python b站动态转发动态评论区抽奖(已打包成exe,可以下载食用)
Posted Love丶伊卡洛斯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python b站动态转发动态评论区抽奖(已打包成exe,可以下载食用)相关的知识,希望对你有一定的参考价值。
前言
更新日志
2022-5-28 由于发现b站api变更,更新新版本v3.6进行适配
2022-8-1 更新兼容视频动态版本v3.7
2022-9-20 基于ttk库优化UI,发布版本v3.8
简述
记 b站动态评论+视频评论区 抽奖2合1 JS版本发布后,计划了这次的python版本,本来的预期是实现同功能的python版并挂我服务器上免费提供抽奖服务来着。不过写着写着突然发现了之前对API的解析有所漏洞,导致我发现了一个新bug。。。(居然没人提醒我)

旧程序将全部的自发型动态归为type=11,今天测试时发现居然还有type=17和1的情况

于是乎 我就把原来的JS版的也改了,顺便把python的动态评论区抽奖给写了。动态转发也根据Hack Inn大佬之前提供的源码,进行了python3版本的简单适配,因为我懒了0.0
python版本:3.8.5
工程构建:pycharm
代码/exe下载
代码下载:GitHub 码云
exe程序下载:GitHub 码云(温馨提示:请勿随意执行来历不明的程序)


效果图
GUI版-v3.8
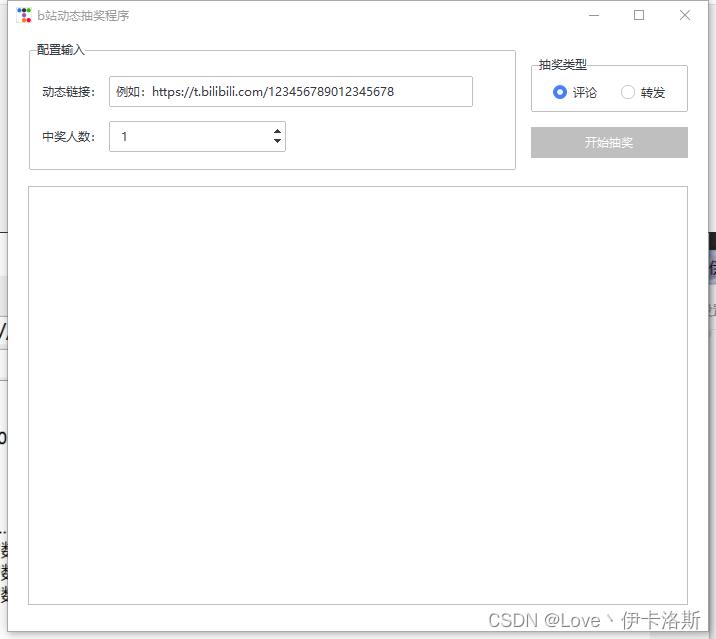
GUI版-v3.7
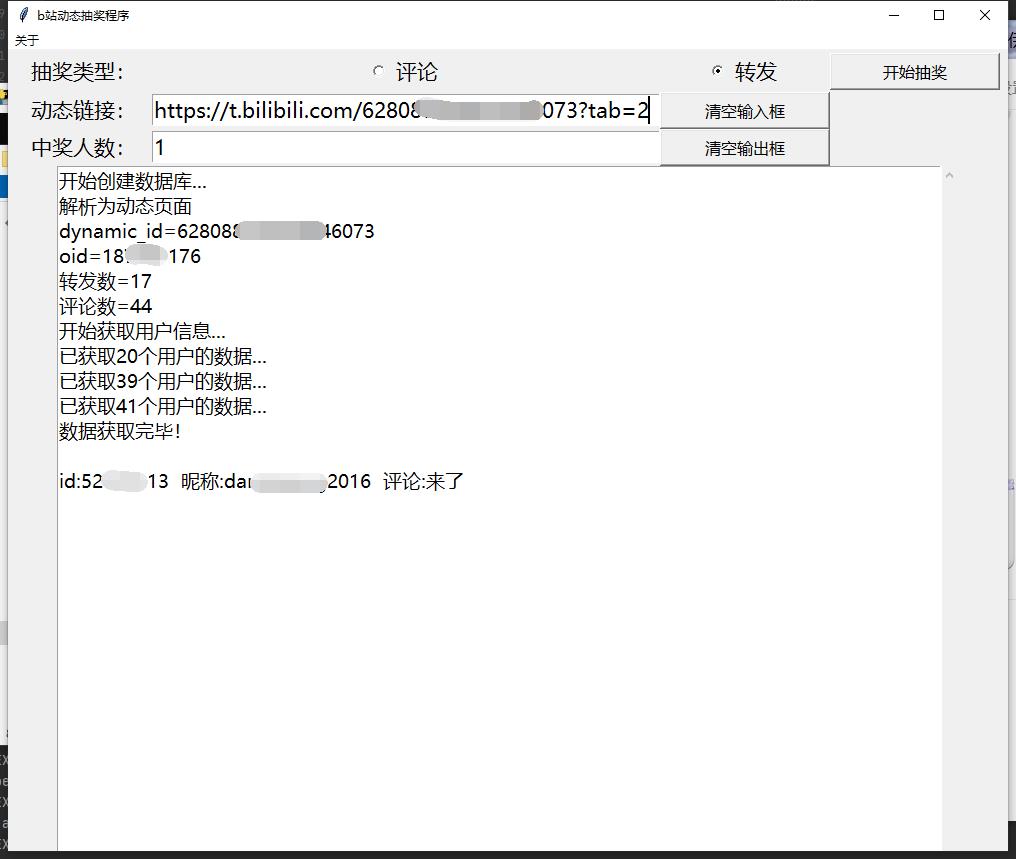
cmd版本

【b站抽奖】Python实现 动态转发、动态评论抽奖,实际程序演示+粗略讲解
使用说明
GUI版本使用方法类似
1、双击运行bat文件

2、输入抽奖类型(数字) 然后“回车”
(1评论 0转发)

3、粘贴入 动态页面的链接 然后“回车”
因为动态又改版了,?后面的东西都不要复制了
注意,链接后的 ?tab=2 也需要复制过来,因为做了动态类型的识别,这也做为关键参数需要检测。
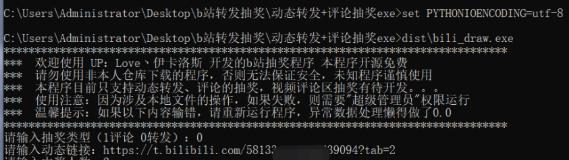
4、输入中奖人数(要是数字) 然后“回车”
因为我没做校验(懒)
直接就运行完成了。会爬取所有评论人的数据到数据库(自动去重)
数据库文件在同一文件夹下“user_data.db”
然后会直接抽取中奖用户并打印,复制中奖信息即可。
最后输入数字1,退出程序。
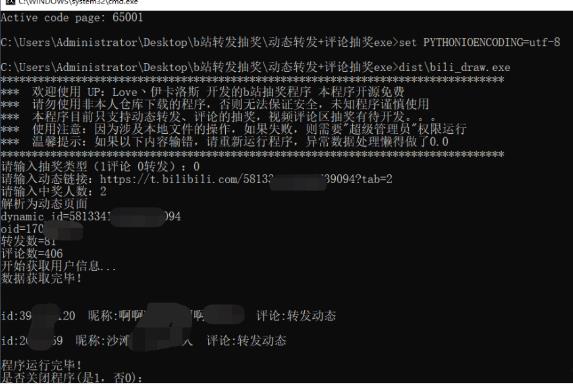
