09 APACHE KAFKA原理
Posted IT BOY
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了09 APACHE KAFKA原理相关的知识,希望对你有一定的参考价值。
APACHE KAFKA原理
目录
(3) 00000000000000000000.index
(4) 00000000000000000000.timeindex
PT1 KAFKA事务
Pt1.1 消息幂等性
在RabbitMQ部分,已经介绍过在消费端要基于业务的唯一性实现消息幂等性,保证在MQ异常或者网络抖动等因素下,重发消息不会产生重复消费的情况。
在Kafka中,同样建议如此。除此之外,Kafka基于一些机制在服务端自己实现了消息的幂等性,来帮助减轻消费端的压力。
幂等性Producer
在Producer端,设置enable.idempotence=true来打开生产者幂等性,将Producer升级为幂等性Producer。
实现Producer的幂等性,Kafka引入了Producer ID(即PID)和Sequence Number。
-
PID(Producer ID):每个新的Producer在初始化的时候会被分配一个唯一的PID,这个PID对用户是不可见的。
-
sequence number:对于每个PID,该Producer发送数据的每个消息都对应一个从0开始单调递增的Sequence Number。幂等性生产者发送的每条消息都带有相应的sequence number,服务端就是根据这个值来判断是否是重复消息,如果服务端发现当前sequence number已经比服务端记录的值要小,那就判定当前消息重复。
全局有序性
不过,PID和sequence number是和Producer客户端有关,并不是全局有序的,他只能保证同一个Producer客户端往同一个Topic分区发送消息时的幂等性。
-
保证单分区上的幂等性,即一个幂等性Producer客户端只保证同一个Topic分区上不出现重复消息。
-
只能实现单会话上的幂等性,单会话是指Producer进程的一次运行,如果Producer进程重启,幂等性就无法保证。
如果要实现全局幂等性,就要用到事务。
Pt1.2 生产者事务
生产者事务是Kafka在 2017年0.11.0.0引入的新特性,通过事务Kafka可以保证跨生产者会话的消息幂等发送。
生产者事务主要适用以下场景:
-
假设只有1个Broker,Topic只有1个分区,1个副本,我们希望业务上相关联的多条消息能够全部失败或者全部成功。
-
如果生产者发送消息到多个Topic或者多个分区,消息可能分布在不同的Broker上,客户端希望消息能够全部发送成功或者全部发送失败。
-
生产者和消费者在同一代码段,从上游接收并处理消息,然后发送给消息,客户端希望能够保证消息收发同时成功。
和生产者事务相关的API有5个:
-
initTransactions():初始化事务。
-
beginTransaction():开启事务。
-
commitTransaction():提交事务。
-
abortTransaction():中止事务。
-
sendOffsetsToTransaction():当消费者和生产者在同一段代码中(从上游接收消息发送给消费者),在提交的时候把消费的消息Offset发送给Consumer Corordinator。
关于生产者事务,有几个要点:
-
Kafka事务可能会跨分区,属于分布式事务。Kafka是基于2PC的分布式事务,有Transaction Coordinator负责协调事务,如果都可以提交事务,那么就Commit,否则Abort。
-
Kafka的事务日志记录在
__transaction_state这个特殊的topic中,和消费者的offset一样。事务日志用于记录事务状态,以便在Coordinator挂掉之后可以继续处理原来的事务。 -
事务有唯一的id,即
transaction.id,是使用UUID生成,用于标记唯一的事务。如果生产者挂了,重启后通过事务ID找到未处理完的事务接着处理。
在Spring Kafka部分,有使用Spring实现Kafka生产者事务的案例,可以参考。
PT2 生产者原理
Kafka生产者客户端发送消息主要有两个线程来协调完成,分别是Main线程和Send线程。Main线程负责处理要发送的消息,Send线程负责将消息发送到Kafka服务端的Broker。
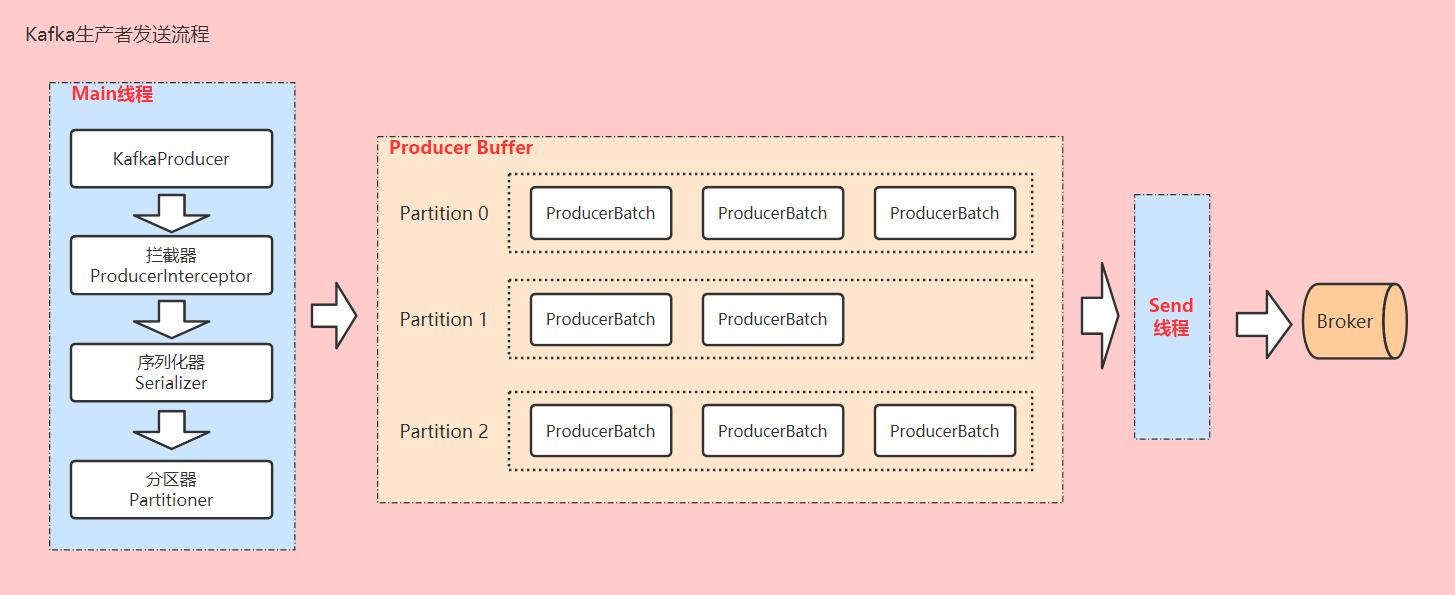
生产者消息并不是立马发送到Broker(由参数linger.ms控制),而是先放在Producer端的Buffer中,当累计发到条数达到Batch数(由参数batch.size控制)或者Buffer满了(由buffer.memory控制),再通过Send线程将整个批次消息发送到Broker。
Pt2.1 创建KafkaProducer
在创建KafkaProducer对象时,实际上是启动了主线程,并创建了一个Send线程。
在代码中通过javaapi创建KafkaProducer,主线程负责处理消息:
Producer<String, String> producer = new KafkaProducer<String, String>(pros);在源码构造器中,创建Sender对象,并启动IO线程负责发送数据:
this.sender = this.newSender(logContext, kafkaClient, this.metadata);
String ioThreadName = "kafka-producer-network-thread | " + this.clientId;
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();Pt2.3 拦截器ProducerInterceptor
拦截器的作用是实现消息的定制化,对要发送的消息做一些特殊的处理,比如业务逻辑的统计、转换等。
在producer.send()方法发送消息前,会先处理interceptor.onSend()处理:
// 源码如下
// org.apache.kafka.clients.producer.KafkaProducer#send(org.apache.kafka.clients.producer.ProducerRecord<K,V>, org.apache.kafka.clients.producer.Callback)
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback)
// 先触发interceptor处理
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
// 然后发送消息
return this.doSend(interceptedRecord, callback);
在代码中增加拦截器:
// Kafka生产者
public class ProducerAPI
public static void main(String[] args)
