CTF-MISC(入门|笔记|工具)
Posted MangataTS
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CTF-MISC(入门|笔记|工具)相关的知识,希望对你有一定的参考价值。
文章目录
音频隐写
直接隐写
顾名思义,要么就不装了直接给你一个摩斯电码,要么就是双声道中有一个声道是摩斯电码,这种慢慢数一数就行
频谱隐写
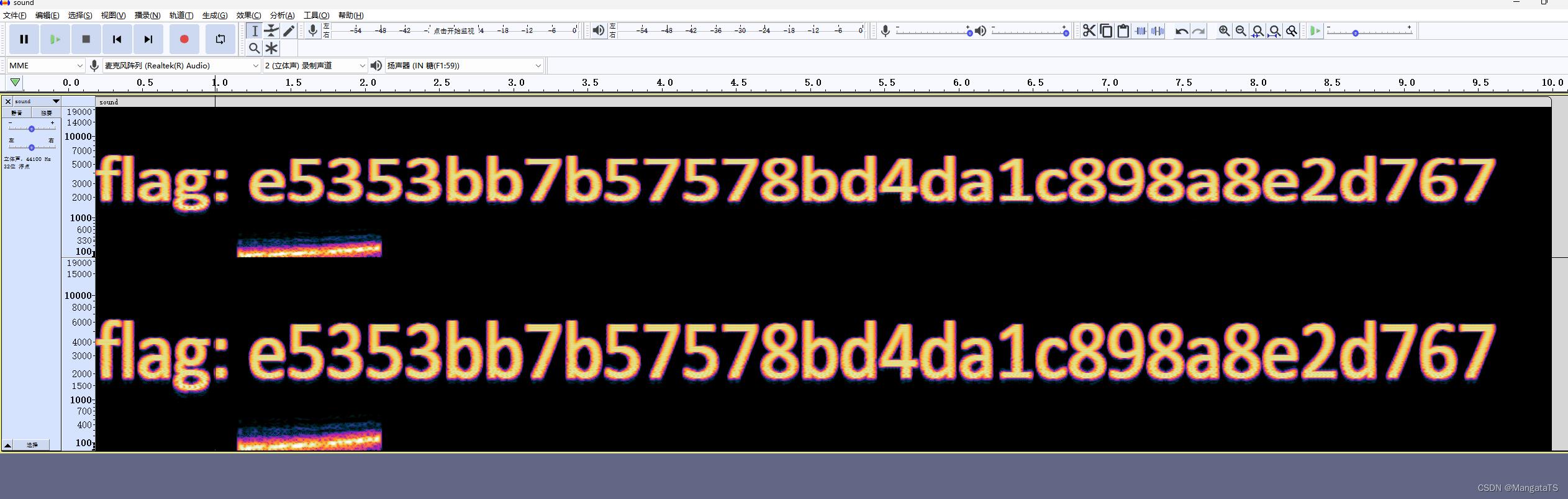
音频中的频谱隐写是将字符串隐藏在频谱中,此类音频通常会有一个较明显的特征,听起来是一段杂音或者比较刺耳。
eg:Su-ctf-quals-2014:hear_with_your_eyes
流量分析
一般流量分析分为以下三种情况:
- 流量包修复
- 协议分析
- 数据提取
第一种流量包修复
考的很少,可以参考:https://www.cnblogs.com/ECJTUACM-873284962/p/9884447.html
第二种是协议分析
我们通过分析不同类型的数据包,来查找flag可能出现的位置,常用的手段:
- 第一步,查看协议分级,找出流量最多的协议,然后过滤重点查看
- 第二步,将当前可疑的协议进行溯源,例如
TCP溯源或者HTTP,然后分析可能出现的地方 - 第三步,分析观察可疑流量的包头信息以及流量的去向信息(例如flag可能以某种规律出现在包头,或者说当前流量是一次盲注攻击)
- 第四步,要是啥也没分析出来,去试试
binwalk或者foremost分离一下试试,没准有隐藏文件(不过一般流量分析的时候就能看出来)
第三种数据提取
其实就是上面的操作,只不过可能需要使用T-shark写脚本,来提取流量中某种特定规律,例如
CTFhub中的ICMP的流量分析三道题
图片分析
zsteg
这是一个用于检测PNG和BMP中的隐藏数据隐藏数据的工具,可以快速提取隐藏信息。
命令:zsteg 文件名 --all
BMP
目前遇到的是2017世安杯的LOW,题目链接:https://adworld.xctf.org.cn/challenges/details?hash=7c7e8acc-38c7-43c5-af88-a44964ba88c6_2
考点是图片隐写,我们先用画图打开文件,然后另存为png格式的,然后使用stegSlove打开,看一下色道就会发现一个二维码,然后直接扫描就得到flag了
考点是LSB隐写,可以参考一下这个博客:https://blog.csdn.net/weixin_34075268/article/details/88744599
PNG
foremost 工具
这个工具主要是做文件的分离的恢复
ctf这类文件分离的题目,大多时候可以使用
binwalk或者winhex也可以使用dd命令。可以使用foremost,相对来说binwalk更加强大,速度也快,但是有时候如果不能分离出来,就可以试试看foremost。
-V - 显示版权信息并退出
-t - 指定文件类型. (-t jpeg,pdf ...)
