双方案-基于Mysql 与 ElasticSearch实现关键词提示搜索与全文检索
Posted Huterox
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了双方案-基于Mysql 与 ElasticSearch实现关键词提示搜索与全文检索相关的知识,希望对你有一定的参考价值。
文章目录
前言
就喜欢搞这种不需要怎么费劲的东西,只需要把思路阐述清楚,随笔性质的博文,顺手啊,几乎不用改定就可以当博文发布出去。
那么,这里的话我们要做的就是实现这个关键词的一个搜索功能,这个前端我就不说了,实现起来起来其实还是容易的,就是费劲。我们主要关注到后端,然后关于这个的话,我们这里还是提供两个方案,一个就是直接基于mysql>=5.7去做的,还有一个就是直接基于ElasticSearch去做。当然自己做一个也可以,那么之后的话,工程结束的话,那么以后碰到这种容易写的或者,非常有必要的东西,我还是会回来记录一下的。
Mysql检索
那么首先我们基于Mysql去做。这个方案最省钱,当然由于Mysql的数据是在磁盘当中的,首先会慢一点,然后,在重新对数据进行修改的时候,需要重新构建索引,如果我们做全文检索的话,那么如果这个词很多的话,更新是会比较慢的,因此适合小批量的数据检索,或者说仅仅针对某一个字段进行检索。例如我们做的是一个博文技术交流社区,我们可以选择对标题进行检索。当然一般情况下来说,以CSDN这种网站为例,我们在检索的时候,往往会发现它匹配的其实不仅仅只是标题,其实对文章的内容也会做检索,因此,当我们需要做这种检索的时候,使用MySQL 的话,其实就不是那么好了,但是凡事是没有绝对的。不同的场景还是有不同的优势的。
当然最最简单,直接暴力的方式就是,mysql like。至于效果,我就不说了。
简述原理
全文检索通常会使用倒排索引实现。倒排索引同B+树索引一样,也是一种索引结构。
只是数据结构肯定是不同的,它通过一个辅助表,这个辅助表中存储了单词与单词自身在一个或多个文档中所在位置之间的映射。这通常采用关联数组实现,有两种表现形式:
1)inverted file index:单词,单词所在的文档ID
2)full inverted index:单词,单词所在的文档ID,在具体文档中的位置
有机会可以聊一聊这个关于B+ 树,其实还是很有意思的,以前一直以为数据库会CURD就行了,现在自己做项目发现,八股文还有点用的,涉及到的很多优化那省下来的可是白花花的银子。有什么方案,为什么这样,理解大致原理还是很重要的
首先大概形式可能是这样的:
一句话 we dislike java lucene
存进去的东西大概是这个样子的:
(数据表)
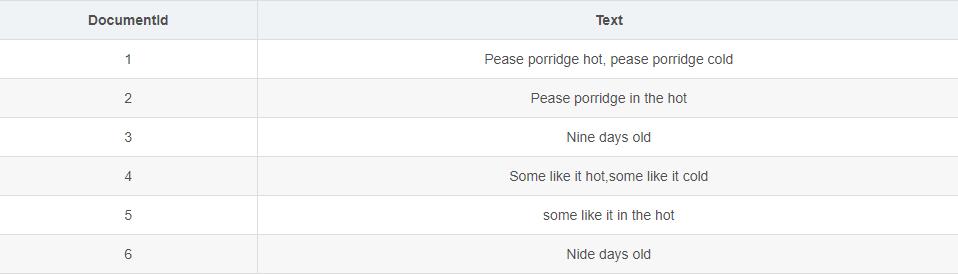
这个东西的话其实和我们的表结构是类似的,Documentid 其实就是我们ID呗,text只是我们的一个字段嘛。其实在MySQL实现里面,我们就是按照表来的,只是这个表很多个字段罢了。
最后构建出的索引大概是这个样子。(full inverted index)
(索引表)
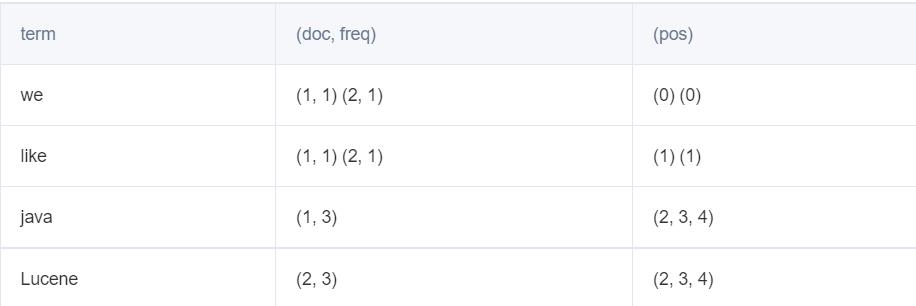
那么此时当我们去查找的时候,那么我们是这样的。
那么,在MySQL>=5.7 中InnoDB存储引擎支持全文索引采用full inverted index的方式,将(DocumentId,Position)视为一个“ilist” 。因此在全文检索的表中,一共有两列,一列是word字段,另一个是“ilist”,并且在word字段上设有索引。
此外,由于在ilist字段中存放了Poistion信息,所以可以进行Proximity Sreach,但是MyISAM存储引擎不支持该特性。
那么我们去查找的时候呢,我们就是先把一句话,先做个分词,然后呢,我们去索引里面匹配,把这些id找出来,然后做个交集,当然还会计算一下匹配程度,然后拿到id之后,我们再根据我们原来的数据表去找到对应的一个行。
其他索引
同样的,在检索的其他索引的时候,工作原理是类似的。比如我们经常用的数字ID主键之类的,用B+ 树进行一个实现。
我们的一个表的数据大概是这样放的:(假设用B+ 树构建索引)
id,数据
那么之后的话我们构建一个索引。大概是这样的:
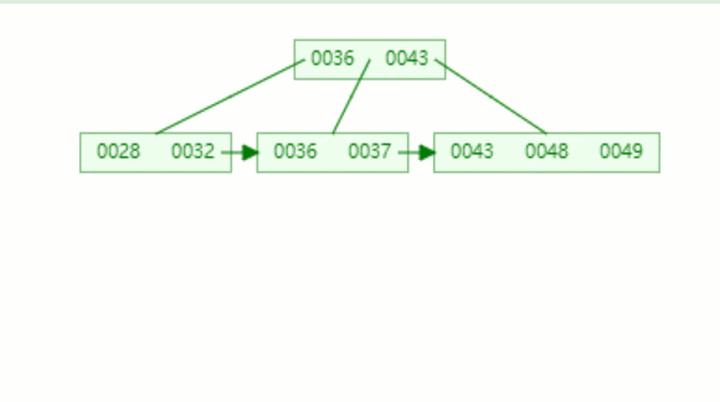
我们这样的数据节点,放到这样一颗树当中,这样就比遍历方便多了。
所以的话,这里你应该可以理解为什么要用B+ 树了,B树和B+ 树是类似的,只是B+ 树多了一个子节点间的连接,就是这样呗:
id,数据,nexid 为啥只需要nexid, 这个应该不需要我多说了吧。为什么是B树,不是其他树也可以理解了。
构建
okey,扯了一下犊子,我们继续来说说,如何使用到MySQL进行到一个检索。
那么首先要做的就是添加我们刚刚说的全文检索的索引。这里的话,我要说明的就是,其实这个全文索引是很早就支持了的,但是对于中文的分词是没有实现的,这个就很尬了,当然以前的解决方案就是搞个拼音去,但是>=5.7以后支持了中文分词,这个就棒。
ALTER TABLE `table_name` ADD FULLTEXT ( `col` )
如果不是innoDB,那么可以使用这个进行切换,当然直接用图形化软件也可以,应该没人喜欢怼命令。
ALTER TABLE my_table ENGINE = InnoDB;
实例
那么按照我这个为例,那么我先对博文进行一个创建,对标题进行创建全文检索。
ALTER TABLE blogs_blog ADD FULLTEXT INDEX ft_blog (`blog_title`) WITH PARSER ngram;
ft_blog: 所以名字
blog_title: 字段名字
这个可以搞多个字段哈。
那么接下来我们做一个简单的查询。
SELECT * FROM blogs_blog WHERE blogid>3 and MATCH(blog_title) AGAINST ('问题' IN NATURAL LANGUAGE MODE)
那么这里可以看到一个结果。

同样的我们刚刚说了他会做一个匹配,所以的话,我们可以看到它和全部进行匹配的结果
SELECT blogid as id, MATCH (blog_title) AGAINST ('问题' IN NATURAL LANGUAGE MODE) AS score FROM blogs_blog;
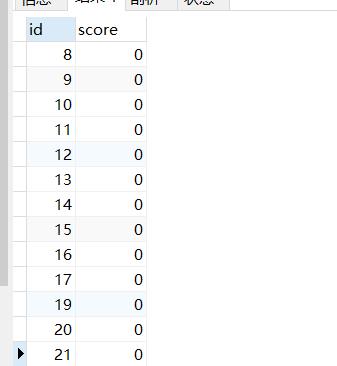
这里的话,其实是把全部的数据进行了一个评分。所以本来人家就慢,数据多,需要计算的得分多,单条数据的量有多,算得就慢。当然主要消耗还是在IO这里,但是放内存烧钱啊。
代码
那么接下来的话,我们就来简单的实现一下这个东西,这里比较遗憾的,虽然MybatisPlus可以满足大量的查询构建,但是对于这个,咱们还是需要自己手动去编写SQL。
这里的话也是简单一点,由于咱们这个SQL的话比较长,比较复杂,所以的话,我把这个SQL给放到了这个xml文件 当中。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.huterox.whitehole.whiteholeblog.dao.BlogDao">
<!--sql-->
<select resultType="com.huterox.whiteholecould.entity.blog.BlogEntity" id="fullMatch">
SELECT *
FROM (SELECT * FROM blogs_blog WHERE status=1) as a
WHERE MATCH(blog_title) AGAINST (#key IN NATURAL LANGUAGE MODE)
ORDER BY fork_number DESC,collect_number DESC,like_number DESC, view_number DESC
Limit 0,5
</select>
</mapper>
之后的话,我们在页面测试一下就好了。

可以发现,接口返回了正常的数据。
搜索流程
okey,那么之后的话,就是我们需要去实现这样的一个功能,我们直接以csdn为例子吧。
当你在搜索栏进行搜索的时候呢,我们需要跳出这样的提示。

当然在CSDN这个是对搜索做了一个统计,对这个做了一个维护检索。不过我们这边是直接对内容进行搜索。然后下拉列表给出提示,然后去进行搜索。
那么逻辑的话,我这里是这样的。
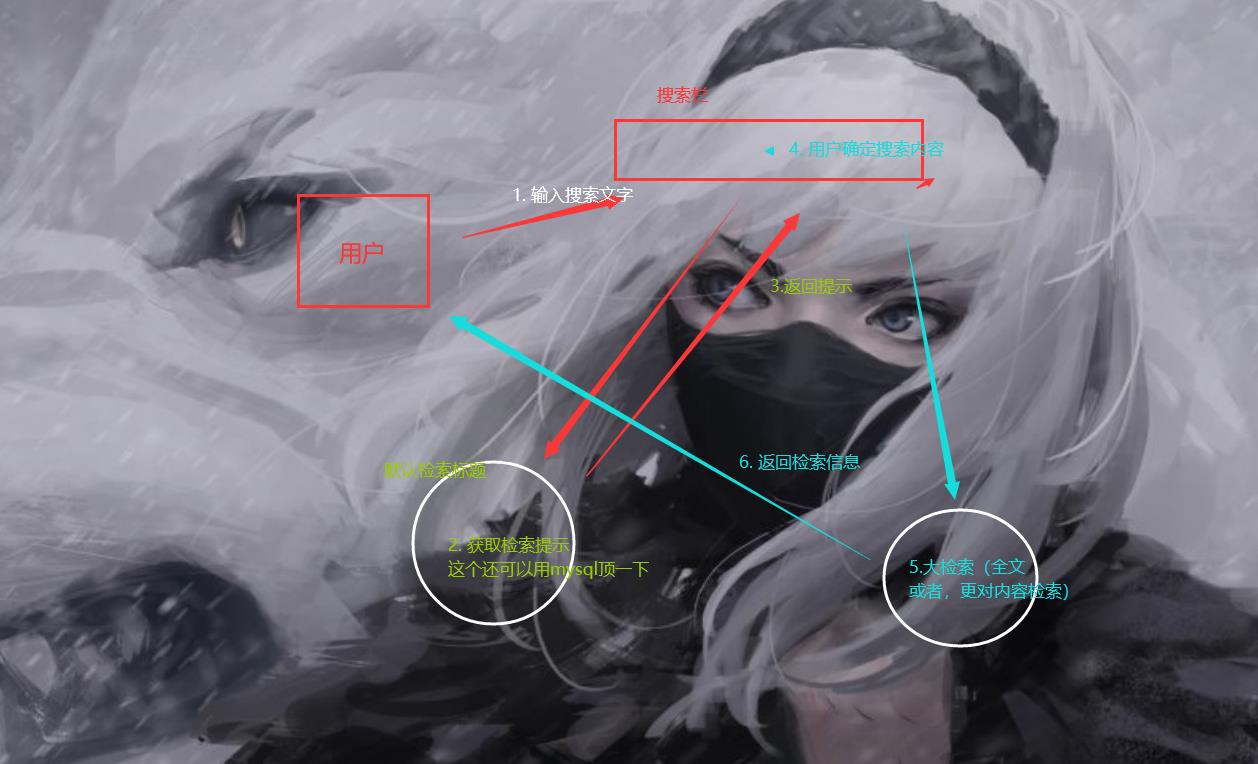
搜索
所以的话,我们其实是有两个接口的,那么接下来的就是全文检索的接口,这个接口比较特别的就是,我们需要做一个分页。那么对应分页,由于这个Sql比较复杂,因此我们还是手写SQL,那么这块的话,由于我们并不是需要展示全部的搜索结果,所以的话,完全没有必要做物理分页,那么我们就做一个逻辑分页,也就是内存分页。那么首先我们依然需要写sql.
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.huterox.whitehole.whiteholeblog.dao.BlogDao">
<!--sql-->
<select id="fullSearch" resultType="com.huterox.whiteholecould.entity.blog.BlogEntity">
SELECT *
FROM (SELECT * FROM blogs_blog WHERE status=1) as a
WHERE MATCH(blog_title) AGAINST (#key IN NATURAL LANGUAGE MODE)
ORDER BY fork_number DESC,collect_number DESC,like_number DESC, view_number DESC
Limit 0,#size
</select>
</mapper>
然后的话我们需要实现一个逻辑分页。
String key = blogSearchQ.getKey();
Integer page = blogSearchQ.getPage();
Integer limit = blogSearchQ.getLimit();
// 这里我们实现的逻辑分页,而不是物理分页,首先是物理分页要做两次查询,然后是,我们
// 匹配的结果不可能全部给用户展示出来的,
List<BlogEntity> blogEntities = blogDao.fullSearch(key,50);
int end = Math.min(page * limit, blogEntities.size());
List<BlogEntity> entities = blogEntities.subList((page - 1) * limit, end);
PageUtils pageUtils = new PageUtils(
entities,
blogEntities.size(),
limit,
page
);
return R.ok().put("page",pageUtils);
最多查询50条数据,然后分页给你。
然后这个PageUtis其实就是把MP的Ipage拿了过来,只是我这边重写了一些方法,所以做了提取。
public class PageUtils implements Serializable
private static final long serialVersionUID = 1L;
/**
* 总记录数
*/
private int totalCount;
/**
* 每页记录数
*/
private int pageSize;
/**
* 总页数
*/
private int totalPage;
/**
* 当前页数
*/
private int currPage;
/**
* 列表数据
*/
private List<?> list;
/**
* 分页
* @param list 列表数据
* @param totalCount 总记录数
* @param pageSize 每页记录数
* @param currPage 当前页数
*/
public PageUtils(List<?> list, int totalCount, int pageSize, int currPage)
this.list = list;
this.totalCount = totalCount;
this.pageSize = pageSize;
this.currPage = currPage;
this.totalPage = (int)Math.ceil((double)totalCount/pageSize);
/**
* 分页
*/
public PageUtils(IPage<?> page)
this.list = page.getRecords();
this.totalCount = (int)page.getTotal();
this.pageSize = (int)page.getSize();
this.currPage = (int)page.getCurrent();
this.totalPage = (int)page.getPages();
public int getTotalCount()
return totalCount;
public void setTotalCount(int totalCount)
this.totalCount = totalCount;
public int getPageSize()
return pageSize;
public void setPageSize(int pageSize)
this.pageSize = pageSize;
public int getTotalPage()
return totalPage;
public void setTotalPage(int totalPage)
this.totalPage = totalPage;
public int getCurrPage()
return currPage;
public void setCurrPage(int currPage)
this.currPage = currPage;
public List<?> getList()
return list;
public void setList(List<?> list)
this.list = list;
ElasticSearch 实现
okey,到了咱们的主角了,当然如果你觉得前面的就够了,大可不必用ES,我这个就是纯纯的怼技术栈了属于是。没办法你只要用了分布式,那么nacos,这种中间件, 分布式事务这种中间件,就是必不可少的,这些就是额外的硬件成本,如果在上ES,那么成本继续上升。
那么这里的话,我选择使用Elastic-Easy来实现。(其实Python早就有这种类型的ORM框架了,只有Java先前还在坚守半自动,少扯底层,容易扯到蛋,又不是没有提供原生API,自己调去)
那么在在这里的话,需要考虑的问题就是,我们需要同时把我们的这个数据进行更新到我们的ES当中,那么这里的更新也是两种方式,增量更新和全量更新。也就是当数据修改,插入是更新一下,或者,搞个定时任务,对MySQL里面的全部数据更新到ES当中。
那么这里对应的是三种解决方案,首先对于增量更新,我们肯定是异步的,对应全量,就分为两种喽,同步与异步。
这个的话,方案比较多,所以我选择不烧钱的方案,我们自己实现一个增量的更新。
环境配置
在此之前,如果你想要详细了解elastic-easy的话,那么可以查阅官方文档:https://www.easy-es.cn/pages/ec7460/
我们这边的话就只是用到了我们需要的东西,当然这边还是做演示哈。然后文档的话,没有覆盖到很多操作,如果你对于ES有了解的话,那么直接进入它的源码地址,里面的test有样例:https://gitee.com/dromara/easy-es
那么这里我们要做的非常简单,导入依赖:
<dependency>
<groupId>cn.easy-es</groupId>
<artifactId>easy-es-boot-starter</artifactId>
<version>1.0.2</version>
</dependency>
然后编写elastic的配置:
在你的application.yml当中
easy-es:
address: 66.6666.6666.66:9200
username: elastic #es用户名,若无则删去此行配置
password: 大年三十博主生日(狗头) #es密码,若无则删去此行配置
编码
这个非常简单,先写一个实体类,我这里的话是把博文的标题和博文的简介给搞进去了,博文内容的话,我没有搞进去,内容太多了。
我的实体类是这样的:
@Data
@IndexName("esblogmodel")
public class EsBlogModel
/**
* es中的唯一id
*/
private String id;
/**
* 文章标题
*/
@HighLight()
@IndexField(fieldType = FieldType.TEXT, analyzer = Analyzer.IK_SMART, searchAnalyzer = Analyzer.IK_MAX_WORD)
private String title;
/**
* 博文简介
*/
@HighLight()
@IndexField(fieldType = FieldType.TEXT, analyzer = Analyzer.IK_SMART, searchAnalyzer = Analyzer.IK_MAX_WORD)
private String info;
private Long blogid;
这里的话还做了一个高亮,如果是以前的话,看到那些API我就头大,边查文档边写可不好玩。
然后在创建一个Mapper。
@Component
public interface EsBlogModelMapper extends BaseEsMapper<EsBlogModel>
很多操作的话其实和MybatisPlus很像,作者也说了,就是仿造MP搞的。
然后记得别忘了在启动类,或者配置类,搞一个扫描路径。
xxxx
@EsMapperScan("xxxx.es.mapper")
public class WhiteholeBlogApplication
public static void main(String[] args)
SpringApplication.run(WhiteholeBlogApplication.class, args);
然后的话就可以先愉快的happy了。
查询与插入
其实这个,API接口和MP差不多,操作也类似,所以几乎我们不需要做太多工作。 插入非常简单:
EsBlogModel esBlogModel = new EsBlogModel();
esBlogModel.setBlogid(3L);
esBlogModel.setInfo("WhiteHole简介");
esBlogModel.setTitle("WhiteHole简介,白洞技术交流社区");
esBlogModelMapper.insert(esBlogModel);
这样做我就完成了插入,当然使用前我们需要注入:
EsBlogModelMapper esBlogModelMapper;
@Autowired
public void setEsBlogModelMapper(EsBlogModelMapper esBlogModelMapper)
this.esBlogModelMapper = esBlogModelMapper;
String indexName = "esblogmodel";
if(!esBlogModelMapper.existsIndex(indexName))
Boolean index = esBlogModelMapper.createIndex();
assert index;
不过这里的话其实就没必要使用这段代码了:
String indexName = "esblogmodel";
if(!esBlogModelMapper.existsIndex(indexName))
Boolean index = esBlogModelMapper.createIndex();
assert index;
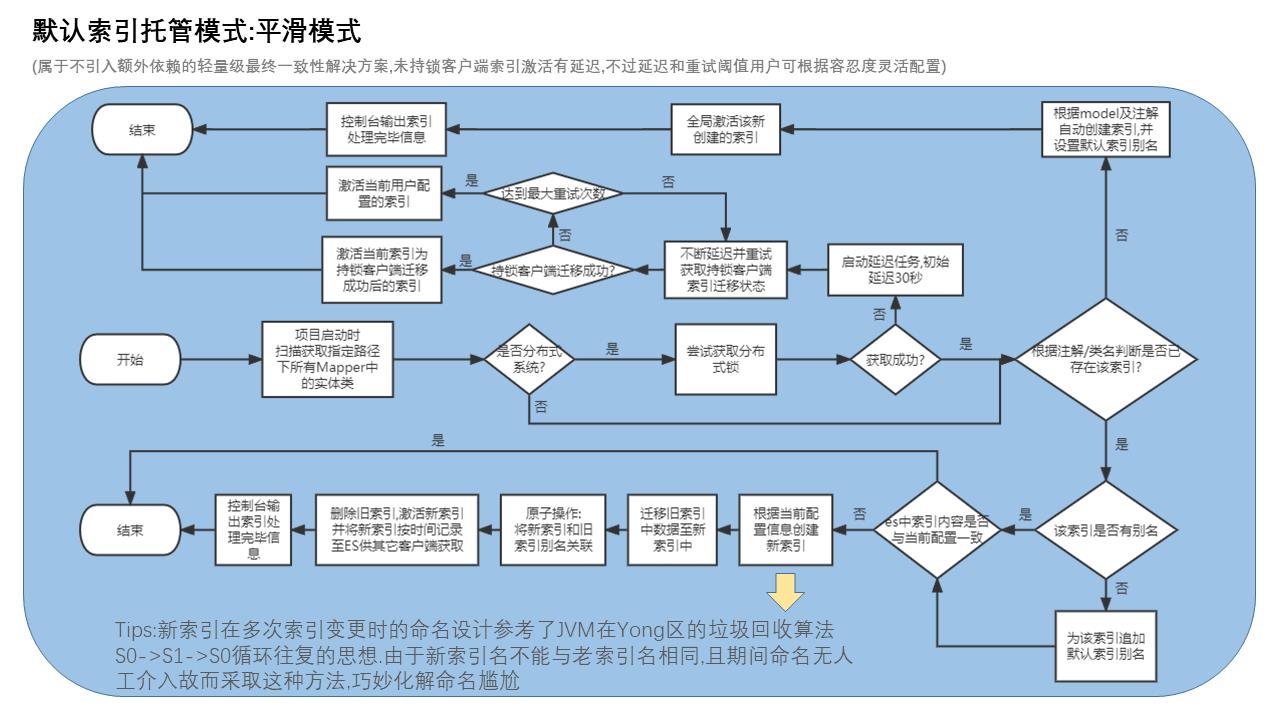
因为在insert的时候,如果没有它会自己创建,先前看文档的时候没看仔细,有个大图:
之后的话是查询,这个查询也是简单的:
LambdaEsQueryWrapper<EsBlogModel> esQueryWrapper = new LambdaEsQueryWrapper<>();
esQueryWrapper.multiMatchQuery(key,EsBlogModel::getTitle,EsBlogModel::getInfo);
esQueryWrapper.limit(50);
List<EsBlogModel> esBlogModels = esBlogModelMapper.selectList(esQueryWrapper);
return R.ok().put("list",esBlogModels);
最后的话我们做一个简单验证:
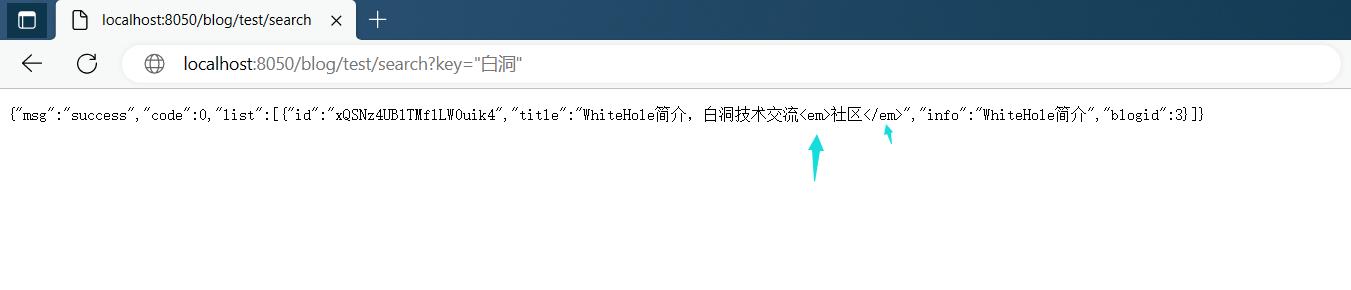
可以发现返回的结果也是有高亮的。
以上是关于双方案-基于Mysql 与 ElasticSearch实现关键词提示搜索与全文检索的主要内容,如果未能解决你的问题,请参考以下文章