你的新进程是如何被内核调度执行到的?
Posted 热爱编程的大忽悠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了你的新进程是如何被内核调度执行到的?相关的知识,希望对你有一定的参考价值。
你的新进程是如何被内核调度执行到的?
大家好,我是飞哥!
在前面的文章《Linux进程是如何创建出来的?》 和 《聊聊Linux中线程和进程的联系与区别》 中我们都讲过了,进程和线程在创建出来后会加入运行队列里面等待被调度。
但咱们之前提的太笼统了。所谓的运行队列到底长什么样子、新进程是如何被加入进来的、调度是如何选择一个新进程的、新进程又如何被切换到 CPU 上运行的,这些细节咱们都没提到。今天就来展开看看这些进程运行背后的原理。
通过今天的文章,你将对以下两个问题有个更深入的理解。
- 进程不主动释放 CPU 的话,每次调度最少能运行多久?
- 进程的 nice 值代表的是优先级吗,高优先级是否能抢占低优先级的 CPU ?
好了,我们正式展开今天主题的内功修炼!(本文总共一万字,阅读预计要27分钟)
一、CPU 核的运行队列
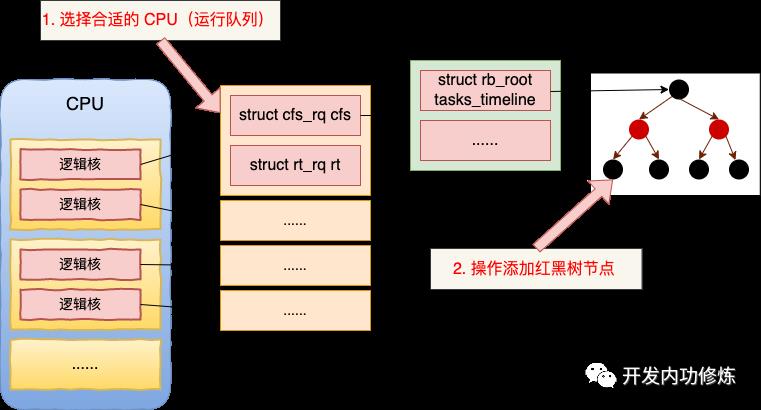
进程创建完后需要被添加到运行队列中,那我们就来看看这个运行队列究竟是长啥样子的。
关于运行队列,我们得先从 CPU 的物理结构讲起。现代主流的服务器都是多 CPU 架构,每颗 CPU 又会包含多个物理核,每个物理核又可以超线程出多个逻辑核来供操作系统管理和使用。
拿某台线上的服务器 32 核的服务器来举例,该服务器实际上是有 2 颗 CPU,每颗 CPU 包含了 8 个物理核心。这样总共包含的是 16 个物理核。
因为该服务器每个物理核心又可以当成两个超线程来用,所以通过 top 命令可以看到有 32 “核”,这里看到的核其实是逻辑核。
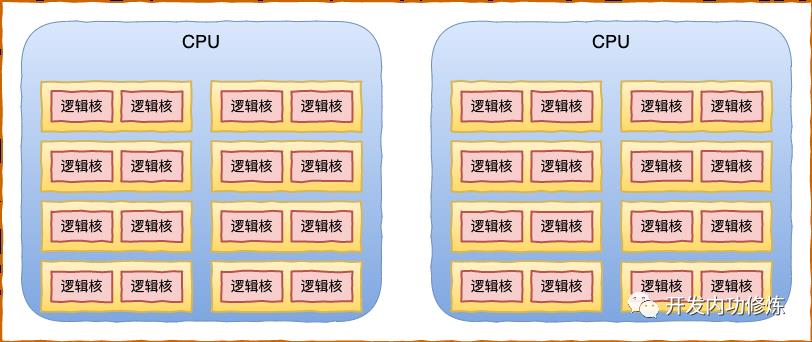
为了让每个 CPU 核(逻辑核)都能更好地参与进程任务处理,不需要考虑和其他处理器竞争的问题,也能充分利用本地硬件 Cache 来对访问加速。Linux 内核会为每个 CPU 核都分配一个运行队列,也就是 struct rq 内核对象。
内核定义是通过 DEFINE_PER_CPU 来定义 Per CPU 变量的。其中运行队列使用的是 DEFINE_PER_CPU_SHARED_ALIGNED 宏。
//file:kernel/sched/core.c
DEFINE_PER_CPU_SHARED_ALIGNED(struct rq, runqueues);
DEFINE_PER_CPU_SHARED_ALIGNED 宏接收两个参数,第一参数可以理解为是数组类型,第二个参数可以理解为数组名。
//file:include/linux/percpu-defs.h
