python自动化之selenium以及接口自动化
Posted 素七七吖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python自动化之selenium以及接口自动化相关的知识,希望对你有一定的参考价值。
文章目录
vscode下载selenium,seleniu环境配置https://blog.csdn.net/weixin_34402408/article/details/88724699
八大元素定位
基于标签的属性来定位标签


frameset(框架集):忽略;frame(框架)和iframe(子框架)是需要处理的
八大元素定位是指,id、name、link text、partial link text、classname、tagname、cossselector、xpath
id、name
id,基于元素属性里面的id的值来定位,类似于每个人的身份证号,是不重复的
name,基于元素属性里面的name的值来定位,类似每个人的姓名,是可以有重名的

link text、partial link text
link text,主要用于超链接进行定位

partial link text是link text的模糊查询版本,类似于数据库中like %,模糊查询匹配到多个符合条件的元素,选取第一个
想找的第二个或者别的元素driver.find_elements_by_partial_link_text("百度")[1](get到百度网址)

classname、tagname
classname,基于元素样式来进行定位,容易遇到重复的
tagname,标签名进行定位,重复率最高,只有在需要定位后进行二次筛选的时候进行使用

cossselector、xpath
cossselector定位,应用相对较多,基于class属性来实现的定位,定位的内容可以直接copy选择selector(#id em[class=''])
xpath,是目前应用最多的,基于页面结构来进行定位

xpath相对路径,基于匹配制度来查找,依照xpath语法结构
例如://*[@id='kw'](//表示从根路径下开始查找;*表示任意元素;[]表示筛选条件/查找函数;@表示基于属性来筛选,例如@id='kw'表示基于属性id的值为kw的条件来查找)

在浏览器console里面也可以写xpath语句来定位,确认xpath路径是否正确,在F12界面Ctrl+f填入写的语句查找或者在console界面写入语句

根据文本定位 例如://a[text()="登录"]
当无法直接定位某个元素时,可以通过定位子元素返回父级来获取元素(末尾加上/..来返回上一级)

除了xpath写法外还有函数写法,//input[contains(@id,'kw')],contains表示匹配模糊查找,id的值包含kw
文本定位,//input[contains(text(),'XXXXX')]
//*[start-with(@id,'XXX')]属性值以XXX开头
//*[substring(@id,2)='XXX'],截取值,从第二个字符开始截取后的值为XXX

其他特殊定位处理
有框架的定位处理
有框架要先进入框架
driver.switch_to.frame("frame名/id"),然后再进行对框架内的元素的定位
对于没有id和name的框架用xpath定位,传入WebElement对象
iframe=driver.find_element_by_xpath('//*[@id="bjui-navtab"]/div[3]/div/iframe')
driver.switch_to.frame(iframe)

也可以用WebElement对象来定位
driver.switch_to.frame(driver.find_element_by_tag_name("iframe"))
出框架:driver.switch_to.default_content()
下拉框的定位
先定位,定位之后转化为下拉框的select对象(要导入包from selenium.webdriver.support.select import select)
通过value值进行定位下拉框里的元素选择

还可以通过select_by_visible_text(绝对文本内容)来定位选择下拉框里面的元素,例如:sel.select_by_visible_text("50")
绝对文本内容就是所有的文本信息,连空格( )也是文本内容,但是有类似空格这种特殊符号,可能该方法就无法定位选中
也可以通过select_by_index(下标)来进行定位选择下拉框内的内容,下拉框元素的每个option都有对应的下标志,第一个是0往下递增

弹窗处理
alert弹窗
弹窗有alert(只有确定),confirm(有确定有取消),prompt(有确定取消还可以输入值)
ale=driver.switch_to.alert
ale.accept()[点击确定,dismiss()是点击取消,send_keys()是输入值,text()是获得弹窗的文本]

其他弹窗
有的弹窗不是alert等的类型,但是也会只显示一会就消失
由于不是alert弹窗,无法使用switch_to方法。只能使用元素定位去获取text(),为了避免我们正在获取时,元素就提前消失了,导致报错。
可以先采用ActionChains模块的方法move_to_element()方法鼠标悬浮在弹窗上,这样弹窗就不会消失,然后去定位弹窗文本
from selenium.webdriver.common.action_chains import ActionChains
loc = driver.xxxx # 首先我们获取该元素定位
action_chains = ActionChains(drver)
action_chains.move_to_element(loc).perform() # 鼠标悬浮在该弹窗,防止弹窗消失
message = drver.text(loc) # text()获取弹窗元素文本
print(message)
div文本获取
当我们使用selenium获取div标签下的文本时, 应该使用get_attribute('innerText')
div = browser.find_element_by_xpath('你的div path')
text = div.get_attribute('innerText')
text即为div下的文本
鼠标和键盘操作