Properties pros = new Properties();
/** 1、参数配置 */
// 配置服务端ip:port
pros.put("bootstrap.servers", "121.4.33.15:9092");
// key-value的序列化协议:Kafka在发送数据时都是需要序列化的。
pros.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
pros.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// Producer确认模式:0 发出去就确认,1 落盘就确认,all 所有follower同步完才确认
pros.put("acks", "1");
// 消息发送异常时(未被确认),发送方重试次数
pros.put("retries", "3");
// 多少条数据发送一次,默认16K。达到数量会触发消息发送
pros.put("batch.size", "16385");
// 批量发送的等待时间,时间到了会触发消息发送
pros.put("linger.ms", "5");
// 客户端缓冲区大小,默认32M,缓冲区满了也会触发消息发送
pros.put("buffer.memory", 33554432);
// 获取元数据时生产者的阻塞时间,超时后抛出异常
pros.put("max.block.ms", 3000);
// 添加拦截器(这里是重点)
List<String> interceptors = new ArrayList<>();
interceptors.add("com.example.mq.mqdemo.kafka.producer.MessageInterceptor");
pros.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors);
/** 2、启动生产者客户端 */
Producer<String, String> producer = new KafkaProducer<String, String>(pros);
/** 3、构建并发送消息对象:只有Value场景 */
ProducerRecord valueRecord = new ProducerRecord("first_topic", "这是一条只包含Value的消息。");
producer.send(valueRecord);
/** 4、构建并发送消息对象:Key-Value场景 */
ProducerRecord keyValueRecord = new ProducerRecord("first_topic", "firstMsg", "这是一条Key-Value的消息。");
producer.send(keyValueRecord);
/** 5、关闭生产者客户端 */
producer.close();
配置拦截器:
public class MessageInterceptor implements ProducerInterceptor<String, String>
// 发送消息时触发
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> producerRecord)
// 执行对消息的定制化处理,比如入库,统计
System.out.println("即将要发送的消息:" + producerRecord.key() + "=" + producerRecord.value());
return producerRecord;
// 收到服务端ACK时触发
@Override
public void onAcknowledgement(RecordMetadata recordMetadata, Exception e)
System.out.println("发送消息已被Broker确认");
// 关闭生产者时触发
@Override
public void close()
System.out.println("Producer即将关闭");
// 使用键值对配置时触发
@Override
public void configure(Map<String, ?> map)
System.out.println("配置");
启动生产者,拦截器被执行:
配置
即将要发送的消息:null=这是一条只包含Value的消息。
发送消息已被Broker确认
即将要发送的消息:firstMsg=这是一条Key-Value的消息。
发送消息已被Broker确认
Producer即将关闭Pt2.3 序列化器Serializer
Kafka在发送消息前,需要对消息的Key和Value进行序列化,在配置Producer时需要指定序列化协议。Kafka自带提供了多种序列化工具,同时也可以自定义实现序列化器,使用诸如Avro、JSON、Thrift或者Protobuf这种高性能序列化器,只需要实现org.apache.kafka.common.serialization.Serializer接口即可。
诸如下面的形式:
public class JsonSerializer implements Serializer
@Override
public byte[] serialize(String topic, Object data)
// TODO 基于JSON格式实现对象序列化
// TODO
return new byte[0];
Pt2.4 分区器Partitioner
分区器就是消息路由的配置,当前Producer发送的消息,应该分配到Topic的那个分区。
在消息发送时,Kafka会计算应该发送的分区信息:
// Kafka源码
// org.apache.kafka.clients.producer.KafkaProducer#doSend
int partition = this.partition(record, serializedKey, serializedValue, cluster);(1) 显示指定partition的场景
如果我们在创建消息KafkaRecord时,显示执行了要发送的partition,会优先使用此配置。
// Kafka ProducerRecord源码:带partition信息的构造器。
public ProducerRecord(String topic, Integer partition, K key, V value)
this(topic, partition, null, key, value, null);
KafkaProducer源码中计算partition的逻辑。
// Kafka源码
// org.apache.kafka.clients.producer.KafkaProducer#partition
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster)
Integer partition = record.partition();