#define DEFINE_PER_CPU_SHARED_ALIGNED(type, name) \\
DEFINE_PER_CPU_SECTION(type, name, PER_CPU_SHARED_ALIGNED_SECTION) \\
____cacheline_aligned_in_smp
这个宏执行后的效果是初始化出来一个 runqueues 数组,在该数组中为每一个 CPU 核都配置了一个运行队列(struct rq)对象。
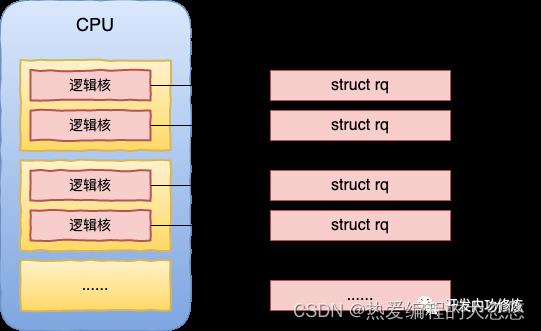
那么这个运行队列 struct rq 又是如何实现的呢?Linux 操作系统进程调度有多种多样的需求。例如有的需要按优先级来实时调度,只要高优先级的进程一就绪,就需要立即抢占 CPU 资源。有的不需要抢占这么频繁,对实时性要求没那么高,但需要进程公平地被分配 CPU 资源就可以了。
为了满足各种复杂的调度策略,内核在 struct rq 中实现了不同的调度类(Scheduling Class)。不同的调度需求的进程放在不同的调度类中。
//file:kernel/sched/sched.h
struct rq
//2.1 实时任务调度器
struct rt_rq rt;
//2.2 CFS 完全公平调度器
struct cfs_rq cfs;
...
2.1 实时调度器
在实时类调度需求中,一般内核线程如 migration 一般对实时性的要求比较高,这类进程需要及时调度分配 CPU。
在这种调度算法中,优先级是最主要考虑的因素。高优先级的进程可以抢占低优先级进程 CPU 资源来运行。同一个优先级的进程按照先到先服务(SCHED_FIFO)或者时间片轮转(SCHED_RR)。
这种调度方式实现起来比较简单,只需要定义一些优先级,并为每个优先级各分配一个链表当队列即可,也叫多优先级队列。
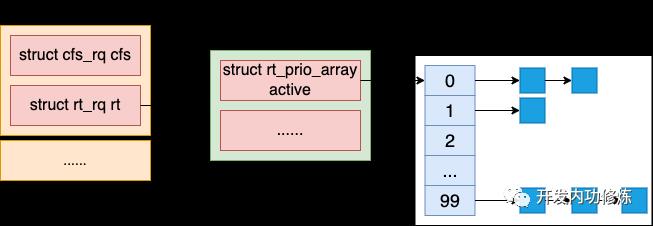
我们来看下代码实现:
//file:kernel/sched/sched.h
struct rt_rq
struct rt_prio_array active;
unsigned int rt_nr_running;
...
其中 rt_prio_array 就是多优先级队列的实现,我们来看下它的定义。
//file:kernel/sched/sched.h
struct rt_prio_array
...
struct list_head queue[MAX_RT_PRIO];
;
其中 MAX_RT_PRIO 定义在 include/linux/sched/rt.h 文件中,它的值为 100。也就是说有 100 个对应不同优先级的队列。
//file: include/linux/sched/rt.h
#define MAX_USER_RT_PRIO 100
#define MAX_RT_PRIO MAX_USER_RT_PRIO
...
