两万字长文,史上最全 C++ 年度总结!
Posted CSDN 程序人生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了两万字长文,史上最全 C++ 年度总结!相关的知识,希望对你有一定的参考价值。

【编者按】C++ 四十年,历久弥新长盛不衰。几日前 CSDN 组织了一次 C++ 直播对话,在非常短的时间内就吸引了两万多开发者观看,足以说明 C++ 在开发者中的影响力。本文的四位作者联合撰文,写下了这篇两万字的长文,深度总结了 C++ 的新进展,以及未来的演进方向,值得所有开发者收藏。
作者 | 祁宇 许传奇 袁秩昊 卜恪
责编 | 唐小引
出品 | 《新程序员》编辑部
不平凡的 2022 年已经过去了,受到疫情影响,C++ 标准委员会(以下简称委员会)只能在线上 Review 提案,效率较低,但在新标准的制定上仍然取得了一些进展。同时,C++20 的 Modules 和 Coroutine 也有一些新的突破,本文将集中介绍 C++ 最新的进展以及大家极为关注的点,譬如:
过去的一年 C++ 社区也有一些大新闻,比如 Google 推出的编程语言 Carbon 号称下一个 C++,它又会对 C++造成什么影响呢?
C++20 发布已经快两年了,相应的 C++20 库有没有跟上呢?过去这一年里 C++ 社区有哪些值得推荐的 C++20 库呢?我们也会重点推荐一些 C++20 基础库,可以帮助用户快速构建高性能 C++ 应用。
我们已经进入了 2023 年,C++23 会在今年发布,它又有哪些值得关注的新特性呢?本文也将介绍 C++23 相关的特性。
C++ 未来比较重要特性(如 executors)现在又是什么状态?相信这也是大家比较关心的,在本篇 C++ 的年度总结中,我们都将为你细细道来。

2022 年度 C++ 标准关键新进展
在 2022 年 2 月,C++23 就进入了 feature freeze(功能冻结期),即在这之后 C++23 将不会接受除了 Defect Resolution 之外的任何更改。委员会的精力将主要集中在现有的 Bug Fix 以及 C++26 中。在 2022 年 11 月,委员会也开启自全球大疫情以来的第一次线下集会。在过去的三年,因为疫情的原因,委员会放弃了往常线下聚会为主的工作方式,改为以线上工作为主。根据大家的反馈以及最后没能达成 C++23 的规划来看,疫情还是对委员会的工作效率造成了不小的影响。而 11 月重启的线下聚会或许也能表明委员会的工作将会重新走入正轨。本节将会提及一些过去一年中在标准方面相对比较重大或较为有意思的改动。由于笔者能力与兴趣原因,可能会有遗漏,望大家见谅。
(1)C++23 的探险者
三年前我们在给 C++23 圈定目标时,谁也不知道这个新版本到底要以何种方式应对未来世界的挑战。但现在,事情已经很清楚了:C++23 要从其他编程语言社区抢人。
import std;
int main()
std::println("hello, world");
用到的新特性:
标准库模块 std 和 std.compat
std::print 和 std::println,整合 std::format 到标准输出
语言核心的现代化
如果说 C++11 看起来像一个新语言,C++23 看起来就像是某个你很熟悉的编程语言。是的,我们连 Hello World 都改了,学校里教 C++ 的书都得重写了。
struct Path
auto exists(this Path& self) -> bool;
auto rename(this Path& self, string_view target) -> void;
auto mkdir(this Path& self, mode_t mode = 0777) -> void;
;如果你熟悉 Rust,它看起来就像是 Rust;如果你习惯加了 type hints 的 Python,它看起来就像 Python。这里的 this 仅仅是堆在 self 参数前一个关键字;self 不过是笔者自顾自取的一个参数名。这下 self.mode 和 mode 不会搞混了,至少在构造函数和虚函数之外的地方是如此。
用到的新特性:
显式对象参数和显式对象成员函数
但光看着像是不够的。C++ 这个名字就意味着,凡事都要做到更好,不单是和 C 相比。
标准库与其他部分的协作
谈谈我最近写 Python 遇到的事情,我看到一个 review 里有很多这样的语句:
print(list(mapping.keys()))如果 mapping == 'nice': 1, 'boat': 2,这个 print 就会打印 ['nice', 'boat']。
但为什么 print(mapping.keys()) 不行?试了一下,结果打印出:
dict_keys(['nice', 'boat'])好吧,虽然不是自己想要的,但也不算太糟。要说太糟的话,这个就有点太糟了:
>>> print(iter(mapping))
<dict_keyiterator object at 0x6ffffe9683b0>除非是你自定义的生成器类型,否则都打印不出有意义的东西。
>>> def fib(n: int) -> int:
... a, b = 0, 1
... for _ in range(n):
... yield a
... a, b = b, a + b
>>> print(f'fib: fib(5)')
fib: <generator object fib at 0x6ffffeeb19e0>但是 C++ 的话则灵活了许多:
std::println("", mapping | views::keys);打印:
["nice", "boat"]生成器:
auto fib(int n) -> std::generator<int>
auto [a, b] = std::tuple(0, 1);
for (auto _ : views::iota(0, n))
co_yield a;
std::tie(a, b) = std::tuple(b, a + b);
/* ... */
std::println("fib: ", fib(5));打印:
fib: [0, 1, 1, 2, 3]不管是容器、view、生成器,还是 tuple 一类的异质容器,不论来自标准库还是第三方,都不需要为看到一点合理的输出从头实现一整个算法。
用到的新特性:
标准库生成器 std::generator
std::format 支持 ranges
不足之处
黑了这么久 Python,还是得承认 Python 和 Rust 这样这样的语言,在让用户上手方面是积累了很多经验的。比如在程序遇到意料之外的错误时,runtime 能打印栈回溯。如果你在 Rust 中把一个字符串解析为 32 位整数:
let v = arg1.parse::<i32>().unwrap();若解析失败,程序运行时就可能看到这样的东西:
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: ParseIntError kind: InvalidDigit ', src/main.rs:5:37
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace设置环境变量 RUST_BACKTRACE=1 重新跑,没有调试器也能看到不少诊断信息:
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: ParseIntError kind: InvalidDigit ', src/main.rs:5:37
stack backtrace:
0: rust_begin_unwind
at /rustc/90743e7298aca107ddaa0c202a4d3604e29bfeb6/library/std/src/panicking.rs:575:5
1: core::panicking::panic_fmt
at /rustc/90743e7298aca107ddaa0c202a4d3604e29bfeb6/library/core/src/panicking.rs:65:14
2: core::result::unwrap_failed
at /rustc/90743e7298aca107ddaa0c202a4d3604e29bfeb6/library/core/src/result.rs:1791:5
