无标题
Posted chocolate2018
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了无标题相关的知识,希望对你有一定的参考价值。
NXP eIQ 机器学习 — 1
第1章 软件栈简介
NXP®eIQ®机器学习软件开发环境(以下简称“NXP eIQ”)为针对NXP微控制器和应用处理器的机器学习应用程序提供了一套库和开发工具。NXP eIQ包含在meta-imx/meta-ml Yocto层中。有关更多信息,请参阅i.MX Yocto项目用户指南(IMXLXYOCTOUG)。
NXP eIQ软件栈目前支持以下六个推理引擎:TensorFlow Lite、ONNX Runtime、PyTorch、DeepViewTMRT、OpenCV和Arm NN。下图显示了跨计算单元支持的eIQ推理引擎。
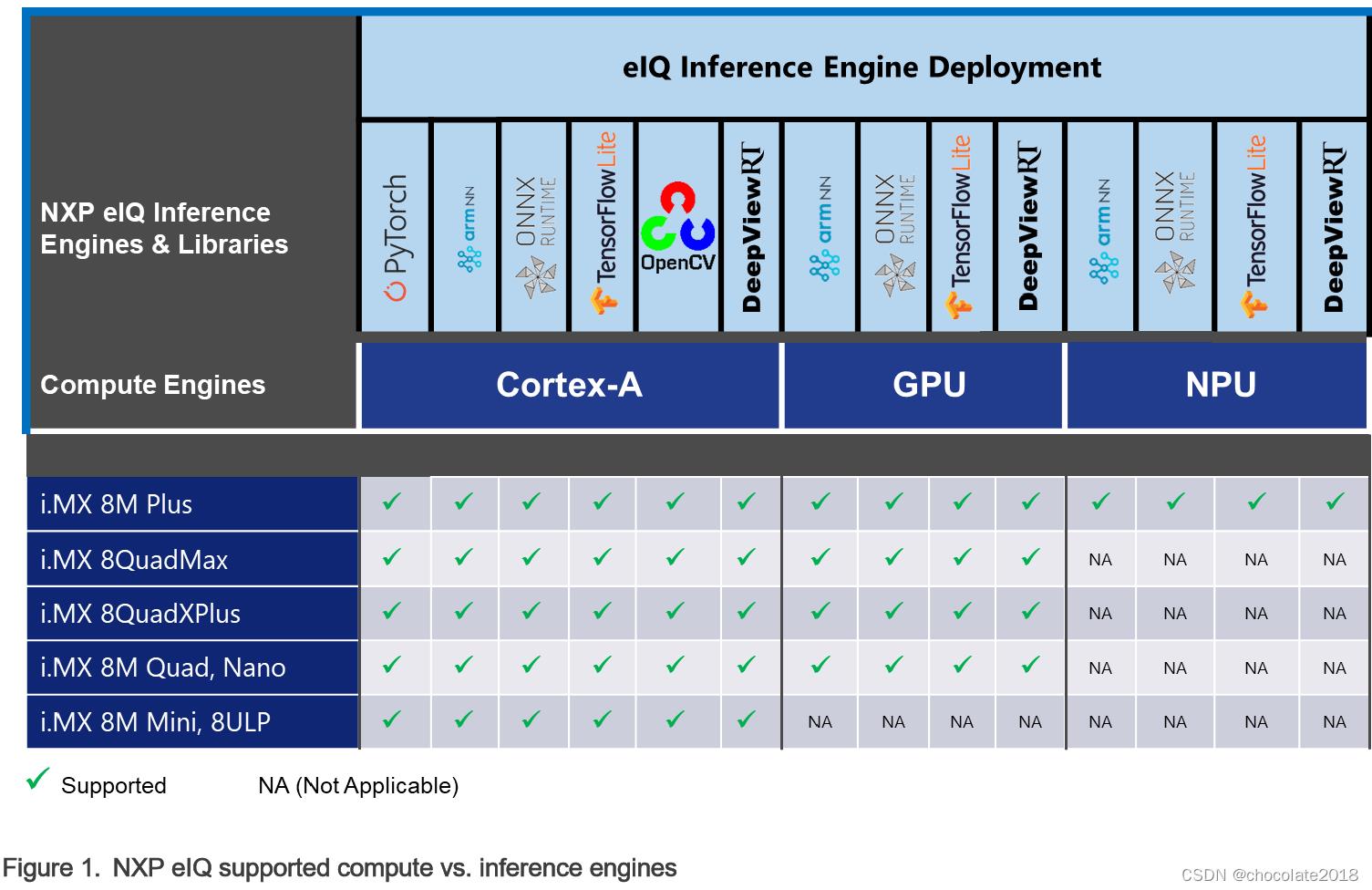
NXP eIQ推理引擎支持Cortex-A核心上的多线程执行。此外,ONNX运行时,TensorFlow Lite, DeepViewRT和Arm NN也支持GPU或NPU上的加速通过神经网络运行时(NNRT)。参见eIQ推断运行时概述。
请注意 Arm NN推理引擎已弃用,未来将移除。
通常,NXP eIQ准备支持以下关键应用领域:
•视力
-多摄像机观测
-活动对象识别
-手势控制
•语音
-语音处理
-家庭娱乐
•声音
-智能感知和控制
-目视检查
-声音监控
第2章 eIQ推断运行时概述
本章概述了与NXP神经网络加速器IPs(GPU或NPU)一起使用的NXP eIQ软件堆栈。下图显示了每个元素之间的数据流。下图有两个关键部分:
神经网络运行时(NNRT),它是连接各种推理框架和神经网络加速器驱动程序的中间件。
TIM-VX是一个软件集成模块,用于促进神经网络在支持OpenVX的ML加速器上的部署。
ModelRunner for DeepViewRT是一个服务器应用程序,能够使用HTTP REST API、Python API或UNIX RPC服务接收请求,并将这些请求直接委托给不同的推理引擎或NN加速器驱动程序。有关更多详细信息,请参见ModelRunner。
NNRT为android NN HAL、Arm NN、ONNX和TensorFlow Lite提供了不同的后端,允许快速部署应用程序。NNRT还为i.MX8处理器提供了一个面向应用程序的框架。诸如Android NN、TensorFlow Lite和Arm NN等应用程序框架可以通过NNRT直接受益于其内置的后端插件来加速。还可以实现其他后端,以扩展对其他框架的支持。
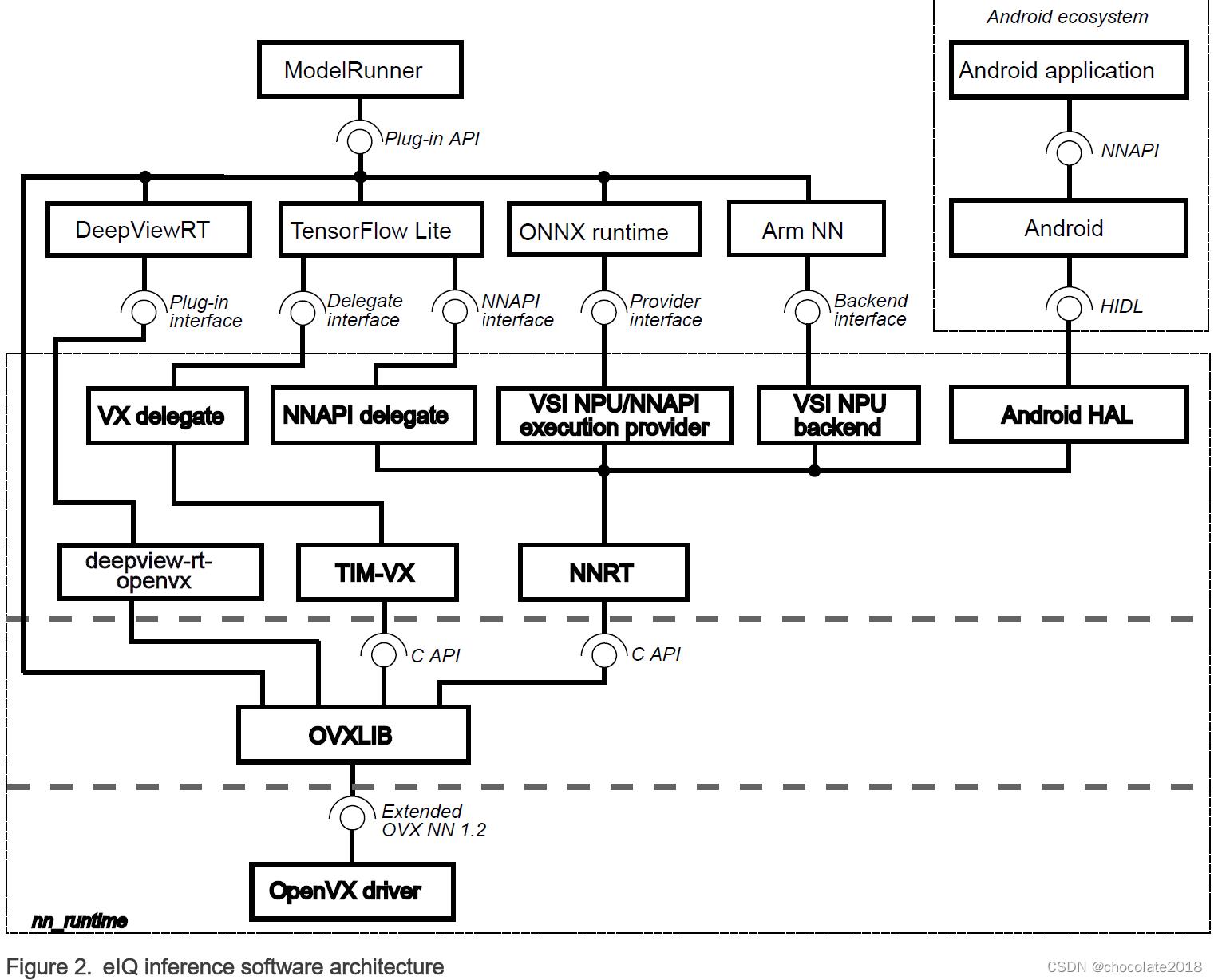
NNRT通过将自身注册为计算后端来支持不同的机器学习框架。由于每个框架定义了不同的后端API,因此为每个框架设计了一个轻量级后端层:
对于Android NN,NNRT遵循Android HIDL定义。它与v1.2 HAL接口兼容
对于TensorFlow Lite,NNRT支持NNAPI委托。它支持Android NNAPI v1.2中的大多数操作
对于Arm NN,NNRT将自己注册为计算后端
对于ONNX运行时,NNRT将自己注册为执行提供程序
这样,NNRT统一了应用程序框架的差异,并为驱动程序堆栈提供了通用运行时接口。同时,NNRT还充当异构计算平台,用于在i.MX8计算设备(如NPU、GPU和CPU)上进一步高效地分配工作负载。
注意事项: OpenCV和PyTorch推理引擎目前都不支持在NXP NN加速器上运行。因此,上述NXP-NN架构图中不包括这两个框架。
第3章 TensorFlow Lite
TensorFlow Lite是一个开源软件库,专注于在移动和嵌入式设备上运行机器学习模型(可在 http://www.tensorflow.org/lite 获得)。它使设备上的机器学习推理具有低延迟和较小的二进制大小。TensorFlow Lite还支持在各种i.MX 8平台(NXP eIQ中)上使用VX代理或Android OS神经网络API(NNAPI)进行硬件加速。
此Yocto Linux版本的TensorFlow Lite源代码可在此存储库中获得,分支
lf-5.15.5_1.0.0 。该存储库是主线的分支https://github.com/tensorflow/tensorflow,并针对NXP i.MX8平台进行了优化。
特点:
TensorFlow Lite v2.6.0
Cortex-A核上使用Arm Neon SIMD指令加速的多线程计算
使用GPU/NPU硬件加速的并行计算(在着色器或卷积单元上)
C++和Python API(支持Python版本3)
每张量和每通道量化模型支持
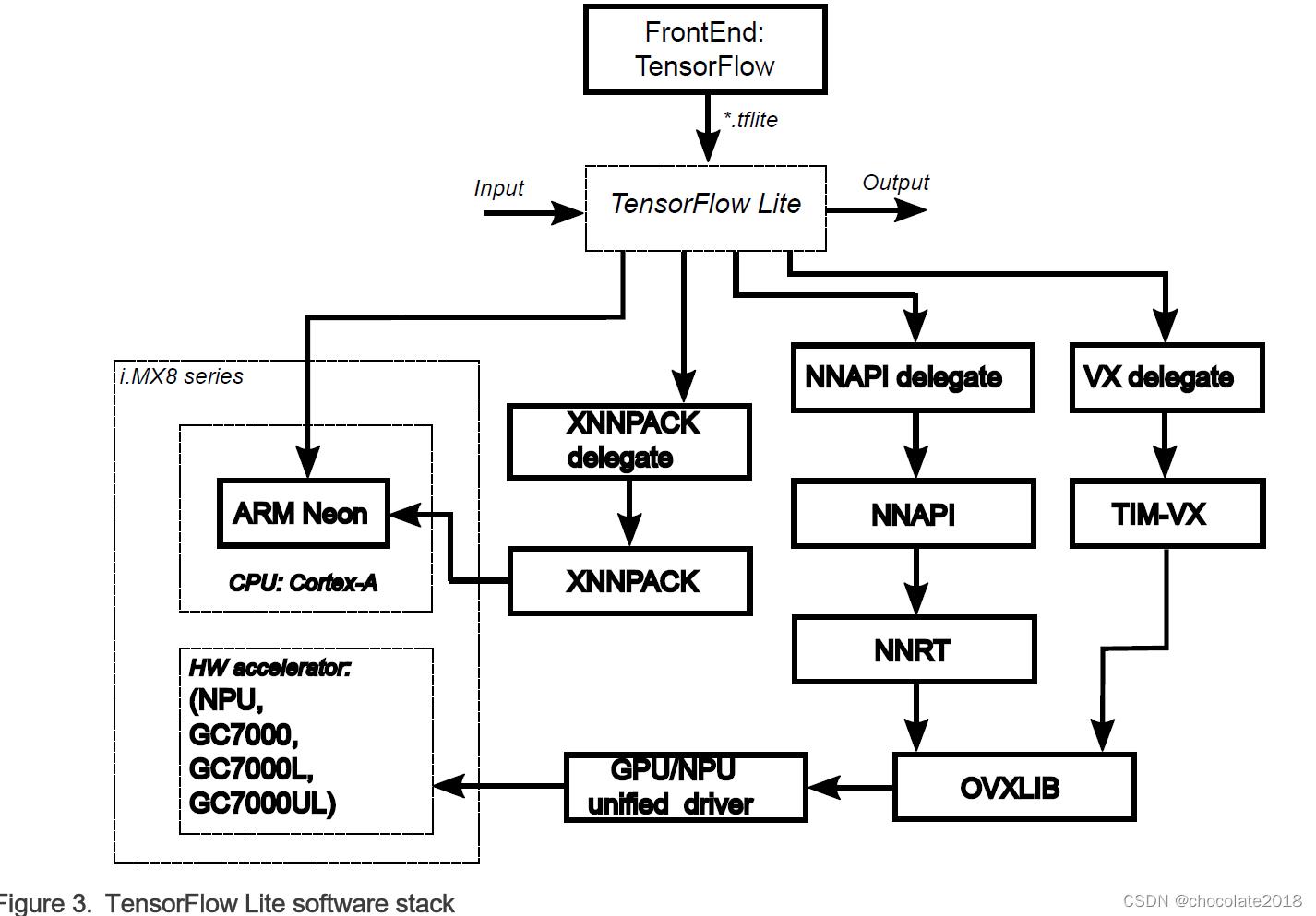
3.1 TensorFlow Lite软件栈
TensorFlow Lite软件堆栈如下图所示。TensorFlow Lite支持在以下硬件单元上进行计算:
CPU Arm Cortex-A内核
使用Android NNAPI驱动程序或VX委托的GPU/NPU硬件加速器
有关在不同硬件平台上支持GPU/NPU硬件加速器计算的详细信息,请参阅软件堆栈介绍。
请注意:
第一次使用NNAPI或VX委托执行模型推断将花费更长的时间,因为GPU/NPU驱动程序需要时间来进行计算图的初始化。图初始化之后的迭代将执行得更快。请注意,计算图是操作及其依赖关系的表示,以执行由模型指定的计算。计算图在模型解析阶段建立。
NNAPI和VX委托实现使用OpenVX™库在GPU/NPU硬件加速器上执行计算图形。因此,OpenVX库支持必须对所选设备可用,以便能够使用加速。关于OpenVX库可用性的更多细节,请参阅i.MX图形用户指南(IMXGRAPHICUG)。
参考i.MX图形用户指南来获取支持OpenVX的gpu列表。注意GC7000 Lite和GC7000 Ultra Lite gpu不支持完全的OpenVX,但是仍然能够运行ML工作负载。
GPU/NPU硬件加速驱动支持每张量和每通道量化模型。GPU/NPU硬件加速器针对每个张量量化模型进行了优化。在每通道量化模型的情况下,性能可能会更低。实际影响取决于所使用的模型。
3.2计算后端和委托
TensorFlow Lite提供了执行各种计算单元的计算操作的选项。我们将它们称为推断后端。
3.2.1内置的内核
默认的推断后端是带有来自TensorFlow Lite实现的引用内核的CPU。内置内核提供了对TensorFlow Lite操作符集的完全支持。
内置内核是在启用RUY矩阵乘法库的情况下构建的,这提高了内核用于浮点和量化操作的性能。
3.2.2 XNNPACK委托
XNNPACK库是一个高度优化的浮点神经网络推理操作符库,适用于ARM、WebAssembly和x86平台。XNNPACK库可以通过TensorFlow Lite中的XNNPACK委托使用。XNNPACK委托计算是在CPU上执行的。
它为浮点运算符的TensorFlow Lite运算符集的一个子集提供了优化的实现。一般来说,它提供了比内置的浮点运算符内核更好的性能。
请注意
自TensorFlow Lite 2.6.0以来,默认情况下浮点模型是通过XNNPACK委托执行的。
3.2.3 NNAPI委托
NNAPI委托能够加速片上硬件加速器上的推断。该委托基于Android的神经网络API (NNAPI)规范。完整的规范可以在这里获得:https://developer.android.com/ndk/reference/group/neural-networks。
TensorFlow Lite库使用来自GPU/NPU驱动的Android NNAPI实现来运行GPU/NPU硬件加速器的推断。实现的NNAPI版本是1.2,与TensorFlow Lite的特性集相比,它在支持的张量数据类型和操作方面有一些限制。因此,一些模型可能在没有启用加速的情况下工作,但在使用NNAPI时可能会失败。有关支持的功能的完整列表,请参阅NNAPI文档的NN HAL版本部分。
NNAPI规范自带操作符集,它包含了来自TensorFlow Lite操作符集的大部分操作符,但不是全部。此外,并非所有的TensorFlow Lite操作符变体都被NNAPI支持。这对于硬件加速器操作符支持是有效的,加速器支持一些操作符,但不是NNAPI规范的一部分。因此,即使HW加速器支持特定的层,某些层的执行也可能不必要地落在CPU上。
对于模型中被NNAPI委托拒绝的所有操作符,TensorFlow Lite运行时将打印一条警告消息,说明该操作符被委托拒绝的原因:
操作符ARG_MAX (v1)被NNAPI委托拒绝:NNAPI只支持int32输出。此信息可用于优化模型以获得更好的性能。
请注意
Linux平台的NNAPI委托已弃用,并将在未来被移除。使用VX委托代替。在Python API中不支持NNAPI委托。
