十年磨一剑,云原生分布式数据库PolarDB-X的核心技术演化
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了十年磨一剑,云原生分布式数据库PolarDB-X的核心技术演化相关的知识,希望对你有一定的参考价值。
PolarDB-X前身是淘宝内部使用的分库分表中间件TDDL(2007年,Java库的形态),早期以DRDS(2012年开始研发,2014年上线,分库分表中间件+mysql Proxy的形态)的品牌在阿里云上提供服务,后来(2019年)正式转型为分布式数据库PolarDB-X(正式成为了PolarDB品牌的一员)。从中间件到分布式数据库,我们在以MySQL为存储构建分布式数据库这条路上走了10余年,这中间积累了大量的技术,也走了一些弯路,未来我们也会坚定的走下去。
PolarDB-X的发展过程主要分成了中间件(DRDS)和数据库(PolarDB-X)两个阶段,这两个阶段存在着巨大的差异。笔者参与PolarDB-X的开发恰好刚满十年,全程经历了整个发展过程。今天就和大家唠一唠PolarDB-X发展与转型过程中的一些有意思的事情。
中间件时代(2012~2019)
DRDS时期的发展思路其实很简单,满足用户的几个主要诉求:
- 阿里云上提供的RDS MySQL单实例最大存储空间有限制(例如早期只有2T)
- Share Storage的数据库可以解决磁盘容量问题,但依然受到单机CPU\\内存的限制,无法解决写扩展性的问题
- 使用开源中间件能解决上述问题,但做扩容等运维操作十分的麻烦复杂
在这样的背景下,我们在中间件TDDL之上增加了一个MySQL Proxy(实际上是Cobar的网络层),部署在了阿里云上,便成为了最早的DRDS。
上云的开始--使用云也服务云
值得一提的是,DRDS上云的方式放到现在看,也是非常时髦的。
像阿里云的普通用户一样,它也拥有一个阿里云的账号(只不过这个账号有上万亿的授信额度),使用这个账号的AK/SK,调用阿里云各个产品的Open API来进行各种操作。

例如,创建实例时,会购买ECS来进行部署DRDS节点;会购买SLB搭在前面来做负载均衡;会购买SLS服务用来存储该实例的SQL审计;会打通DRDS节点到用户RDS的网络等等。
这种形式的管控架构目前被广泛的运用,充分的利用了云的优势。DRDS几乎不需要关注资源问题,也不需要自己维护库存;像机器宕机这种问题,ECS也能自动的进行迁移(连IP都不会发生变化),非常的便利。让DRDS的研发团队可以将更多的精力放在提升产品本身的能力上。
DRDS一方面为阿里云上的用户提供服务,另一方面也作为阿里云的一个“普通用户”,享受着云技术带来的好处,还是非常有趣的。
在DRDS时期,我们在内核侧重点积累了以下技术能力:
SQL语义上与MySQL的兼容性
TDDL仅服务于内部用户,而淘宝的研发规范相对是比较严格的,应用使用的SQL都是比较简单的类型,所以对SQL的处理是非常少的,简单说,它甚至不需要理解SQL的语义,仅做转发即可。但云上用户的需求五花八门,又存在大量迁移上云的存量应用,对SQL兼容性要求变高了很多。这就要求我们要提供一个完整的SQL引擎。
DRDS相对于TDDL以及市面上一众的分库分表中间件,多了两个关键组件:具备完整的算子体系的查询优化器与执行器。它的目标是无论SQL有多复杂,都要能够正确理解其语义,并执行出正确的结果。
这里有非常多需要长期积累的工作。举几个例子:
- 任何一个MySQL支持的内建函数,都有可能是基于一个不能下推的结果进行计算的,这就要求DRDS需要支持所有MySQL的内建函数,并且目标与MySQL的行为一致。我们在DRDS内实现了几乎所有的这些函数(https://github.com/ApsaraDB/galaxysql/tree/main/polardbx-optimizer/src/main/java/com/alibaba/polardbx/optimizer/core/function)。早期我们有两位同学花了数年时间来做这件事情,并且打磨至今。
- MySQL中支持大量的charset与collation,不同的组合会带来不同的排序结果。如果我们要使用归并排序的算子对MySQL层已经局部有序的结果进行归并,则需要确保DRDS使用与MySQL一致的排序行为。实际上这里要求DRDS支持与MySQL行为一致的charset与collation系统,例如我们实现的utf8mb4_general_ci:https://github.com/ApsaraDB/galaxysql/blob/main/polardbx-common/src/main/java/com/alibaba/polardbx/common/collation/Utf8mb4GeneralCiCollationHandler.java。
类似这样的工作还有很多,例如类型系统(PolarDB-X 类型系统概述 - 知乎)、sql_mode、时区系统、默认值等等,繁琐但必要。这些工作都很好的延续到了PolarDB-X中。
极致的下推优化
将计算下推到与数据最近的地方,这是保证性能的一个最朴素的原则。
将MySQL作为一个分布式数据库的存储引擎,它实际上本身也具备很强的计算能力。特别相对于目前很多使用KV来作为存储引擎的分布式数据库,它们大多只能做到Filter、函数的下推执行。但MySQL却支持完整的SQL执行,将分片级的JOIN、子查询、聚合等操作尽可能多的下推到MySQL上,是DRDS保证高性能的一个关键。
下表简单对比业界产品的一些优化选择,信息来自公开文档:
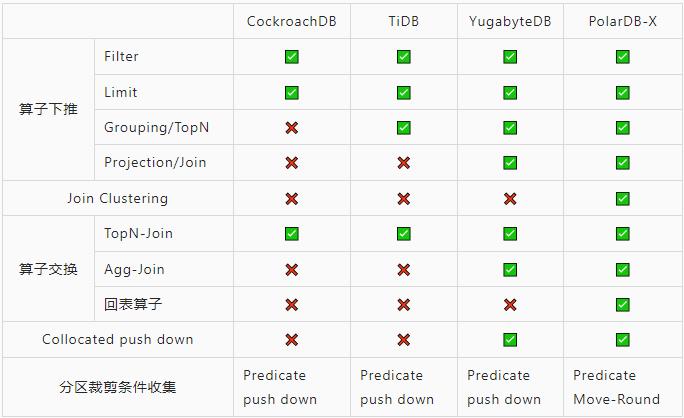
推多了会导致结果错误,推少了会达不到最佳性能。DRDS的优化器积累了大量下推优化策略。这些优化策略大多是没有办法凭空想象出来的,只有通过实际的场景案例,才能得到积累。详见:
PolarDB-X 优化器核心技术 ~ 计算下推 - 知乎。
物理算子的丰富与MPP的执行引擎
物理算子也就是指执行器的各种算法,例如对于Join,我们支持HybridHashJoin、LookupJoin、NestedLoopJoin、SortMergeJoin、MaterializedSemiJoin等等算法。
DRDS最初仅支持单线程去执行SQL,但这种执行对复杂的SQL是不够用的。我们先做了单机并行引擎(SMP),又发展到了现在的MPP引擎,PolarDB-X 并行计算框架 - 知乎。
同时,执行引擎还支持spill out(中间结果落盘的能力),即使只有15M内存,也能跑通TPCH 1G的测试,详见:PolarDB-X 如何用 15M 内存跑 TPC-H 1G? - 知乎。
这些能力的积累与突破,极大的提升了PolarDB-X在面对复杂的SQL的计算能力。
坎坷的分布式事务
分布式事务,是绕不开的一个问题。