3: core::result::Result<T,E>::unwrap
at /rustc/90743e7298aca107ddaa0c202a4d3604e29bfeb6/library/core/src/result.rs:1113:23
4: playground::main
at ./src/main.rs:5:17
5: core::ops::function::FnOnce::call_once
at /rustc/90743e7298aca107ddaa0c202a4d3604e29bfeb6/library/core/src/ops/function.rs:251:5
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.我们可以在 C++ 里写一个几乎等价的 parse 函数:
template<std::integral T>
auto parse(std::string_view from) -> std::expected<T, std::errc>
T to;
auto ed = std::to_address(from.end());
if (auto [ptr, ec] = std::from_chars(from.data(), ed, to);
ec != std::errc())
return std::unexpectedec;
else if (ptr != ed)
return std::unexpectedstd::errc::invalid_argument;
else
return to;
然后试一试:
auto v = parse<int>(arg1).value();但你只会看到:
terminate called after throwing an instance of 'std::bad_expected_access<std::errc>'
what(): bad access to std::expected without expected value和 Rust 程序没开 RUST_BACKTRACE=1 时差不多,甚至没有行号。
C++23 做了一些努力。你可以直接打印当前的栈回溯:
std::println(stderr, "", std::stacktrace::current());但当前的栈 != 异常抛出时的栈;我期待 C++26 给出一个开箱即用的解决方案。
用到的新特性:
std::stacktrace 标准库类型
std::expected,类似 Rust 的 Result<T, E>
关于 C++23,以上提到的许多特性,文章只展示了浮光掠影的一小部分,它们对 C++ 特殊的意义远远超出「制造一点熟悉感」;让一个语言的新版本中或大或小的特性保持正交、挖掘协同作用,是一项大工程。期待你能在 C++23 对 C++ 的应用产生深远影响之时从中获益。
(2)Executors
Executors 算得上 C++ 标准提案中的明星提案了。它能获得如此高的期望度的原因之一可能是包括网络库、协程库在内的提案都需要依赖 Executors 提案。另一方面可能也说明大家对于一个统一的调度器接口的期望。在过去的三年内,由于提案过大、疫情导致只能线上 Review 等诸多缘由,Executors 提案的进度并不算快。在 2021 年 12 月至 2022 年 2 月,Executors 提案的作者们以时间不足、Executor 十分重大为由,发起了罕见的冲锋式 Review。然而委员会还是以提案过大、无法完成 Review 的理由拒绝了该提案进入 C++23,将其放入了 C++26 的周期内。
虽然这一结果后续导致了不少微词,笔者依然觉得委员会的决定是理智和冷静的。一方面在过去包括 Modules、Concepts、Reflections 在内的诸多提案都被反复延迟过,感觉不到 Executors 需要特事特办的理由。另一方面,个人认为,“慢” 与其说是 C++ 特性发展的 Defect(缺点),不如说是 C++ 特性发展的 Feature(特征)。毕竟对于程序语言来说,“乱” 是比 “慢” 可怕得多的事。更何况今年来 C++ 标准的发展速度其实已经非常快了。
(3)SIMD
跳出 C++ 标准本身,异步化和并行化是当今 C++ 世界的两大浪潮。对于 C++ 程序员来说,当你想显著地提高程序性能时,从异步化和并行化这两个方面开始思考是比较稳妥的方式。对于异步化而言,上面提到的 Executors 和下面提到的 Coroutines 都可算是相关的话题。对于并行化而言,无论是 GPU 加速、CPU SVE、编译器向量化优化亦或者是各种并行编程库(例如 Open_MP)都与并行化有关。
再让我们回到 C++ 标准本身,与并行化相关的概念则在 Parallelism TS 当中。而 Parallelism TS 中的 SIMD 库则是距离我们最近的一部分。目前 SIMD 库已经脱离了 Parallelism TS ,之后的所有改动都将直接在 LEWG 中讨论。
SIMD 库的意义在于将各种之前需要手写 SIMD instrinsic 的操作封装成跨平台的标准化街口。一方面调用函数接口肯定比手写 SIMD 指令要友好的多,而且库实现大概率会比手写的效率高。另一方面 SIMD 库的封装对于编译器向量化也会有好处。最后,SIMD 库的出现对于目前国内存在体系结构迁移需求的开发者们来说,会是一个非常大的福音。不然任何之前通过手写 SIMD 指令以获取性能提升的项目都会付出当初难以预料的成本。希望 SIMD 库可以如期进入 C++26。
(4)Concurrency v2 TS
2022 年 2 月发布的 TS:
https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2021/n4895.pdf
在 2022 年 11 月的会议中,Concurrency v2 TS 的两个比较重要的变动是:RCU(Read-copy-update)以及 std::hazard_pointers 将会脱离 Concurrency v2 TS,作为独立的 feature targeting C++26。RCU本身是 Linux 内核中的一种同步技术,支持并发地执行一个 Updater 以及多个 Reader 而不需要上锁,是一种很高效的同步机制。
而 hazard pointer 则是一种只允许单个写线程持有,多个读线程共享的指针,是 lock-free 编程中的重要数据结构。RCU 和 hazard pointer 都是在实践中被长期验证过的高效、经典的同步数据结构,如果能成功被加入标准的话,想必对于 C++ 的用户们来说会带来不少用处。哪怕我们在日常开发中不会用到这种高级的同步数据结构,我们在引用的库中应该也能得到 RCU 和 hazard pointer 标准化的好处。
除了 RCU 和 std::hazard_pointer 之外,Concurrency TS 中还将包含 synchronized_value<T>,byte-wise atomic memcpy 以及 asymetric fence 等等组件。总体来说,值得期待。
(5)Library Fundamentals v3 TS
2022 年 7 月通过的基础库扩展 v3:
https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2022/n4908.html
Library Fundamentals v2 TS,即 Library Fundamntals TS 的上一次发布,还是在 2017 年。而 Library Fundamentals v3 TS 相比较于 Library Fundamentals v2 TS 相比,只增加了一个新 feature:(scope guard)。同时 Library Fundamentals v3 TS 还保留着以下 Library Fundamentals v2 TS 中的组件:
detection idiom
propagate_const
observer_ptr
ostream joiner
sample
shuffle
randint
reseed