3.2.4 VX委托
VX委托是inmx 8 Linux平台上NNAPI委托的继承者。它能够加速片上硬件加速器的推理。VX委托直接使用硬件加速器驱动程序(带有扩展的OpenVX)来充分利用加速器功能。通过NNAPI委托,它提供了与片上HW加速器能力更好的对齐。
VX委托作为外部委托[1]可用。对应的库可以在/usr/lib/libvx_delegate.so中找到。
c++和Python API都支持VX委托。要使用VX委托(或任何外部委托),请参阅c++中的external_delegate_provider实现和/或Python中的label_image.py。op_status.md中提供了支持的操作符列表。
3.3交付计划
TensorFlow Lite可以使用Yocto项目配方。
TensorFlow Lite交付包包含:
TensorFlow Lite共享库
TensorFlow Lite头文件
用于TensorFlow Lite的Python模块
图像分类示例应用程序,适用于c++ (label_image)和Python (label_image.py)
TensorFlow Lite基准测试应用(benchmark_model)
TensorFlow Lite评估工具(coco_object_detection_run_eval, imagenet_image_classification_run_eval, inference_diff_run_eval),详见TensorFlow Lite委托。
对于应用程序开发,TensorFlow Lite共享库和头文件在SDK中可用。有关更多细节,请参阅应用程序开发一节。
在TensorFlow Lite 2.6.0交付包中有以下委托:
XNNPACK委托
NNAPI委托(弃用)
VX委托
3.4 构建细节
TensorFlow Lite使用CMake构建系统进行编译。对包构建的注意事项是:
启用RUY矩阵乘法库(TFLITE_ENABLE_RUY=On)。与使用Eigen和GEMLOWP构建的内核相比,RUY矩阵乘法库提供了更好的性能。
支持XNNPACK Delegate (TFLITE_ENABLE_XNNPACK)
NNAPI代表支持2,包括拒绝操作的警告消息(TFLITE_ENABLE_NNAPI_VERBOSE_VALIDATION=On)
外部委托支持(TFLITE_ENABLE_EXTERNAL_DELEGATE=On)
构建运行时库并作为共享库提供(TFLITE_BUILD_SHARED_LIB=On)。如果优先选择TensorFlow Lite库到应用程序的静态链接,则保持该开关处于关闭状态(默认设置)。如果应用程序是用CMake构建的,这可能会很方便,如创建CMake项目章节所述,使用TensorFlow Lite。
该包使用默认的-O2优化级别编译。一些CPU内核,例如RESIZE_BILINEAR,在-O3优化级别下表现更好,但是一些内核在-O2下表现更好,例如ARG_MAX。建议根据应用需求调整优化级别。
Yocto项目用这些设置构建TensorFlow Lite。构建配置可以通过在meta-imx层(位于
meta-imx/meta-ml/recipes-libraries/tensorflow-lite/)更新TensorFlow Lite Yocto配方来改变,或者使用CMake和Yocto SDK从源代码构建TensorFlow Lite。
3.5应用程序开发
本节介绍TensorFlow Lite c++ API在应用程序开发中的使用。
要开始TensorFlow Lite c++应用程序开发,首先必须生成Yocto SDK。参见i.MX Yocto项目用户指南(IMXLXYOCTOUG)了解如何生成用于交叉编译的Yocto SDK环境的详细信息。要在主机上激活这个Yocto SDK环境,使用以下命令:
$ source <Yocto_SDK_install_folder>/environment-setup-aarch64-poky-linux
要构建一个使用TensorFlow Lite的应用程序,有以下选项:
创建CMake项目,使用TensorFlow Lite (CMake superbuild模式)
使用Yocto SDK预编译库
TensorFlow Lite的CMake配置文件位于根库TensorFlow / Lite /CMakeLists.txt中(用于NXP i.MX8平台)。