2.2 完全公平调度器
Linux 主要是用来运行用户进程的。对于绝大部分的用户进程来说,对实时性的要求没那么高。如果因为优先级的问题频繁地发生抢占,进而导致过多的进程上下文切换的开销,对系统整体的性能是有不利的影响的。
所以用户进程采用的是不同的调度算法。Linux 2.6.23 之后采用了完全公平调度器(Completely Fair Scheduler,CFS)作为对用户进程的调度算法。CFS 调度器的核心思想是强调让每个进程尽量公平地分配到 CPU 时间即可,而不是实时抢占。。
举个例子,假设一个 CPU 上有两个任务需要执行,那么每个任务都将分配 50% 的 CPU 时间,以保障公平性。假如有 N 个任务,CPU 尽可能分配给每个进程 1/N 的处理时间。
公平调度算法在实现上引入了一个虚拟时间的概念。一旦进程运行虚拟时间就会增加。尽量让虚拟时间最小的进程运行,谁小了就要多运行,谁大了就要少获得 CPU。最后尽量保证所有进程的虚拟时间相等,动态地达到公平分配 CPU 的目的。
但是在数据结构的组织上,有一个小小的难点要解决。那就是当所有程序运行起来后,每一个进程的虚拟时间是不断地在变化的。如何动态管理这些虚拟时间不断在变化的进程,快速把虚拟时间最少的进程找出来。
在 CFS 调度器中采用的解决办法是使用的是红黑树来管理任务。红黑树把进程按虚拟运行时间从小到大排序。越靠树的左侧,进程的运行虚拟时间越小。越靠树的右侧,进程的运行虚拟时间就越大。这样每当想挑选可运行进程时,直接从树的最左侧选择节点就可以了。
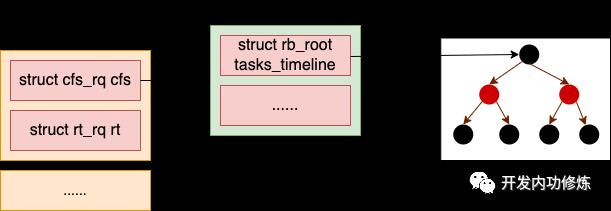
以下是 cfs_rq 对象的定义,其中的 rb_xx 就是红黑树相关的定义。
//file:kernel/sched/sched.h
struct cfs_rq
...
u64 min_vruntime;
struct rb_root tasks_timeline;
struct rb_node *rb_leftmost;
...
另外完全公平调度器实现上考虑到的两个细节这里我和大家提一下。
第一个就是照顾性能开销。
前面我们说过,进程上下文切换会导致额外的 CPU 浪费。假如被选中的进程刚运行没多久,它的虚拟时间时间就比另一个进程小了。这时候难道要马上换另一个进程处理么?出于减少频繁切换进程所带来的成本考虑,显然并不应该这样。
所以,Linux 会保证选择到的进程一个最短的运行时间,这个时间由 sched_min_granularity_ns 这个内核参数来控制。
# sysctl -a | grep min_granularity
kernel.sched_min_granularity_ns = 10000000
上面是飞哥阿里云服务器的默认配置。这表示进程至少会运行 10 ms。当然了,如果进程因为等待网络、磁盘等资源时主动放弃那另算。
第二个就是权重考量。
在实践中可能确实有进程需要多分配一点运行时间。Linux 采用的做法在是上述绝对公平算法基础上再为进程引入一个权重。
通过给每个进程设置一定的权重,各个进程按权重的比例公平地来分配 CPU 时间。如果进程的权重高,那就按比例多获得一点 CPU,权重低获得的比例就低。
这个权重就是 Linux 进程的 nice 值,也就是我们平时 top 命令结果中看到的 ni 这一列。nice 范围为 -20(最高权重)到 19(最低权重)。
现在有很多人都把 nice 理解成了优先级,这是不太恰当的。优先级强调的是抢占,高优先级比低优先级有优先获得 CPU 的权利。而用户进程中的 nice 值强调的是获取到 CPU 运行时间的比例,理解成权重更合适。
三、新进程之初始化
之前在 《Linux进程是如何创建出来的?》一文中我们讲到,fork 创建时主要是调用了 copy_process 对新进程的 task_struct 进行各种初始化。在初始化的过程中,也涉及到几个进程调度相关的变量的初始化,这里我们专门来看一下。
//file:kernel/fork.c
static struct task_struct *copy_process(...)
...
sched_fork(p);
...
在创建进程 copy_process 时会调用 sched_fork 来完成调度相关的初始化。
//file:kernel/sched/core.c
void sched_fork(struct task_struct *p)
__sched_fork(p);
p->state = TASK_RUNNING;
if (!rt_prio(p->prio))
p->sched_class = &fair_sched_class;
...
