机器学习-对数几率回归(逻辑回归)算法
Posted 吾仄lo咚锵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习-对数几率回归(逻辑回归)算法相关的知识,希望对你有一定的参考价值。
文章目录
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。
简介
对数几率回归(Logistic Regression),也称逻辑回归,虽然名字中含有回归,但其实是一种分类算法。找一个单调可微函数将分类任务中的真实标记与线性回归模型的预测值联系起来,是一种广义线性回归。
比如给定身高和体重数据,通过线性回归算法训练模型后,可以得到身高体重的回归方程,从而得到预测值。
现需要根据身高体重来判断胖瘦,即二分类任务,也就是要根据回归方程来转换成分类,定义激活函数,转为0~1之间的值,即对数几率回归的输入就是线性回归的输出—— z = w T x + b z=\\bold w^T\\bold x+ b z=wTx+b。
通过属于某个类别的概率值来判断是否属于该类别,比如设定大于0.5则判为该类别,定义损失函数和优化算法对模型进行训练。
线性回归可参考::回归-线性回归算法(房价预测项目)
激活函数
激活函数就是将预测值
z
=
w
T
x
+
b
z=\\bold w^T\\bold x+ b
z=wTx+b转换为0/1值。
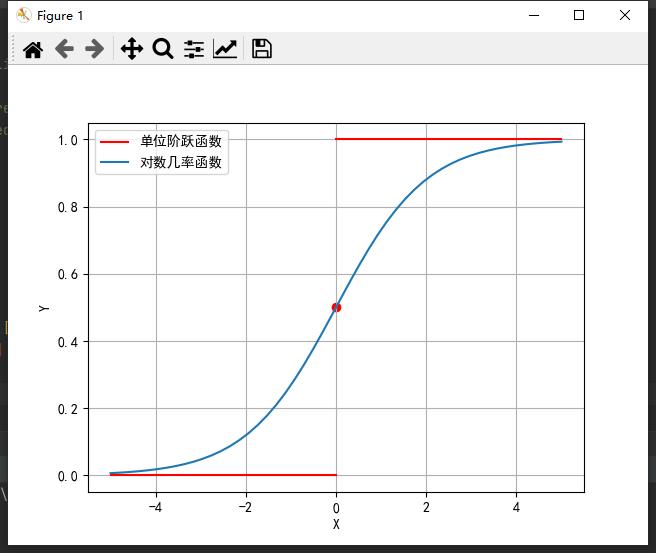
最理想的就是单位阶跃函数:
KaTeX parse error: No such environment: align* at position 7: \\begin̲a̲l̲i̲g̲n̲*̲̲\\beginsplity=…
但是单位阶跃函数并不连续,我们需要找到一个单调可微的函数,在一定程度上尽量接近单位阶跃函数,而对数几率函数(Sigmoid函数)就能很好的近似。
y
=
1
1
+
e
−
z
y=\\frac11+e^-z
y=1+e−z1
两者图像如下:
将
z
=
w
x
+
b
z=\\bold w\\bold x+ b
z=wx+b带入Sigmoid函数中,有
y
=
h
(
w
T
x
)
=
1
1
+
e
−
(
w
T
x
+
b
)
y=h(w^Tx)=\\frac11+e^-(w^Tx+b)
y=h(wTx)=1+e−(wTx+b)1
l n y 1 − y = w T x + b … ① ln\\fracy1-y=w^Tx+b \\dots① ln1−yy=wTx+b…①
y就是正例,1-y是反例,两者比值称为几率,再取对数ln,故得名对数几率函数。
损失函数
损失函数是定义了预测标记和真实标记的误差,在逻辑回归中,我们希望每个样本属于其真实标记的概率越大越好,使用对数似然损失。
将
y
y
y视为后验概率估计
p
(
y
=
1
∣
x
)
p(y=1|x)
p(y=1∣x),带入式①,有
p
(
y
=
1
∣
x
)
=
h
(
w
T
x
)
p
(
y
=
0
∣
x
)
=
1
−
h
(
w
T
x
)
p(y=1|x)=h(w^Tx)\\\\p(y=0|x)=1-h(w^Tx)
p(y=1∣x)=h(wTx)p(y=0∣x)=1−h(wTx)
使用极大似然法,利用已知的样本的真实标记,反推最大概率导致这样的结果的参数值。
通过分布律求极大似然函数:
L
(
y
i
∣
x
i
,
w
)
=
∏
i
=
1
m
h
(
w
T
x
)
y
i
(
1
−
h
(
w
T
x
)
)
1
−
y
i
L(y_i|x_i,w)=\\prod_i=1^mh(w^Tx)^y_i(1-h(w^Tx))^1-y_i
L(yi∣xi,w)=i=1∏mh(wTx)yi(1−h(wTx))1−yi
取对数后,得到对数似然函数:
L
(
y
i
∣
x
i
,
w
)
=
∑
i
=
1
m
y
i
l
o
g
(
h
(
w
T
x
)
)
+
(
1
−
y
i
)
l
o
g
(
1
−
h
(
w
T
x
)
)
L(y_i|x_i,w)=\\sum_i=1^my_ilog(h(w^Tx))+(1-y_i)log(1-h(w^Tx))
L(yi∣xi,w)=i=1∑myilog(h(wTx))+(1−yi)log(1−h(wTx))
由于log函数在(0,1)区间内是负的,我们乘以-1,使最终损失函数为正:
J
(
w
)
=
∑
i
=
1
m
−
y
i
l
o
g
(
h
(
w
T
x
)
)
−
(
1
−
y
i
)
l
o
g
(
1
−
h
(
w
T
x
)
)
J(w)=\\sum_i=1^m-y_ilog(h(w^Tx))-(1-y_i)log(1-h(w^Tx))
J(w)=i=1∑m−yilog(h(wTx))−(1−yi)log(1−h(wTx))
(
插播反爬信息)博主CSDN地址:https://wzlodq.blog.csdn.net/
优化算法
得到损失函数的定义后,我们期望损失越小越好,即使 J ( w ) = 0 J(w)=0 J(w)=0,可以牛顿法、梯度下降法等求得最优解。
梯度下降可参考::浅谈梯度下降与模拟退火算法
使用梯度下降对w求偏导:
∂ J ∂ w = ∑ i = 1 m ( y i − h ( w T x i ) ) x i \\frac\\partial J\\partial w=\\sum_i=1^m(y_i-h(w^Tx_i))x_i ∂w∂J=i=1∑m(yi−h(wTxi))xi
然后更新
w
w
w得到
w
∗
w^*
w∗即可:
w
∗
=
w
−
η
∂
J
∂
w
w^*=w-\\eta\\frac\\partial J\\partial w
w∗=w−η∂w∂J
代码
使用sklearn库LgisticRegression()函数。
项目一、鸢尾花:
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# 数据处理
iris = datasets.load_iris() # 载入鸢尾花数据集
x = iris.data[:100, ] # 取前100行(二分类
y = iris.target[0:100]
x_train, x_test, y_train, y_test = train_test_split(x, y) # 划分训练集测试集
# 创建逻辑回归模型
estimator = LogisticRegression()
# 模型训练
estimator.fit(x_train, y_train)
# 预测
y_pred = estimator.predict(x_test)
print("预测值:", y_pred)
# 模型评估
print('准确率:%.3f' % estimator.score(x_test, y_test))
# 可视化
plt.scatter(x[:, 0], x[:, 1], c=y, alpha=0.5) # 只选取了两个特征来作二维图
for i in range(len(x_test))