3.5.1 创建使用TensorFlow Lite的CMake项目
推荐的方法是创建一个使用TensorFlow Lite的CMake项目,如用CMake构建TensorFlow Lite中描述的那样。CMake负责依赖项的准备工作,包括下载、配置和构建步骤。
为了演示这个构建选项,在tensorflow/lite/examples/minimal中有一个最小的示例项目。构建:
1.按照上面的描述设置Yocto SDK
2.使用CMake配置项目:
$ mkdir build-minimal-example; cd build-minimal-example
$ cmake -DCMAKE_TOOLCHAIN_FILE=$OE_CMAKE_TOOLCHAIN_FILE -DTFLITE_ENABLE_XNNPACK=on \\ -DTFLITE_ENABLE_RUY=on -DTFLITE_ENABLE_NNAPI=on -DTFLITE_ENABLE_NNAPI_VERBOSE_VALIDATION=on \\ -DTIM_VX_INSTALL=$SDKTARGETSYSROOT/usr ../tensorflow/lite/examples/minimal
3.构建项目:
$ cmake --build . -j4
4.最小的示例可以在build目录中找到:
$ file minimalminimal: ELF 64-bit LSB shared object, ARM aarch64, version 1 (GNU/Linux), dynamically linked, interpreter /lib/ld-linux-aarch64.so.1, BuildID[sha1]=4a928894439e0b33217ea28790378690ab4ce7cd, for GNU/Linux 3.14.0, with debug_info, not stripped
5.你可以选择剥离最终的二进制文件:
$ $STRIP --remove-section=.comment --remove-section=.note --strip-unneeded <file>
这个构建选项有几个优点:
基于配置选项的自动依赖关系解析
选择静态链接还是动态链接(TFLITE_BUILD_SHARED_LIB=on/off)
在Debug模式下构建整个项目(包括它的依赖项)(CMAKE_BUILD_TYPE=Debug/Release/…),以增强调试体验
3.5.2使用Yocto SDK预编译库
另一种选择是使用预编译的二进制文件和头文件,它们可以直接在Yocto SDK中获得。Yocto SDK中的TensorFlow Lite构件如下:
TensorFlow Lite共享库(libtensorflow-lite.so)在/usr/lib
TensorFlow Lite头文件在/usr/include中
请注意
并非所有的TensorFlow Lite依赖都安装在Yocto SDK中,有必要下载并手动构建它们。所需的版本请参阅tensorflow/lite/tools/cmake/modules/文件夹。
要构建位于tensorflow/lite/examples/label_image/中的图像分类演示(label_image),请遵循以下步骤:
1.创建构建目录:
$ mkdir build-manual
$ cd build-manual
- 下载Abseil库依赖项:
$ wget https://github.com/abseil/abseil-cpp/archive/6f9d96a1f41439ac172ee2ef7ccd8edf0e5d068c.tar.gz -O abseil-cpp.tar.gz
$ tar -xzf abseil-cpp.tar.gz
$ mv abseil-cpp-6f9d96a1f41439ac172ee2ef7ccd8edf0e5d068c abseil-cpp
3.构建label_image示例:
$ $CC ../tensorflow/lite/examples/label_image/label_image.cc ../tensorflow/lite/examples/label_image/bitmap_helpers.cc ../tensorflow/lite/tools/evaluation/utils.cc ../tensorflow/lite/tools/delegates/delegate_provider.cc -Iabseil-cpp -O2 -ltensorflow-lite -lstdc++ -lpthread -lm -ldl -lrt
3.6运行图像分类示例
包含机器学习层的Yocto Linux BSP图像默认包含一个简单的预安装示例,名为“label_image”,可用于图像分类模型。示例二进制文件位于:
/usr/bin/tensorflow-lite-2.6.0/examples

演示说明:
在CPU上使用mobilenet模型运行示例,使用如下命令:
$ ./label_image -m mobilenet_v1_1.0_224_quant.tflite -i grace_hopper.bmp -l labels.txt
对于’grace_hopper.bmp’输入图像,i.MX 8MPlus SoC上成功分类的输出如下:
Loaded model mobilenet_v1_1.0_224_quant.tflite
resolved reporter
invoked
average time: 39.271 ms
0.780392: 653 military uniform
0.105882: 907 Windsor tie
0.0156863: 458 bow tie
0.0117647: 466 bulletproof vest
0.00784314: 835 suit
要使用XNNPACK委托在CPU上运行示例应用程序,请使用
–use_xnnpack=true开关
$ ./label_image -m mobilenet_v1_1.0_224_quant.tflite -i grace_hopper.bmp -l labels.txt --use_xnnpack=true
要在GPU/NPU硬件加速器上运行相同型号的示例,添加
–use_nnapi=true (用于NNAPI委托)或
–external_delegate_path=/usr/lib/libvx_delegate.so (对于VX委托)命令行参数。为了区分3D GPU和NPU,可以使用环境变量USE_GPU_INFERENCE。例如,使用VX委托在NPU硬件上运行加速模型,使用以下命令:
$ USE_GPU_INFERENCE=0 ./label_image -m mobilenet_v1_1.0_224_quant.tflite -i grace_hopper.bmp -l labels.txt --external_delegate_path=/usr/lib/libvx_delegate.so
i.MX 8MPlus处理器的NPU加速输出如下:
INFO: Loaded model ./mobilenet_v1_1.0_224_quant.tflite
INFO: resolved reporter
Vx delegate: allowed_builtin_code set to 0.
Vx delegate: error_during_init set to 0.
Vx delegate: error_during_prepare set to 0.
Vx delegate: error_during_invoke set to 0.
EXTERNAL delegate created.
INFO: Applied EXTERNAL delegate.
W [HandleLayoutInfer:257]Op 18: default layout inference pass.
INFO: invoked
INFO: average time: 2.567 ms
INFO: 0.768627: 653 military uniform
INFO: 0.105882: 907 Windsor tie
INFO: 0.0196078: 458 bow tie
INFO: 0.0117647: 466 bulletproof vest
INFO: 0.00784314: 835 suit
另外,可以运行使用TensorFlow Lite解释器专用Python API的示例。示例文件位于:
/usr/bin/tensorflow-lite-2.6.0/examples
使用预定义的命令行参数运行这个例子,使用下面的命令:
$ python3 label_image.py
输出应如下:
Warm-up time: 159.1 ms
Inference time: 156.5 ms
0.878431: military uniform
0.027451: Windsor tie
0.011765: mortarboard
0.011765: bulletproof vest
0.007843: sax
Python示例也支持外部委托。开关
–ext_delegate
3.7运行基准测试程序
包含机器学习层的Yocto Linux BSP映像默认包含一个预安装的基准测试应用程序。它执行一个简单的TensorFlow Lite模型推断并打印基准测试信息。应用程序二进制文件位于:
/usr/bin/tensorflow-lite-2.6.0/examples
基准测试说明如下:
在CPU上运行带计算的基准测试,使用以下命令:
$ ./benchmark_model --graph=mobilenet_v1_1.0_224_quant.tflite
您可以使用–num_threads=X参数指定线程的数量,以便在多个核上运行推断。要获得最高的性能,请将X设置为可用的核心数。
基准测试应用程序的输出应该类似于:
STARTING!
Log parameter values verbosely: [0]
Graph: [mobilenet_v1_1.0_224_quant.tflite]
Loaded model mobilenet_v1_1.0_224_quant.tflite
Going to apply 0 delegates one after another.
The input model file size (MB): 4.27635
Initialized session in 3.051ms.
Running benchmark for at least 1 iterations and at least 0.5 seconds but terminate if exceeding 150 seconds.
count=4 first=160408 curr=155384 min=155384 max=160408 avg=156869 std=2076
Running benchmark for at least 50 iterations and at least 1 seconds but terminate if exceeding 150 seconds.
count=50 first=155586 curr=155424 min=155274 max=155622 avg=155443 std=81
Inference timings in us: Init: 3051, First inference: 160408, Warmup (avg): 156869, Inference (avg): 155443
Note: as the benchmark tool itself affects memory footprint, the following is only APPROXIMATE to the actual memory footprint of the model at runtime. Take the information at your discretion.Peak memory footprint (MB): init=4.49219 overall=10.6133
要使用XNNPACK委托运行推断,添加–use_xnnpack=true开关:
$ ./benchmark_model --graph=mobilenet_v1_1.0_224_quant.tflite --use_xnnpack=true
要使用GPU/NPU硬件加速器对NNAPI委托运行推断,添加–use_nnapi=true开关:
$ ./benchmark_model --graph=mobilenet_v1_1.0_224_quant.tflite --use_nnapi=true
要使用GPU/NPU硬件加速器对VX Delegate运行推断,需要添加
--external_delegate_path=/usr/lib/libvx_delegate.so开关:
$ ./benchmark_model --graph=mobilenet_v1_1.0_224_quant.tflite --external_delegate_path=/usr/lib/libvx_delegate.so
GPU/NPU模块加速的输出(对于VX Delegate)应该类似于:
STARTING!
Log parameter values verbosely: [0]
Graph: [mobilenet_v1_1.0_224_quant.tflite]
External delegate path: [/usr/lib/libvx_delegate.so]
Loaded model mobilenet_v1_1.0_224_quant.tflite
Vx delegate: allowed_builtin_code set to 0.
Vx delegate: error_during_init set to 0.
Vx delegate: error_during_prepare set to 0.
Vx delegate: error_during_invoke set to 0.
EXTERNAL delegate created.
Going to apply 1 delegates one after another.
Explicitly applied EXTERNAL delegate, and the model graph will be completely executed by the delegate.
The input model file size (MB): 4.27635
Initialized session in 13.437ms.
Running benchmark for at least 1 iterations and at least 0.5 seconds but terminate if exceeding 150 seconds.
W [HandleLayoutInfer:257]Op 18: default layout inference pass.
count=1 curr=4586473
Running benchmark for at least 50 iterations and at least 1 seconds but terminate if exceeding 150 seconds.
count=398 first=2541 curr=2419 min=2419 max=2549 avg=2467.87 std=13
Inference timings in us: Init: 13437, First inference: 4586473, Warmup (avg): 4.58647e+06, Inference (avg): 2467.87
Note: as the benchmark tool itself affects memory footprint, the following is only APPROXIMATE to the actual memory footprint of the model at runtime. Take the information at your discretion.Peak memory footprint (MB): init=7.24609 overall=34.0117
委托不需要支持TensorFlow Lite运行时定义的全部操作符集合。如果模型包含这样一个操作,而这个操作不被特定的委托所支持,那么这个操作的执行就会通过TensorFlow Lite引用内核返回到CPU。通过这种方式,模型表示的计算图被划分为几个部分,每个部分都被执行。图形分割或者也叫图分区是一个过程,在定义的计算图模型分成小段(或分区)和他们每个人在CPU上执行通过委托或使用参考内核(CPU回退),基于操作支持的委托。
如果在GPU/NPU硬件加速器上加速,这个基准测试应用程序还可以用来检查模型的可选分割。为此,可以使用–enable_op_profiling=true 和 --max_delegated_partitions= (例如,1000)选项的组合。
除了上面给出的输出,NNAPI委托还会报告为什么某个层被拒绝的详细信息:
INFO: Created TensorFlow Lite delegate for NNAPI.
WARNING: Operator RESIZE_BILINEAR (v1) refused by NNAPI delegate: Operator refused due performance reasons.
WARNING: Operator RESIZE_BILINEAR (v1) refused by NNAPI delegate: Operator refused due performance reasons.
WARNING: Operator RESIZE_BILINEAR (v1) refused by NNAPI delegate: Operator refused due performance reasons.
WARNING: Operator ARG_MAX (v1) refused by NNAPI delegate: NNAPI only supports int32 output.Explicitly applied NNAPI delegate, and the model graph will be partially executed by the delegate w/ 2 delegate kernels.
并提供详细的分析信息:
Profiling Info for Benchmark Initialization:
================================= Run Order ===================================
[node type] [start] [first] [avg ms] [%] [cdf%]
ModifyGraphWithDelegate 0.000 4.597 4.597 95.791% 95.791%
AllocateTensors 4.528 0.198 0.101 4.209% 100.000%
======================== Top by Computation Time ==============================
[node type] [start] [first] [avg ms] [%] [cdf%]
ModifyGraphWithDelegate 0.000 4.597 4.597 95.791% 95.791%
AllocateTensors 4.528 0.198 0.101 4.209% 100.000%
Number of nodes executed: 2
=========================== Summary by node type ==============================
[Node type] [count][avg ms] [avg %] [cdf %] [mem KB] [times called]
ModifyGraphWithDelegate 1 4.597 95.791% 95.791% 684.000 1
AllocateTensors 1 0.202 4.209% 100.000% 0.000 2
Timings (microseconds): count=1 curr=4799
Memory (bytes): count=0
2 nodes observed
Operator-wise Profiling Info for Regular Benchmark Runs:
================================ Run Order ====================================
[node type] [start] [first] [avg ms] [%] [cdf%]
TfLiteNnapiDelegate 0.000 14.890 14.894 11.349% 11.349%
RESIZE_BILINEAR 14.896 1.331 1.331 1.014% 12.363%
TfLiteNnapiDelegate 16.227 2.944 2.909 2.216% 14.579%
RESIZE_BILINEAR 19.137 0.279 0.277 0.211% 14.790%
RESIZE_BILINEAR 19.415 44.316 44.496 33.905% 48.695%
ARG_MAX 63.912 67.438 67.332 51.305% 100.000%
========================= Top by Computation Time =============================
[node type] [start] [first] [avg ms] [%] [cdf%]
ARG_MAX 63.912 67.438 67.332 51.305% 51.305%
RESIZE_BILINEAR 19.415 44.316 44.496 33.905% 85.210%
TfLiteNnapiDelegate 0.000 14.890 14.894 11.349% 96.559%
TfLiteNnapiDelegate 16.227 2.944 2.909 2.216% 98.775%
RESIZE_BILINEAR 14.896 1.331 1.331 1.014% 99.789%
RESIZE_BILINEAR 19.137 0.279 0.277 0.211% 100.000%
Number of nodes executed: 6
========================== Summary by node type ===============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
ARG_MAX 1 67.332 51.306% 51.306% 0.000 1
RESIZE_BILINEAR 3 46.102 35.129% 86.435% 0.000 3
TfLiteNnapiDelegate 2 17.802 13.565% 100.000% 0.000 2
Timings (microseconds): count=8 first=131198 curr=130580 min=130580 max=132766 avg=131238 std=616Memory (bytes): count=0
6 nodes observed
根据输出中的“Number of nodes executed”一节,可以判断计算图的哪一部分是在GPU/NPU硬件加速器上执行的。除TfLiteNnapiDelegate外的所有节点都回退到CPU。在上面的例子中,ARG_MAX和RESIZE_BILINEAR节点退回到CPU。
3.8使用TensorFlow Lite转换器进行训练后量化
TensorFlow提供了几种模型量化的方法:
训练后量化与TensorFlow Lite转换器
量化感知训练使用模型优化工具包和TensorFlow Lite转换器
在以前的TensorFlow版本中可以使用其他各种方法
请注意:模型量化也得到了“eIQ工具包”的支持。也请参阅eIQ Toolkit用户指南(EIQTUG)。
涵盖所有这些内容超出了本文档的范围。本节介绍使用TensorFlow Lite Converter进行训练后量化的方法。
该转换器是标准TensorFlow桌面安装的一部分。它用于转换和可选量化TensorFlow模型到TensorFlow Lite模型格式。使用该工具有两种选择:
Python API(推荐)
命令行脚本
本章描述了使用Python API进行训练后量化的过程。对模型转换和量化有用的文档在这里:
Python API文档:https://www.tensorflow.org/versions/r2.6/api_docs/python/tf/lite/TFLiteConverter
模型转换指南:www.tensorflow.org/lite/convert
模型量化指南:https://www.tensorflow.org/lite/performance/post_training_quantization
模型优化指南:https://www.tensorflow.org/model_optimization
请注意:TensorFlow页面上的指南通常涵盖了TensorFlow的最新版本,可能与NXP eIQ中可用的版本不同。要查看哪些特性是可用的,请查看TensorFlow或TensorFlow Lite特定版本对应的API。
目前在NXP eIQ中可用的TensorFlow Lite版本是2.6.0。建议使用对应TensorFlow版本的TensorFlow Lite转换器。TensorFlow Lite运行时应该与以前版本的TensorFlow Lite Converter生成的模型兼容,但是这种向后兼容性不被保证。避免使用连续版本的TensorFlow Lite转换器。
2.6.0版本的转换器具有以下属性:
通过在inference_input_type和inference_output_type中设置所需的数据类型,可以支持输入和输出张量量化。
基于TOCO或MLIR的转换可用。这是由实验al_new_converter属性控制的。由于TOCO已经过时,基于MLIR的转换在2.6.0版本的转换器中已经被默认设置。
MLIR转换器使用动态张量形状,这意味着批量大小的输入张量是不指定的。GPU和NPU硬件加速器不支持动态张量形状,需要关闭。TensorFlow的标准安装没有提供API来控制动态张量形状特征,但可以在TensorFlow安装中停用,如下所示。找到/site-packages/tensorflow/lite/python/lite.py 文件,修改私有方法TFLiteConverterBase._is_unknown_shapes_allowed(self) 的返回为False值,如下所示:
def _is_unknown_shapes_allowed(self):
# Unknown dimensions are only allowed with the new converter.
# Return self.experimental_new_converter
# Disable unknown dimensions support.
return False
请注意
MLIR是TensorFlow使用的一种新的NN编译器,支持量化。在MLIR之前,量化是由TOCO(或TOCO Converter)进行的,现在已经过时了。见https://www.tensorflow.org/api_docs/python/tf/compat/v1/lite/TocoConverter。关于MLIR的详细信息,请参见https://www.tensorflow.org/mlir。
在NN加速器(GPU或NPU)上运行的模型不要使用动态范围方法。它只将权值转换为8位整数,但保留了fp32中的激活,这导致在fp32中运行推断,并为数据转换带来额外的开销。事实上,与fp32模型相比,推断甚至更慢,因为转换是在运行中完成的。
对于训练后的全整数量化,需要一个具有代表性的数据集。在具有代表性的数据集中,样本的选择对最终量化模型的准确性影响很大。创建具有代表性的数据集的最佳实践是:
使用原始浮点模型具有非常好的精度的训练样本,基于模型使用的度量(例如,分类模型使用SoftMax评分,对象检测模型使用IOU等)。
有代表性的数据集应该有足够的样本。
相对于所需的模型精度,代表性数据集的大小和其中可用的特定样本被认为是需要调优的超参数。
以上是关于无标题的主要内容,如果未能解决你的问题,请参考以下文章