Lua实现日志收集业务
Posted 杨 戬
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Lua实现日志收集业务相关的知识,希望对你有一定的参考价值。
文章目录
Lua
Lua 是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放, 其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。
OpenResty®
OpenResty® 是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。
用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。OpenResty 通过lua脚本扩展nginx功能,可提供负载均衡、请求路由、安全认证、服务鉴权、流量控制与日志监控等服务。
OpenResty® 通过汇聚各种设计精良的 Nginx 模块(主要由 OpenResty 团队自主开发),从而将 Nginx 有效地变成一个强大的通用 Web 应用平台。这样,Web 开发人员和系统工程师可以使用 Lua 脚本语言调动 Nginx 支持的各种 C 以及 Lua 模块,快速构造出足以胜任 10K 乃至 1000K 以上单机并发连接的高性能 Web 应用系统。
关于OpenRestry的学习,可以参考中文社区官网:http://openresty.org/cn/
OpenRestry安装
下载OpenRestry:
wget https://openresty.org/download/openresty-1.11.2.5.tar.gz
解压:
tar -xf openresty-1.11.2.5.tar.gz
安装(进入到解压目录进行安装):
cd openresty-1.11.2.5
./configure --prefix=/usr/local/openresty --with-luajit --without-http_redis2_module --with-http_stub_status_module --with-http_v2_module --with-http_gzip_static_module --with-http_sub_module
make
make install
软件会安装到/usr/local/openresty,这里面会包含nginx,如下图所示:
配置环境变量:
vi /etc/profile
export PATH=/usr/local/openresty/nginx/sbin:$PATH
source /etc/profile
Lua日志收集实操
使用Lua实现日志收集,并向Kafka发送访问的详情页信息,此时我们需要安装一个依赖组件lua-restry-kafka。关于lua-restry-kafka的下载和使用,可以参考
https://github.com/doujiang24/lua-resty-kafka
日志收集流程
日志收集流程如下:
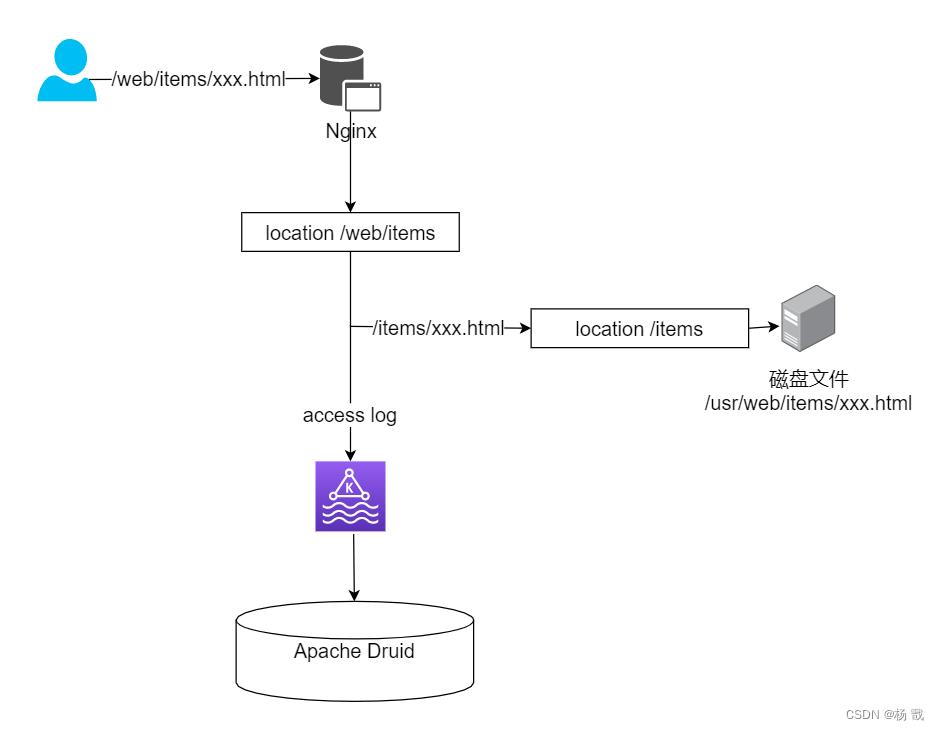
用户请求/web/items/xxx.html,进入到nginx第1个location中,在该location中向Kafka发送请求日志信息,并将请求中的/web去掉,跳转到另一个location中,并查找本地文件,这样既可以完成日志收集,也能完成文件的访问。
实现步骤
插件配置
插件 lua-restry-kafka 地址:https://github.com/doujiang24/lua-resty-kafka
下载包 lua-resty-kafka-master.zip,我们需要将该文件上传到/usr/local/openrestry目录下,并解压,再配置使用,具体步骤如下:
解压:
unzip lua-resty-kafka-master.zip
配置:
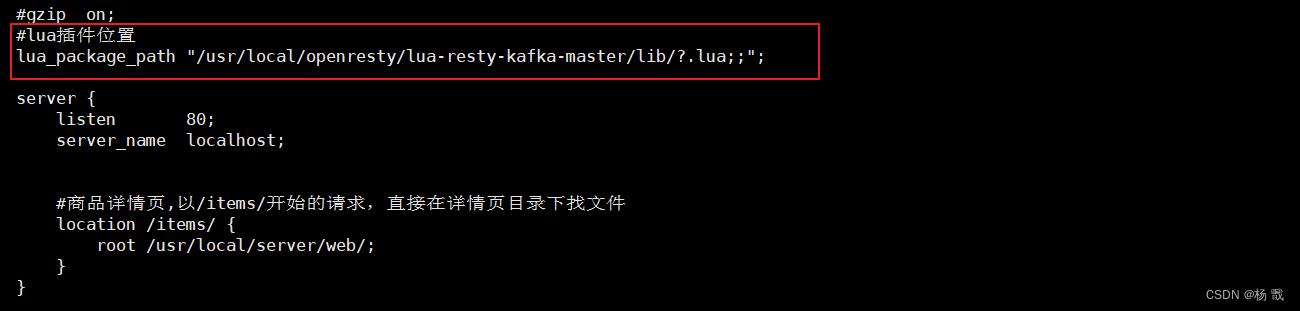
修改nginx.conf,在配置文件中指定lua-resty-kafka的库文件位置:
lua_package_path "/usr/local/openresty/lua-resty-kafka-master/lib/?.lua;;";
配置效果图如下:
日志收集
用户访问一个静态详情页的时候,需要实现日志收集,日志收集采用Lua将当前访问信息发布到Kafka中,因此这里要实现Kafka消息生产者。
我们定义一个消息格式:
"actime": "2020-4-10 9:50:30",
"uri": "http://192.168.211.137/items/S1235433012716498944.html",
"ip": "119.123.33.231",
"token": "Bearer ITHEIMAOOPJAVAITCAST"
生产者脚本:
定义好了消息格式后,创建一个生产者,往Kafka中发送静态详情页的访问信息。我们创建一个lua脚本,access.lua用于访问信息日志的信息收集,脚本内容如下:
--引入json解析库
local cjson = require("cjson")
--kafka依赖库
local client = require "resty.kafka.client"
local producer = require "resty.kafka.producer"
--配置kafka的链接地址
local broker_list =
host = "192.168.211.137", port = 9092
--创建生产者
local pro = producer:new(broker_list, producer_type="async")
--获取IP
local headers=ngx.req.get_headers()
local ip=headers["X-REAL-IP"] or headers["X_FORWARDED_FOR"] or ngx.var.remote_addr or "0.0.0.0"
--定义消息内容
local logjson =
logjson["uri"]=ngx.var.uri
logjson["ip"]=ip
logjson["token"]="Bearer ITHEIMA"
logjson["actime"]=os.date("%Y-%m-%d %H:%m:%S")
--发送消息
local offset, err = pro:send("itemaccess", nil, cjson.encode(logjson))
--页面跳转
local uri = ngx.var.uri
uri = string.gsub(uri,"/web","")
ngx.exec(uri)
nginx配置
按照上面的流程图,我们需要配置nginx的2个location,修改nginx.conf,代码如下:
server
listen 80;
server_name localhost;
#/web开始的请求,做日志记录,然后跳转到下面的location
location /web/items/
content_by_lua_file /usr/local/openresty/nginx/lua/items-access.lua;
#商品详情页,以/items/开始的请求,直接在详情页目录下找文件
location /items/
#日志处理
#content_by_lua_file /usr/local/openresty/nginx/lua/items-access.lua;
root /usr/local/server/web/;
日志收集测试
请求地址:http://192.168.211.106/web/items/static01.html
查看Kafka的itemaccess队列数据:

以上是关于Lua实现日志收集业务的主要内容,如果未能解决你的问题,请参考以下文章