委员会认为 Library Fundamentals TS 的发展效率总体比较低,同时在委员会的讨论中,Library Fundamentals TS 组件的优先级也低于直接单独发的库提案。最后在 2022 年 11 月的会议中,委员会宣布 Library Fundamentals v3 TS 将会是最后的 Library Fundamentals TS,这表示 Library Fundamentals TS 将不会再有任何发展。之后,如果 Library Fundamentals TS 中的某些组件比较引人感兴趣的话,就应该直接作为单独的提案提出了。
(6)Transactional Memory TS
2022 年 11 月发布的 Transaction Memory v2 TS:
https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2022/n4923.pdf
Transactional Memory 是计算机科学中的重要概念。在有了并发编程之后,Transactional Memory 将会容易很多。但如果没有 hardware 支持的 transcational memory,依靠软件模拟的 Transactional Memory 的开销很大而显得使用 Transactional Memory 的好处并不明显,不太有意思。
而随着支持 Transactional Memory 的商用级处理器日渐出现之后(例如 Arm 的 Hardware Transactional Memory Extension 以及 Intel 的 Transactional Synchronization Extensions ),Transactional Memory 的分量与前景也在肉眼可见的加重。C++委员会也及时地加快了对 Transactional Memory 标准化的设计。
在对 Transactional Memory 具体的设计上,C++ 委员会的选择出人意料地非常简洁和克制。基本只引入了一个语法:atomic do 。
unsigned int f()
static unsigned int i = 0;
atomic do
++i;
return i;
不需要任何解释,读者看到这段代码后的理解与实际的语义基本差不了多少。而且和其他 C++ 近年新引入的语法相比,背后并没有那么多的弯弯绕绕。在笔者所知的近年来所有新 C++ feature 当中,Transactional Memory 的设计是最简洁的,对标准文本的影响也是最小的。而在具体的语义上,委员会的设计也给实现者留下了非常巨大的空间。唯一美中不足的是,目前还看不到任何实现和实现的迹象,可能只能等硬件公司的开发者们将此事提上日程。
(7)C++ Ecosystem International Standard
C++ 标准委员会的核心产出是一份说明 C++ 核心语言与 C++ 标准库定义的文档。除此之外的事情,原则上都不归委员会管了。虽然 C++ 程序员们谈起 C++ 标准时往往会带着敬畏的态度,但 C++ 今日的成功决不只取决于 C++ 语言本身,更取决于 C++ 的生态。
例如,对于绝大多数 C++ 程序员来说,他们阅读标准的时间应该是远小于他们与编译器、链接器、构建系统、包管理器、调试器、静态分析工具与动态分析工具等等工具打交道的时间的。这里我们暂且将 C++ 生态的概念限制为 C++ 工具的生态。然而与有着统一标准 C++ 语言规范不同,C++ 工具间的交互能力(interoperability)的规范只能说是经验主义、约定俗成的。这对于现有 C++ 工具的维护者来说是个不小的负担。而对于新 C++ 工具的开发者而言,更是要花上大量的时间去关注非规范的 C++ 工具生态,这给新 C++ 工具的开发带来了非常重的、额外的、其实本不必要的负担。
这个问题在 C++ 引入 Modules 后变得更严峻了,因为 Modules 会给现有的几乎所有 C++ 工具带来全新的挑战。为了解决以上提到的这些问题,委员会提出有必要制订 C++ Ecosystem International Standard[1]来为 C++ 生态制订明确的规范。
虽然目前距离第一版规范的面世还遥遥无期,或者说 C++ Ecosystem International Standard 应该包含那些部分都还没有完全确定下来。但我们相信,这一定是 C++ 发展历史上极为重要的一步。

Modules
Header files are a major source of complexity, errors caused by dependencies, and slow compilation. Modules address all three problems.
头文件是复杂性、依赖错误、编译太慢的主要根源,而 Modules 则能够解决了这三个问题。
—— Bjarne Stroustrup,C++ 之父
Modules 被很多人认为是 C++20 中最重要的特性,同时也是对 C++未来影响最大的特性。原因之一可能是因为只能使用文本替换以引入依赖的 C++ 看起来确实很不 Modern。在笔者所知的所有主流高级语言中,除了 C++ 之外,唯一还使用 Modules 的语言是 C 语言,就连 Fortran 也都早就用上了 Modules。
但与之相对应的,Modules 也是 C++20 四大特性(Modules、Coroutines、Concepts 和 Ranges)中被各个编译器支持地最慢、最不完善的一个特性。我们在本节中会先对 Modules 语法做一个简单的介绍、之后会介绍 Modules 在编译器、构建系统及其他工具中的支持情况,再对 Modules 的未来做一个展望。
(1)语法简介
Modules 可简单分类为 Named Modules 和 Header Units。对文字比较敏感的朋友看到这句话肯定会觉得很难受。为什么 Units 和 Modules 是并列的呢?这里指的其实是 import 关键字后可接的内容。import后可接 module-name(及 partition-name)和 header-name。
严格来说,Modules 可分为 Named Modules 和 Unnamed Modules(也叫 Global Modules)。Named Modules 是由 module-unit 声明的。module-unit 是一类特殊的 translation-unit。而 header-unit 则是在 import header-name; 时合成(Synthesized)的一种特殊 translation-unit,同时 header-unit 中的声明均视为位于 Global Module 中。这样一来,大家也就能理解为什么 Modules 会被分类为 Named Modules 和 Header Units 了。
接下来我们会简单介绍下 Modules 的语法,但不会引入所有细节,只是希望大家通过这一小节能对 Modules 有个直观的感受。大家感兴趣的话可以再找更进阶的材料学习。
Header Units
Header Units 的语法为:
import header-name;
header-name:
< h-char-sequence >
" q-char-sequence "
h-char-sequence:
h-char
h-char-sequence h-char
h-char:
any member of the translation character set except new-line and U+003E GREATER-THAN SIGN例如:
import <iostream>;
import "importable-header";看上去很简单,似乎只需要把 #include 换成 import 再加个分号就好了。但事实远没这么简单。观察例子的第二行,这里写的是 import "importable-header"; 即 Header Units 只能 import 所谓的 importable-header。但什么是 importable-header 呢?C++ 标准的说法是 implementation-defined。只有标准库中的头文件需要是 importable-header。这给包括工具链开发者在内的广泛用户带来了非常深的困扰。意味着我们无法确定任何使用了 Header Units 的代码是否是符合标准的、跨编译器与跨平台兼容的。
Header Units 的问题还不止于此,来看下面这个例子:
// a.cpp
// Compile flags: -std=c++20 -DFOO
import "foo.h";
...