文件上传操作
定位到选择文件夹后不使用click方法而是直接send_keys("文件地址"),这样就可以上传文件了

页面切换
有时候,例如像进行QQ登录的时候会打开新的页面,需要在新的页面进行操作,这是需要进行页面切换
handles = driver.window_handles #获取当前浏览器的所有窗口句柄
driver.switch_to.window(handles[-1]) #切换到最新打开的窗口
driver.switch_to.window(handles[-2]) #切换到倒数第二个打开的窗口
driver.switch_to.window(handles[0]) #切换到最开始打开的窗口
#点击QQ登录
driver.find_element_by_partial_link_text("QQ登录").click()
# 获取当前所有标签页句柄
wins = driver.window_handles # 返回的是一个列表,按照标签页打开的顺序
# 切换到第二个标签页
driver.switch_to.window(wins[1])
time.sleep(2)
#进入框架
driver.switch_to_frame(0)
#点击头像登录
driver.find_element_by_id("img_out_2356823260").click()
# driver.switch_to.window(wins[0])
基于网易云的登录自动化实战
网易云手机号登录自动化
最好使用from selenium.webdriver.common.by import By的语法(便于封装)
例如:driver.find_element(By.XPATH,"//a[text()='登录']").click()
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
#创建浏览器对象
driver = webdriver.Chrome()
#隐式等待5秒
driver.implicitly_wait(5)
#网易云登录自动化
driver.get("https://music.163.com/")
#最大化当前页面
driver.maximize_window()
#定位元素
#定位登录
driver.find_element(By.XPATH,"//a[text()='登录']").click()
#定位选择其他登录模式
driver.find_element(By.XPATH,"//a[text()='选择其他登录模式']").click()
#定位同意协议勾选框
driver.find_element(By.XPATH,"//input[@id='j-official-terms']").click()
#定位选择手机号登录按钮
driver.find_element(By.XPATH,'//a[@class="u-btn2 u-btn2-2"]').click()
#定位输入账号
driver.find_element(By.XPATH,"//input[@id='p']").send_keys("账号")
#定位输入密码
driver.find_element(By.XPATH,"//input[@id='pw']").send_keys("密码")
#定位登录按钮
driver.find_element(By.XPATH,"//a[@class='j-primary u-btn2 u-btn2-2']").click()
#停留,保持在页面
os.system('pause')
#退出网页
driver.close()

51job自动搜索python并且把结果输出或者写入表格
先定位输入框输入内容
再定位选择城市,先将已经选择的(class-on)取消选择,再选择自己想要的城市
定位搜索按钮点击
定位结果

结果写入excel

unittest框架自动化
vscode中运行unittest框架:
创建python单元测试文件,包含test;文件名必须要包含test,否则将无法识别为unittest框架文件

按Ctrl+Shift+p,打开vscode命令选板,输入命令“Python:Configure Tests”,然后回车,进入配置

选择unittest框架和方法命名方式

打开控制台,可以看到控制台中已经包含了unittest方法

使用unittest方法
写一个类继承unittest.Testcase
导入unittest包
定义一个以test开头的方法,方法里面写自动化代码(选择的命名方式是以test开头就必须以test开头,其他方法的命名与其对应规则对应)

命令行的运行方式:python -m unittest python文件名(会运行所有子测试方法,例如:python -m test_autom.py)
只运行其中一个:python -m unittest python文件名.TestCase.类名(例如:python -m test_autom.TestCase.test_login)
设计模式(封装)
pom+关键字封装
pom模式:page object model 页面对象模式
能够解决线性脚本的问题、代码不能重复利用的问题、后期维护的问题
分为三层:
1.基础层(base):放selenium的原生方法;
2.页面对象层(po):主要用于放页面的元素和页面的动作;
3.测试用例层(testcase):存放测试用例以及测试数据
测试用例层调用页面对象层的方法,页面对象层调用基础层的方法
新建一个base层的类将原生方法进行封装