return partition != null ? partition : partitioner.partition(record.topic(),
record.key(), serializedKey, record.value(), serializedValue, cluster);
例如,代码中指定partition为0:
/** 3、构建并发送消息对象:Key-Value场景 */
ProducerRecord valueRecord = new ProducerRecord("first_topic", 0, "firstMsg", "这是一条Key-Value的消息。");
producer.send(valueRecord);(2) 自定义分区器
实现org.apache.kafka.clients.producer.Partitioner可以自定义分区器,根据定制化的业务逻辑来决定消息的分区路由。
在Producer中加入自定义分区器:
// 自定义分区器
pros.put("partitioner.class","com.example.mq.mqdemo.kafka.producer.MyPartitioner");
自定义分区器逻辑:
//自定义分区器算法。
public class MyPartitioner implements Partitioner
// Partitioner计算分区逻辑
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster)
// TODO 自定义补充
return 0;
// Partitioner关闭时触发
@Override
public void close()
System.out.println("关闭自定义partitioner");
// 配置Partitioner时触发
@Override
public void configure(Map<String, ?> map)
System.out.println("配置自定义partitioner");
(3) Kafka默认分区器
如果没有显示指定partition,也没有自定义分区器,Kafka会使用默认分区器DefaultPartitioner逻辑计算partition。
逻辑如下:
// Kafka源码
// org.apache.kafka.clients.producer.internals.DefaultPartitioner#partition(java.lang.String, java.lang.Object, byte[], java.lang.Object, byte[], org.apache.kafka.common.Cluster, int)
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster,
int numPartitions)
if (keyBytes == null)
return stickyPartitionCache.partition(topic, cluster);
// 对Key进行hash,然后再对Topic的partition进行取余,获得对应的分区位置。
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
(4) Kafka轮训分区器
如果没有指定Key,无法使用DefaultPartitioner,Kafka提供了一种轮训算法RoundRobinPartitioner。
RoundRobinPartitioner会在第一次调用时生成一个整数,每次调用时都会递增1,并且是线程安全的。计算分区时使用整数对分区数量取余,从而实现一种轮训的状态。
// Kafka源码
// org.apache.kafka.clients.producer.RoundRobinPartitioner#partition
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster)
// 获取topic的分区数
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
// 获取递增整数
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (!availablePartitions.isEmpty())
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
else
// 全局整数对partition数量取余,获取存放位置。
return Utils.toPositive(nextValue) % numPartitions;
// 缓存一个全局递增的AtomicInteger
private int nextValue(String topic)
AtomicInteger counter = topicCounterMap.computeIfAbsent(topic, k ->
return new AtomicInteger(0);
);
return counter.getAndIncrement();
Pt2.5 消息累加器
消息处理完成后,并不是立马发送到Broker,而是会进入消息累加器RecordAccumulator。
// Kafka源码
// org.apache.kafka.clients.producer.KafkaProducer#doSend
// 将消息添加到累加器等待发送
result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs,
false, nowMs);RecordAccumulator本质上是一个Map,基于Topic-Partition统计batch,batch满了之后会唤醒Sender线程,将消息发送到Broker。
// Kafka源码
// org.apache.kafka.clients.producer.internals.RecordAccumulator
ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches;消息批次统计
// Kafka源码
// org.apache.kafka.clients.producer.KafkaProducer#doSend
// 消息批次满了唤醒Sender线程
if (result.batchIsFull || result.newBatchCreated)
log.trace("Waking up the sender since topic partition is either full or
getting a new batch", record.topic(), partition);
this.sender.wakeup();
以上就是整个生产者发送消息的过程,提供了很多的钩子开放给外部做自定义,你可以自定义消息处理逻辑,可以选择序列化方式,也可以自定义消息分区路由的逻辑。
Pt2.6 服务端响应机制