// b.cpp
// Compile flags: -std=c++20
import "foo.h";这个例子中有两个源文件 a.cpp 和 b.cpp,它们都 import 了 foo.h,但它们的编译选项是不一致的。此时将 a.cpp 和 b.cpp 中的 import "foo.h"; 编译为同一个 header unit 明显是不合适的。但如果将 a.cpp 和 b.cpp 中的 import "foo.h"; 编译为两个不同的 header unit,那么一方面编译速度不但不会更快还会更慢,因为我们需要付出额外的序列化和反序列化的时间。另一方面这个做法也与我们的原则:“在一个项目中,一个 module 只编译一次”相违背,还会增加 One-Definition-Rule Violation 的可能性。除此之外,header units 还有不少其他的问题,这里不再展开。
直到 2022 年 11 月的会议上,委员会的工具链小组依然花了很多时间讨论编译器与构建系统该如何合作来让 Header Units 可用。而这个问题直到今天也没有达成共识。
Named Modules
我们可以 module-unit 中声明 Named Modules。module-unit 是包含 module declaration 的 translation unit。module-unit 的语法为:
module-unit:
module-declaration declaration-seq
global-module-fragment module-declaration declaration-seq这个语法的含义是,module-unit 要么由 module-declaration 开头,要么由 global-module-fragment 开头后接 module-declaration。这里的 declaration-seq 表示后续的各种声明。
global-module-fragment 的语法为:
global-module-fragment:
module preprocessing-directives这里的 preprocessing-directives 指 #include、#define 等各种 # 开头的 directives 以及 import、export 等语句(觉得奇怪的话,可以暂且忘掉)。
module-declaration 的语法为:
[export] module module_name[:partition_name];根据 module-declaration 的不同,可将该 module unit 分为:
Primary Module Interface Unit
Module Implementation Unit
Module Interface Partition Unit
Internal Module Partition Unit
让我们用一个例子来理解下这些概念:
// M.cppm
export module M;
export import :interface_part;
import :impl_part;
export void Hello();
// interface_part.cppm
export module M:interface_part;
export void World();
// impl_part.cppm
module;
#include <iostream>
#include <string>
module M:impl_part;
import :interface_part;
std::string W = "World.";
void World()
std::cout << W << std::endl;
// Impl.cpp
module;
#include <iostream>
module M;
void Hello()
std::cout << "Hello ";
// User.cpp
import M;
int main()
Hello();
World();
return 0;
在例子中的 M.cppm 是一个 Primary Module Interface Unit。Primary Module Interface Unit 将声明一个 Module,一个 Module 中只可包含一个 Primary Module Interface Unit。例子中的 interface_part.cppm 和 impl_part.cppm 分别是 Module Interface Partition Unit 和 Internal Module Partition Unit(它们之间的区别比较复杂,大家可以暂且不用在意)。
总之,Module Partition Unit 将会声明一个 Module 的一个 Partition。一个 Module 中的 Partition 需要是唯一的。Module 外的用户无法直接 import Module Partition。例子中的 Impl.cpp 是一个 Module Implementation Unit。一个 Module 可以有多个 Module Implementation Unit。Module Implementation Unit 会隐式的 import 对应的 primary module。Module Implementation Unit 可用于定义各种 Module Interface Unit 中声明的实现。在例子中的 interface_part.cppm 和 impl_part.cppm 包含了 Global module fragment 用以依赖所需的头文件。这也正是 Global module fragment 的设计用途,用以后向兼容各种所需的头文件。在 M.cppm 和 interface_part.cppm 中,函数 Hello() 与函数 World() 前有关键字 export,表面这两个声明是可被 Module 的用户使用的。
虽然本节看上去有些长,但稍微总结下 Module 的定义即先写个 module; 引入 Global Module Fragment,之后引入所需的头文件,再使用 export module module-name; 声明 Module 的名字。之后在需要对外可见的声明前加上 export 关键字就好了。如果当前文件写得太长了,还可以另起一个文件声明下 Partition 就好,export module module-name:partition-name 也可以将具体实现放到 Module Implementation Unit 当中。至于 Module 的使用就更简单了,需要什么 Module,直接 import 进来即可。
虽然读者们可能也能感觉到还会有各式各样的细节,但起码看上去 Modules 确实不难对吧?