创建页面对象的类直接继承刚刚的基础类,写入页面元素与页面动作

测试用例层调用页面层的方法来实现代码

前后置处理
setUp和tearDown
setUp在测试用例之前的准备工作
tearDown在测试用例之后的扫尾工作(U和D一定要大写,孩子被坑哭了,pytest是小写)
新创建一个baseutil类在里面继承unittest.TestCase方法,写入setUp和tearDown,
在测试用例层的login里面就不用继承unittest.TestCase,直接继承baseutil类里面的方法
需要注意的是__init__()方法的改变,以及调用方法时要传递driver参数,page类没有改变


setUpClass和setDownClass
setUpClass和setDownClass是在每个类之前要执行的工作,在当前类的每个用例之前和之后只执行一次
常用于setUpClass创建日志对象,创建数据库连接,创建接口的请求,setDownClass用于销毁(pytest是setup_class/teardown_calss)

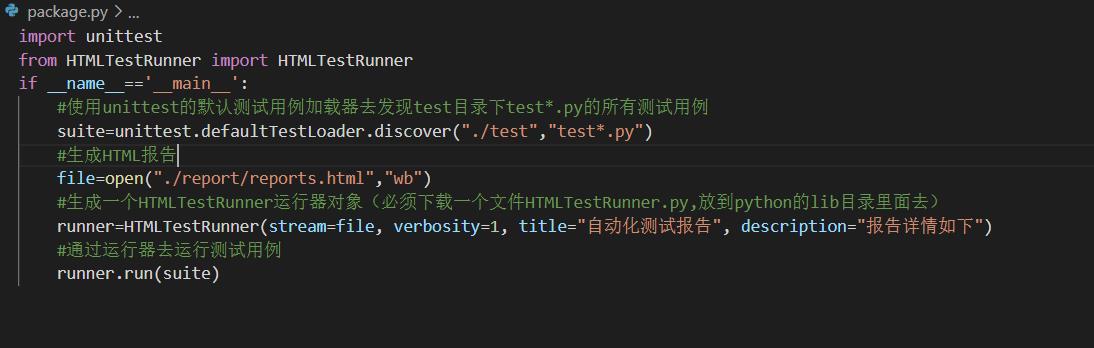
生成报告
执行需要的用例并且生成html格式的测试用例报告
在网上下载HTMLTestRunner.py的文件放到python的lib目录下
断言
self.assertEqual(first, second)用于判断两个值是否相等
self.assertTrue(expr)用于判断一个值是否为True
self.assertIn(member, container)用于判断一个值是否在另一个值里面