-d - 打开间接块检测 (针对UNIX文件系统)
-i - 指定输入文件 (默认为标准输入)
-a - 写入所有的文件头部, 不执行错误检测(损坏文件)
-w - 向磁盘写入审计文件,不写入任何检测到的文件
-o - 设置输出目录 (默认为./output)
-c - 设置配置文件 (默认为foremost.conf)
-q - 启用快速模式. 在512字节边界执行搜索.
-Q - 启用安静模式. 禁用输出消息.
-v - 详细模式. 向屏幕上记录所有消息。
binwalk
和上面的foremost功能类似,是一个文件提取分离的工具
博客讲解:https://www.bilibili.com/read/cv11310186
steghide
这个是一个色道隐写的工具
stegslove
这个也是观察色道的一个工具
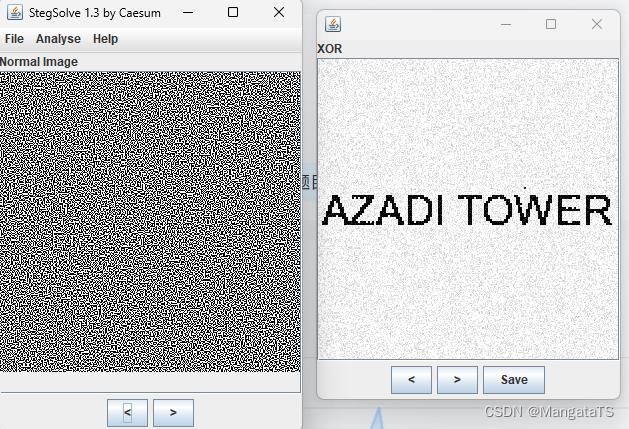
该工具还能进行图片合并功能,例题:https://adworld.xctf.org.cn/challenges/details?hash=ba932136-a9c1-4eff-8b7b-2320c775ca62_2 ,给了你一个压缩包里面有两张图,然后我们需要将两个图片进行合并得到FLAG:
tweakpng
这个工具可以帮我们检查png的一些参数,例如IHDR、CRC等等
JPG
F5-steganography
F5刷新隐写
命令:java Extract 路径
然后会得到一个output.txt
stegdetect
通过统计分析技术评估 JPEG 文件的 DCT 频率系数的隐写工具, 可以检测到通过 JSteg、JPHide、OutGuess、Invisible Secrets、F5、appendX 和 Camouflage 等这些隐写工具隐藏的信息,并且还具有基于字典暴力破解密码方法提取通过 Jphide、outguess 和 jsteg-shell 方式嵌入的隐藏信息。
-q 仅显示可能包含隐藏内容的图像。
-n 启用检查JPEG文件头功能,以降低误报率。如果启用,所有带有批注区域的文件将被视为没有被嵌入信息。如果JPEG文件的JFIF标识符中的版本号不是1.1,则禁用OutGuess检测。
-s 修改检测算法的敏感度,该值的默认值为1。检测结果的匹配度与检测算法的敏感度成正比,算法敏感度的值越大,检测出的可疑文件包含敏感信息的可能性越大。
-d 打印带行号的调试信息。
-t 设置要检测哪些隐写工具(默认检测jopi),可设置的选项如下:
j 检测图像中的信息是否是用jsteg嵌入的。
o 检测图像中的信息是否是用outguess嵌入的。
p 检测图像中的信息是否是用jphide嵌入的。
i 检测图像中的信息是否是用invisible secrets嵌入的。
一般命令为:.\\stegdetect.exe -tjopi -s 10 Misc.jpg
如果反馈是negative那就说明没看出来是什么类型
压缩包分析
zip伪加密
https://blog.csdn.net/xiaozhaidada/article/details/124538768
crc32
这是一个很暴力的方法,只能适用于压缩包文件内容很小,因为我们不去爆破压缩包的密码,而是直接去爆破源文件的内容,我这里附上几个脚本代码吧,感觉zip包的题目很少出到
crc-1byte.py
import binascii
import string
def crack_crc():
print('-------------Start Crack CRC-------------')
crc_list = [0xda6fd2a0, 0xf6a70, 0x70659eff, 0x862575d]#文件的CRC32值列表,注意顺序
comment = ''
chars = string.printable
for crc_value in crc_list:
for char1 in chars:
char_crc = binascii.crc32(char1.encode())#获取遍历字符的CRC32值
calc_crc = char_crc & 0xffffffff#将获取到的字符的CRC32值与0xffffffff进行与运算
if calc_crc == crc_value:#将每个字符的CRC32值与每个文件的CRC32值进行匹配
print('[+] : '.format(hex(crc_value),char1))
comment += char1
print('-----------CRC Crack Completed-----------')
print('Result: '.format(comment))
if __name__ == '__main__':
crack_crc()
crc-2byte.py
import binascii
import string
def crack_crc():
print('-------------Start Crack CRC-------------')
crc_list = [0xef347b51, 0xa8f1b31e, 0x3c053787, 0xbbe0a1b]#文件的CRC32值列表,注意顺序
comment = ''
chars = string.printable