还有一个至关重要的问题,生产者消息发送到Broker之后,怎么知道Broker已经成功接收了呢。假如网络发生终端,或者Broker接收消息还未处理完发生宕机,实际上消息没有得到处理,那这条消息就丢了。所以需要有一种机制,能够在服务端Broker确认消息接收状态后,通知生产者,那样生产者就可以记录消息发送状态,并决定是继续发送下一条消息还是重发当前消息。
(1) Broker端ACK应答机制
我们知道,Kafka服务端在持久化数据的时候,Partition可以有多个副本,来保证消息的可靠性。那么当服务端接收到消息时,怎样才算成功接收,何时给Producer响应呢。有两种处理策略:
-
第一种是Leader和半数以上follower节点完成同步(指副本也完成消息持久化),发送ACK给Producer。这样Kafka集群能够保证一定的可靠性(极端情况下不能保证),同时能够保证响应Producer的时效性。
-
第二种是Leader和全部follower节点完成消息同步,才发送ACK给Producer。这样可以充分保证消息的可靠性(除非整个集群挂了,那就没办法了),但是全部节点都完成同步,耗时也会更久,相应的Producer吞吐量也就下来了。
Kafka服务端选择了第二种方案,在发生故障时可靠性更高,并且另一半副本确认带来的时延对Kafka影响一般并不大。
这是Kafka服务端所认定的确认方式,但是对于Producer客户端来说,有时候并不是特别在乎消息的可靠性。比如我只是同步日志数据,或者同步操作通知,允许在一些特殊情况下少量消息的丢失,反而我对发送消息的吞吐量非常在意,那这种稳妥的方案对我来说就不是很友好。
所以Kafka提供给客户端一种更加灵活的ACK应答方式的选择。
(2) Producer端ACK应答机制
Kafka为客户端提供了3种可靠性级别,Producer(用户端)可以根据对消息可靠性和时效性的要求进行权衡,选择合适的策略。通过acks参数可以设定Producer端对ACK应答机制的策略,支持三种策略:
-
acks=0:Producer发送消息后,不等待broker的ack。
这种策略提供了最好的吞吐量,但也是最差的可靠性,broker接收到消息后,还没有来得及处理,既然不等到broker确认,肯定也没有相应的重发机制,当broker发生重启或故障时,丢失消息的几率非常高(几率高是相对故障发生而言,本身broker故障率不会很高,否则就说明基础中间件本身存在很大问题)。这种比较适合对消息可靠性要求没有那么高的场景,比如日志数据同步,一些不重要的通知类消息推送等。
-
acks=1:默认配置。Producer发送消息后等待broker的ack确认,分区的Leader节点落盘成功后返回客户端ack确认。
这时候可能follower副本还没完成数据同步,如果此时Leader节点发生故障且无法恢复,将有几率丢失数据。这种适合一般场景,对消息可靠性有一定要求,但是没有绝对高(时效性强,又要万无一失)的要求,允许一定概率的消息丢失,但是可以得到相对高的吞吐量。当然这里说的消息丢失,只是说在一次收发消息时发生数据丢失,但是在场景实现上,在全链路数据上,可以通过一定的机制(比如稽核,比如对账等)发现问题,从而制定相应的补偿机制来弥补这种不足。
-
acks=all:Producer发送消息后,partition的Leader和Follower节点全部完成数据持久化后再相应ack给客户端。
这种机制kafka保证了最高的数据可靠性,牺牲了客户端吞吐量。当然,所谓的最高也只是Kafka层面的,如果整个集群发生宕机无法恢复,或者地震了整个机房都毁了,这种可靠性也是无法保证的。这种策略适合对消息可靠性有严格要求的场景,比如各种支付场景,比如金融证券这些场景等。
在后两种情况下,除了可用性之外,还会发生一种场景:broker已经完成持久化(部分或者全部),准备给客户端发送ack,这时候Leader节点故障,导致Producer没有收到确认ACK。此时如果配置重发策略,客户端会重发消息,这时候就需要消费者要基于业务场景实现一定的消息幂等性,防止重复消费的情况。
(3) ISR(in-sync replica set)
在需要等待Followers节点确认的策略中(比如ack=all),假如3个Follower中有一个挂了,其它两个已经完成持久化,但是第三个迟迟没有发送完成消息,难道要一直等下去吗。这岂不是比消息丢了还惨,整个客户端完全处于不可用状态,无限制等待ACK确认直到超时,重发后再次陷入等待状态。
Kafka为了解决这种情况,制定了一种策略。Leader节点有多个Follower节点,Follower节点会定期和Leader节点交互(心跳)以维持活跃状态,Leader节点将活跃的Follower保存在动态SET结构中,称之为ISR(in-sync replica set)。只要ISR里面的Follower完成同步后(这里讨论的是基于ack=all的策略,其它策略也雷同),就给Producer客户端返回ACK确认。
所以,虽然Leader有多个Follower,但是并不是需要等待所有Follower都完成数据同步后再发送ACK,那些已经失联的Follower的同步状态不做考虑,除非他们重新发起心跳加入到ISR中。
如果一个Follower长时间不同步数据,就会被从ISR中剔除,这个时间由参数replica.lag.time.max.ms决定(默认30秒)。如果Follower被踢出后恢复正常,又重新开始同步数据,会被重新加入ISR。
如果Leader挂了,只有ISR成员才有资格参加选举,成为新的Leader。
PT3 BROKER存储原理
Pt3.1 Partition存储
我们已经知道,Kafka对Topic进行分区,将消息分别存放到不同的Partition中,提高了Kafka存储能力,降低了单台服务器的访问压力,同时提升了吞吐量。在一个partition中,消息是顺序写入的,但是在全局环境下,比如整个Topic中,消息不一定是全局有序。

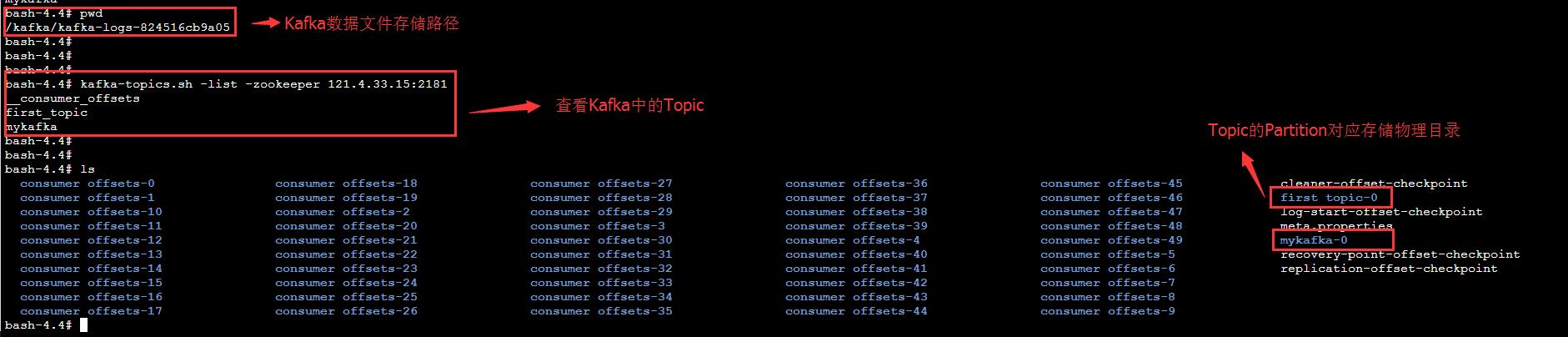
在服务器上,每个Partition有一个物理目录,
Pt3.2 副本机制
Kafka的副本机制提高了分区的可靠性,通过replication-factor可以在创建Topic时指定分区副本数量。要注意的是,分区的副本必须在不同的Broker节点上,因为副本是为了防止Broker单点故障时引发的数据丢失问题,两个副本如果在同一个Broker上,当Broker故障必然都不能幸免,因此同一个Broker节点上的两个相同副本并没有多大意义。Kafka干脆就做了严格限制,同一个Topic分区的两个副本不能分布在同一个Broker节点。所以分区副本数量不能大于集群Broker节点数,否则会报错。
副本包含Leader节点和Follower节点,Leader负责对外提供服务,包括读和写。Follower节点只负责从Leader同步数据,不负责对外服务,但是当Leader故障时会参加选举成为新的Leader。这样的设计简单,Follower不参与对外服务(对比数据库主从读写分离),不需要考虑主从同步的延时在读写分离场景带来的数据一致性问题。Follower节点要做的只是保存完整的Leader数据,哪怕存在一些时延或者故障恢复,只要最终和Leader数据一致。
