Innodb如何实现表--下篇
Posted 热爱编程的大忽悠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Innodb如何实现表--下篇相关的知识,希望对你有一定的参考价值。
Innodb如何实现表--下篇
Innodb数据页结构
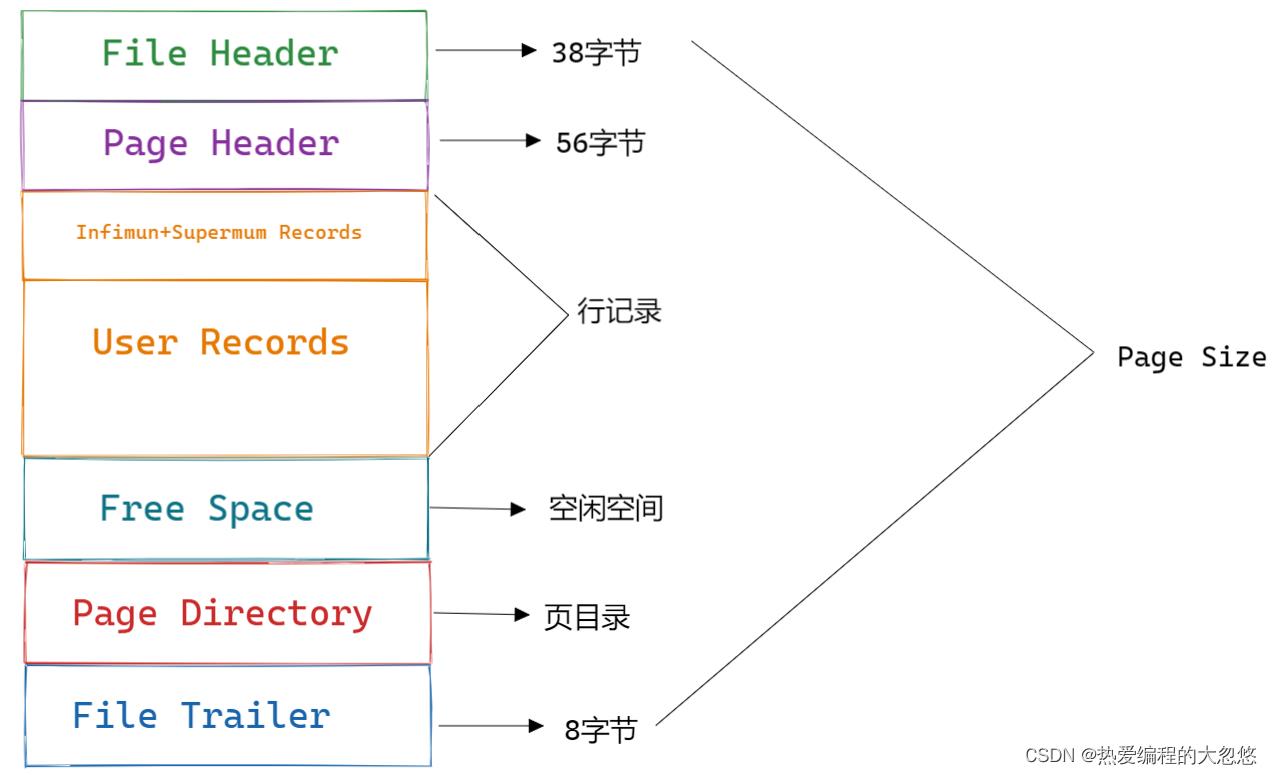
Innodb数据页由以下7个部分组成:
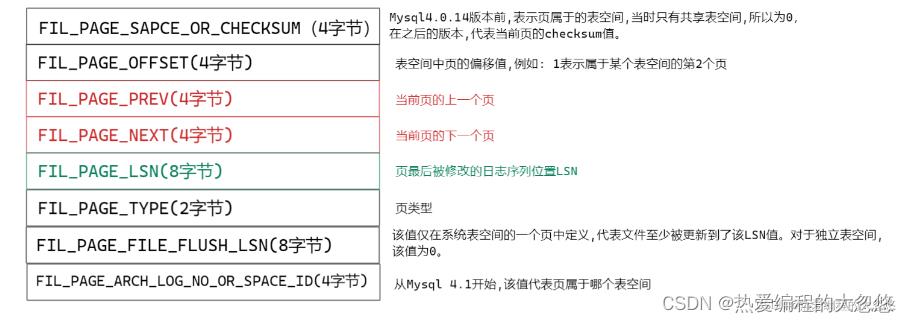