for crc_value in crc_list:
for char1 in chars:
for char2 in chars:
res_char = char1 + char2#获取遍历的任意2Byte字符
char_crc = binascii.crc32(res_char.encode())#获取遍历字符的CRC32值
calc_crc = char_crc & 0xffffffff#将获取到的字符的CRC32值与0xffffffff进行与运算
if calc_crc == crc_value:#将获取字符的CRC32值与每个文件的CRC32值进行匹配
print('[+] : '.format(hex(crc_value),res_char))
comment += res_char
print('-----------CRC Crack Completed-----------')
print('Result: '.format(comment))
if __name__ == '__main__':
crack_crc()
crc-3byte.py
import binascii
import string
def crack_crc():
print('-------------Start Crack CRC-------------')
crc_list = [0x2b17958, 0xafa8f8df, 0xcc09984b, 0x242026cf]#文件的CRC32值列表,注意顺序
comment = ''
chars = string.printable
for crc_value in crc_list:
for char1 in chars:
for char2 in chars:
for char3 in chars:
res_char = char1 + char2 + char3#获取遍历的任意3Byte字符
char_crc = binascii.crc32(res_char.encode())#获取遍历字符的CRC32值
calc_crc = char_crc & 0xffffffff#将遍历的字符的CRC32值与0xffffffff进行与运算
if calc_crc == crc_value:#将获取字符的CRC32值与每个文件的CRC32值进行匹配
print('[+] : '.format(hex(crc_value),res_char))
comment += res_char
print('-----------CRC Crack Completed-----------')
print('Result: '.format(comment))
if __name__ == '__main__':
crack_crc()
crc-4byte.py
import binascii
import string
def crack_crc():
print('-------------Start Crack CRC-------------')
crc_list = [0xc0a3a573, 0x3cb6ab1c, 0x85bb0ad4, 0xf4fde00b]#文件的CRC32值列表,注意顺序
comment = ''
chars = string.printable
for crc_value in crc_list:
for char1 in chars:
for char2 in chars:
for char3 in chars:
for char4 in chars:
res_char = char1 + char2 + char3 + char4#获取遍历的任意4Byte字符
char_crc = binascii.crc32(res_char.encode())#获取遍历字符的CRC32值
calc_crc = char_crc & 0xffffffff#将遍历的字符的CRC32值与0xffffffff进行与运算
if calc_crc == crc_value:#将获取字符的CRC32值与每个文件的CRC32值进行匹配
print('[+] : '.format(hex(crc_value),res_char))
comment += res_char
print('-----------CRC Crack Completed-----------')
print('Result: '.format(comment))
if __name__ == '__main__':
crack_crc()
crc-5byte.py
import binascii
import string
def crack_crc():
print('-------------Start Crack CRC-------------')
crc_list = [0x5a904a21]#文件的CRC32值列表,注意顺序
comment = ''
chars = 'abcdefghijklmnopqrstuvwxyz\\\\'
for crc_value in crc_list:
for char1 in chars:
for char2 in chars:
for char3 in chars:
for char4 in chars:
for char5 in chars:
res_char = char1 + char2 + char3 + char4 + char5#获取遍历的任意5Byte字符
char_crc = binascii.crc32(res_char.encode())#获取遍历字符的CRC32值
calc_crc = char_crc & 0xffffffff#将遍历的字符的CRC32值与0xffffffff进行与运算
if calc_crc == crc_value:#将获取字符的CRC32值与每个文件的CRC32值进行匹配
print('[+] : '.format(hex(crc_value),res_char))
comment += res_char
print('-----------CRC Crack Completed-----------')
print('Result: '.format(comment))
if __name__ == '__main__':
crack_crc()
上面的五个代码其实也就是对应的不同字节数的压缩文件
zip包明文攻击
- 我们为zip压缩文件所设定的密码,首先被转换成 3 3 3 个 32 32 32
bit的key,所以可能的key的组合是 2 96 2^96 296,这是个天文数字,如果用暴力穷举的方式是不太可能的,除非你的密码比较短或者有个厉害的字典。- 压缩软件用这3个
key加密所有包中的文件,也就是说,所有文件的key是一样的,如果我们能够找到这个key,就能解开所有的文件。- 如果我们找到加密压缩包中的任意一个文件,这个文件和压缩包里的文件是一样的,我们把这个文件用同样的压缩软件同样的压缩方式进行无密码的压缩,得到的文件就是我们的
Known plaintext(已知明文)。用这个无密码的压缩包和有密码的压缩包进行比较,分析两个包中相同的那个文件,抽取出两个文件的不同点,就是那3个key了,如此就能得到key。两个相同文件在压缩包中的字节数应该相差 12 12 12 个byte,就是那 3 3 3 个key了。虽然我们还是无法通过这个key还原出密码,但是我们已经可以用这个key解开所有的文件,所以已经满足我们的要求了,毕竟对我们而言,得到解压后的文件比得到密码本身更重要。
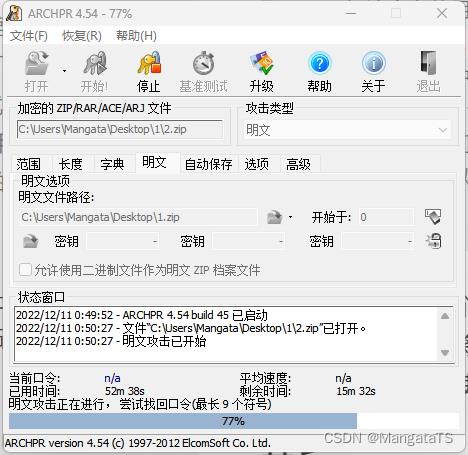
简单说一下就是两个通过相同加密的文件,如果已经有一个压缩包是被解出来了(伪加密),我们就可以将这个压缩包作为明文对另一个压缩包进行攻击,最终破解出第二个压缩包的密码,我们使用ARCHPR工具进行攻击:(不过貌似挺慢)
其它
条形码扫描
https://online-barcode-reader.inliteresearch.com/
例题:https://adworld.xctf.org.cn/challenges/details?hash=eaf7cbbe-2377-433f-841a-461d431d4a72_2
pyc反编译
使用Uncompyle6进行反编译,例题:https://adworld.xctf.org.cn/challenges/details?hash=7a4e06c0-811c-4493-a628-886dc5bd59b4_2
题目思路大概是丢进stegslove,然后观察色道发现有一个色道隐写的二维码,然后扫描后发现一串字母和数字,然后Hex解码后发现可能是pyc文件,于是丢进winhex然后使用Uncompyle6进行反编译,命令:uncompyle6 -o ans.py kk.pyc,然后打开ans.py跑一下代码就出来了
# uncompyle6 version 3.8.0
# Python bytecode 2.7 (62211)
# Decompiled from: Python 3.9.4 (tags/v3.9.4:1f2e308, Apr 6 2021, 13:40:21) [MSC v.1928 64 bit (AMD64)]
# Embedded file name: 1.py
# Compiled at: 2016-10-18 15:12:57
def flag():
str = [
102, 108, 97, 103, 123, 51, 56, 97, 53, 55, 48, 51, 50, 48, 56, 53, 52, 52, 49, 101, 55, 125]
flag = ''
for i in str:
flag += chr(i)
print flag
数据转换到ASCII乱码
题目链接:https://adworld.xctf.org.cn/challenges/details?hash=d8d12470-34b6-4146-a27e-5cd1c057d186_2
碰到了这样的题目,给你一串十六进制的字符串,然后就没有信息了,直接转换ASCII会乱码,搜索后发现是数据偏移了
128
128
128 位,然后,mark一下博主的脚本:
cipher = 'd4e8e1f4a0f7e1f3a0e6e1f3f4a1a0d4e8e5a0e6ece1e7a0e9f3baa0c4c4c3d4c6fbb9e1e6b3e3b9e4b3b7b7e2b6b1e4b2b6b9e2b1b1b3b3b7e6b3b3b0e3b9b3b5e6fd'
print(''.join([chr(int(cipher[i:i + 2], 16) - 128) for i in range(0,len(cipher), 2)]))