所有评论人员数据查看
评论人员数据存储于同一文件夹的“user_data.db”中
sqlite数据库,我使用 sqlitebrowser打开这个db文件
可以看到我们的user表
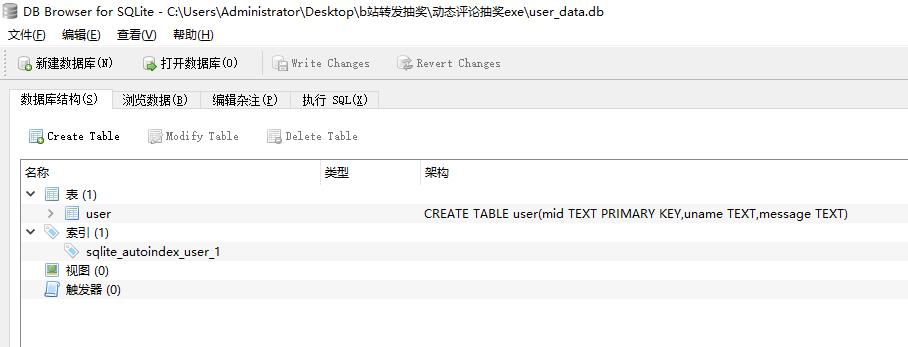
点击“浏览数据”,选择我们要查看的user表,即可看到所有用户数据
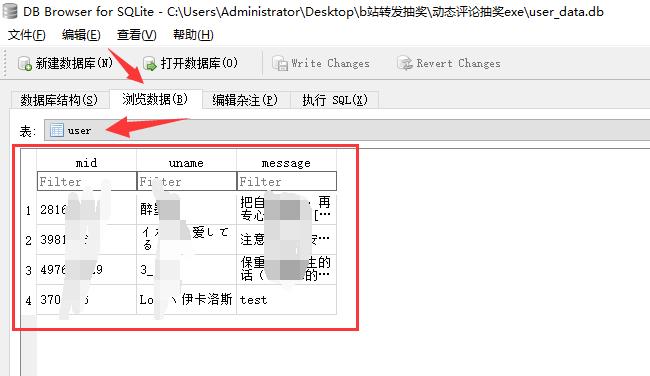
当然你也可以用网上的 随机数程序生成随机数,然后进行抽奖,问题不大0.0
源码
GUI版本-v3.8
# -*- coding: utf-8 -*-
import json
import time
import random
import urllib.request
import urllib.parse
import sqlite3
import tkinter
import ttkbootstrap as ttk
from ttkbootstrap.constants import *
from ttkbootstrap.dialogs import Messagebox
from ttkbootstrap.scrolled import ScrolledText
# python版本:3.8.12
# 打包 pyinstaller -F 1.py
# 获取抽奖类型
global draw_type
global referer
# 中奖人数
global lucky_num
global dynamic_id
global text_str
# 动态类型
global api_type
api_type = 11
draw_type = 1
dynamic_id = ""
# 打印文本框
text_str = ''
# 数据集合
id_set = set()
name_set = set()
lucky_set = set()
headers1 =
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Type': 'text/plain;charset=UTF-8',
'Referer': 'https://t.bilibili.com',
'origin': 'https://t.bilibili.com',
# 'cookie': 'l=v',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/70.0.3538.25 '
'Safari/537.36 Core/1.70.3875.400 QQBrowser/10.8.4492.400 '
# 字符串是否是数字
def is_number(s):
try:
float(s)
return True
except ValueError:
pass
try:
import unicodedata
unicodedata.numeric(s)
return True
except (TypeError, ValueError):
pass
return False
# 配置数据库
def config_db():
global con, cur
global text_str
# print("开始创建数据库...")
text_str = "开始创建数据库...\\n"
text.insert(END, text_str)
text.update()
con = sqlite3.connect("user_data.db")
cur = con.cursor()
# 创建表user
sql = "CREATE TABLE IF NOT EXISTS user(mid TEXT PRIMARY KEY,uname TEXT,message TEXT)"
cur.execute(sql)
# 情况表数据
sql = "delete from user"
cur.execute(sql)
# 获取oid、转发数、评论数函数
def get_oid():
global text_str
global dynamic_id
global api_type
global text
if referer[8] == 't':
# print('解析为动态页面')
text_str = "解析为动态页面\\n"
text.insert(END, text_str)
text.update()
else:
# print('解析为视频页面')
text_str = "解析为视频页面\\n"
text.insert(END, text_str)
text.update()
tab_type = "2"
# 用户输入是否是完整复制动态链接,链接尾部 是否是 ?tab=2
# if referer[-6:-1] == "?tab=":
# dynamic_id = referer[23:len(referer) - 6]
# tab_type = referer[-1]
# else:
# dynamic_id = referer[23:len(referer)]
temp = referer.split('?')
temp2 = temp[0].split('/')
dynamic_id = temp2[3]
# print("dynamic_id=" + dynamic_id)
text_str = "dynamic_id=" + dynamic_id + "\\n"
text.insert(END, text_str)
text.update()
if len(dynamic_id) == 0:
# print("dynamic_id异常,程序终止,请检查您的输入是否有误!")
text_str = "dynamic_id异常,程序终止,请检查您的输入是否有误!\\n"
text.insert(END, text_str)
text.update()
base_info = 'ret': False
return base_info
# payload = 'dynamic_id': dynamic_id
payload = 'timezone_offset': '-480', 'id': dynamic_id
data = urllib.parse.urlencode(payload)
# print(data)
req = urllib.request.urlopen('https://api.bilibili.com/x/polymer/web-dynamic/v1/detail?%s' % data)
# req = urllib.request.urlopen('https://api.vc.bilibili.com/dynamic_svr/v1/dynamic_svr/get_dynamic_detail?%s' % data)
ret = req.read().decode()
# print(ret)
json1 = json.loads(ret)
oid = json1["data"]["item"]["basic"]["comment_id_str"]
repost = json1["data"]["item"]["modules"]["module_stat"]["forward"]["count"]
# oid = json1["data"]["card"]["desc"]["rid"]
# repost = json1["data"]["card"]["desc"]["repost"]
comment = 0
# 非视频动态
if tab_type == "2":
comment = json1["data"]["item"]["modules"]["module_stat"]["comment"]["count"]
else:
comment = 0
# 判断动态类型
api_type = json1["data"]["item"]["basic"]["comment_type"]
# print("oid=" + str(oid))
base_info = 'ret': True, 'oid': oid, 'repost': repost, 'comment': comment
# print(base_info)
return base_info
# 获取用户信息函数
def get_user_info(base_info):
global text_str
global api_type
global text
# print("开始获取用户信息...")
text_str = "开始获取用户信息...\\n"
text.insert(END, text_str)
text.update()
if int(api_type) == 17:
# 用户输入是否是完整复制动态链接,链接尾部 是否是 ?tab=2
if referer[-6:-1] == "?tab=":
base_info["oid"] = referer[23:len(referer) - 6]
else:
base_info["oid"] = referer[23:len(referer)]
end = 0
for i in range(int((base_info["comment"] - 1) / 20) + 1):
if i == 0:
url = "https://api.bilibili.com/x/v2/reply/main?jsonp=jsonp&next=0&type=" + str(api_type) + \\
"&oid=" + str(base_info["oid"]) + "&mode=3&plat=1&_=" + str((int(round(time.time() * 1000)) + 1))
else:
url = "https://api.bilibili.com/x/v2/reply/main?jsonp=jsonp&next=" + str(i + 1) + "&type=" + str(api_type) + \\
"&oid=" + str(base_info["oid"]) + "&mode=3&plat=1&_=" + str((int(round(time.time() * 1000)) + 1))
if i == int((base_info["comment"] - 1) / 20):
end = 1
get_data(url, end)
time.sleep(0.5)
# 获取数据函数
def get_data(url, end):
print(url)
global text_str
global text
req = urllib.request.urlopen(url)
ret = req.read().decode()
# print(ret)
json1 = json.loads(ret)
# json1["data"]["replies"]有可能为null
if json1["data"]["replies"] is not None:
len1 = len(json1["data"]["replies"])
for i in range(len1):
mid = json1["data"]["replies"][i]["member"]["mid"]
uname = json1["data"]["replies"][i]["member"]["uname"]
message = json1["data"]["replies"][i]["content"]["message"]
# 数据插入集合
# name_set.add(uname)
id_set.add(mid)
# 数据插入数据库
sql = "replace into user(mid, uname, message) values (?, ?, ?)"
cur.execute(sql, (mid, uname, message))
con.commit()
# print("已获取" + str(len(id_set)) + "个用户的数据...")
text_str = "已获取" + str(len(id_set)) + "个用户的数据...\\n"
text.insert(END, text_str)
text.update()
# print("插入一组数据组")
if end == 1:
# print("数据获取完毕!\\n")
text_str = "数据获取完毕!\\n"
text.insert(END, text_str)
text.update()
# print(name_set)
# print(id_set)
while len(lucky_set) < int(lucky_num):
num = random.randint(0, (len(id_set) - 1))
lucky_set.add(num)
# print(lucky_set)
# id_list = list(id_set)
# name_list = list(name_set)
# for i in range(int(lucky_num)):
# print("昵称:" + name_list[i] + " id:" + id_list[i] + "\\n")
for i in range(int(lucky_num)):
lucky_list = list(lucky_set)
# print("lucky_num=" + str(lucky_list[i]))
sql = "select * from user limit " + str(lucky_list[i]) + ",1"
cur.execute(sql)
rows = cur.fetchall()
for row in rows:
# print('\\nid:%s 昵称:%s 评论:%s' % (row[0], row[1], row[2]))
text_str = '\\nid:%s 昵称:%s 评论:%s' % (row[0], row[1], row[2]) + '\\n'
text.insert(END, text_str)
text.update()
text_str = '\\n\\n'
text.insert(END, text_str)
text.update()
# 获取转发用户的数据
def get_repost_user_info(base_info):
global text_str
global dynamic_id
global text
print("开始获取用户信息...")
text_str = "开始获取用户信息...\\n"
text.insert(END, text_str)
text.update()
# 用户输入是否是完整复制动态链接,链接尾部 是否是 ?tab=2
# if referer[-6:-1] == "?tab=":
# dynamic_id = referer[23:len(referer) - 6]
# else:
# dynamic_id = referer[23:len(referer)]
temp = referer.split('?')
temp2 = temp[0].split('/')
dynamic_id = temp2[3]
temp_num = 0
# 根据转发数进行循环
while temp_num < int(base_info["repost"]):
url = "https://api.live.bilibili.com/dynamic_repost/v1/dynamic_repost/view_repost?dynamic_id=" + \\
str(dynamic_id) + "&offset=" + str(temp_num)
req = urllib.request.urlopen(url)
ret = req.read().decode()
# print(url)
# print(ret)
json1 = json.loads(ret)
len1 = 0
if "comments" in ret:
len1 = len(json1["data"]["comments"])
# print(len1)
else:
print("可获取的数据结束!\\n")
text_str = "可获取的数据结束!\\n"
text.insert(END, text_str)
text.update()
break
for i in range(len1):
uid = json1["data"]["comments"][i]["uid"]
uname = json1["data"]["comments"][i]["uname"]
comment = json1["data"]["comments"][i]["comment"]
# 数据插入集合
# name_set.add(uname)
id_set.add(uid)
# 数据插入数据库
sql = "replace into user(mid, uname, message) values (?, ?, ?)"
cur.execute(sql, (uid, uname, comment))
con.commit()
temp_num += 20
# print("已获取" + str(len(id_set)) + "个用户的数据...")
text_str = "已获取" + str(len(id_set)) + "个用户的数据...\\n"
text.insert(END, text_str)
text.update()
time.sleep(0.5)
print("数据获取完毕!\\n")
text_str = "数据获取完毕!\\n"
text.insert(END, text_str)
text.update()
while len(lucky_set) < int(lucky_num):
num = 0
if len(id_set) > 1:
num = random.randint(0, (len(id_set) - 1))
lucky_set.add(num)
else:
print('用户数据不足2个,数据异常,程序结束')
text_str = "用户数据不足2个,数据异常,程序结束\\n"
text.insert(END, text_str)
text.update()
return
for i in range(int(lucky_num)):
lucky_list = list(lucky_set)
# print("lucky_num=" + str(lucky_list[i]))
sql = "select * from user limit " + str(lucky_list[i]) + ",1"
cur.execute(sql)
rows = cur.fetchall()
for row in rows:
print('\\nid:%s 昵称:%s 评论:%s' % (row[0], row[1], row[2]))
text_str = '\\nid:%s 昵称:%s 评论:%s' % (row[0], row[1], row[2]) + '\\n'
text.insert(END, text_str)
text.update()
text_str = '\\n\\n'
text.insert(END, text_str)
text.update()
# 单选框点击
def radio_click():
global draw_type
draw_type = radio.get()
# print("draw_type:" + str(draw_type))
# 开始抽奖按钮点击
def start_btn以上是关于python b站动态转发动态评论区抽奖(已打包成exe,可以下载食用)的主要内容,如果未能解决你的问题,请参考以下文章