(2)Modules 的好处
封装性
我们以 asio 库中的 asio::string_view 为例进行说明。以下是 asio::string_view 的实现:
namespace asio
#if defined(ASIO_HAS_STD_STRING_VIEW)
using std::basic_string_view;
using std::string_view;
#elif defined(ASIO_HAS_STD_EXPERIMENTAL_STRING_VIEW)
using std::experimental::basic_string_view;
using std::experimental::string_view;
#endif // defined(ASIO_HAS_STD_EXPERIMENTAL_STRING_VIEW)
// namespace asio
# define ASIO_STRING_VIEW_PARAM asio::string_view
#else // defined(ASIO_HAS_STRING_VIEW)
# define ASIO_STRING_VIEW_PARAM const std::string&
#endif // defined(ASIO_HAS_STRING_VIEW)该文件的位置是 /asio/detail/string_view.hpp,位于 detail 目录下。同时我们从 asio 的官方文档[2]中也找不到 string_view 的痕迹。所以基本可以判断 asio::string_view 这个组件在 asio 中是不对外提供的,只在库内部使用,作为在 C++ 标准不够高时的备选。然而使用者们确可能将 asio::string_view 作为一个组件单独使用 Examples[3],这违背了库作者的设计意图。从长远来看,类似的问题可能会导致库用户代码不稳定。因为库作者很可能不会对没有暴露的功能做兼容性保证。
这个问题的本质是头文件的机制根本无法保证封装。用户想拿什么就拿什么。
而 Modules 的机制可以保障用户无法使用我们不让他们使用的东西,极强地增强了封装性:

隔离性
这指的是 import module; 不会受到上下文所影响。例如每一个人都能看出下面代码的问题:
#define true false
#include "header.h"header.h 中的实现将严重受到影响。当然这个例子可能过于极端了,真实世界也不会有人这么写代码。但可以看一个更真实的案例:
#include "headerA.h"
#include "headerB.h"
// 以及
#include "headerB.h"
#include "headerA.h"这个例子说的是由于 #include 头文件顺序不同导致的行为差异。没踩过这个坑的 C++ 程序员想必不多。
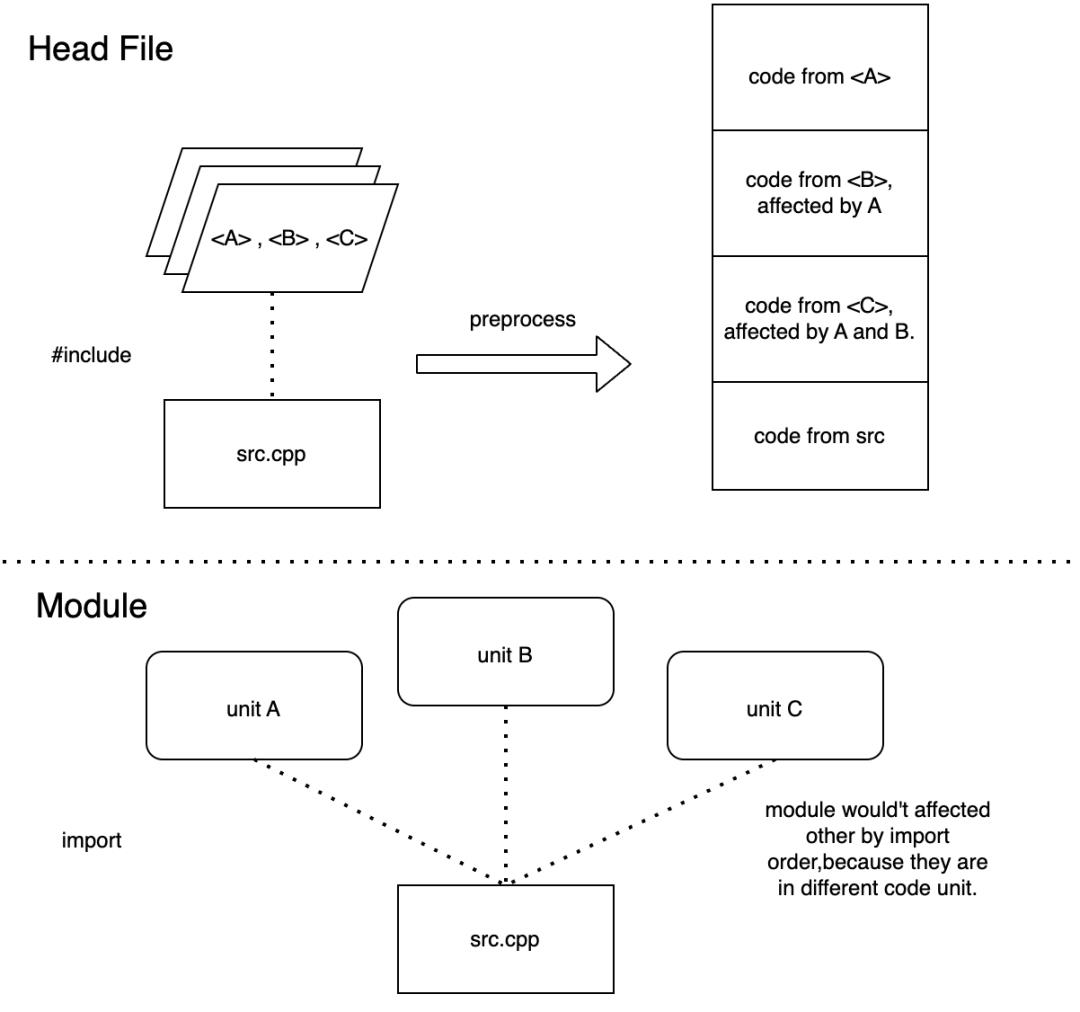
而在使用 Modules 之后,不会再受到外界定义的宏的影响,同时 import modules; 的顺序也不会改变程序的行为。
更强的一致性检查
One Definition Rule(ODR)是 C++ 的重要规则。ODR 可以简单理解为在一个程序中一个 Entity 只应该拥有一个定义。违反 ODR 可能给 C++ 程序带来很严重同时很难查的 bug。但在之前的编译模型当中,每个 TU 都是单独编译的,互不干扰。这使得编译器只能在当前 TU 中检查 ODR,对于跨 TU 的 ODR Violation,之前的编译器是无能为力的。
之前的实践方式都是将跨 TU 的 ODR violation 检查交给链接器来做。但由于从高级语言到链接器之间已经损失了非常多的信息,链接器能检查到的 ODR violation 是有限的。而在 Modules 进入 C++ 之后,我们就拥有了在编译器前端进行跨 TU 检查 ODR violation 的能力,这是一个很大的进步。
编译加速
Modules 很吸引 C++ 程序员的一个特性即是 Modules 的编译加速能力。从定性的角度分析 Modules 编译加速能力时,我比较喜欢用这个例子来解释:如果一个项目中存在 N 个头文件与 M 个源文件,每个源文件都 include 了每个头文件,那么这个项目的编译时间复杂度可以表示为 O(N*M)。

而如果将项目以一个头文件对应一个 Module Unit 的方式重构之后的话,因为每个 Module Unit 中的代码不会被重复编译,我们可以将整个项目的编译时间复杂度表示为 O(N+M)。从 O(N*M) 到 O(N+M) 的改进是非常巨大的。
当然这个模型显然是太过于粗糙了,有很多的因素都没有考虑,例如模版、inline 函数、编译器优化等等,但我们应该还是能看出 Modules 在 C++ 项目编译加速方面的潜力。
能预计到很多读者会好奇使用 Modules 到底具体地能给我们的项目带来多大的编译加速比?大概是一个什么样的数字?这样直观的数据当然是非常吸引人的。然而在当下的环境中,直接给出一个 Modules 编译加速能力的数字是不负责任的和误导人的。一方面每个项目的代码结构和组织方式都天差地别,另一方面编译器中相关的实现无论宏观架构或者细节部分可能都有较大的调整空间,再者目前对于 Modules 使用的实践的方式不够多、规模也不够大。在这样的情况下,具体数字的价值就很小了。
这段话本身想对读者表达的是大家目前不应该被 Modules 具体的加速比数字所迷惑了。当前在网上能搜到的数据中,从百分之几到几十倍都有。在笔者所做的实验中,根据配置与代码的不同,从百分之十几到几倍的数据都有。大家如果好奇自己的项目在 Modules 中能得到多大的加速比的话,最好的办法还是自己上手试一下。
(3)std modules
std modules 是 C++23 的一个重要特性。在由于疫情导致产出下降的 C++23 中,std modules 可能是其中最亮眼的特性了。std modules 允许用户直接 import std; 而导入标准库中的所有声明(宏除外)。例如:
import std;
int main()
std::cout << "Hello World.\\n";
对于用户来说,这个语法并没有太多需要值得关心的地方。如果你在 import std; 后出了任何问题,那大概率都会是工具链的问题而不会是你的问题。当然了,工具链什么时候 ready 就是另一个问题了。目前 MSVC 已经推出了需要用户自行安装的 std.ixx[4];libc++ 正在做非常初期的探索;暂时没有听到 libstdc++ 相关的传闻。