当断言定位的是一个动态的会出现一会就消失的弹窗时,使用了数据驱动,有的数据输入后提交会弹出弹窗,有的则不会,这时就需要利用try expect语句
...
global addsuccessValue
element_existance = True
try:
# 尝试寻找元素,如若没有找到则会抛出异常
element = self.locator_element(CumPage.allsuccess)
except:
element_existance = False
if element_existance:
addsuccessValue =self.get_attribute(CumPage.allsuccess,'innerText')
#断言
def get_except_result1(self):
return addsuccessValue
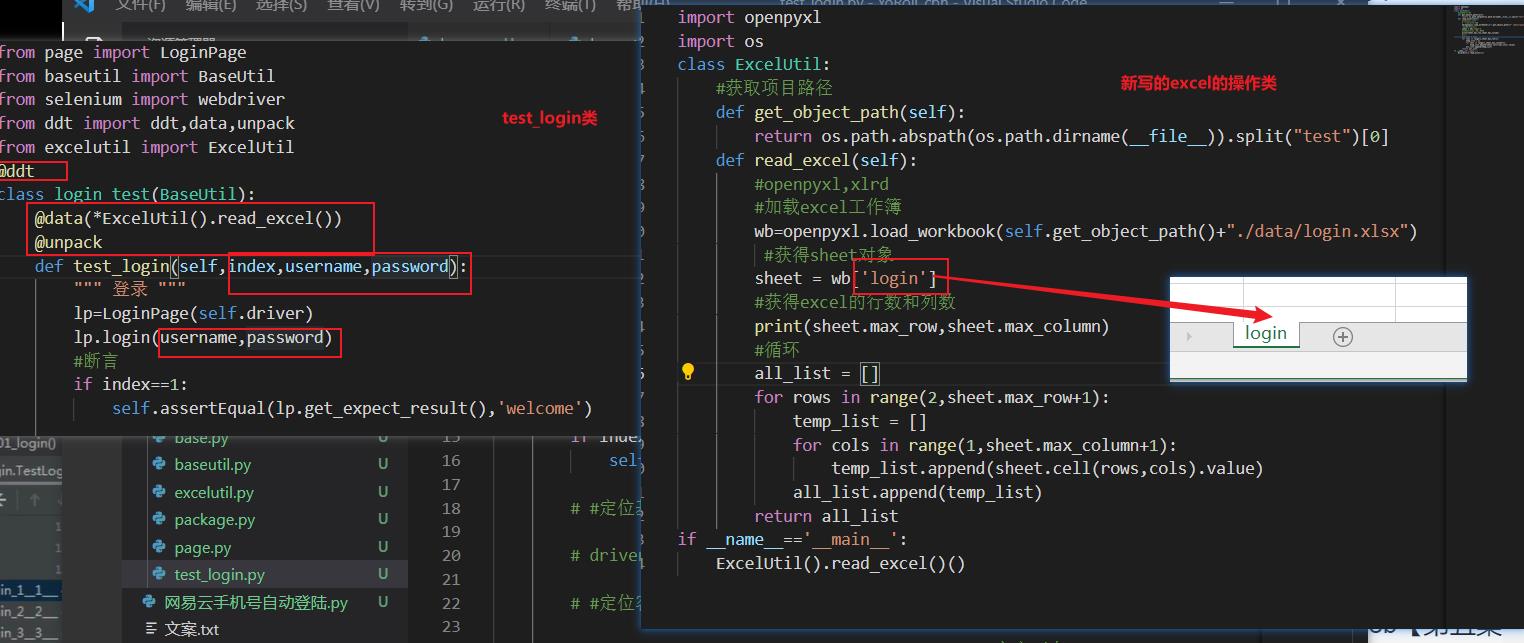
DDT+Excel数据驱动
Excel适用于web自动化,yaml适用于接口自动化
data driver test数据驱动测试,可以完美和unittest结合实现数据驱动
DDT通过装饰器来使用,在函数或者类上面加上一个装饰器来实现特定的功能
@ddt 装饰类,用于声明当前类使用ddt驱动;@data 装饰函数,用于函数传值;@unpack 装饰函数,用于数据解包;@file_data 装饰函数,用于读取yaml、json文件
先写好Excel文件,写入数据后将Excel文件拖入自己所创建的自动化项目的文件夹下

使用@data传值的时候传递多个值就会执行多次,修改Excel的sheet值为login
写一个excelutil的工具类来实现将Excel里面的数据改为['XX','XX','XX']格式,在用例类里面使用@ddt,@data,@unpack
使用openpyxl,没有该包就先下载,pip3 install openpyxl
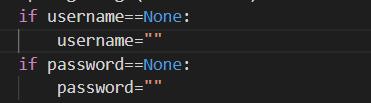
传递空值的时候回报错,因为NoneType的特殊性,加上if语句将None改为""
pytest
可以结合allure生成定制版的测试报告,支持很多强大的第三方插件(allure-pytest,pytest-xdist,pytest-ordering ……)

想要同时下载多个插件的话,就可以新建一个txt文档,将要下载的插件写入文档,一个插件名称占一行
然后在控制台输入 pip install -r 文件名(pip不可以的话用pip3),就可以同时下载文档里面写入的插件

默认规则
模块名必须以test_开头或者_test结尾
测试类必须以Test开头,并且不能有init方法
测试方法必须以test开头
执行(运行)
主函数和命令行
pytest的默认执行方式是根据自己写的方法从上到下依次执行,如果想要规定谁先执行或者指定执行顺序的话,可以使用标记
在想要规定顺序的方法前面加上@pytest.mark.run(order=num)[num是自己指定的,如果想要第一个执行,num就是1]