在上面代码中最重要的一行是 p->sched_class = &fair_sched_class。这一行表示这个进程将会被完全公平调取策略进行调度。其中 fair_sched_class 是一个全局对象,代表完全公平调度器。它实现了调取器类中要求的添加任务队列、删除任务队列、从队列中选择进程等方法。
//file:kernel/sched/fair.c
const struct sched_class fair_sched_class =
.next = &idle_sched_class,
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
...
.select_task_rq = select_task_rq_fair,
.migrate_task_rq = migrate_task_rq_fair,
...
另外就是把进程的虚拟运行时间初始化为 0,迁移次数初始化为 0 。
//file:kernel/sched/core.c
static void __sched_fork(struct task_struct *p)
p->on_rq = 0;
...
p->se.nr_migrations = 0;
p->se.vruntime = 0;
...
四、新进程加入调度
同在 《Linux进程是如何创建出来的?》一文中我们讲到,进程在 copy_process 创建完毕后,通过调用 wake_up_new_task 将新进程加入到就绪队列中,等待调度器调度。
//file:kernel/fork.c
long do_fork(...)
//复制一个 task_struct 出来
struct task_struct *p;
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace);
//子任务加入到就绪队列中去,等待调度器调度
wake_up_new_task(p);
...
今天我们可以来展开看看 wake_up_new_task 执行时具体都发生了什么。新进程是如何加入到 CPU 运行队列 (struct rq)中的,我们来展开详细看看。
//file:kernel/sched/core.c
void wake_up_new_task(struct task_struct *p)
//4.1 为进程选择一个合适的CPU
set_task_cpu(p, select_task_rq(p, SD_BALANCE_FORK, 0));
//4.2 将进程添加到活动进程集合
rq = __task_rq_lock(p);
activate_task(rq, p, 0);
...
wake_up_new_task 主要做了两件事,一是选择一个合适 CPU,二是将进程添加到所选的 CPU 的任务队列中。
4.1 选择合适的 CPU 运行队列
前面我们讲到,每个 CPU 核都有一个对应的运行队列 runqueue (struct rq)。所以新进程在加入调度前的第一件事就是选择一个合适的运行队列。然后使用该任务队列中,并等待调度。
要稍微注意的是,在 set_task_cpu(p, select_task_rq(p, SD_BALANCE_FORK, 0)) 这一行代码中包含对两个函数的调用。
- select_task_rq 是选择一个合适的 CPU(运行队列)
- set_task_cpu 是使用选择好的 CPU
在讲选择运行队列之前,我们先简单回顾一下 CPU 里的缓存。
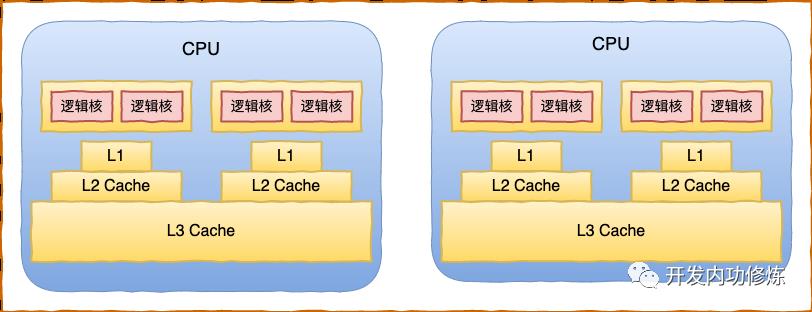
CPU 同一个物理核上的两个逻辑核是共享一组 L1 和 L2 缓存的。整颗物理 CPU 上所有的核心共享同一组 L3。每一级 Cache 的访问耗时都差别非常大,L1 大约是 1 ns 多一些,L2 大约是 2 ns 多,L3 大约 4 - 8 ns。而内存耗时在最坏的随机 IO 情况下可以达到 30 多 ns。
存储延迟测试参见《实际测试内存在顺序IO和随机IO时的访问延时差异》,想了解你的 CPU 上 cache 的情况请参见《CPU cache 的查看》
了解了 CPU 的物理结构以及各级缓存的性能差异,你就大概能弄明白选择 CPU 的核心目的了。CPU 调度是在缓存性能和空闲核心两个点之间做权衡。同等条件下会尽量优先考虑缓存命中率,选择同 L1/L2 的核,其次会选择同一个物理 CPU 上的(共享 L3),最坏情况下去选择另外一个物理 CPU 上的核心。
选择运行队列 select_task_rq 这个函数有点复杂。但是理解了上面这个逻辑后,相信你理解起来就会容易很多。
//file:kernel/sched/core.c
static inline
int select_task_rq(struct task_struct *p, int sd_flags, int wake_flags)
int cpu = p->sched_class->select_task_rq(p, sd_flags, wake_flags);
...