有人可能还有疑问,之后的新特性都会不会只加到 std module 中而不会加到标准库头文件中?或者说标准库头文件在未来是否会被逐渐 deprecate?无论从 Modules 在工具链方面的实际进度还是从向后兼容性这两个角度来看,目前都没有这个征兆。
(4)目前编译器支持状态
总体来说 MSVC 对 Modules 的支持状态是最领先的,其次是 Clang 和 GCC。笔者对于 Modules 在 Clang 中的状态相对比较熟悉些,这里就描述下 Modules 在 Clang 中的状态吧。
Modules 技术在某种程度上可以理解为对 C++ 代码的序列化和反序列化。目前 Clang 和 GCC 的做法都是对 C++ 代码对应的 AST 进行序列化和反序列化。在 Clang 中相关的技术最早可以追述到 Clang 开发时用于帮助 Debugging 的技术。之后 PCH(Precompiled Header)技术也复用了这个技术。然后 Apple 开发了 Objective-C++ Modules。后续 Apple 和 Google 在这之上开发了 Clang C++ Modules 技术。
Clang C++ Modules 是 Clang 的一个 C++ 扩展,可以将 Header 隐式地转换为 Modules,所以也叫 Clang Header Modules 以及 Clang Implicit Modules。后来当 Modules 确认进入 C++ 标准后,Google 在 Clang 中做了 Standard C++ Modules 初步的支持。不过之后因为各种原因,Google 在 C++ 标准方面的投入放缓,Clang 中 Standard C++ Modules 的支持也陷入了停滞。
从 2021 年下半年开始,笔者和 GCC 的 maintainers 对 Clang 中 Standard C++ Modules 进行了完善。在 2022 年 9 月,Clang15 发布,这也是首个号称支持 Standard C++ Modules 的 Clang 版本。在 Clang15 中,对 Modules 主要的语法都进行了支持。在预计于 2023 年 3 月发布的 Clang16 中,也将会包含更多 Modules 相关的 bug 修复。
虽然号称对 Standard C++ Modules 的语法进行了较为完整的支持,但我们还是得承认目前 Modules 的支持中存在较多的缺陷以及 Bug。这与 Modules 庞大的规模以及编译器社区对于语言新特性的工作方式是有关系的。
首先是编译器社区对新特性支持的工作方式,一般流程是:开发者们看着提案实现特性 -> Reviewer 们觉得没问题之后就合入 -> 宣布该特性已得到支持(注意:此时该特性一般并未得到广泛用户大规模的使用)-> 新版本发布 -> 如有 Bug Report 则根据 Bug Report 进行修复和迭代。
这里的关键点是一个特性是否得到支持的宣称是由开发者和 Reviewer 们经过 Review 和相对有限的测试决定的。以往对于很多规模较小的特性而言,靠着开发者们的经验,一般大家都觉得没问题的话那问题确实也不大。
但对于 Modules 这种规模的特性而言,就必然需要长时间大规模的、基于用户反馈的迭代才能到达一个高可用的状态。特别是 Modules 的本质是对 C++ 语言的序列化和反序列化,这意味着只要 C++ 语言本身依然保持着演化,那 Modules 的开发就不存在 “完成” 这个说法。例如我们现在发现的不少 Modules 的 Bug 与 Concept 这样的新语法相关。
虽然上面这段话可能显得 Clang 中对 Modules 的支持相对较差,但笔者感觉目前三大编译器对 Modules 的支持水平的差距可能并不大。起码近几天三大编译器的开发者碰头交流情况时,大家都表示最近在修 Bug。所以感觉进度其实都差不太多。
当然大家可能还是很好奇何时才能用上一个稳固、丝滑、高可用的 Modules。一方面感觉这个问题没法回答,因为现在 Clang 编译器没有 Stable Release 的概念也不会专门宣布像 Modules 这样的 feature 已经完成了。另一方面我个人套用软件发布生命周期的概念的话,目前 Clang 中 Modules 的状态可能处于 Alpha 或 Beta 的状态,再经过一两个版本就能达到较为稳定的水平了,大概是 Clang17 或 Clang18 左右(注意:这并非官方概念)。

另外比起看各种各样的文章(包括本篇)和评测,还是很推荐大家上手试一试 Modules。一方面如果用的语法不太小众的话,应该问题不大。另一方面如果遇到了编译器问题的话,能做 Minimal Reproducer 向社区发 Issue Report 的话,也很有帮助。
(5)当前构建工具支持状态
其实,阻碍大家使用 Modules 的另一个重要原因还是构建工具的支持不太够。毕竟对大多数人来说无论是手写 makefile 还是写 CMake 或其他构建工具的脚本都还是比较煎熬的事。大家还是希望能有一个开箱即用的工具可以让自己专注于新 feature 本身。本节就简单介绍下我们所知的构建工具对 Modules 的支持情况。
MSBuild。VS 中自带的构建工具。较早的支持了 Modules。不过只支持 MSVC。
Build2。早在 19 年就支持了 GCC Maintainer 提出的 Server-Client 模型。不过只支持 GCC 而且似乎最近没有更新的消息了。
XMake。XMake 是一个轻量级、跨平台的基于 Lua 构建工具。XMake 的更新频率很高且对新 feature 的跟近也很及时。看介绍已经支持了 MSVC、GCC 以及 Clang 三大编译器。XMake 的风评很不错,推荐感兴趣的朋友看一下。
CMake。老牌 C++ 构建工具,不必多说。虽然之前对 Modules 的支持显得略慢,但在过去的半年内开始发力。如果一切顺利的话,在今年春天发布的 CMake 3.26 中将包含对 MSVC、GCC 以及 Clang 三大编译器的支持。
Bazel。暂时没听到 Bazel 官方对 C++20 Modules 进行支持的消息。但得益于 Bazel 的扩展性,目前已经有一些基于 Bazel 的工具开始支持 C++20 Modules。其中我个人最推荐的是 rules_ll[5] 这个工具。与其他玩具性质的扩展不同,rules_ll 似乎是想做一个长期的、针对异构代码编译的工具,对 C++20 Modules 的支持是其中的一个(重要)feature。
(6)对其他工具的影响