Eg.我本地因内存的关系,只搭建了单节点的Kafka,所以无法创建多个副本。就以单节点举例,查看Topic的信息。
# 通过命令查看名称为mykafka的Topic信息。
# 注意,分区名称是从0开始,比如0,1,2。Broker名称是从1开始,比如1,2,3等
./kafka-topics.sh --topic mykafka --describe --zookeeper 121.4.33.15:2181
# topic名称 # 共有1个分区 # 共有1个副本
Topic: mykafka PartitionCount: 1 ReplicationFactor: 1 Configs:
# topic名称 # 分区名 # 分区Leader所在Broker # 副本所在Broker # 活跃ISR所在Broker
Topic: mykafka Partition: 0 Leader: 0 Replicas: 0 Isr: 0Pt3.3 Segment
Kafka使用log文件来保存持久化数据,为了防止log文件不断追加导致文件过大,降低消息的查询效率,Partition的log文件会划分成多个Segment(段)来存储。每个Segment由1个log文件和2个index文件组成(成套出现)。
bash-4.4# pwd
/kafka/kafka-logs-824516cb9a05/mykafka-0
bash-4.4# ls -l
total 16
-rw-r--r-- 1 root root 10485760 May 30 14:55 00000000000000000000.index
-rw-r--r-- 1 root root 458 May 27 06:38 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 May 30 14:55 00000000000000000000.timeindex
-rw-r--r-- 1 root root 10 May 30 14:55 00000000000000000006.snapshot
-rw-r--r-- 1 root root 8 May 30 14:55 leader-epoch-checkpoint(1) leader-epoch-checkpoint
leader-epoch-checkpoint保存每一任Leader开始写入消息时的offset。
bash-4.4# cat leader-epoch-checkpoint
0
1
0 0(2) 00000000000000000000.log
00000000000000000000.log文件保存的是实际的消息数据,数据是不断追加到文件中的,如果满足一定条件,文件会被切分产生新的Segment文件。
有3种策略来决定是否切分log文件:
-
log文件达到一定的大小限制,会切分新的Segment。log.segment.bytes参数指定了log文件的最大限制,默认是1G,数据追加达到相应大小后会切分新的Segment。
# 单个segment文件大小限制 log.segment.bytes=1G -
根据消息的最大时间戳和当前系统时间戳的差值。
log.roll.hours参数指定最大差值,默认是168小时,意味着log文件最多只会保存一周的数据,超过一周后不管当前log文件存储了多大的数据都会被强制切分出新的Segment。 -
当.index文件或者.timeindex文件达到一定大小限制时,切分出新的Segment。即索引文件写满了时也要切分新的Segment,保证三个文件的一致性,
log.index.size.max.bytes参数控制这个数值,默认是10M。
(3) 00000000000000000000.index
00000000000000000000.index记录的是offset偏移量的索引文件。
(4) 00000000000000000000.timeindex
00000000000000000000.timeindex记录的是时间戳(timestamp)的索引文件。
Pt3.4 索引文件
分区log文件虽然进行了Segment切分,但是每个Segment的文件依然存放了很多消息,想要快速进行查询并不容易,因此Kafka提供了索引文件来提升查询消息的效率,索引文件就是前面介绍的.index和.timeindex。
-
偏移量索引文件(.index)记录的是offset和消息数据物理地址(log文件中的位置)的映射关系;
-
时间戳索引文件(.timeindex)记录的是时间戳和偏移量offset的关系。
索引文件都是二进制的,可以通过dumplog命令查看索引数据:
./kafka-dump-log.sh --files /kafka/kafka-logs-824516cb9a05/mykafka-0/00000000000000000000.index | head -n 10Kafka建立的是一种稀疏索引,并不是每条消息数据都会建立索引,那索引到底有多稀疏,间隔多少条会建立一个索引,这也是由参数来控制:log.index.interval.byte=4096。
Kafka根据消息大小来控制,写入消息超过4KB,.index和.timeindex会增加一条索引信息。值越小,索引越密集,检索速度更快的(消息越小,4KB能够容纳的消息数量就越多,每条索引之间能够容纳更多的消息,同等消息量的情况下索引数量会更少,索引说密集度更高,查询次数也会更少),但是会消耗更多的存储空间。值越大,索引越稀疏,写入的频率相对低节省开销,也节省空间,但是查询耗时也会增加。
Kafka索引的时间复杂度为O(log2n)+O(m),n是索引文件的个数,m为稀疏程度。

Kafka利用索引检索消息的步骤如下:
-
Segment文件使用offset来命名,根据文件名称很快能够找到指定offset对应的Segment索引文件。
-
使用Segment索引文件找到offset对应的log消息position。
-
在对应的log文件中找到对应position,获取消息信息。
时间戳索引有两个用途:
-
基于时间戳切分文件;
-
基于时间戳清理消息;
时间戳有两种,一种是消息创建时的时间戳,一种是Broker追加写入的时间戳,可以通过参数来调整:
log.message.timestamp.type=CreateTime|LogAppendTime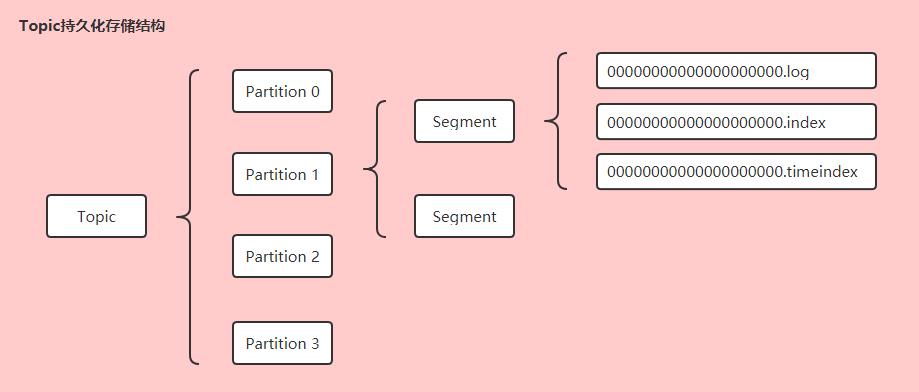
Pt3.5 消息保留机制
有了Segment,有了索引,但是数据文件不断增加,时间久了对存储来说是个头疼的问题,而且数据文件太多,在查找文件时也会降低性能,那就要对数据文件进行清理。
Kafka有两种清理策略,一种是直接删除数据文件,一种是对数据文件进行压缩。
# Kafka数据清理开关配置参数,默认开启
log.cleaner.enable=true
# Kafka数据清理策略参数,默认是直接删除
log.cleanup.policy=delete|compact(1) 直接删除文件
删除策略比较简单,直接找到文件清理即可。但是什么时候触发删除?哪些数据文件应该删除呢?