return cpu;
在本文的第三节中我们提到了 fork 出来的新进程的 sched_class 使用的是公平调度器 fair_sched_class,回忆一下这个结构体的定义。
//file:kernel/sched/fair.c
const struct sched_class fair_sched_class =
...
.select_task_rq = select_task_rq_fair,
.migrate_task_rq = migrate_task_rq_fair,
...
所以上面的 p->sched_class->select_task_rq 这一句实际是进入到了 fair_sched_class 的 select_task_rq_fair 方法里,通过公平调度器实现的选择任务队列的来选择的。
//file:kernel/sched/fair.c
static int
select_task_rq_fair(struct task_struct *p, int sd_flag, int wake_flags)
// 当前 CPU
int cpu = smp_processor_id();
// 上一次执行的 CPU
int prev_cpu = task_cpu(p);
// 快速路径选择
new_cpu = select_idle_sibling(p, prev_cpu);
goto unlock;
// 慢速路径选择
group = find_idlest_group(sd, p, cpu, load_idx);
new_cpu = find_idlest_cpu(group, p, cpu);
.......
为了方便你理解,我把 select_task_rq_fair 源码精简处理后,只留下了关键逻辑。这个函数一开始就获得了当前 CPU(创建新进程的进程所使用的 CPU)和上一次运行的 CPU(新进程暂时还没有)。接下来就是两个关键逻辑:一是快速路径选择,二是慢速路径选择。
在快速路径选择中,主要的策略就是考虑共享 cache 且 idle 的 CPU。优先选择任务上一次运行的CPU,其次是唤醒任务的 CPU。总之就是尽量考虑 cache 性能。
如果快速路径没选到,那就进入慢速路径。首选选出负载最小的组(find_idlest_group),然后再从该组中选出最空闲的 CPU(find_idlest_cpu)。
当进入到慢速路径以后,会导致进程下一次执行的时候跑的别的核、甚至是别的物理 CPU 上,这样以前跑热的 L1、L2、L3 就都失效了。用户进程过多地发生这种漂移会对性能造成影响。当然内核在极力地避免。如果你想强行干掉漂移,可以试试 taskset 命令。
至于 set_task_cpu 的逻辑比较简单,主要就是把选到的 CPU 设置到新创建出来的进程 task_struct 上。
4.2 将进程添加到活动进程集合
在选择完 CPU 后,下一步就是将新创建出来的进程添加到该 CPU 对应的运行队列 (struct rq) 中。
//file:kernel/sched/core.c
void wake_up_new_task(struct task_struct *p)
//4.1 为进程选择一个合适的CPU
set_task_cpu(p, select_task_rq(p, SD_BALANCE_FORK, 0));
//4.2 将进程添加到活动进程集合
rq = __task_rq_lock(p);
activate_task(rq, p, 0);
...
经过 set_task_cpu 设置后,新进程taskstruct 指针 p 上已经记录了下一次要使用的 CPU 号。调用 __task_rq_lock 函数的作用就是将新进程 p 要使用的 CPU 的运行队列 struct rq 给找出来,并给它加个锁防止冲突。
接着调用 activate_task 将新进程添加到该 CPU 运行队列中去。
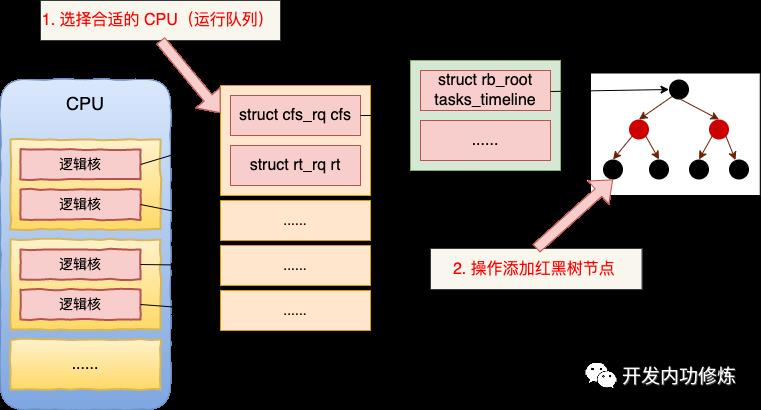
来查看其源码。
//file: kernel/sched/core.c
void activate_task(struct rq *rq, struct task_struct *p, int flags)
......
enqueue_task(rq, p, flags);
static void enqueue_task(struct rq *rq, struct task_struct *p, int flags)
......
p->sched_class->enqueue_task(rq, p, flags);
回忆完全公平调度器 fair_sched_class 对象。
//file:kernel/sched/fair.c
const struct sched_class fair_sched_class =
.next = &idle_sched_class,
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
...
.select_task_rq = select_task_rq_fair,
.migrate_task_rq = migrate_task_rq_fair,
...
可见 p->sched_class->enqueue_task 实际调用的是 enqueue_task_fair。经过 enqueue_task_fair => enqueue_entity ==> __enqueue_entity,最终插入到红黑树中等待调度。
//file:kernel/sched/fair.c
static void __enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
struct rb_node **link = &cfs_rq->tasks_timeline.rb_node;
struct rb_node *parent = NULL;
...
//插入到红黑树中
rb_insert_color(&se->run_node, &cfs_rq->tasks_timeline);
五、调度时机
前面我们讲述的过程全部是新进程创建发生的事情,新进程还没有真正被调度。触发调度器开始选择进程并上 CPU 开始运行的时机有很多。我们就以咱们前面文章讲过的同步阻塞时机为例。
在 图解 | 深入理解高性能网络开发路上的绊脚石 - 同步阻塞网络 IO 一文中我们提到过,在同步阻塞网络编程模型下,如果 socket 上没有收到数据,或者收到不足够多,则调用 sk_wait_data 把当前进程阻塞掉,让出 CPU 并调度运行队列中的其它进程进行。
我们现在假设就有某一个进程发生了这样的阻塞。sk_wait_data 依次会调用 sk_wait_event、schedule_timeout,然后到达调度的核心函数 schedule。我们来看看它的核心实现 __schedule。
//file: kernel/sched/core.c
static void __sched __schedule(void)
......
//取出当前 CPU 及其任务队列
cpu = smp_processor_id();
rq = cpu_rq(cpu);
//5.1 获取下一个待执行任务
next = pick_next_task(rq);
//5.2 执行上下文切换到新进程上
context_switch(rq, prev, next);
......
在这个函数中把当前 CPU 的任务队列取了出来,接着获取下一个待运行的任务,再执行上下文切换到新进程上来运行。接下来我们分两个小节单独来看下。
5.1 获取下一个待执行任务
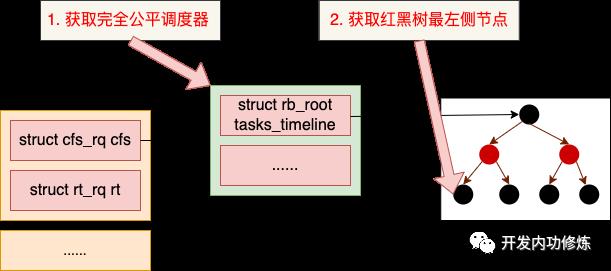
是如何获取下一个待执行任务的呢?我们来看下 pick_next_task 的实现。
//file: kernel/sched/core.c
static inline struct task_struct *
pick_next_task(struct rq *rq)
p = fair_sched_class.pick_next_task(rq);
...
因为大部分都是普通进程,所以大概率会执行到 fair_sched_class.pick_next_task 函数中,也就是 pick_next_task_fair 函数中。该函数其实就是从当前任务队列的红黑树节点将运行虚拟时间最小的节点(最左侧的节点)选出来而已。
//file: kernel/sched/fair.c
static struct task_struct *pick_next_task_fair(struct rq *rq)
//获取完全公平调取器
struct cfs_rq *cfs_rq = &rq->cfs;
//从完全公平调取器红黑树中选择一个进程
se = pick_next_entity(cfs_rq);
...
这样,下一个待运行的进程就被选出来了。
5.2 执行上下文切换到新进程上
选出来待运行的新进程以后,接着就需要执行进程上下文切换,把新进程的运行状态给切换上来。
//file:kernel/sched/core.c
static inline void
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next)
//准备新旧两个进程的地址空间
struct mm_struct *mm, *oldmm;
mm = next->mm;
oldmm = prev->active_mm;
//执行地址空间切换
switch_mm(oldmm, mm, next);
//执行栈和寄存器切换
switch_to(prev, next, prev);
......
当前进程上下文切换完成的时候,新进程终于可以得以运行了!
六、总结
好了,我们把今天的文章的内容总结一下。
一个进程从 fork 创建出来到最后真正能获得 CPU 并进行运行,中间有很多的内核逻辑需要处理,我把它分成了这么几个步骤供你更容易地理解。
第一,每个 CPU 核都有一个运行队列。为了支持不同的调度需求,运行队列是由实时调度器、完全公平调取器等多种调度器组成。
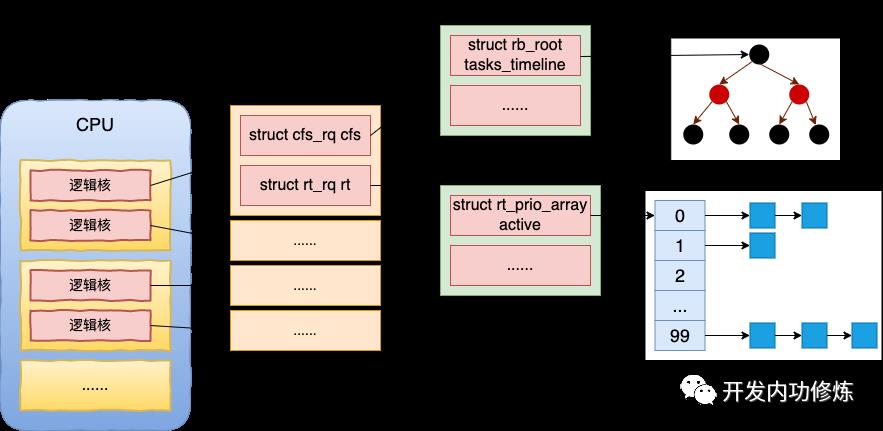
第一,是进程在 fork 的时候会选择自己的调取器,用户进程一般都是用完全公平调度器(fair_sched_class)。
第二,进程创建完前会综合考虑缓存友好性以及空闲状况,选择一个 CPU 运行队列出来,并将新进程添加到该队列中。
第三,内核有很多的时机来触发调度。我们文中举了同步阻塞网络 IO 放弃 CPU 时调取新进程运行的例子。在放弃 CPU 前会从当前 CPU 的运行队列获取一个进程出来,上下文切换后运行之。
我们再回到开篇的问题:
问题一:进程不主动释放 CPU 的话,每次调度最少能运行多久?
在完全公平调度器中,出于减少频繁切换进程所带来的成本考虑,一个进程一旦被分配到 CPU 就会持续运行相对较长的一段时间,避免频繁的进程上下文切换导致的性能损耗。这段时间的最小值由 sched_min_granularity_ns 这个内核参数来控制,单位是 ns (纳秒) 。例如下面这个配置的最短运行时间是 10 ms。
# sysctl -a | grep min_granularity
kernel.sched_min_granularity_ns = 10000000
当然了,如果进程因为等待网络、磁盘等资源时主动放弃 CPU 那另算。
问题二:进程的 nice 值代表的是优先级吗,高优先级是否能抢占低优先级的 CPU ?
在实时任务如 migration 内核线程中,是按优先级调度的。优先级强调的是抢占,高优先级比低优先级有优先获得 CPU 的权利。
但是对于用户进程来讲,一般都采用的完全公平调度器来进行 CPU 资源的分配。在这种调取器中,其 nice 其实是一个权重的概念。权重高的进程获得的 CPU 比例会相对高一些。但不是实时抢占。
以上是关于你的新进程是如何被内核调度执行到的?的主要内容,如果未能解决你的问题,请参考以下文章