- File Header(文件头)
- Page Header(页头)
- Infimun和Supremum Records
- User Records(用户记录,行记录)
- Free Space(空闲空间)
- Page Directory(页目录)
- File Trailer(文件结尾信息)
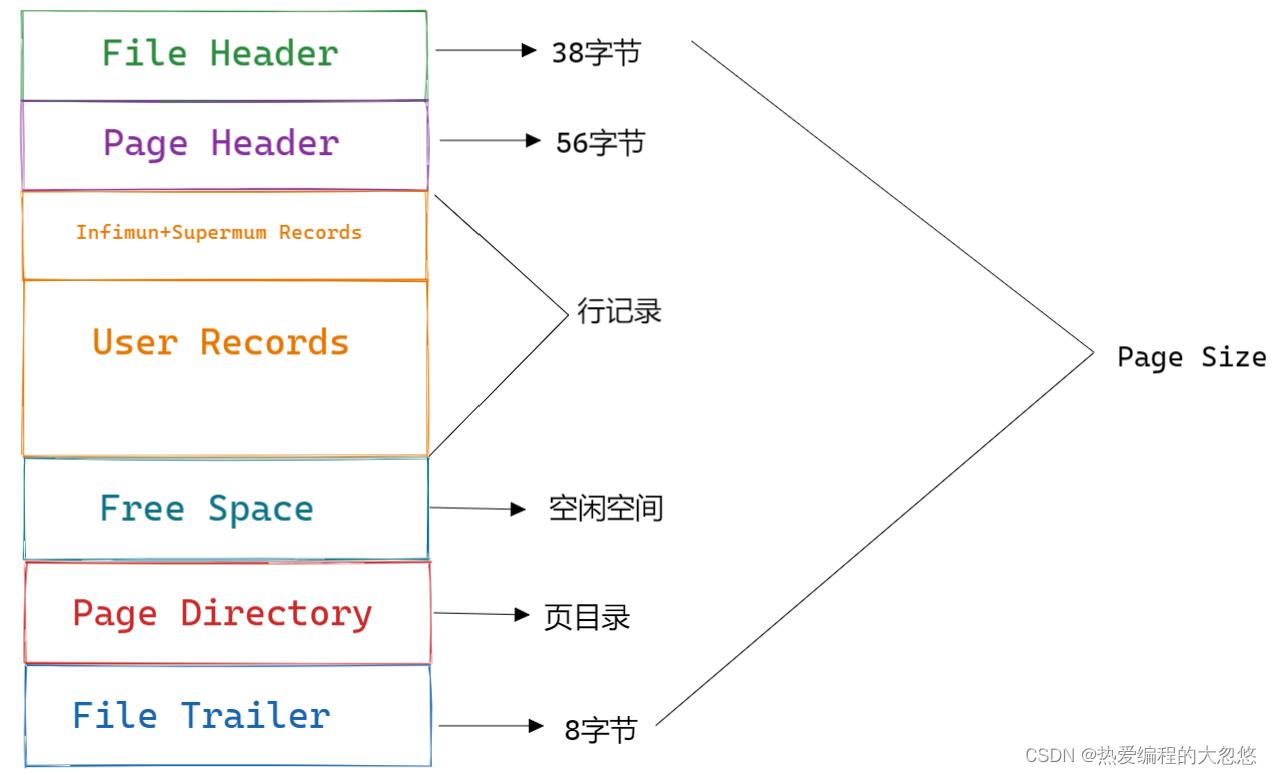
File Header
File Header是所有类型页通用的头信息,共占用38字节:

Innodb存储引擎页主要有下面几种类型:

Page Header
PageHeader是数据页特有的,专门用来记录数据页的状态信息,共占用48字节:

Infimum和Supremum Record
在InnoDB存储引擎中,每个数据页中有两个虚拟的行记录,用来限定记录的边界。Infimum记录是比该页中任何主键值都要小的值, Supremum指比任何可能大的值还要大的值。这两个值在页创建时被建立,并且在任何情况下不会被删除。
在Compact行格式和Redundant行格式下,两者占用的字节数各不相同。下图显示了Infimum和Supremum 记录。
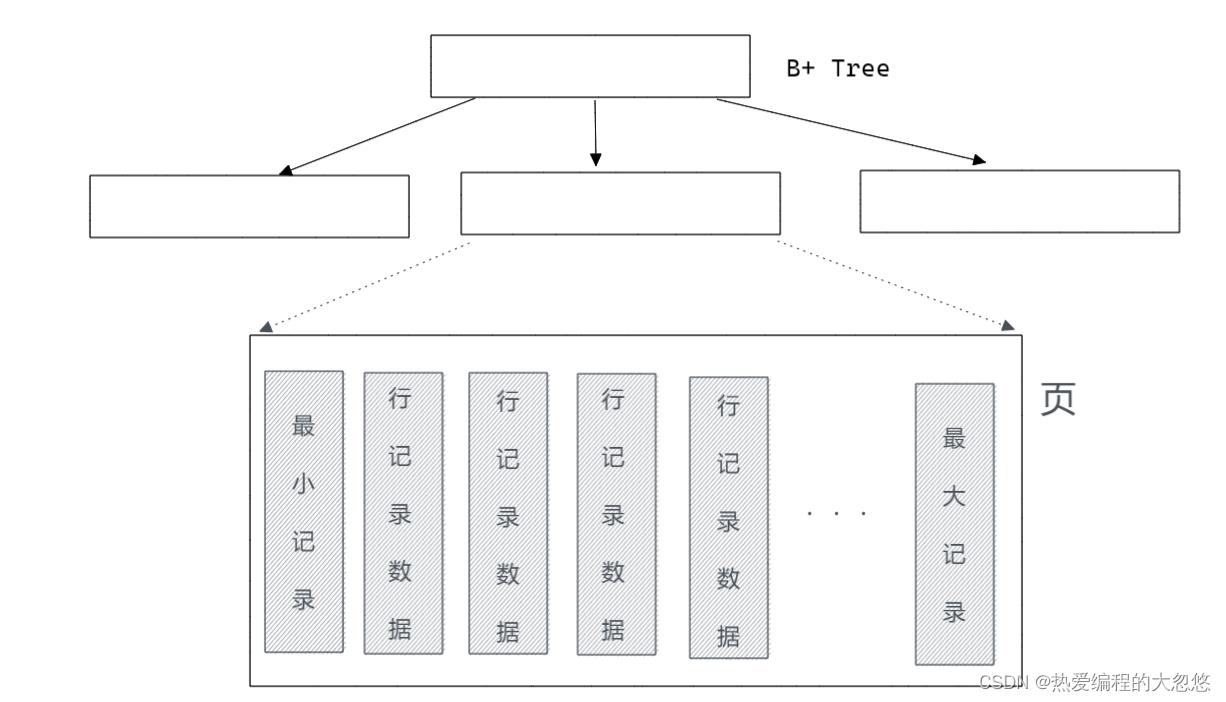
User Records和Free Space
User Record就是之前讨论过的部分,即实际存储行记录的内容。再次强调,InnoDB存储引擎表总是B+树索引组织的。
Free Space很明显指的就是空闲空间,同样也是个链表数据结构。在一条记录被删除后,该空间会被加入到空闲链表中。
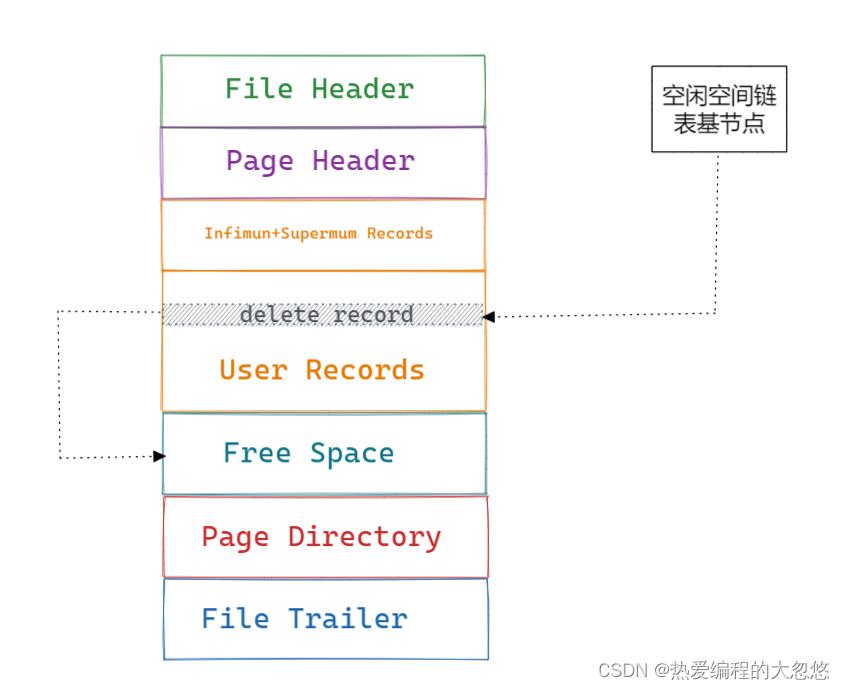
Page Directory
Innodb一个数据页中会存放很多条记录,我们之前讲行格式时提到过。记录的头信息中有一个next_record属性指向下一条记录的位置,因此数据页中多条记录通过单链表的形式串连起来:

链表的特点就是不支持随机遍历,也不支持二分快速查找,如果我们想要快速定位一条记录,那么只能将整个链表进行一遍遍历,因此对于Innodb来说,必须要优化这个问题。
为了支持随机遍历和二分快速查找,Innodb推出了页目录的概念,页目录相当于一个连续的数组,数组中的元素被称为槽,每个槽代表一段范围内的用户记录,并且指向该范围内的最后一条记录。
n_owned属性指示当前槽指示的范围里面包含了多少用户记录,并且Innodb规定伪记录Infimum的n_owned值总是为1,记录Supremum的n_owned的取值范围为[1,8],其他用户记录n_owned的取值范围为[4,8]。当记录被插人或删除时需要对槽进行分裂或平衡的维护操作。
因此,此时在某个数据页内定位一条记录时,首先通过二分查找定位到某个槽,再通过槽定位到那段范围内的记录,由于记录是通过单链表形式串连起来,所以下面就是遍历这个链表定位到目标记录所在位置。
n_owned不能设置过大,否则当通过槽定位到一组记录时,单链表遍历耗时就会增加; 如果n_owned设置过小,那么二分查找次数会增加,并且页目录也会占据更多空间。
File Trailer
为了检测页是否已经完整地写人磁盘 (如可能发生的写人过程中磁盘损坏、机器关机等) ,InnoDB存储引擎的页中设置了File Trailer部分。
File Trailer只有一个 FIL_PAGE_END_LSN 部分,占用8字节。前4字节代表该页的checksum值,最后4字节和File Header中的FIL_PAGE_LSN相同。

File Header组成图
将这两个值与File Header 中的 FIL_PAGE_SPACE_OR_CHKSUM和 FIL_PAGE_LSN 值进行比较,看是否一致(checksum的比较需要通过InnoDB的checksum函数来进行比较,不是简单的等值比较),以此来保证页的完整性(not corrupted)。
在默认配置下,InnoDB存储引擎每次从磁盘读取一个页就会检测该页的完整性,看页是否发生Corrupt,这就是通过File Trailer部分进行检测,而该部分的检测会有一定的开销。用户可以通过参数innodb_checksums来开启或关闭对这个页完整性的检查。
mysql 5.6.6版本开始新增了参数innodb_checksum_algorithm,该参数用来控制检 测 checksum函数的算法,默认值为crc32,可设置的值有:innodb、crc32、none、strict innodb、strict_crc32、strict_none。

innodb为兼容之前版本InnoDB页的checksum检测方式,crc32为MySQL 5.6.6版 本引进的新的checksum算法,该算法较之前的innodb有着较高的性能。但是若表中所有页的checksum值都以strict算法保存,那么低版本的MySQL数据库将不能读取这些页。none表示不对页启用checksum检查。
strict_*正如其名,表示严格地按照设置的checksum算法进行页的检测。因此若低版本MySQL数据库升级到MySQL 5.6.6或之后的版本,启用strict_crc32将导致不能读取表中的页。启用strict_crc32方式是最快的方式,因为其不再对innodb和crc32算法进行两次检测。故推荐使用该设置。若数据库从低版本升级而来,则需要进行mysql_upgrade操作。
实例分析
光说不看假把戏,我们这里实操一番,先搞个表,再搞点数据:
CREATE DATABASE `test`;
USE `test`;
drop table if exists t;
create table t (
a int unsigned not null auto_increment,
b char(10),
primary key(a)
)engine=innodb charset=utf8;
DELIMITER $$
CREATE PROCEDURE load_t(count int unsigned)
BEGIN
set @c=0;
WHILE @c<count DO
INSERT into t
SELECT NULL,REPEAT(char(97+RAND()*26),10);
SET @c=@c+1;
END WHILE;
end;
$$
DELIMITER ;
call load_t(100);
select a,b from t limit 10;
我们通过py_innodb_page_info工具来分析t.idb文件:
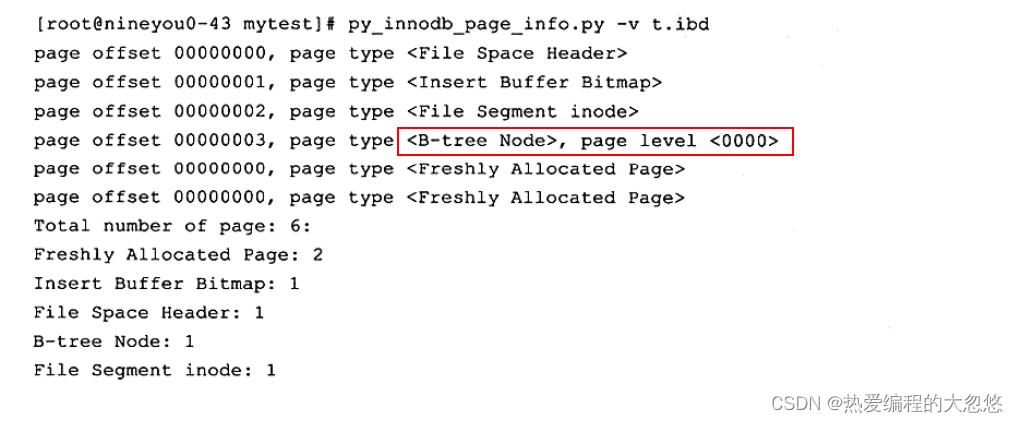
可以发现第四个页是数据页,然后通过hexdump来分析t.idb文件,打开整理得到的十六进制文件,数据页从0x0000c000(16KB*3=0xc000)处开始,得到以下内容:

先分析File Header的前面38个字节:
- db d5 06 1c : 数据页的Checksum值
- 00 00 00 03: 页的偏移量,从0开始
- ff ff ff ff: 前一个页,因为当前只有一个数据页,所以为0xffffffff
- ff ff ff ff:后一个页,因为当前只有一个数据页,所以为0xffffffff
- 00 00 00 00 00 d4 b5 ec: 页的LSN
- 45 bf: 页类型,0x45bf代表数据页
- 00 00 00 00 00 00 00 00: 该值仅在系统表空间定义,代表文件至少被更新到了LSN值,对于独立表空间来说,该值为0
- 00 00 00 4a: 表空间的SPACE ID
接着分析56字节的page header部分:

- 页目录槽数: 00 1a --> 26个槽
- PAGE_HEAD_TOP: 0d c0,代表空闲空间开始位置的偏移量,即0xc000+0xdc0=0xcdc0处开始
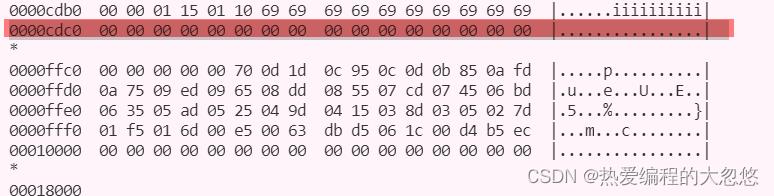
可以观察这个位置,发现这确实是最后一行的结束,接下去的部分都是空闲空间了。
- PAGE_N_HEAP=0x8066,当行记录格式为Compact时,初始值为0x0802;当行格式为Redundant时,初始值是2。其实这些值表示页初始时就已经有Infinimun和Supremum的伪记录行,0x8066-0x8002=0x64,代表该页中实际的记录有100条记录。
- PAGE_FREE=0x0000代表可重用的空间首地址,因为这里没有进行过任何删除操作,故这里的值为0。
- PAGE_GARBAGE=0x0000代表删除的记录字节为0,同样因为我们没有进行过删除,所以这里的值依然为0。
- PAGE_LAST_INSERT=0X0DA5,表示页最后插入的位置的偏移量,即最后插入位置应该在0xc0000+0x0da5=0xcda5处:

可以看到的确是最后插入a列值为100的行记录,但是这次直接指向了行记录的内容,而不是指向行记录的变长字段长度的列表位置。 - PAGE_DIRECTION=0x0002,因为通过自增长的方式进行行记录的插入,所以PAGE_DIRECTION的方向是向右,为0x00002。
- PAGE_N_DIRECTION=0x0063,表示一个方向连续插入记录的数量,因为我们是自增长的方式插入了100条记录,因此该值为99。
- PAGE_N_RECS=0x0064,表示该页的行记录数为100,注意该值与PAGE_N_HEAP的比较,PAGE_N_HEAP包含两个伪行记录,并且是通过有符号的方式记录的,因此值为0x8066。
- PAGE_LEVEL=0x00,代表该页为叶子节点。因为数据量目前较少,因此当前B+树索引只有一层。B+数叶子层总是为0x00。
- PAGE_INDEX_ID=0x000000000000001ba,索引ID。
上面就是数据页的Page Header部分了,接下去就是存放的行记录了,前面提到过InnoDB存储引擎有两个伪记录,用来限定行记录的边界,接着往下看:

观察0xc05E到0xc077,这里存放的就是这两个伪行记录,在InnoDB存储引擎中设置伪行只有一个列,且类型是Char(8)。伪行记录的读取方式和一般的行记录并无不同,我们整理后可以得到如下结果:

然后来分析 infimum行记录的 recorder header部分,最后两个字节位001c表示下一个记录的位置的偏移量,即当前行记录内容的位置0xc063+0x001c,即0xc07f。

Compact行格式复习
0xc07f应该很熟悉了,之前分析的行记录结构都是从这个位置开始,如:

可以看到这就是第一条实际行记录内容的位置了,整理后我们可以得到(跳过前面头信息等字节):
00 00 00 01 -->因为每位建表时设置了主键,这里的ROWID即为列a的值1
00 00 00 00 14 8f ---> 事务ID
bd 00 00 01 35 01 10 --> 回滚指针
78 78 78 78 78 78 78 78 78 78 --> b列的值
通过 Recorder Header的最后两个字节记录的下一行记录的偏移量就可以得到该页中所有的行记录,通过Page Header的PAGE_PREV和PAGE_NEXT就可以知道上个页和下个页的位置,这样InnoDB存储引擎就能读到整张表所有的行记录数据。
最后分析 Page Directory。前面已经提到了从0x0000ffc4到0x0000fff7是当前页的
Page Directory,如下:

需要注意的是,Page Directory是逆序存放的,每个槽占2字节,因此可以看到0063是最初行的相对位置,即0xc063;0070就是最后一行记录的相对位置,即0xc070。我们发现这就是前面分析的Infimum和Supremum的伪行记录。
Page Directory 槽中的数据都是按照主键的顺序存放的,因此查询具体记录就需要通过部分进行。前面已经提到InnoDB存储引擎的槽是稀疏的,故还需通过 Recorder Header的n_owned进行进一步的判断,如InnoDB存储引擎需要找主键a为5的记录,通过二叉查找PageDirectory的槽,可以定位记录的相对位置在00e5处,找到行记录的实际位置0xc0e5。
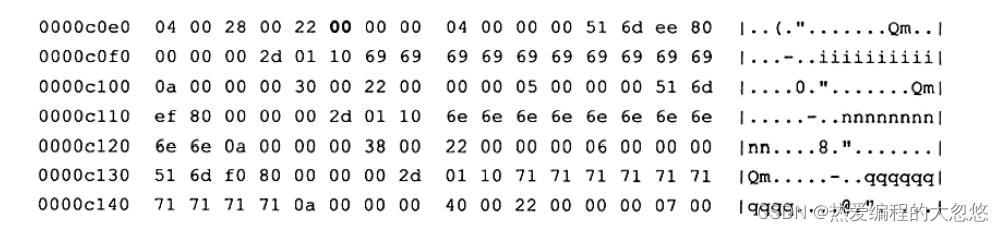
可以看到第一行的记录是4,不是我们要找的6,但是可以发现前面的5字节的Record Header为04 00 28 00 22。找到4~8位表示n_owned值得部分,该值为4,表示该记录有4个记录,因此还需要进一步查找,通过 recorder header 最后两个字节的偏移量0x0022找到下一条记录的位置0xc107,这才是最终要找的主键为5的记录。
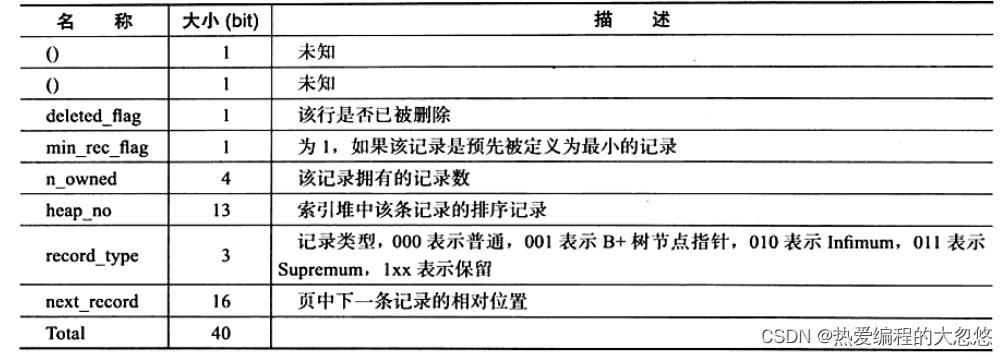
Compact行格式中记录头信息如下:
以上是关于Innodb如何实现表--下篇的主要内容,如果未能解决你的问题,请参考以下文章