对于中间件类型的产品来说,我们有一个很基本的假设:使用标准的MySQL,避免对MySQL做侵入性的修改;即使修改,也应该是插件化的。
不修改MySQL,这导致我们很长一段时间都没有很好的实现分布式事务。
我们前前后后走过的一些弯路:
- 像传统中间件一样,禁止分布式事务。但这个对应用的改造成本太高了。
- 使用柔性事务,很长一段时间我们使用GTS(原名TXC)这样的第三方组件来实现分布式事务。这种方案需要对不同的SQL根据语义来实现回滚语句,SQL兼容性很差。
- 使用GTM的方案。GTM本质是一个单点,并且GTM与Coordinator之间要做大量的数据交互,性能太差,不可能作为一个默认使用的事务策略。所以我们看使用GTM方案的“数据库”,它一定有很严苛的使用条件(例如要求应用尽量避免分布式事务、默认关闭强一致等)。
- XA事务,早期的MySQL对XA支持的很弱,BUG很多(实际上现在的MySQL对于XA的BUG依然很多),例如宕机恢复流程很容易因为XA挂掉。并且XA事务无法解决读的可见性问题,与单机事务的行为不兼容。
事务系统是一个与存储层密切相关的事情,从PolarDB-X的探索来看,不对MySQL做深度修改,是不可能做出性能、功能都符合要求的分布式事务的。这是所有中间件类产品都无法解决的问题,也是中间件与数据库根本性的差异。
绕不开的分区键
从DRDS的第一个用户开始,就一直要回答一个问题,我的表怎么选分区键?
从做“高吞吐”、“高并发”的业务系统角度来看,要求表和SQL带上有业务特征的分区键是非常合理的一件事情。全部下推到存储层,避免产生跨机的查询、事务,做到这些才能保证做到最佳的性能,这是性能的天花板。
问题是,虽然这样做上限很高(高到淘宝双十一0点的业务高峰也可以很丝滑),但:
- 这种改造成本是非常高的,很多时候分区键是很难选的。例如很多电商系统的订单表会有两个查询维度,卖家和买家,选哪个当分区键
- 不是所有的业务系统(或者说不是所有的表和SQL)都值得花这么大的代价去改造的,只有核心系统中的核心逻辑才需要做这种细致的改造
- 拆分键选错了,会导致下限极低。对于数据库来说,提供比较高的上限和提供不太低的下限同样重要。
自然,我们想知道,什么样的技术,才能让你“忘掉”分区键这个东西呢。
数据库时代(2019~)
透明分布式之路
是否需要强制应用在意分区键的概念,是中间件与数据库的关键性区别之一。
分区键与全局索引
广义的“分区键”的概念,其实并不是分布式数据库特有的。
我们在单机数据库中,例如MySQL中,数据存储成了一棵一棵B树。如果一个表只有主键,那它只有一棵B树,例如:
CREATE TABLE t1(id INT,name CHAR(32), addr TEXT, PRIMARY KEY (id))
这个表唯一的B树是按照主键(id)进行排序的。如果我们的查询条件中带了id的等值条件例如where id=14,那么就可以在这棵树上快速的定位到这个id对应的记录在哪里;反之,则要进行全表扫描。

B树用于排序的Key,通过二分查找可以定位到一个叶子节点;分区键通过哈希或者Range上的二分查找,可以定位到一个分片。可以看出它们都是为了能快速的定位到数据。
如果我们要对上面的表做where name='Megan'来查询,在MySQL中,我们并不需要将name设为主键。更加自然的方式是,在name上创建一个二级索引:
CREATE INDEX idx ON t1(name)