什么时候删除?
和Redis的数据清理一样,Kafka实现了一个定时任务负责执行数据删除操作,默认5分钟执行一次。
# Kafka执行删除操作的定时任务执行间隔,默认5分钟。
log.retention.check.interval.ms=300000删除那些文件?
要删除的数据文件肯定是最老的那些文件,也是由参数控制。
# 指定超过多少小时的数据会被删除,默认168小时(一周)
log.retention.hours=168
# 指定超过多少分钟的数据会被删除,默认为空。优先级高于hours,如果配置此参数将使用此配置。
log.retention.minutes=
# 指定超过多少毫秒的数据会被删除,默认为空。优先级高于hours和minutes,如果配置此参数将使用此配置。
log.retention.ms=根据时间配置是基于正常情况,假如碰上双十一,618,那一周的体量可能是平时的几十、上百倍,单纯根据时间限制就可能出问题,所以Kafka也提供了基于大小限制的删除策略。大小限制指的是数据文件的总体大小,如果超过大小限制,先删除老数据,直到删到不超过这个大小为止。
# 数据文件总的大小限制,默认-1代表不限制
log.retention.bytes=-1(2) 文件压缩策略
压缩策略是对文件进行压缩,而不是物理删除,配置参数开启压缩处理。
# Kafka数据清理开关配置参数,默认开启
log.cleaner.enable=true
# Kafka数据清理策略参数,默认是直接删除
log.cleanup.policy=compact在很多实际场景中,消息的 key 和 value 的值之间的对应关系是不断变化的,就像数据库中的数据会不断被修改一样,消费者只关心 key 对应的最新的 value。因此,我们可以开启 kafka 的日志压缩功能,服务端会在后台启动Cleaner线程池,定期将相同的key进行合并,只保留最新的 value 值。
日志的压缩原理如下图:

Pt3.6 高可用策略
(1) Controller选举
新分区创建的时候,或者当前分区中Leader挂了的时候,需要从所有副本中选举出新的Leader负责对外提供服务,这个选举机制怎么操作呢?先来了解下Kafka的控制器。
Kafka集群中会有多个broker,其中有一个broker会被选举为控制器(Kafka Controller),它负责管理整个集群中所有分区和副本的状态。
-
当某个分区的leader副本(一个分区会有多个副本,其中只有leader副本对外提供读写服务)出现故障时,由控制器负责为该分区选举新的leader副本。
-
当检测到某个分区的ISR集合发生变化时,由控制器负责通知所有broker更新其元数据信息。
-
当为某个Topic增加分区数量时,由控制器负责分区的重新分配。
控制器是如何被选举出来的呢?
这点和Redis哨兵很像,Kafka中的控制器选举工作依赖于Zookeeper,Kafka的所有Broker会尝试在zk中创建临时节点/controller,当然只会有一个创建成功(zk特性,先到先得),创建成功的Broker成功竞选为Controller。同时,如果Controller变得不可用,zk上临时节点会自动删除,其它Broker通过watch监听到Controller下线,会重新竞选新的Controller。
在任意时刻,集群中有且只有一个控制器。每个broker启动的时候会去尝试读取/controller节点的brokerid的值,如果读取到的brokerid的值不为-1,表示已经有其他broker节点成功竞选为控制器,所以当前broker就会放弃竞选;如果Zookeeper中不存在/controller节点,或者这个节点的数据异常,那么就会尝试去创建/controller节点。当前broker去创建节点的时候,也有可能有其他broker同时去尝试创建这个节点,只有创建成功的那个broker才会成为控制器。每个broker都会在内存中保存当前控制器的brokerid值,这个值可以标识为ActiveControllerId。
Zookeeper中还有一个与控制器有关的/controller_epoch节点,这个节点是持久(Persistent)节点,节点中存放的是一个整型的controller_epoch值。controller_epoch值用于记录控制器发生变更的次数,即记录当前的控制器是第几代控制器,我们也可以称之为“控制器纪元”。
Controller节点的职责
具备控制器身份的broker需要比其他普通的broker多一份职责,具体细节如下:
-
监听Partition相关的变化
-
为ZK中的/admin/reassign_partitions节点注册PartitionReassignmentHandler用来处理分区重新分配的动作。
-
为ZK中的/admin/isr_change_notification节点注册IsrChangeNotificetionHandler ,用来处理ISR副本集合的变更动作。
-
为ZK中的admin/preferred-replica-election节点添加PreferredReplicaElectionHandler,用来处理Leader副本选举的动作。
-
-
监听Topic相关的变化
-
为ZK中的/brokers/topics节点添加TopicChangeHandler,用来处理Topic增减的变化
-
为ZK中的/admin/delete_topics节点注册TopicDeletionHandler,用来处理主题的删除动作
-
-
监听Broker的变化
-
为ZK中的/brokers/ids节点添加BrokerChangeHandler,用来处理Broker增减的变化
-
-
从ZK中获取Broker、Topic、Partition相关的元数据信息
-
为/brokers/topics/<topic>节点注册PartitionModificationHandler,主题中分区分配的变化
-
-
启动并管理分区状态机和副本状态机
-
更新集群的元数据信息,并同步给其它的Broker
-
如果开启了自动优先副本选举,那么会后台启动一个任务用来自动维护优先副本的均衡。
(2) 副本Leader选举
并不是所有的分区副本都有资格参与选举。
在Kafka中,一个分区所有的副本,叫做Assigned-Replicas(AR);在所有副本中,跟Leader数据保持一定程度同步的,叫做In-Sync Replicas(ISR);跟Leader同步滞后比较多的副本,叫做Out-Sync Replicas(OSR)。默认情况下,同步延迟超过30秒(消息时间戳),就会被踢出ISR,如果同步程度追上来,就会重新加入ISR。
默认只有ISR中的副本才有资格参与Leader选举,但是如果因为一些异常情况,所有副本同步都延迟(ISR为空),可以允许ISR之外的副本参与选择,就是unclean leader election。需要将参数unclean.leader.election.enable设置为true,不过不建议开启,会导致数据丢失。
找到了Controller,也有了ISR,怎么选举出Topic分区的Leader呢?