在 C++ 生态当中,除了编译器和构建系统之外,还有许许多多的其他工具。在这些工具中,几乎所有与项目构建以及以 C++ 代码作为输入的静态分析工具都将会受到 Modules 的强烈冲击。即这些工具如果不对 Modules 做适配,那这些工具面对使用了 Modules 的代码就基本完全没法用。这类工具数量非常多,完全无法列举,这里仅简单举几个例子:
clangd。clangd 是一个 Language Server。clangd 可以为程序员进行代码自动补全、高亮提示、语法提示和代码跳转等功能。而可以想象的,如果不对 Modules 做特殊适配,以上这些功能在面对使用 Modules 的代码时都将失效。市场上的其他类似的工具也都是一样。
ccache。ccache 是一款对编译结果进行 cache 以提升编译速度的工具。ccache 的关键是通过依赖分析以保证做一致性判断时不会误判。但 Modules 恰好会引入新的依赖关系。这就产生了冲突。
distcc。distcc 是一个分布式编译工具。与 ccache 类似,这样的工具必然需要处理依赖关系而与 Modules 产生冲突。而对于 distcc 另一个更大的问题是,目前 Modules 产生的 module file 的体积要远大于预处理后的头文件体积。这使得在网络中传递 module file 可能会成为一个瓶颈。而如果网络传输速度成为瓶颈的话,分布式编译的意义也就受到挑战了。当然,这本质是 Modules 技术的一个挑战而不是分布式编译的。
……
这当然是很多的问题,但对于工具开发者们来说,这也是一个难得的机遇。而这些问题在 Modules 设计之时都已经被考虑到了。最终的结果大家也都看到了。委员会的想法是,这些确实都是很严肃的问题。但经过评估,这些都不是不能解决的问题。我们不能因此止步不前。C++ 语言要朝着更现代化的方向发展,C++ 生态也自然需要向着更现代化的方式去发展才行。C++ 语言的愿景或者说目标用户是:“能够长久运行数十年的大型高效率软件”。为达成这个目标,C++ 生态也需要与之相对应的变化。
(7)未来的方向:兼容性、分发以及包管理器
Modules 受人期待的一个重要原因即大家觉得 Modules 有希望解决 C++ 长久以来的受人诟病的分发问题。可能大多数构建过大型 C++ 项目的朋友都会有一个相同的感受:快被环境问题整吐了。不知道有多少 C++ 程序员在开始一个大型的 C++ 项目时都怀疑过自己到底是一个 C++ 程序员还是一个系统运维。
导致这种问题出现的一个本质原因即是 C++ 生态中的依赖传递方式要么是全源码依赖要么是半源码半二进制依赖。而库的开发人员所考虑的环境、库的编译环境以及用户环境则很可能是不一致的。这导致了各种各样的源码没法编译、没法链接、一运行就挂等等问题。这个问题的本质是大家的环境不一致,但 C++ 语言又使得各种环境要混在一起导致的。在一些拥有良好的基础设施的大公司,这个问题的解决方式是通过强行让大家的环境一致来避免环境不一致带来的混乱问题。但这种方式一方面需要很强的技术能力,另一方面却也增加了技术交流的壁垒。
而 Modules 的出现使得我们有机会从另一个角度来解决这个问题。Modules 能够将库的开发环境(或者说库的编译环境)与用户环境隔离开来,降低了环境冲突的风险。另一方面 Modules 能够将库所需的开发环境描述在 metadata 里,这让用户遇到无法兼容的环境时可以尽可能早的得到报错信息而不是各种链接错误或者说运行时错误时满脸茫然。
不过这节既然被放到了「未来的方向」中,即说明这个想法目前还只是个美好的愿景。本质原因是想要达到上述的美好环境,我们需要支持 Modules 的二进制分发。但任何二进制分发都需要涉及到兼容性问题。而目前 Modules 的二进制兼容性,基本等价于 0。别说 Clang 与 GCC 编译的 Modules 的二进制兼容,就连 Clang 任意不同版本编译后的 Modules 的二进制都是不兼容的。
这是因为目前编译器实现 Modules 的方式基本是对 AST 的序列化和反序列化。而 AST 作为编译器内部的数据结构,其必然是没有什么格式要求的。不然一个开发者交个 patch 简单改下 AST 都需要发提案进行修改,这样的模式显然太低效了。据我所知目前 MSVC,Clang 和 GCC 都处于这个状态。开发者们目前的共识是,起码现在 Modules 的二进制分发是不现实的,还是推荐大家源码分发吧。另外听说 MSVC 在弄 Modules 的二进制格式规范,但进度应该非常慢,不知何时才能有比较具体的东西可以看看。
虽然统一的二进制格式显得遥遥无期,但大家都觉得这应该是未来的方向,也是 Modules 诞生的重要意义。个人觉得,未来可期。
(8)Carbon 与 “下一个 C++”
在 22 年的夏天,Google 向大家隆重地介绍了号称 “下一个 C++” Carbon 语言。这里由于篇幅与主题原因,不对 Carbon 语言做过多介绍,但非常建议感兴趣的朋友们可以去看看 Carbon 官方的文档。Carbon 官方的文档丰富而流畅,笔者认为这是学习工业界系统级编程语言设计的绝佳材料,特别是 Carbon 目前还处于设计中的状态,这种机会并不多。
回过头来,Carbon 的核心概念其实可以简单概括为 “C++ 的未来就是现有的 C++ 代码库”。现在当我们问为什么要用 C++ 写产品级代码时,我们能得到的其中两个较多答案是“因为我们依赖的库是用 C++ 写的” “我加入的时候这个产品就是用 C++ 写的了,后来代码太多改不过来了”。对于这两个答案,翻译一下就是,“如果依赖的库不是 C++,那么我不会使用 C++” “如果我们改得过来的话,那我们就不用 C++了”。将这两句话再延伸下就是,“我们现在及之后编写 C++代码的理由是因为之前的 C++代码”。再延伸一步即是上面提到的这句话,“C++的未来就是现有的 C++代码库”。而如果有一个可以完全兼容现有 C++代码的新语言,对于抱有以上两种心态的用户而言,他们确实不用再写 C++代码了。
需要注意,笔者并不赞同以上这个观点。但无论笔者是否赞同,都确实有以及将会有为数不少的人认同这个想法。在这里提到这个话题的原因是,Carbon 能做到完全兼容现有 C++ 代码的原因之一即是 Modules 技术背后的对 C++ 代码进行预编译后序列化以及反序列化的技术,而不是再 Carbon 语言里再塞一堆内置的 C++ 语法。
可以预见的是,未来某日 Modules 技术成熟之后,实现完全兼容 C++ 的新语言的成本将会低很多。可能像目前自制语言已不稀奇一样,也许未来的 “下一个 C++” 将会俯仰皆是。你的 “下一个 C++” 又何必是 Carbon?