每个二级索引在MySQL中都是一棵独立的B Tree,其用于排序的Key就是二级索引的列。也就是说,当前t1这张表,有两颗B Tree了,主键一棵,idx一棵,分别是:
id->name,addrname->id
当使用where name='Megan'进行查询是,会先访问idx这颗B树,根据name='Megan'定位到叶子节点,获取到id的值,再使用id的值到主键那颗B树上,找到完整的记录。

二级索引实际上是通过冗余数据,使用空间与提升写入的成本,换取了查询的性能。
同时,二级索引的维护代价并不是非常的高,一般情况下可以放心的在一个表上创建若干个二级索引。
同理,在分布式数据库中,想让你“忘掉”分区键这个东西,唯一的方法就是使用分布式二级索引,也称为全局索引(Global Index)。并且这个全局索引需要做到高效、廉价、与传统二级索引的兼容度高。
全局二级索引同样也是一种数据冗余。例如,当执行一条SQL:
INSERT INTO t1 (id,name,addr) VALUES (1,"meng","hz");
如果orders表上有seller_id这个全局二级索引,可以简单理解为,我们会分别往主键与seller_id两个全局索引中执行这个insert,一共写入两条记录:
INSERT INTO t1 (id,name,addr) VALUES (1,"meng","hz");INSERT INTO idx (id,name) VALUES (1,"meng");
其中t1主键索引的分区键是id,idx的分区键是name。

同时,由于这两条记录大概率不会在一个DN上,为了保证这两条记录的一致性,我们需要把这两次写入封装到一个分布式事务内(这与单机数据库中,二级索引通过单机事务来写入是类似的)。
当我们所有的DML操作都通过分布式事务来对全局索引进行维护,二级索引和主键索引就能够一直保持一致的状态了。
好像全局索引听起来也很简单?实则不然。
全局索引与分布式事务
索引一定要是强一致的,例如:
- 不能写索引表失败了,但是写主表成功了,导致索引表中缺数据
- 同一时刻去读索引表与主表,看到的记录应该是一样的,不能读到一边已提交,一边未提交的结果
...
这里对索引的一致性要求,实际上就是对分布式事务的要求。
由于全局索引的引入,100%的事务都会是分布式事务,对分布式事务的要求和“强依赖分区键类型的分布式数据库”完全不同了,要求变得更高:
- 至少需要做到SNAPSHOT ISOLATION以上的隔离级别,不然行为和单机MySQL差异会很大,会有非常大的数据一致性风险。目前常见的方案是HLC、TrueTime、TSO、GTM方案,如果某数据库没有使用这些技术,则需要仔细甄别。
- 100%的分布式事务相比TPCC模型10%的分布式事务,对性能的要求更高,HLC、TSO、TrueTime方案都能做到比较大的事务容量,相对而言,GTM由于更重,其上限要远远低于同为单点方案的TSO(TSO虽然是单点,但由于有Grouping的优化,容量可以做的很大)。
- 即使用了TSO/HLC等方案,优化也要到位,例如典型的1PC、Async Commit等优化。不然维护索引增加的响应时间会很难接受。
与单机索引的兼容性
此外,单机数据库中,索引有一些看起来非常自然的行为,也是需要去兼容的。
例如:
- 能通过DDL语句直接创建索引,而不是需要各种各样的周边工具来完成。
- 前缀查询,单机数据库中,索引是可以很好的支持前缀查询的,全局索引应该如何去解这类问题?
