机器学习-分类评估方法(召回率ROC与混淆矩阵)
Posted 吾仄lo咚锵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习-分类评估方法(召回率ROC与混淆矩阵)相关的知识,希望对你有一定的参考价值。
文章目录
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。
精确率与召回率
精确率(Precision)与召回率(Recall)是分类任务中的常用指标,首先需要知道混淆矩阵。
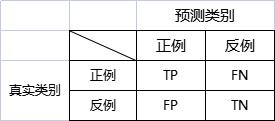
在二分类问题中,我们把样例的真实类别与分类模型预测的预测类别,进行排列组合,正例是类别1,反例是类别0,得到如下4种情形:
- 真正例(True Positive,TP)
- 假反例(False Negative,FN)
- 假正例(False Positive,FP)
- 真反例(True Negative,TN)
显然,四者之和等于样例总数,混淆矩阵如下:
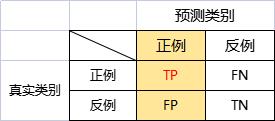
精确率
P
P
P是所有预测类别为1的样本中,真实类别为1的比例,表示查的是准不准。
P
=
T
P
T
P
+
F
P
P=\\fracTPTP+FP
P=TP+FPTP
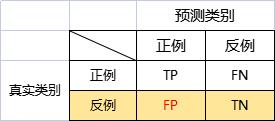
召回率
R
R
R是所有真实类别为1的样本中,预测类别为1的比例,表示查的是全不全。
R
=
T
P
T
P
+
F
N
R=\\fracTPTP+FN
R=TP+FNTP

由于总数是固定的,精确率越高则召回率越低,反之亦然,也就是说两者是矛盾的,难以两全其美。
以 P P P为纵坐标, R R R为横坐标,构建P-R图,如果一个模型A的P-R曲线完全包住模型B,自然模型A比模型B更优,其精准率和召回率都大于B。
但如果出现模型A的精确率比模型B好,而模型B的召回率又比模型A好,即P-R图中出现交点,此时就不好判断两个模型孰优孰劣了,各有千秋。
此时可以综合考虑精确率和召回率,定义F1度量。
F1度量
F 1 = 2 T P 2 T P + F N + F P = 2 P R P + R F_1=\\frac2TP2TP+FN+FP=\\frac2PRP+R F1=2TP+FN+FP2TP=P+R2PR
F 1 F1 F1度量综合考虑了精确率 P P P和召回率 R R R两个指标,反映了模型的稳健性。
当然了,在实际应用场景中,可能对精确率和召回率有偏重,可以乘以加权权重 β \\beta β。
推广到多分类任务中,由于混淆矩阵是对应正反两个类别的,而多分类中类别大于2。使用组合,将组合中每两个类别生成一个对应矩阵,并计算F1,最后再计算所有F1的平均值,得到宏F1(macro-F1)。
类似的,可以计算宏精准率(macro-P)、宏召回率(macro-R)。
在sklearn库中,可以调用classification_report()计算这些指标。
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))

ROC与AUC
上述指标对于数据相对平衡时,是可以提供一个很好的参考。但是如果对于极不平衡的数据,上述指标就不能正确反映模型的优劣了。
比如肺癌数据集中,99个是肺癌样本,1个不是肺癌样本。如果分类模型不管三七二十一,对于输入全部判为肺癌,那它的正确率仍高达99%。
对于这种不平衡的情况,我们需要参考ROC曲线和AUC指标。
(
插播反爬信息)博主CSDN地址:https://wzlodq.blog.csdn.net/
首先定义 T P R TPR TPR和 F P R FPR FPR。
真正例率(True Positive Rate,TPR)是所有真实类别为1的样本中,预测类别为1的比例:
T
P
R
=
T
P
T
P
+
F
N
TPR=\\fracTPTP+FN
TPR=TP+FNTP

假正例率(False Positive Rate,FPR)是所有真实类别为0的样本中,预测类别为0的比例:
F
P
R
=
F
P
F
P
+
T
N
FPR=\\fracFPFP+TN
FPR=FP+TNFP
ROC曲线的横坐标就是
F
P
R
FPR
FPR,纵坐标就是
T
P
R
TPR
TPR,其全称是Receiver Operating Characteristic,受试者工作特征。当
F
P
R
FPR
FPR=
T
P
R
TPR
TPR时,也就是对角线(下图虚线),表示无论真实类别是0还是1的样本,分类模型预测预测为1的概率是想等的。当ROC曲线越往左上,即
T
P
R
TPR
TPR越接近1时,表示模型越好,反之越差。
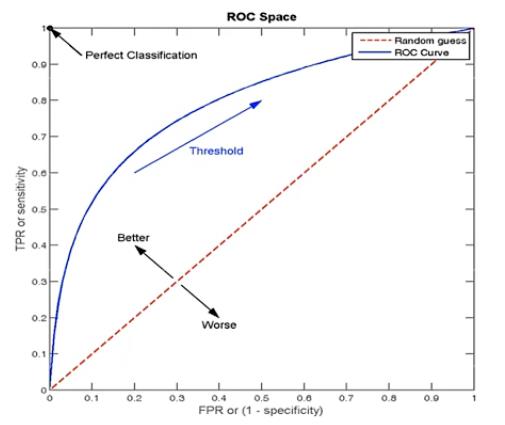
图片摘自网络。
与P-R图存在相同的问题,如果两个模型的POC曲线有交点时,也不好判断孰优孰劣。此时可以通过AUC指标来判断。
AUC全称Area Under ROC Curve,即ROC曲线下的面积,AUC越大越接近1,则表示模型越好。
可以使用sklearn库中roc_auc_score()函数来计算ROC下面积,即AUC。
注意正例1反例0,传参记得处理数据。
from sklearn.metrics import roc_auc_score
print(roc_auc_score(y_test, y_pred))

混淆矩阵
将上述二分类中的混淆矩阵应用到多分类任务中,即将正例反例两类扩展到类1类2···类n中,反映预测标签与真实标签的情况,计算各类预测结果中的百分比情况,使用颜色作为区分,颜色越深对于百分比越大,表示属于该类的概率越大。也就是对角线越深则越好,可以较好的评估分类模型。
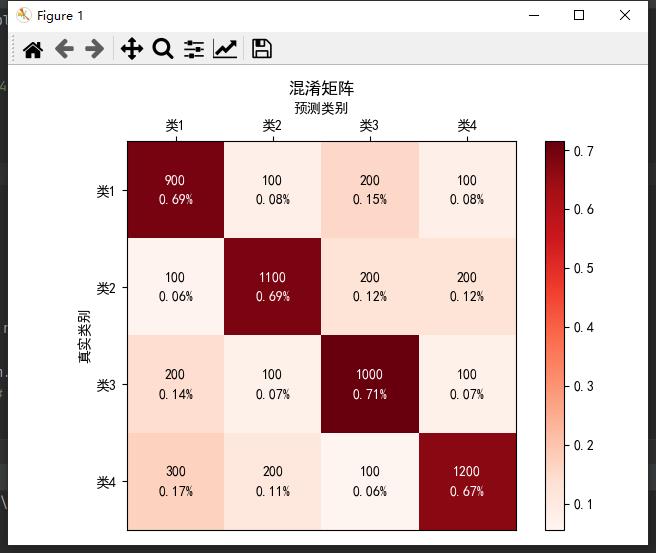
图中可以显示数值或百分比或两者同时显示。
from matplotlib import pyplot as plt
import numpy as np
classes = ['类1', '类2', '类3', '类4']
confusion_matrix = np.array([(900, 100, 200, 100),
(100, 1100, 200, 200),
(200, 100, 1000, 100),
(300, 200, 100, 1200)])
proportion = [] # 百分比
for i in confusion_matrix:
for j in i:
temp = j / (np.sum(i))
proportion.append(temp)
# 转为二维numpy矩阵
proportion = np.array(proportion).reshape(confusion_matrix.shape[0], confusion_matrix.shape[1])
plt.imshow(proportion, cmap=plt.cm.Reds) # 按照像素显示出矩阵
plt.colorbar().ax.tick_params() # 设置右侧色标刻度
# 遍历矩阵
for i in range(len(classes)):
for j in range(len(classes)):
if i == j: # 背景色太深了,设字体为白色
plt.text(j, i - 0.1, s=confusion_matrix[i, j], va='center', ha='center', color='white') # 显示数字
plt.text(j, i + 0.1, s="%.2f%%" % proportion[i, j], va='center', ha='center', color='white') # 显示百分比
else:
plt.text(j, i - 0.1, s=confusion_matrix[i, j], va='center', ha='center') # 显示数字
plt.text(j, i + 0.1, s="%.2f%%" % proportion[i, j], va='center', ha='center') # 显示百分比
plt.title('混淆矩阵') # 图名
plt.xlabel('预测类别') # x轴名
plt.ylabel('真实类别') # y轴名
plt.gca().xaxis.set_label_position('top') # 设置x轴在顶部
# 设置x轴的刻度和标签只显示在顶部
plt.gca().tick_params(axis="x", top=True, labeltop=True, bottom=False, labelbottom=False)
plt.xticks(np.arange(len(classes)), classes) # 设置x刻度
plt.yticks(np.arange(len(classes)), classes) # 设置y刻度
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文编码
plt.rcParams['axes.unicode_minus'] = False # 显示负号
plt.tight_layout() # 紧凑排布
plt.show()
原创不易,请勿转载(
本不富裕的访问量雪上加霜)
博主首页:https://wzlodq.blog.csdn.net/
来都来了,不评论两句吗👀
如果文章对你有帮助,记得一键三连❤
以上是关于机器学习-分类评估方法(召回率ROC与混淆矩阵)的主要内容,如果未能解决你的问题,请参考以下文章