副本的选举一般是在创建Topic或者Leader下线时发生的,Kafka中默认的leader的选举策略是OfflinePartitionLeaderElectionStrategy,这个策略会从AR中按顺序查找第一个存活的副本,并且这个副本必须在ISR中,如果不进行分区的重新分配,AR中的副本以及顺序是不变的,但是ISR会变,所以一般来说,Leader就是优先副本。
举例来说,我们有3个副本1、2和3。当前Leader是副本1,如果挂了就只剩2和3。按照副本顺序来说2优先于3,如果副本2在ISR中那它就会成为新的Leader;如果2不在ISR,就看3在不在ISR,如果在3就成为新的Leader,如果不在就要看是否允许ISR之外的副本参与选举,如果允许还是2优先。
(3) 副本主从同步
在Kafka副本中,只有Leader节点会对外提供读写服务,Follower只需要从Leader同步数据,不同Follower同步的Offset肯定不完全是一致的,那么同步的过程是怎样的呢?
先来介绍几个概念:
-
LSO(Log Start Offset):开始同步的Offset,一般是0。
-
LEO(Log End Offset):当前副本下一条等待写入消息的Offset(最新消息Offset + 1)。
-
HW(Hign Watermark):ISR中最小的LEO。
先来看图:
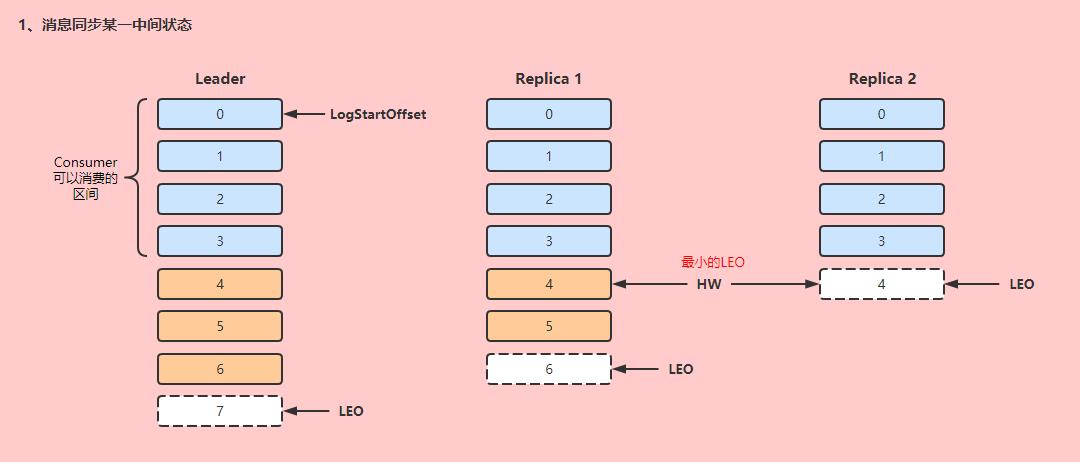
Leader会管理所有ISR中最小的LEO,作为HW,Consumer最多只能消费到HW之前的位置(图中offset=3),ISR副本中没有完成同步的消息,是不能被Consumer消费的。这样就保证了不会出现,Consumer已经消费了offset=6,但是此时Leader挂了,新的Leader的Offset却小于Consumer已经消费的消息Offset,出现了消息缺失的情况。
如果Follower完成数据同步,则会同步推进LEO和HW:
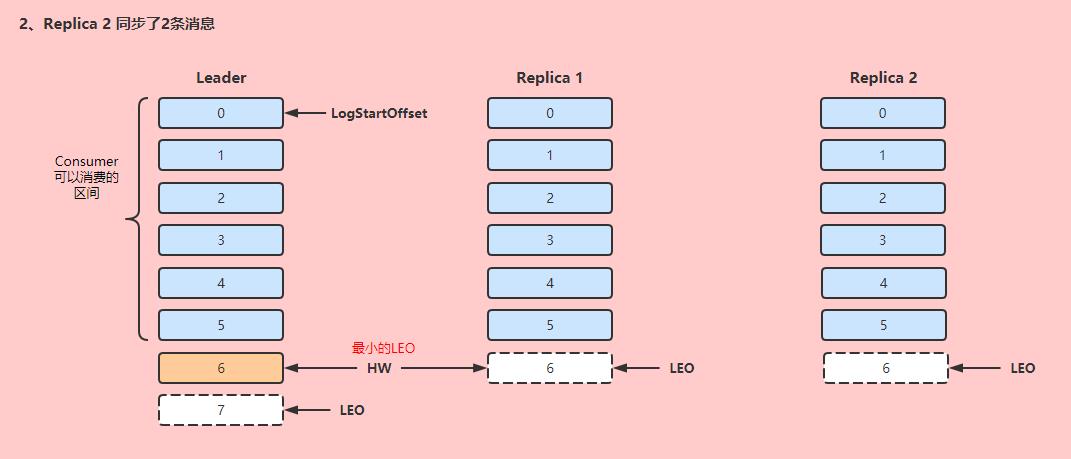
大概同步流程如下:
-
Follower节点向Leader节点发送一个fetch请求,Leader根据当前Follower的LEO发送需要同步的数据,然后更新当前Follower的LEO。
-
Follower接收数据,完成消息写入,并更新自身LEO。
-
Leader更新HW(维护的ISR中最小LEO)。
(4) 副本故障处理
假设当前集群状态如下。
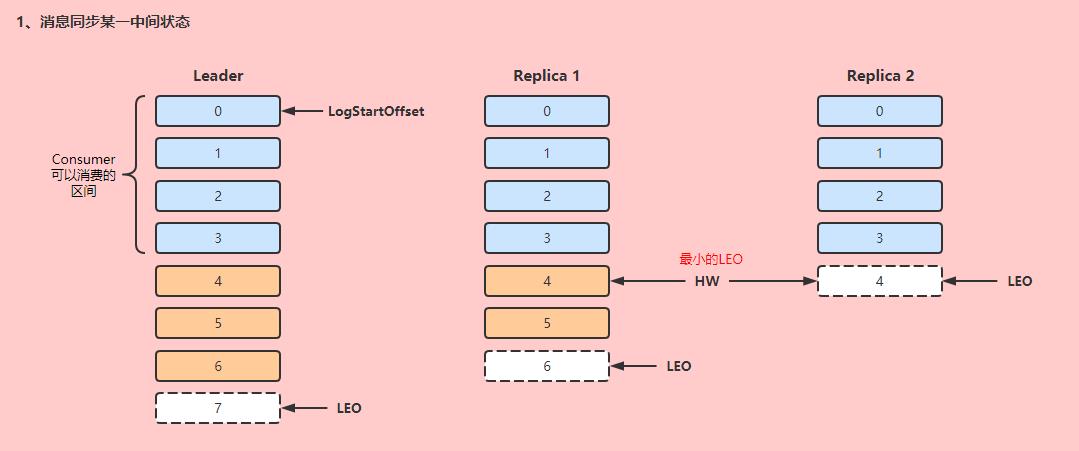
当某一Follower发生故障时,会被先剔除ISR(与Leader节点消息同步延迟超过30秒),如果Follower故障恢复,重新从Leader节点同步数据。
假设副本Replica 1宕机后恢复,宕机前记录的HW为4(说明可能当前集群只消费到Offset=3的消息),他会先把本地记录的大于等于HW的消息都清除(offset=4/5),然后向Leader发送消息同步的请求。
等到消息同步进度追到Leader进度的30秒以内时,会重新加入ISR。
假设Leader发生故障,首先需要选择一个新的Leader(图中Replica 1优先,会成为Leader)。为了保证消息的一致性,其它Follower需要把大于等于HW的消息截取掉,然后其它副本开始向Leader发送消息同步请求。
在这种同步机制下,消息会发生丢失,但是副本间数据一致性是可以保证的。
(5) 消息不丢失配置
通过如下配置能够尽可能保证消息不丢失。
-
Producer使用带有回调的send(msg, callback),而不是send(msg),一旦出现失败,可以针对性设置补偿措施。
-
设置acks = all。当Partition的Leader和Follower都提交时,才算已提交,保证高可用。
-
设置retries为一个较大的值,当网络出现抖动时,能够自动重试发送消息,避免消息丢失或者发送失败。
-
设置unclean.leader.election.enable = false,非ISR中的Follower不能参与Leader选举,避免选举一个不可用的节点做Leader。
-
设置replication.factor >= 3,保证有三个或以上副本。
-
设置min.insync.replicas > 1,默认值是1,意味着在Broker端,消息只要被写入1个副本就算是已提交。在生产环境中,设置成大于1来提升消息可靠性,同时要保证replication.factor > min.insync.replicas,推荐设置为replication.factor = min.insync.replicas + 1。如果设置为相等,万一有副本发生抖动或不可用,整个分区就无法提交,无法工作。
-
确认消息消费完成再提交。Consumer端有个参数enable.auto.commit,最好置为false,由消费端自己处理offset的提交更新。
PT4 消费者原理
Pt4.1 Offset维护
Kafka Offset是由Broker端维护,以分区为维度来隔离,从1开始计数,0是没有数据,分区内有序,全局不保证有序。
分区消息是不断追加到Segment,连续有序,消费之后也不会被删除,所以Kafka可以读取历史消息进行消费。Kafka通过Offset来维护当前分区消息的消费进度,由Broker统一维护(因为一个分区可以被多个Consumer消费,只有在服务端维护Offset才能做到一致性)。