- 热点问题(Big Key问题),单机数据库中,如果一个索引选择度不高(例如在性别上创建了索引),除了稍微有些浪费资源外,不会有什么太严重的问题;但是对于分布式数据库,这个选择度低的索引会变成一个热点,导致整个集群的部分热点节点成为整个系统的瓶颈。全局索引需要有相应的方法去解决此类问题。
索引的创建速度,索引回表的性能,索引的功能上的限制,聚簇索引,索引的存储成本等等,其实也都极大的影响了全局索引的使用体验,这里鉴于篇幅原因,就不继续展开了。
索引的数量
对全局索引的这些要求,本质来源于全局索引的数量。
透明性做的好的数据库,所有索引都会是全局索引,其全局索引的数量会非常的多(正如单机数据库中一个表一个库的二级索引数量一样)。数量多了,要求才会变高。
而,这些没有全做好的分布式数据库,即使有全局索引,你会发现它们给出的用法依然会是强依赖分区键的用法。
它们会让创建全局索引这件事,变成一个可选的、特别的事情。这样业务在使用全局索引的时候会变的非常慎重。自然,全局索引的数量会变成的非常有限。
当全局索引的数量与使用场景被严格限制之后,上述做的不好的缺点也就变得没那么重要了。
面向索引选择的查询优化器
我们知道,数据库的优化器核心工作机制在于:
- 枚举可能的执行计划
- 找到这些执行计划中代价最低的
例如一个SQL中涉及三张表,在只考虑左深树的情况下:
- 在没有全局索引的时候,可以简单理解为,执行计划的空间主要体现在这三张表的JOIN的顺序,其空间大小大致为3x2x1=6。执行计划的空间相对是较小的,优化器判断这6个执行计划的代价也会容易很多。(当然优化器还有很多工作,例如分区裁剪等等,这些优化有没有索引都要做,就不多说了)。
- 在有全局索引的时候,情况就复杂多了。假设每个表都有3个全局索引,那执行计划空间的大小大致会变成(3x3)x(2x3)x(1x3)=162,这个复杂度会急剧的上升。相应的,对优化器的要求就会高的多。优化器需要考虑更多的统计信息,才能选择出更优的执行计划;需要做更多的剪枝,才能在更短的时间内完成查询优化。
所以我们可以看到,在没有全局索引的“分布式数据库”或者一些中间件产品中,其优化器是很羸弱的,大多是RBO的,它们根本就不需要一个强大的优化器,更多的优化内容实际上被单机优化器给替代了。
PolarDB-X提供了使用代价模型的优化器:PolarDB-X CBO 优化器技术内幕 - 知乎。
在MySQL上实现强一致、高性能的分布式事务
为了做一个透明的分布式数据库,最关键的就是全局索引以及全局索引依赖的分布式事务了。中间件时代的探索已经告诉我们,要做强一致、高性能的分布式事务,一定要对存储(MySQL)做深度的修改。
我们选择的是使用全局MVCC(TSO)+2PC(XA)的方案。
MySQL的单机MVCC中包含了start_timestamp(也就是MySQL中的trx_id),为了实现全局MVCC,需要做几件核心的事情:
- 提供一个全局的时间戳生成器TSO,PolarDB-X 全局时间戳服务的设计 - 知乎。
- 使用TSO生成的全局时间戳替换掉单机生成的trx_id。
- 引入commit_timestamp(同样由TSO生成),使用strat_timestamp与commit_timestamp来进行可见性的判断,非常的高效。
PolarDB-X 分布式事务的实现(二)InnoDB CTS 扩展 - 知乎。不使用在节点之间交换活跃事物链表或者GTM这种代价非常大的方案。
PolarDB-X中的事务流程:

InnoDB中的记录格式的修改,我们称之为Lizard事务系统,详见:https://developer.aliyun.com/article/795058

我们还有其他一些文章来介绍PolarDB-X分布式事务的实现:
- PolarDB-X 强一致分布式事务原理
(PolarDB-X 强一致分布式事务原理 - 知乎) - PolarDB-X 分布式事务的实现(一)
(PolarDB-X 分布式事务的实现(一) - 知乎)
有了分布式事务与全局索引后,PolarDB-X正式从中间件转型成了一个分布式数据库。
PolarDB-X的透明分布式
PolarDB-X实现了非常优秀的分布式事务与全局索引,满足上文提到了对全局索引的要求,做到了透明分布式。
在透明分布式模式下(CREATE DATABASE中指定mode='auto'),所有的索引都是全局索引,应用无需关心分区键的概念。
例如,我们的建表语句,与单机MySQL完全一致,并不需要指定分区键:
create table orders (id bigint, buyer_id varchar(128) comment '买家', seller_id varchar(128) comment '卖家', primary key(id),index sdx(seller_id),index bdx(buyer_id))

创建全局索引也与单机MySQL创建二级索引的体验一致,全程是Online的:
CREATE INDEX idx_seller_id ON orders (seller_id);
PolarDB-X的全局索引是强一致的,其数据一致性体验与单机MySQL没有明显差异,提供了符合MySQL语义的RC与RR的隔离级别。
同时,PolarDB-X在索引的维护、优化器上也做了大量的工作,确保索引能高效的创建、维护,优化器能正确的生成使用索引的执行计划。
PolarDB-X的分区算法,也能很好的处理索引中产生的热点、数据倾斜等问题,参考:PolarDB-X 数据分布解读(二) :Hash vs Range - 知乎
自动(透明)决定下限,手动决定上限
按透明与手动来划分市面上常见的分布式数据库:
- 透明的分布式数据库的典型代表:TiDB、CockroachDB。
- 手动的分布式数据库典型代表:OceanBase、YugabyteDB。
是否透明的分布式数据一定比手动的要好呢?
对于只提供透明用法的数据库,迁移成本会比较低,初步体验会比较好。但进入深水区后,由于不可避免的会大量的使用分布式事务,在核心场景中,性能往往是达不到要求的(或者同样的性能需要更高的成本),并且缺少消除分布式事务、更充分的计算下推等优化手段。
对于只提供手动用法的数据库,虽然设计良好的分区键使得理论上能够做到性能最优,但使用门槛会大幅增加(10%核心表设计分区键也就算了,剩下的90%非核心表也要设计分区键)。
我们认为,无论是纯透明还是纯手动的分布式数据库,都无法很好的满足业务对是用成本和性能兼顾的要求。
PolarDB-X除了提供了透明模式,也完整的支持了分区表的语法,并提供了Join Group/Table Group、分区在线变更等工具,让应用在需要极致性能的情况下,能将事务、计算更多的下推到存储节点。
PolarDB-X是市面上唯一能够做到同时提供透明与手动两种模式的分布式数据库,我们推荐大多场景使用透明模式,之后对核心业务场景进行压测,并使用分区表语法对这些场景做手动的优化,以达到最高的性能。
使用Paxos协议做到RPO=0
中间件对接的MySQL普遍使用主备架构,这种方式最大的问题就是会丢数据,甚至时间长了是一个必然的事情(常在河边走,哪能不湿鞋呢)。
经过数据库圈子这几年的科普,基本大家都知道了需要使用一些一致性协议,例如Paxos和Raft才能做到不丢数据。这些协议实际上并不是什么秘密了,甚至数据库圈子都有一个段子“现在校招的学生都要能手撸Paxos了”。
门槛并不在协议本身上,而在于如何与MySQL结合后的稳定性与性能。稳定性,只有经过大规模的验证,踩过足够多的坑,才能获得。
PolarDB-X所使用的的Paxos协议是源于阿里内部的X-Paxos,可以这样说,阿里内部的MySQL数据库,已经不存在主备模式了,100%的使用X-Paxos。这代表它经历了上万个MySQL集群以及各种大促的验证,具备极高的可靠性。
我们有几篇文章想写介绍X-Paxos:
- PolarDB-X 一致性共识协议 —— X-Paxos:PolarDB-X 一致性共识协议 —— X-Paxos - 知乎
- PolarDB-X 存储架构之“基于Paxos的最佳生产实践”:PolarDB-X 存储架构之“基于Paxos的最佳生产实践” - 知乎
完全兼容MySQL的Binlog协议
要利用MySQL生态的资源,非常重要的一点是能够使用MySQL生态的工具,将数据流向下游。业内常见的方案里:
- 中间件类产品,需要用户去订阅每个MySQL的Binlog,由用户自行解决这中间的各种运维问题(例如DDL问题,不同的分表名要做合并等),非常的繁琐。
- 分布式数据库类产品,这些大多提供自己的CDC能力,例如OceanBase、TiDB,但他们的格式并非MySQL的Binlog格式,无法直接使用MySQL生态。
PolarDB-X是市面上唯一一个提供完全兼容MySQL Binlog协议的分布式数据库,用户可以使用任何开源的MySQL Binlog订阅、解析工具(例如Canal)来对接PolarDB-X的Binlog。

这极大的提升了PolarDB-X的易用性。详见:
- PolarDB-X 如何兼容 MySQL Binlog 协议和参数,PolarDB-X 如何兼容 MySQL Binlog 协议和参数 - 知乎
- PolarDB-X 全局 Binlog 解读,PolarDB-X 全局 Binlog 解读 - 知乎
下一个五年
我们对未来的PolarDB-X充满想象,希望她能变成一个更好的数据库。虽然有很多的不确定性,不过有一些事情是我们会持续去做的。
最重要的,我们会坚持在MySQL生态上,并且坚持在基于MySQL作为存储节点构建分布式数据库这条技术路线上。我们认为这是我们相对于其他分布式数据库的一个非常关键的差异。与MySQL的兼容其实分为功能兼容与性能兼容,使用分布式KV等技术方案,也许能在功能上兼容MySQL,但是很难做到与MySQL性能上的兼容。MySQL是一个具备全功能的存储,将大量的事务与计算下推到存储节点,是分布式数据库做到高性能的关键。
业内提供全局索引的分布式数据库,全局索引的性能(写入和查询)与单机数据库中索引的性能和行为普遍都有一定的差距,缩小这个差距,便能提升分布式数据库的下限。对于PolarDB-X来说,这个差距主要来自于CN与DN(MySQL)之间的交互链路过长,有很多冗余的操作(MySQL Server层的线程连接模型、MySQL优化器、Parser等)。我们会通过使用RPC协议与MySQL进行交互、做薄MySQL Server层等方式来进一步提升PolarDB-X全局索引的性能。
自动的负载均衡能够极大的降低分布式数据库的使用门槛,PolarDB-X的一些特性(手动与自动兼顾、Join能够下推等),使得这件事情相对于不支持这些特性的数据库有一些额外的难度(一把泪,但我们可以解决),这块还需要一些时间进行打磨。
降本增效是这两年比较火的一个话题,PolarDB-X即将OSS归档的能力,能够自动的将历史数据转储到OSS上,并能通过和在线数据一样的SQL接口进行访问,也支持使用Spark等开源大数据工具对转储的OSS文件直接进行分析等操作。详见:PolarDB-X on OSS: 冷热数据分离存储 - 知乎。
HTAP是分布式数据库领域比较热门的主题,各数据库厂商提出了各种各样的方案。但从现有的HTAP实现来看,性能、隔离性、成本三者处于一种比较矛盾的状态(有些数据库会使用列存副本,性能OK,但很贵;有些数据库在HA使用的备节点来做分析,性能和隔离性就会差一些),离理想中的HTAP差距甚远。我们也会在这个领域做持续性的投入,希望能探索出一种能满足大多数业务场景的HTAP的形态出来。
提供异地多活(全球化等概念)在数据库层面更原生的支持。支持淘宝的异地多活使我们团队在这个领域积累了大量的经验(相信没有人比我们懂的更多)。实际上PolarDB-X是国内少有的落地大型异地多活项目的数据库(其中一个还是民生级的系统),我们希望能把这些经验变成数据库的原生能力,减少异地多活系统对外部组件的依赖,将它变得更为普世。
最后,我们也会坚定的做好开源,保持商业版与开源版在内核层面代码的一致性。同时也会继续发展轻量化的开源管控系统。
感谢大家对PolarDB-X的支持,欢迎关注我们的专栏:PolarDB-X - 知乎
本文为阿里云原创内容,未经允许不得转载。
以上是关于十年磨一剑,云原生分布式数据库PolarDB-X的核心技术演化的主要内容,如果未能解决你的问题,请参考以下文章