–html ./report/report.html:生成html报告
pytest.ini文件执行
实际中最主要的执行方法是写一个pytest.ini文件(写完后借助工具改为ANSI编码),放在项目跟目录,然后直接控制台输入pytest 即可
在这个文件里面写入测试文件夹,测试的参数,配置测试搜索模块文件名称以及测试类名和测试函数名(转编码格式时把中文去掉)
形成测试报告了可以在参数里面再写入 --html ./report/report.html;在report目录下生成report.html的报告

分组执行
在进行冒烟执行和分模块执行以及分接口和web执行时,在方法前面我们都会加上对应模块的标记,比如@pytest.mark.smoke;@pytest.mark.usermanage
在pytest.ini文件里面加入markers的值如下图
执行方式就是pytest -vs -m "smoke";同时执行两个就是pytest -vs -m "smoke or usermanage"

跳过测试用例
有的测试用例想要在执行的时候跳过,就在该用例的方法前面加上@pytest.mark.skip(reason="XXXX")[原因可写可不写]
需要写有条件跳过的话就是@pytest.mark.skipif(判断条件,reason="XXXX")[例如:@pytest.mark.skipif(age>18,'已成年')]
fixture装饰器
fixture装饰器是pytest的一个用于实现部分以及全部用例的前后置的工具
@pytest.fixture(scope="",params="",autouse="",ids="",name="")
(1)scope表示的是被@pytest.fixture标记的方法的作用域。function(默认) , class,moduile ,package/session.
(2)params 参数化,支持列表[],元组(),字典列表[,,],字典元组(,,)
(3)autouse=True :自动使用,默认False,自动使用的话就是所有的函数和类都会使用
(4)ids :当使用params泰数化时,给每一个值设置一个变量名。意义不大。
(5)name:给表示的是被@pytest. fioxture标记的方法取一个别名。使用别名后就不能再使用它本身函数的名字来调用了
scope的级别是class就是类级别的前后置,model表示在每个模块只会执行一次(一个模块可以有多个类,一个类可以有多个函数)
前置后置就是写玩前置的内容后用yield分隔写后置内容

在装饰器里面是params="",是参数名要s,在下面使用的param是属性名

import pytest
pytest.fixture (scope='function ' , params=[ '成龙','甄子丹','菜10'])
def my_fixture (request):
print(前置')
yield request.param
#return和yield都表示返回的意思,但是return的后面不能有代码,yield返回后后面可以接代码。
print(后置)
class TestMashang1:
def test_o1_ baili (self):
print ( '\\n测试百里')
def test_02_xingyao (self,my_fixture):
print( '\\n测试星瑶')
print ( ' -----―-----―--'+str(my_fixture))
conftest.py和fixture装饰器结合实现全局的前置应用
我们可以通过conftest.py和fixture结合来实现全局的前置应用,比如项目的全局登录,模块的全局处理
conftest.py是单独存在的配置文件,名称不能更改
使用conftest.py就可以跨文件使用前置
原则上conftest.py需要和运行的用例放到同一个层,并不需要import操作(不同层也可以做到)
修改为pytest形式
在pytest中setup和teardown是小写的u和d,只需要在用例类的函数前加上 @pytest.mark.parametrize()
括号里面写上数据("index,username,password",ExcelUtil().read_excel())数据解析直接"index,username,password",有几个参数就写几个
pytest的断言是直接assert(assert lp.get_except_result()=='welcome')


生成报告
先安装pip3 install allure-pytest

去官网下载allure2并配置环境https://www.jianshu.com/p/078c2e856a83
配置好了重新打开vscode就可以正常运行了
生成allure报告第一步生成json格式的临时文件也可以就在 pytest.ini文件文件中的参数里面写入 --alluredir ./temp来完成

pytest+yaml接口自动化
先pip3 install requests下载requests以及pyYaml

yaml文件格式:
1.MAP(键值对):键:(空格)值
2.列表list(数组):用一组横线开头
yaml文件的拓展名可以是yaml或者yml

Map写法

数组写法

yaml写用例一般以"—"开头,因为用例可能有多种,有正确的用例和错误的用例,以"—"开头代表是列表

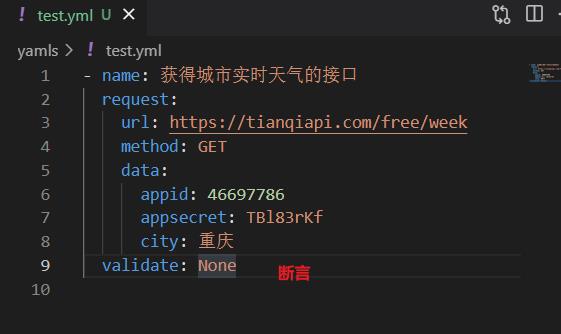
简单天气接口实例
先在yaml文件里面写好接口的信息
ow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ3OTMyMzk3,size_16,color_FFFFFF,t_70)
- name: 获得城市实时天气的接口
request:
url: https://tianqiapi.com/free/week
method: GET
data:
appid: 46697786
appsecret: TBl83rKf
city: 重庆
写一个pytest的python文件(命名一定要test_开头或者_test结尾)

添加pytest的数据驱动装饰器,使用刚刚写的yaml文件导入数据,写一个python函数读取yaml文件里面的值,利用函数导入数据到装饰器
yaml读取后的数据是字典列表
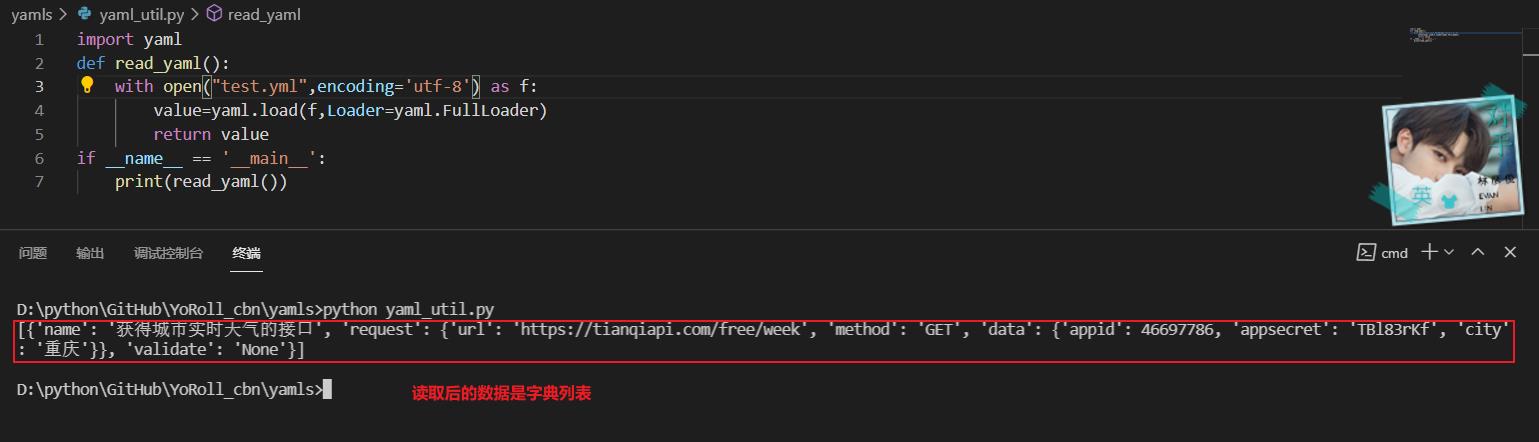
import yaml
def read_yaml(yamlPath):
with open(yamlPath,encoding='utf-8') as f:
value=yaml.load(f,Loader=yaml.FullLoader)
return value
if __name__ == '__main__':
print(read_yaml())
导入模块后在装饰器里使用读取yaml文件的方法,导入数据

数据导入后就实现requests来发送请求,requests的请求传递参数有两种方式,data和json
data:只能传输字符串或者是非嵌套的字典。(非嵌套:'city":'深圳;嵌套: city :city":'深圳另)
json:只能传输字典

import pytest
from yaml_util import read_yaml
import requests
class Test_api:
@pytest.mark.parametrize("data",read_yaml('test.yml'))
def test_weather(self,data):
# print(data)
# print(data['name'])
# print(data['request']['url'])
# print(data['request']['method'])
# print(data['request']['data'])
# print(data['validate'])
res=requests.get(data['request']['url'],data['request']['data'])
#print(res.text) #文本字符串
print(res.json()) #json格式
if __name__=='__main__':
pytest.main(['-vs'])
以上是关于python自动化之selenium以及接口自动化的主要内容,如果未能解决你的问题,请参考以下文章