早期Kafka将partition,consumer group和offset维护在zk中,但是读写频率高,性能损耗太大。后来是将它维护在一个特殊的Topic中,名为__consumer_offsets,默认有50个分区,每个默认默认1个replica。
__consumer_offsets主要负责存储两种对象:
-
GroupMetadata:保存了消费者组中各个消费者信息(每个消费者都有编号)。
-
OffsetAndMetadata:保存了消费者组和各个partition的Offset数据
通过脚本可以查看_consumer_offsets信息:./kafka-console-consumer.sh --topic
__consumer_offsets --bootstrap-server 121.4.33.15:9092 --formatter "kafka.coordinator.group.GroupMetadataManager\\$OffsetsMessageFormatter" --from-beginning
./kafka-console-consumer.sh --topic __consumer_offsets --bootstrap-server 121.4.33.15:9092 --formatter "kafka.coordinator.group.GroupMetadataManager$OffsetsMessageFormatter" --from-beginning
# 数据比较多,截取部分。
[first-group,first_topic,0]::OffsetAndMetadata(offset=8, leaderEpoch=Optional[0], metadata=, commitTimestamp=1622193793127, expireTimestamp=None)
[first-group,first_topic,0]::OffsetAndMetadata(offset=8, leaderEpoch=Optional[0], metadata=, commitTimestamp=1622193794128, expireTimestamp=None)
[first-group,first_topic,0]::OffsetAndMetadata(offset=8, leaderEpoch=Optional[0], metadata=, commitTimestamp=1622193795129, expireTimestamp=None)
[first-group,first_topic,0]::OffsetAndMetadata(offset=8, leaderEpoch=Optional[0], metadata=, commitTimestamp=1622193796128, expireTimestamp=None)
[first-group,first_topic,0]::OffsetAndMetadata(offset=8, leaderEpoch=Optional[0], metadata=, commitTimestamp=1622193797129, expireTimestamp=None)
[first-group,first_topic,0]::OffsetAndMetadata(offset=8, leaderEpoch=Optional[0], metadata=, commitTimestamp=1622193798129, expireTimestamp=None)
[first-group,first_topic,0]::OffsetAndMetadata(offset=8, leaderEpoch=Optional[0], metadata=, commitTimestamp=1622193799129, expireTimestamp=None)
[first-group,first_topic,0]::OffsetAndMetadata(offset=8, leaderEpoch=Optional[0], metadata=, commitTimestamp=1622193800131, expireTimestamp=None)
[first-group,first_topic,0]::OffsetAndMetadata(offset=8, leaderEpoch=Optional[0], metadata=, commitTimestamp=1622193801133, expireTimestamp=None)
[first-group,first_topic,0]::OffsetAndMetadata(offset=8, leaderEpoch=Optional[0], metadata=, commitTimestamp=1622193802133, expireTimestamp=None)
[first-group,first_topic,0]::OffsetAndMetadata(offset=8, l以上是关于09 APACHE KAFKA原理的主要内容,如果未能解决你的问题,请参考以下文章