于列出所有的文章。编辑blog应用的views.py文件:
Copyfrom django.shortcuts import render, get_object_or_404
from .models import Post
defpost_list(request):
posts = Post.published.all()
return render(request, 'blog/post/list.html', 'posts': posts)我们创建了第一个视图函数--文章列表视图。post_list目前只有一个参数request,这个参数对于所有的视图都是必需的。在这个视图中,取得了所有已经发布(使用了published管理器)的文章。
最后,使用由django.shortcuts提供的render()方法,使用一个HTML模板渲染结果。render()方法的参数分别是reqeust,HTML模板的位置,传给模板的变量名与值。render()方法返回一个带有渲染结果(HTML文本)的HttpResponse对象。render()方法还会将request对象携带的变量也传给模板,在模板中可以访问所有模板上下文管理器设置的变量。模板上下文管理器就是将变量设置到模板环境的可调用对象,会在第三章学习到。
再写一个显示单独一篇文章的视图,在views.py中添加下列函数:
Copydefpost_detail(request, year, month, day, post):
post = get_object_or_404(Post, slug=post, status="published", publish__year=year, publish__month=month,
publish__day=day)
return render(request, 'blog/post/detail.html', 'post': post)这就是我们的文章详情视图。这个视图需要year,month,day和post参数,用于获取一个指定的日期和简称的文章。还记得之前创建模型时设置slug字段的unique_for_date参数,这样通过日期和简称可以找到唯一的一篇文章(或者找不到)。使用get_object_or_404()方法来获取文章,这个方法返回匹配的一个数据对象,或者在找不到的情况下返回一个HTTP 404错误(not found)。最后使用render()方法通过一个模板渲染页面。
6.2为视图配置URL
URL pattern的作用是将URL映射到视图上。一个URL pattern由一个正则字符串,一个视图和可选的名称(该名称必须唯一,可以在整个项目环境中使用)组成。Django接到对于某个URL的请求时,按照顺序从上到下试图匹配URL,停在第一个匹配成功的URL处,将HttpRequest类的一个实例和其他参数传给对应的视图并调用视图处理本次请求。
在blog应用下目录下边新建一个urls.py文件,然后添加如下内容:
Copyfrom django.urls import path
from . import views
app_name = 'blog'
urlpatterns = [
# post views
path('', views.post_list, name='post_list'),
path('<int:year>/<int:month>/<int:day>/<slug:post>/', views.post_detail, name='post_detail'),
]上边的代码中,通过app_name定义了一个命名空间,方便以应用为中心组织URL并且通过名称对应到URL上。然后使用path()设置了两条具体的URL pattern。第一条没有任何的参数,对应post_list视图。第二条需要如下四个参数并且对应到post_detail视图:
year:需要匹配一个整数
month:需要匹配一个整数
day:需要匹配一个整数
post:需要匹配一个slug形式的字符串
我们使用了一对尖括号从URL中获取这些参数。任何URL中匹配上这些内容的文本都会被捕捉为这个参数的对应的类型值。例如<int:year>会匹配到一个整数形式的字符串然后会给模板传递名称为int的变量,其值为捕捉到的字符串转换为整数后的值。而<slug:post>则会被转换成一个名称为post,值为slug类型(仅有ASCII字符或数字,减号,下划线组成的字符串)的变量传给视图。
对于URL匹配的类型,可以参考https://docs.djangoproject.com/en/2.0/topics/http/urls/#path-converters
如果使用path()无法满足需求,则可以使用re_path(),通过Python正则表达式匹配复杂的URL。参考https://docs.djangoproject.com/en/2.0/ref/urls/#django.urls.re_path了解re_path()的使用方法,参考https://docs.python.org/3/howto/regex.html了解Python中如何使用正则表达式。
为每个视图创建单独的urls.py文件是保持应用可被其他项目重用的最好方式。
现在我们必须把blog应用的URL包含在整个项目的URL中,到mysite目录下编辑urls.py:
Copyfrom django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('blog/', include('blog.urls', namespace='blog')),
]这行新的URL使用include方法导入了blog应用的所有URL,使其位于blog/URL路径下,还指定了命名空间blog。URL命名空间必须在整个项目中唯一。之后我们方便的通过使用命名空间来快速指向具体的URL,例如blog:post_list和blog:post_detail。关于URL命名空间可以参考https://docs.djangoproject.com/en/2.0/topics/http/urls/#url-namespaces。
6.3规范模型的URL
可以使用在上一节创建的post_detail URL来为Post模型的每一个数据对象创建规范化的URL。通常的做法是给模型添加一个get_absolute_url()方法,该方法返回对象的URL。我们将使用reverse()方法通过名称和其他参数来构建URL。编辑models.py文件
Copyfrom django.urls import reverse
classPost(models.Model):
# ......defget_absolute_url(self):
return reverse('blog:post_detail', args=[self.publish.year, self.publish.month, self.publish.day, self.slug])之后在模板中,就可以使用get_absolute_url()创建超链接到具体数据对象。
译者注:原书这里写得很简略,实际上反向解析URL是创建结构化站点非常重要的内容,可以参考Django 1.11版本的Django进阶-路由系统了解原理,Django 2.0此部分变化较大,需研读官方文档。
ExtJS 3.4:如何显示 TreeNode 的加号/减号图标
unicode 减号的转换(来自 matplotlib ticklabels)