Coroutines
协程 (Coroutines) 是 C++20 引入的 4 大特性(Modules、Coroutines、Concepts 和 Ranges)之一。协程本身也是计算机科学中的经典概念,在上个世纪 60 年代就出现了。协程的本意是一个可中断的执行流,而根据这个执行流的上下文中是否包含栈的信息,又可将协程分为有栈协程(stackful coroutines) 和无栈协程(stackless coroutines)。
对于有栈协程,既然它是一个可中断的带有栈的执行流,那这个概念和我们所熟知的线程就非常相似了。为了避免混淆,在一般语境中,我们说线程指的是由操作系统管理中断和唤醒的线程。而有栈协程的中断和唤醒则是通过用户态代码实现的,所以有栈协程也被叫做用户态线程,也有 fibers、green threads 这样的名字。
Go 语言中的杀手级特性 Goroutines 就是一种有栈协程。因为有栈协程是用户态线程,所以能理解线程概念的朋友理解有栈协程应该会很容易。有栈协程相比于线程的价值即是有栈协程的切换是用户态的、不需要陷入内核态。这用户态切换相比于内核态切换所节约的成本就是有栈协程的价值。当然,与之相对的,线程的切换和调度由内核控制而有栈协程的切换和调度则由用户预先设置好,即有栈协程应该调度但没有调度或有栈协程不应调度但调度时所产生的成本则是有栈协程的成本和代价。
对于无栈协程,它没有栈,它执行的上下文就是开始函数本身,即无栈协程是一个可中断和唤醒的函数。由于有栈协程更容易被大家理解和接受,所以有些地方也叫无栈协程作第二代协程(但似乎无栈协程出现的时间并不比有栈协程晚)。无栈协程因为没有栈,无栈协程在切换时的代价非常低,基本等价于两个函数调用,而有栈协程切换时还需要保存各种寄存器,相比起来就慢很多了。但无栈协程也有其代价,由于无栈协程天然没有栈,而我们编程时的逻辑往往自然是有调用关系概念的,这使得我们用无栈协程时需要显式的语法来表示这种特殊的调用关系。这也是常说的无栈协程的传染性。在其他语言中,像 javascript 与 Rust 中的 await 与 async 都是用无栈协程来实现的。
再回到协程进入 C++ 标准时,当时协程这个概念在各个语言中都很火,特别是 Go 中 Goroutine 非常火爆,大家都觉得 C++ 也应该有协程特性才对(当然事实和这个不一定有逻辑关系,协程进入 C++ 标准很早就开始筹备了)。很自然地,C++ 标准中的协程应该是无栈协程还是有栈协程就成为了一个自然的选择。当时有 Google 提出的有栈协程方案与微软提出的无栈协程方案。最终由于 C++ 的零抽象原则以及无栈协程方案更高的扩展性,委员会最终选择了无栈协程的方案。
至此,在 C++语境中提及协程(Coroutines)都默认为无栈协程。而在此之前,在 C++语境中提到协程时则可能指代更好理解的有栈协程。比如很多 C++20 之前的协程库其实指的是有栈协程库。
值得一题的是,目前依然有提案尝试将有栈协程加入到 C++ 标准中。毕竟有栈协程和无栈协程终归不是一个东西,语义的差别也比较大。所以现在标准中已有无栈协程不是一个拒绝有栈协程进入标准的很强的理由。但目前委员会的状态似乎是没有明确反对但也没有很大兴趣的状态。
(1)语法简介
委员会希望 C++20 协程有着尽可能高的可扩展性,所以在 C++20 中只设计了协程的语义框架而没有设计任何的协程语义。这也和其他很多的语言不同,其他语言就算选择了底层使用无栈协程实现,最终提供给用户的都是封装好的接口。C++20 的协程的用户本质上是协程库作者而非广大的用户。按照设计者的想法,C++协程的最终用户(end user)只需要学习所需的、封装好的协程库即可而不必学习繁复的 C++20 协程语法。
如果大家对 C++20 协程语法感兴趣的话,个人建议看看 Lewis Baker 的博客[6]。这是我见过对 Coroutine 语法的解读最好的材料了,就不在此拾人牙慧了。
(2)用途
异步场景
协程或者说 C++20 协程最吸引人的地方在于可用同步的方式写异步的代码。正如之前提到的,当前 C++世界的两大浪潮是异步化和并行化。当我们想提高一个 IO 密集型的同步程序的性能时,将其异步化能得到很好的效果。在我们的实践中,这一般可以得到一个数量级以上的 QPS 的提升。异步化当然不是个新概念。但之前在 C++项目中想写异步程序往往需要基于回调的方式。但回调的写法不直观、对程序员有很大的心智负担。会增加出 Bug 的概率,对程序性能可能也有影响。接下来通过一个简单的例子说明下。
首先,我们先来看看同步的代码,这个代码会读若干个文件后返回总的文件体积。代码还是很简单的:
uint64_t ReadSync(std::vector<File> Inputs)
uint64_t read_size = 0;
for (auto &&Input : Inputs)
read_size += ReadImplSync(Input);
return read_size;
接下来我们再看下一个基于回调的版本: