系统学习深度学习(十六)--Overfeat
Posted Eason.wxd
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了系统学习深度学习(十六)--Overfeat相关的知识,希望对你有一定的参考价值。
转自:http://blog.csdn.net/hjimce/article/details/50187881
一、相关理论
本篇博文主要讲解来自2014年ICLR的经典图片分类、定位物体检测overfeat算法:《OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks》,至今为止这篇paper,已然被引用了几百次,把图片分类、定位、检测一起搞,可见算法牛逼之处非同一般啊。开始前,先解释一下文献的OverFeat是什么意思,只有知道了这个单词,我们才能知道这篇文献想要干嘛,OverFeat说的简单一点就是特征提取算子,就相当于SIFT,HOG等这些算子一样。Along with this paper, we release a feature extractor named “OverFeat”,这是文献对overfeat定义的原话。
这篇文献最牛逼的地方,在于充分利用了卷积神经网络的特征提取功能,它把分类过程中,提取到的特征,同时又用于定位检测等各种任务,牛逼哄哄啊。只需要改变网络的最后几层,就可以实现不同的任务,而不需要从头开始训练整个网络的参数。
其主要是把网络的第一层到第五层看做是特征提取层,然后不同的任务共享这个特征提取层。基本用了同一个网络架构模型(特征提取层相同,分类回归层根据不同任务稍作修改、训练)、同时共享基础特征。
二、计算机视觉的三大任务
开始讲解paper算法前,先让我们来好好学习一下计算机视觉领域中:分类、定位、检测这三者的区别。因为文献要一口气干掉这三个任务,所以先让我们需要好好区分一下这三个任务的区别:
A、图片分类:给定一张图片,为每张图片打一个标签,说出图片是什么物体,然而因为一张图片中往往有多个物体,因此我们允许你取出概率最大的5个,只要前五个概率最大的包含了我们人工标定标签(人工标定每张图片只有一个标签,只要你用5个最大概率,猜中其中就可以了),就说你是对的。
B、定位任务:你除了需要预测出图片的类别,你还要定位出这个物体的位置,同时规定你定位的这个物体框与正确位置差不能超过规定的阈值。
C、检测任务:给定一张图片,你把图片中的所有物体全部给我找出来(包括位置、类别)。
OK,解释完三个任务,我们接着就要正式开始学习算法了,我们先从最简单的任务开始讲起,然后讲定位,最后讲物体检测,分三大部分进行讲解。
三、Alexnet图片分类回顾
因为paper的网络架构方面与Alexnet基本相同,所以先让我们来好好回顾一下Alexnet的训练、测试:
(1)训练阶段:每张训练图片256*256,然后我们随机裁剪出224*224大小的图片,作为CNN的输入进行训练。
(2)测试阶段:输入256*256大小的图片,我们从图片的5个指定的方位(上下左右+中间)进行裁剪出5张224*224大小的图片,然后水平镜像一下再裁剪5张,这样总共有10张;然后我们把这10张裁剪图片分别送入已经训练好的CNN中,分别预测结果,最后用这10个结果的平均作为最后的输出。
overfeat这篇文献的图片分类算法,在训练阶段采用与Alexnet相同的训练方式,然而在测试阶段可是差别很大,这就是文献最大的创新点(overfeat的方法不是裁剪出10张224*224的图片进行结果预测平均,具体方法请看下面继续详细讲解)。
四、基础学习
开始讲解overfeat这篇文献的算法前,让我们先来学两招很重要的基础招式:FCN、offset max-pooling,等我们学完这两招,再来学overfeat这篇paper算法。
1、FCN招式学习
FCN又称全卷积神经网络,这招是现如今是图片语义分割领域的新宠(来自文献:《Fully Convolutional Networks for Semantic Segmentation》),同时也看懂overfeat这篇文献所需要学会的招式。
我们知道对于一个各层参数结构都设计好的网络模型来说,输入的图片大小是固定的,比如Alexnet设计完毕后,网络输入图片大小就是227*227。这个时候我们如果输入一张500*500的图片,会是什么样的结果?我们现在的希望是让我们的网络可以一直前向传导,让一个已经设计完毕的网络,也可以输入任意大小的图片,这就是FCN的精髓。FCN算法灵魂:
1、把卷积层-》全连接层,看成是对一整张图片的卷积层运算。
2、把全连接层-》全连接层,看成是采用1*1大小的卷积核,进行卷积层运算。
下面用一个例子,讲解怎么让一个已经设计好的CNN模型,可以输入任意大小的图片:
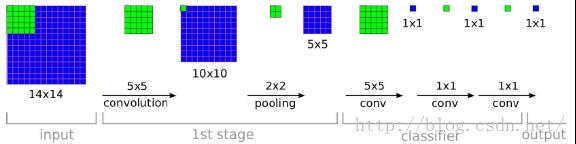
如上图所示,上面图中绿色部分表示:卷积核大小。假设我们设计了一个CNN模型,输入图片大小是14*14,通过第一层卷积后我们得到10*10大小的图片,然后接着通过池化得到了5*5大小的图片。OK,关键部分来了,接着要从:5*5大小的图片-》1*1大小的图片:
(1)传统的CNN:如果从以前的角度进行理解的话,那么这个过程就是全连接层,我们会把这个5*5大小的图片,展平成为一个一维的向量,进行计算(写cnn代码的时候,这个时候经常会在这里加一个flatten函数,就是为了展平成一维向量)。
(2)FCN:FCN并不是把5*5的图片展平成一维向量,再进行计算,而是直接采用5*5的卷积核,对一整张图片进行卷积运算。
其实这两个本质上是相同的,只是角度不同,FCN把这个过程当成了对一整张特征图进行卷积,同样,后面的全连接层也是把它当做是以1*1大小的卷积核进行卷积运算。
从上面的例子中,我们看到网络的输入是一张14*14大小的图片,这个时候加入我就用上面的网络,输入一张任意大小的图片,比如16*16大小的图片,那么会是什么样的结果?具体请看下面的示意图:
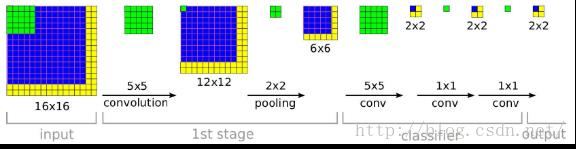
这个时候你就会发现,网络最后的输出是一张2*2大小的图片。这个时候,我们就可以发现采用FCN网络,可以输入任意大小的图片。同时需要注意的是网络最后输出的图片大小不在是一个1*1大小的图片,而是一个与输入图片大小息息相关的一张图片了。
OK,这个时候我们回来思考一个问题,比如Alexnet网络设计完毕后,我们也用FCN的思想,把全连接层看成是卷积层运算,这个时候你就会发现如果Alexnet输入一张500*500图片的话,那么它将得到1000张10*10大小的预测分类图,这个时候我们可以简单采用对着每一张10*10大小的图片求取平均值,作为图片属于各个类别的概率值。
其实Alexnet在测试阶段的时候,采用了对输入图片的四个角落进行裁剪,进行预测,分别得到结果,最后的结果就是类似对应于上面2*2的预测图。这个2*2的每个像素点,就类似于对应于一个角落裁剪下来的图片预测分类结果。只不过Alexnet把这4个像素点,相加在一起,求取平均值,作为该类别的概率值。
需要注意的是,一会儿overfeat就是把采用FCN的思想把全连接层看成了卷积层,让我们在网络测试阶段可以输入任意大小的图片。
2、offset max-pooling
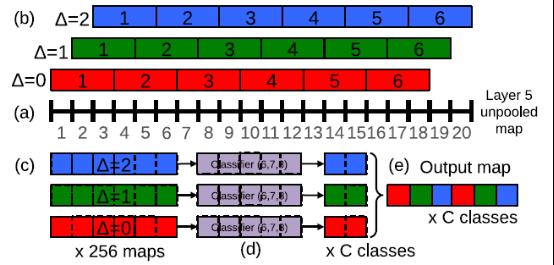
再让我们来学习一招大招,这一招叫offset 池化。为了简单起见,我们暂时不用二维的图像作为例子,而是采用一维作为示例,来讲解池化:

如上图所示,我们在x轴上有20个神经元,如果我们选择池化size=3的非重叠池化,那么根据我们之前所学的方法应该是:对上面的20个,从1位置开始进行分组,每3个连续的神经元为一组,然后计算每组的最大值(最大池化),19、20号神经元将被丢弃,如下图所示:

我们也可以在20号神经元后面,人为的添加一个数值为0的神经元编号21,与19、20成为一组,这样可以分成7组:[1,2,3],[4,5,6]……,[16,17,18],[19,20,21],最后计算每组的最大值,这就是我们以前所学CNN中池化层的源码实现方法了。
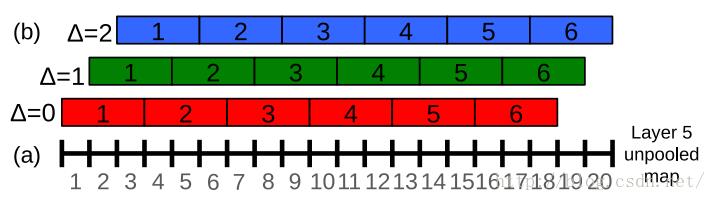
上面我们说到,如果我们只分6组的话,我们除了以1作为初始位置进行连续组合之外,也可以从位置2或者3开始进行组合。也就是说我们其实有3种池化组合方法:
A、△=0分组:[1,2,3],[4,5,6]……,[16,17,18];
B、△=1分组:[2,3,4],[5,6,7]……,[17,18,19];
C、△=2分组:[3,4,5],[6,7,8]……,[18,19,20];
对应图片如下:
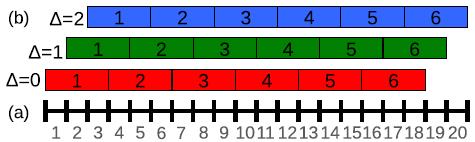
以往的CNN中,一般我们只用了△=0,得到池化结果后,就送入了下一层。于是文献的方法是,把上面的△=0、△=1、△=2的三种组合方式的池化结果,分别送入网络的下一层。这样的话,我们网络在最后输出的时候,就会出现3种预测结果了。
我们前面说的是一维的情况,如果是2维图片的话,那么(△x,△y)就会有9种取值情况(3*3);如果我们在做图片分类的时候,在网络的某一个池化层加入了这种offset 池化方法,然后把这9种池化结果,分别送入后面的网络层,最后我们的图片分类输出结果就可以得到9个预测结果(每个类别都可以得到9种概率值,然后我们对每个类别的9种概率,取其最大值,做为此类别的预测概率值)。
OK,学完了上面两种招式之后,文献的算法,就是把这两种招式结合起来,形成了文献最后测试阶段的算法,接着我们就来讲讲怎么结合。
五、overfeat图片分类
我们先从文献是怎么搞图片分类的开始说起,训练阶段基本变化不大,最大的区别在于网络的测试阶段。
1、paper网络架构与训练阶段
(1)网络架构
对于网络的结构,文献给出了两个版本,快速版、精确版,一个精度比较高但速度慢;另外一个精度虽然低但是速度快。下面是高精度版本的网络结构表相关参数:
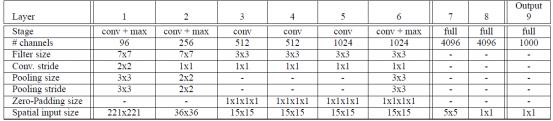
表格参数说明:
网络输入:从上面的表格,我们知道网络输入图片大小为221*221;
网络结构方面基本上和AlexNet是一样的,也是使用了ReLU激活,最大池化。不同之处在于:(a)作者没有使用局部响应归一化层;(b)然后也没有采用重叠池化的方法;(c)在第一层卷积层,stride作者是选择了2,这个与AlexNet不同(AlexNet选择的跨步是4,在网络中,如果stride选择比较大得话,虽然可以减少网络层数,提高速度,但是却会降低精度)。
这边需要注意的是我们需要把f7这一层,看成是卷积核大小为5*5的卷积层,总之就是需要把网络看成我们前面所学的FCN模型,没有了全连接层的概念,因为在测试阶段我们可不是仅仅输入221*221这样大小的图片,我们在测试阶段要输入各种大小的图片,具体请看后面测试阶段的讲解。
补充(http://blog.csdn.net/mao_kun/article/details/50571766):
3.1 参数设置
提取221*221的图片,batch大小,权值初始值,权值惩罚项,初始学习率和Alex-net一样。不同地方时就动量项权重从0.9变为0.6;在30, 50, 60, 70, 80次迭代后,学习率每次缩减0.5倍。
3.2模型设计
作者提出了两种模型,fast模型和accurate模型。
Fast模型:
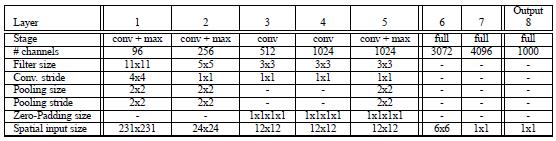
Input(231,231,3)→96F(11,11,3,s=4)→max-p(2,2,s=2)→256F(5,5,96,1) →max-p(2,2,2) →512F(3,3,512,1) →1024F(3,3,1024,1) →1024F(3,3,1024) →max-p(2,2,2) →3072fc→4096fc→1000softmax
Fast模型改进:
1,不使用LRN;
2,不使用over-pooling使用普通pooling;
3,第3,4,5卷基层特征数变大,从Alex-net的384→384→256;变为512→1024→1024.
4,fc-6层神经元个数减少,从4096变为3072
5,卷积的方式从valid卷积变为维度不变的卷积方式,所以输入变为231*231
Accurate模型改进:
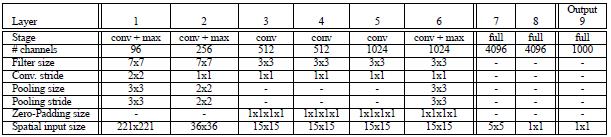
Input(231,231,3)→96F(7,7,3,s=2)→max-p(3,3,3)→256F(7,7,96,1)→max-p(2,2,2) →512F(3,3,512,1) →512F(3,3,512,1) →1024F(3,3,1024,1) →1024F(3,3,1024,1) →max-p(3,3,3) →4096fc→4096fc→1000softmax
1,不使用LRN;
2,不使用over-pooling使用普通pooling,更大的pooling间隔S=2或3
3,第一个卷基层的步长从4变为2(accurate 模型),卷积大小从11*11变为7*7;第二个卷基层filter从5*5升为7*7
4,增加了一个卷积层,变为6层;从Alex-net的384→384→256;变为512→512→1024→1024.
两个模型参数和连接数目对比:
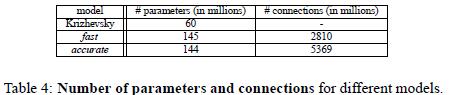
每层参数个数:=特征数M*每个filter大小(filter_x*filter_y*连接特征数(由于本文是全连接,所以连接特征数就等于前一层特征个数))没有把bias计算在内。
|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Fast | 3.5万 | 61 | 118 | 0 | 472 | 944 | 11324 | 1678 | 409 |
| Accurate | 1.4万 | 120 | 118 | 236 | 472 | 944 | 10485 | 1678 | 409 |
通过计算发现,连接方式,特征数目,filter尺寸是影响参数个数的因素;
1连接方式是关键因素,例如主要参数都分布在全连接层;
2最后一个卷积层特征图的大小也是影响参数个数的关键,例如第七层fast模型的特征图为6*6; accurate模型的输入特征为5*5,所以尽管accurate比fast多了1024个全连接神经元,但是由于输入特征图相对较小,多所以本层两个模型的参数差的不多。所以最后一个卷基层特征图大小对参数影响较大。
-----------------------------------------------------------------------------------------------------
(2)网络训练
训练输入:对于每张原图片为256*256,然后进行随机裁剪为221*221的大小作为CNN输入,进行训练。
优化求解参数设置:训练的min-batchs选择128,权重初始化选择高斯分布的随机初始化:
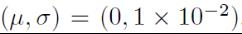
然后采用随机梯度下降法,进行优化更新,动量项参数大小选择0.6,L2权重衰减系数大小选择10-5次方。学习率一开始选择0.05,然后根据迭代次数的增加,每隔几十次的迭代后,就把学习率的大小减小一半。
然后就是DropOut,这个只有在最后的两个全连接层,才采用dropout,dropout比率选择0.5,也就是网络的第6、7层。
2、网络测试阶段
这一步需要声明一下,网络结构在训练完后,参数的个数、结构是固定的,而这一步的算法并没有改变网络的结构,也更不可能去改变网络参数。
我们知道在Alexnet的文献中,他们预测的方法是输入一张图片256*256,然后进行multi-view裁剪,也就是从图片的四个角进行裁剪,还有就是一图片的中心进行裁剪,这样可以裁剪到5张224*224的图片。然后把原图片水平翻转一下,再用同样的方式进行裁剪,又可以裁剪到5张图片。把这10张图片作为输入,分别进行预测分类,然后在softmax的最后一层,求取个各类的总概率,求取平均值。
然而Alexnet这种预测方法存在两个问题:首先这样的裁剪方式,把图片的很多区域都给忽略了,说不定你这样的裁剪,刚好把图片物体的一部分给裁剪掉了;另外一方面,裁剪窗口重叠存在很多冗余的计算,像上面我们要分别把10张图片送入网络,可见测试阶段的计算量还是蛮大的。
Overfeat算法:训练完上面所说的网络之后,在测试阶段,我们不再是用一张221*221大小的图片了作为网络的输入,而是用了6张大小都不相同的图片,也就是所谓的多尺度输入预测,如下表格所示:
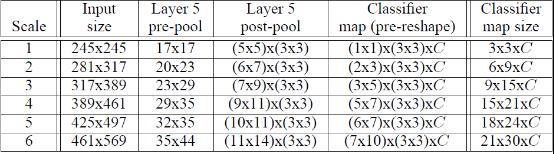
测试阶段网络输入图片大小分别是245*245,281*317……461*569。
然后当网络前向传导到layer 5的时候,就使出了前面我们所讲的FCN、offset pooling这两招相结合的招式。在这里我们以输入一张图片为例(6张图片的计算方法都相同),讲解layer 5后面的整体过程,具体流程示意图如下:
从layer-5 pre-pool到layer-5 post-pool:这一步的实现是通过池化大小为(3,3)进行池化,然后△x=0、1、2,△y=0、1、2,这样我们可以得到对于每一张特征图,我们都可以得到9幅池化结果图。以上面表格中的sacle1为例,layer-5 pre-pool大小是17*17,经过池化后,大小就是5*5,然后有3*3张结果图(不同offset得到的结果)。
从layer-5 post-pool到classifier map(pre-reshape):我们知道在训练的时候,从卷积层到全连接层,输入的大小是4096*(5*5),然后进行全连接,得到4096*(1*1)。但是我们现在输入的是各种不同大小的图片,因此接着就采用FCN的招式,让网络继续前向传导。我们从layer-5 post-pool到第六层的时候,如果把全连接看成是卷积,那么其实这个时候卷积核的大小为5*5,因为训练的时候,layer-5 post-pool得到的结果是5*5。因此在预测分类的时候,假设layer-5 post-pool 得到的是7*9(上面表格中的scale 3),经过5*5的卷积核进行卷积后,那么它将得到(7-5+1)*(9-5+1)=3*5的输出。
然后我们就只需要在后面把它们拉成一维向量摆放就ok了,这样在一个尺度上,我们可以得到一个C*N个预测值矩阵,每一列就表示图片属于某一类别的概率值,然后我们求取每一列的最大值,作为本尺度的每个类别的概率值。
最后我们一共用了6种不同尺度(文献好像用了12张,另外6张是水平翻转的图片),做了预测,然后把这六种尺度结果再做一个平均,作为最最后的结果。
OK,至此overfeat图片分类的任务就结束了,从上面过程,我们可以看到整个网络分成两部分:layer 1~5这五层我们把它称之为特征提取层;layer 6~output我们把它们称之为分类层。
六、定位任务
后面我们用于定位任务的时候,就把分类层(上面的layer 6~output)给重新设计一下,把分类改成回归问题,然后在各种不同尺度上训练预测物体的bounding box。
我们把用图片分类学习的特征提取层的参数固定下来,然后继续训练后面的回归层的参数,网络包含了4个输出,对应于bounding box的上左上角点和右下角点,然后损失函数采用欧式距离L2损失函数。
参考文献:
1、《Fully Convolutional Networks for Semantic Segmentation》
2、《OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks》
补充:http://blog.csdn.net/seavan811/article/details/49825891
亮点1:多尺度-classification
通常的分类是给了一个东西,然后判定类别,但是给了一张图,不知道东西在哪该如何分类?所以一般的方法是“金字塔+sliding window”结构,然后对每一个window做一次分类。这样的算法是非常耗时的,作者认为,不需要sliding window的过程,我们可以在同一个网络里面完成。这里插一句:为什么不用直接输入图像就给出类别呢?那是因为像ImageNet这样的数据,主要的物体是在图像中央,并且大小是填充了图像相当大的部分的,所以就算是有一些variation,那也是CNN能handle的,但是如果在测试中物体只是一个很小尺寸,并且出现在图像的一个角落,那么这个variation对于训练数据来说是完全impossible的。所以直接CNN分类的效果会很差。除非训练数据覆盖了各种尺寸和位置,当然这是non-sense的。那么这篇文章是怎么实现的呢?在原图上滑窗是笨拙的,那么就在输出的feature map上滑。
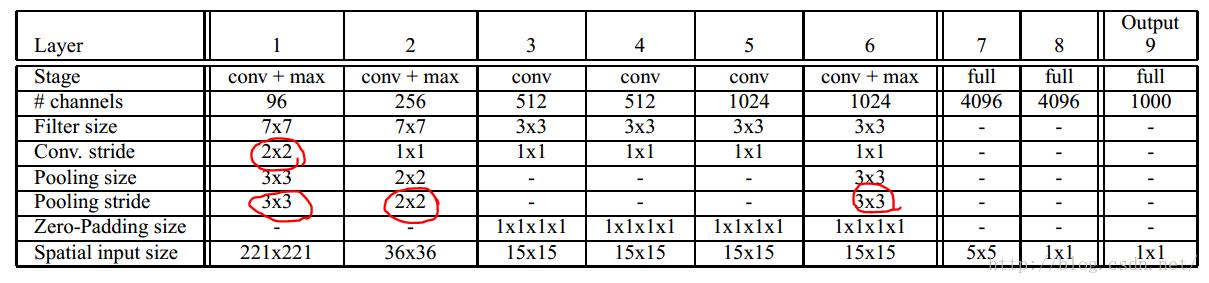
我们从网络入手,红色标记的stride表示的就相当于对原图降采样,所以才会有作者说的:“However, thetotal subsampling ratio in the network described above is 2x3x2x3, or 36.”那么对于221*221的图像来说,通过了前面的conv+pooling就瞬间变成了6*6了。现在可以开心的在这个feature map上做滑动了。可以看到layer7(第一个fc层)的输入是5*5的,也就是说用这个5*5的窗口去6*6的上面滑,就可以得到2*2的窗口了,每一个窗口对应一个位置,将这4个5*5的作为输入,分别输入fc,这样就可以得到4个C向量,C代表要分的1000个类。炫酷吧。这样实现了一个coarse滑窗。
但是作者觉得不够,这样的不够精细,*36倍呢。所以想到了一个offset的方法(灵感来自Ref【9】),参考下面图
然后作者还是觉得不够,就在输入图像就做了手脚,又从Ref【15】里面得到灵感,【15】将图像做了crop,四个corner,加一个中间,总共变成了5个子图像,然后对图像进行翻转,这样就变成了10个图像。本文作者不知道为什么采用的是“We then extract 5 random crops(and their horizontal flips)”不过核心思想是一样的,这样sliding window又变多了。
作者最后还做了一个scale上的变换,这个就没什么好说的了,把图像放缩到6个尺度上,所以,最终,这个多尺度的滑窗思想就得到实现了。
得到了那么多的窗口,就有那么多的classification结果,平均一下概率值,就可以得到最终的classification结果了。其实有了那么多的结果也未必是好事,融合结果会导致有些尺度上的强响应会丢失。不过鲁棒性会变好。我们来看看分类的结果
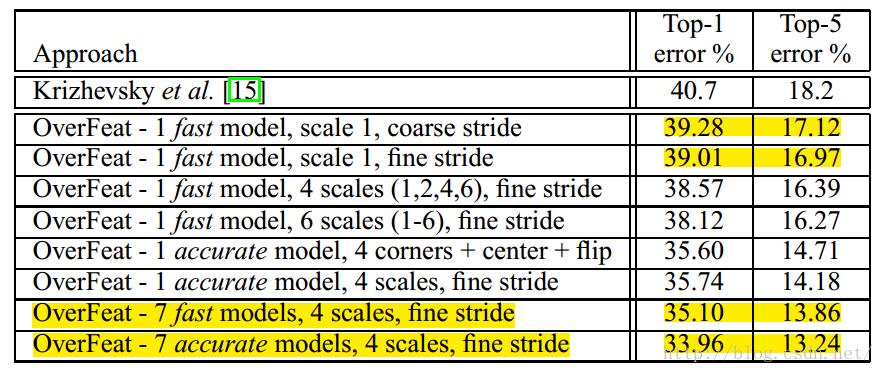
从结果来看,整体是变好了的,主要应该还是因为sliding window和scale的功劳。至于那个offset的改进,从第3,4行来看,好像并没有什么大的提升,说明差这几个像素,对于不停做convolution的图像来说,真的没啥影响(个人理解:池化层原本的作用就是提取特征的仿射不变性,所以,在经过多层次的卷积后,已经与物体原始位置无精确关系,因此,不觉得offset 池化有多少实际作用)。另外最后看到多模型的融合,这还是王道啊。侧面也说明了,这样的模型的学习和样本的影响在深度学习中还是有很多问题的,不稳定。
亮点2:多任务
上面说完了classification,localization就简单多了,反正就是在刚才那个架构上去regression出四个参数,表达box的四个角。输出了再combine一下,总的来说就没有什么新意了。Detection就更没什么说的了,连作者都懒得说了。
-
同时做了多个任务,这个做法我有一些看法,就是多任务一起做到底是好还是坏?我没有定论,个人感觉是要看任务的相关性,比如说classification和localization,classification会帮助提取物体自身的feature,而打破了纯粹的localization中的combined context的影响,当然这个还是要看样本的选择。当然这个还需要今后进一步的去论证。
-
滑窗,利用feature map来避免大量的sliding window,个人感觉肯定只是在原始图像上做sliding window的一种折衷方案,毕竟太耗时了。不过方法还是有一定的启发的,不知道什么时候能出一个好的解决框架。
-
多模型,多尺度,没什么说的,踏踏实实的好东西
讨论
-
“打破了纯粹的localization中的combined context的影响“?
—— 做localization实际项目时,一般物体都是处于图像的某个小区域,所以对全图做训练很容易把物体和经常出现的context combine在一起,这样一旦样本不够充分,就很容易学出combine在一起的context特征而不是单纯的object特征。 -
如果我是用原图做多scale的滑窗,和现在这个方法在feature map上做sliding window比,哪个性能好?
—— 这个没有具体的对比试验佐证,但是在最后输出的feature map上做sliding window,更像是选取了相应更好的特征区域,所以和在原图上做sliding window是不同的,从感觉上来说,对于classification这个任务来说应该是更好的,因为它打破了bounding box的约束,更好的“包含”了好的特征。另外,因为max pooling的非线性操作,所以不可能往回找到sliding window在原图上的位置 - 再插一句,如果最后出来的36个vector,直接全部fc,而不是做平均,估计效果会更好,只是怕参数量太大了。这样样本的需求也太大。不过如果这样直接连接FC层的话,才会更好的体现end-to-end的精神。
补充2:http://blog.csdn.net/whiteinblue/article/details/43374195
四 定位
基于训练的分类网络,用一个回归网络替换分类器网络;并在各种缩放比例和view下训练回归网络来预测boundingbox;然后融合预测的各个bounding box。
4.1 生成预测
同时在各个view和缩放比例下计算分类和回归网络,分类器对类别c的输出作为类别c在对应比例和view出现的置信分数;
4.2 回归训练
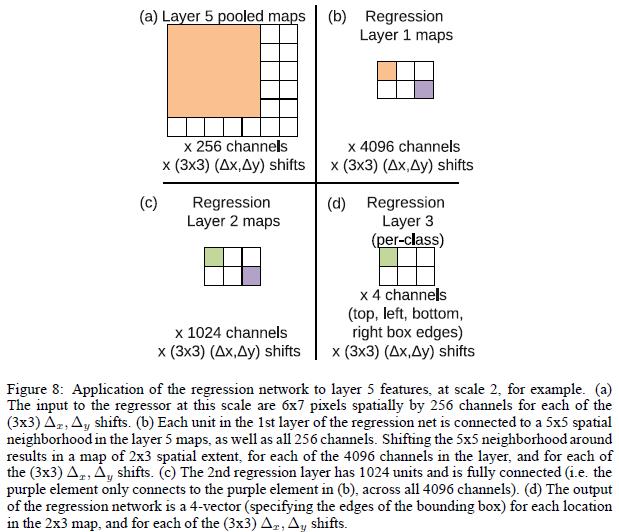
如上图所示,每个回归网络,以最后一个卷积层作为输入,回归层也有两个全连接层,隐层单元为4096,1024(为什么作者没有说,估计也是交叉实验验证的),最后的输出层有4个单元,分别是预测bounding box的四个边的坐标。和分类使用offset-pooling一样,回归预测也是用这种方式,来产生不同的预测结果。
使用预测边界和真实边界之间的L2范数作为代价函数,来训练回归网络。最终的回归层是一个类别指定的层,有1000个不同的版本。训练回归网络在多个缩放比例下对于不同缩放比例融合非常重要。在一个比例上训练网络在原比例上表现很好,在其他比例上也会表现的很好;但是多个缩放比例训练让预测在多个比例上匹配更准确,而且还会指数级别的增加预测类别的置信度。

上图展示了在单个比例上预测的在各个offset和sliding window下 pooling后,预测的多个bounding box;从图中可以看出本文通过回归预测bounding box的方法可以很好的定位出物体的位置,而且bounding box都趋向于收敛到一个固定的位置,而且还可以定位多个物体和同一个物体的不同姿势。但是感觉offset和sliding window方式,通过融合虽然增加了了准确度,但是感觉好复杂;而且很多的边框都很相似,感觉不需要这么多的预测值。就可以满足超过覆盖50%的测试要求。
4.3结合预测
a)在6个缩放比例上运行分类网络,在每个比例上选取top-k个类别,就是给每个图片进行类别标定Cs
b)在每个比例上运行预测boundingbox网络,产生每个类别对应的bounding box集合Bs
c)各个比例的Bs到放到一个大集合B
d)融合bounding box。具体过程应该是选取两个bounding box b1,b2;计算b1和b2的匹配分式,如果匹配分数大于一个阈值,就结束,如果小于阈值就在B中删除b1,b2,然后把b1和b2的融合放入B中,在进行循环计算。
最终的结果通过融合具有最高置信度的bounding box给出。
具体融合过程见下图:
1,不同的缩放比例上,预测结果不同,例如在原始图像上预测结果只有熊,在放大比例后(第三,第四个图),预测分类中不仅有熊,还有鲸鱼等其他物体

2通过offset和sliding window的方式可以有更多的类别预测

3在每个比例上预测bounding box,放大比例越大的图片,预测的bounding box越多

4,融合bouding box

在最终的分类中,鲸鱼预测和其他的物体消失不仅使因为更低的置信度,还有就是他们的bounding box集合Bs不像熊一样连续,具有一致性,从而没有持续的置信度积累。通过这种方式正确的物体持续增加置信度,而错误的物体识别由于缺少bounding box的一致性和置信度,最终消失。这种方法对于错误的物体具有鲁棒性(但是图片中确实有一些鱼,虽然不是鲸鱼;但是系统并没有识别出来;也可能是类别中有鲸鱼,但是没有此种鱼的类别)。
4.4实验
本文多个multi-scale和multi-view的方式非常关键,multi-view降低了4%,multi-scale降低了6%。令人惊讶的是本文PCR的结果并没有SCR好,原因是PCR的有1000个模型,每个模型都是用自己类别的数据来进行训练,训练数据不足可能导致欠拟合。而SCR通过权值共享,得到了充分的训练。
五,检测
检测和分类训练阶段相似,但是是以空间的方式进行;一张图片中的多个位置可能会同时训练。和定位不通过的是,图片内没有物体的时候,需要预测背景。
这个地方由于作者叙述的有些简略,没怎么看懂;本文的方法在ILSVRC中获得了19%,在赛后改进到24.3%;赛后主要是使用更长的训练时间和利用“周围环境”(每一个scale也同时使用低像素scale作为输入;介个有点不明白)。
六,总结
1,multi-scale sliding window方式,用来分类,定位,检测
2,在一个卷积网络框架中,同时进行3个任务
本文还可以进一步改进,
1,在定位实验总,没有整个网络进行反向传播训练
2,用评价标准的IOU作为损失函数,来替换L2
3,交换bounding box的参数,帮助去掉结果的相关性(这个有点不明白)。
后来工作2被牛津大学作者做了出来。
一些困惑和理解
感觉卷积网络真的好强大,干啥都行,而且还能相互间共享特征;虽然分类,定位,和检测的难度是递增的,但是感觉分类是最基础的,分类结果的好坏决定了后面两个任务的好坏,因为图片中物体分类准确了,才能进行定位和检测;在分类阶段调整网络部分并没有过多的叙述原因,只是给出了最后的网络结构,通过暴力式的增加复杂度,提取更多信息。
本文multi-scale测试的处理方式和SPP-net(下一篇博文)的方式有些不同,本文是通过multi-view的方式采用滑窗的方式产生多个数据结果,而Spp-net通过改变子采样比例,来得到固定的特征层输出。感觉本文的滑窗方式更适合预测bounding box和detection;因为这种方式可以是物体和view很好的匹配,从而得到很好置信得分,但是还是感觉有些复杂,例如offset是否可以使用两个,sliding window感觉可以像Alex-net那样采用5-view的方式,在特征图中选取上下左右和中间5个view进行预测就可以了,因为pooling的特征具有聚集性,感觉每个view会有很大的相似性。
图中对熊的定位实例中,卷积网络在不同的scale上面会得到不同的分类结果,在联合上一篇博文中两位作者对平移,缩放和翻转不变形的探讨;卷积网络的优势就是对于平移具有不变形,但是感觉对于平移和缩放的识别能力是有限的,对于大的物体能够很好的识别,对于小的物体感觉网络有些乏力,这可能也就是为什作者在multi-scale时,从来都是放大而不是缩小;还有就是感觉和每个高层对应底层的感受野有关,例如才本文中一个layer-5的特征激活值,对应输入层图像36*36的一个小区域,如果物体比36*36区域小,或者稍微大一些;感觉网络就会识别困难。感觉后面GoogLeNet,里面的Inception模型,就和这个有关系,不同的filter和pooling可以对应不同的初始感受野(个人观点)。
另外,再补充一个overfeat 基于torch7的测试demo,有基础的论文实现。(没有offset 池化)
https://github.com/soumith/overfeat-torch
所以,Overfeat实际的贡献在于:
1.多任务实现,再不改变基础网络的前提下,实现分类,定位,检测视觉任务。
2.证明多视野训练,多尺度测试的有效性
3.FCN的有效利用。
4.offset 池化,后来在其他模型中很少见到。个人认为实际帮助不大。
5.PCR和SCR效果对比,也不能作为最终定论。
6.注意,定位问题,只调整FC层,这与后面VGG调整全层有差异。后者证明调整全层效果更好。
以上是关于系统学习深度学习(十六)--Overfeat的主要内容,如果未能解决你的问题,请参考以下文章