strings命令
strings命令加上grep筛选和正则表达可以帮我们在文件中特定的字段,例如:strings 8deb5f0c2cd84143807b6175f58d6f3f.core| grep .*
动态图片分解
网站:https://tu.sioe.cn/gj/fenjie/
关于PDF的数据隐写
刚才做了一道大无语的题,就是:
https://adworld.xctf.org.cn/challenges/details?hash=3dc21fd0-684f-4a05-9360-4c2339c9a377_2
CSAW的一道MSIC数据隐写,数据是隐写在这个pdf中的,不过可能颜色上做了遮盖,用浏览器打开ctrl+a一键提取所有字,就能得到flag
PIL库
常用的一些功能如下:
from PIL import Image,ImageFilter,ImageGrab,ImageDraw,ImageFont
# 创建图片:宽800*高600,红色
imNew = Image.new('RGB',(800,600),(255,0,0))
# 显示图片
#imNew.show()
# 抓取屏幕
imGrab = ImageGrab.grab()
imGrab.save('grab.jpg', 'jpeg')
# 打开图片
im = Image.open('1.jpg')
# 复制图片
im1 = im.copy()
im2 = im.copy()
im3 = im.copy()
im4 = im.copy()
im5 = im.copy()
im6 = im.copy()
im7 = im.copy()
# 获得图片宽高:
w, h = im.size
print('图片宽高: * '.format(w, h))
# 缩略图(图片不会被拉伸,只能缩小)
im.thumbnail((w//2, h//2))
im.save('1_thumbnail.jpg', 'jpeg')
# 缩放(图片可能会被拉伸,可缩小也可放大)
im1 = im1.resize((w//2, h//2))
im1.save('1_resize.jpg', 'jpeg')
# 模糊图片
im2 = im2.filter(ImageFilter.BLUR)
im2.save('1_blur.jpg', 'jpeg')
# 旋转图片,逆时钟旋转45度
im3 = im3.rotate(45)
im3.save('1_rotate.jpg', 'jpeg')
# 图片转换:左右转换 FLIP_LEFT_RIGHT,上下转换 FLIP_TOP_BOTTOM
im4 = im4.transpose(Image.FLIP_LEFT_RIGHT)
im4.save('1_transpose.jpg', 'jpeg')
# 图片裁剪
box = (200,200,400,400) #左上角(0,0),4元组表示坐标位置:左、上、右、下
im5 = im5.crop(box)
im5.save('1_crop.jpg', 'jpeg')
# 图片上添加文字
draw = ImageDraw.Draw(im6)
#truetype设置字体、文字大小
#stxingka.ttf华文行楷 simkai.ttf 楷体 simli.ttf 隶书
font = ImageFont.truetype("C:\\\\WINDOWS\\\\Fonts\\\\stxingka.ttf", 20)
draw.text((100,100), ('hello word \\n你好,世界'), fill='#0000ff', font=font)
im6.save('1_drawText.jpg', 'jpeg')
# 图片上添加图片(粘贴图片)
imTmp = Image.new('RGB',(30,30),'blue')
im7.paste(imTmp, (50,50)) #第2个参数为坐标
im7.save('1_paste.jpg','jpeg')
# 图片横向拼接:拼接上面im6、im7(两张图片大小一样)
im6Width, im6Height = im6.size
imHorizontal = Image.new('RGB', (im6Width * 2, im6Height))
imHorizontal.paste(im6, (0,0))
imHorizontal.paste(im7, (im6Width,0))
imHorizontal.save('1_horizontal.jpg', 'jpeg')
# 图片竖向拼接:拼接上面im6、im7
imVertical = Image.new('RGB', (im6Width, im6Height*2))
imVertical.paste(im6, (0,0))
imVertical.paste(im7, (0,im6Height))
imVertical.save('1_vertical.jpg', 'jpeg')
ImageDraw 模块提供了 Draw 类,它能在 Image 实例上进行简单的 2D 绘画。你可以使用这个模块来创建新图像或者修饰现有图像。
有关 PIL 的更高级绘图库,可以参考 aggdraw模块
创建 Draw 类的实例
要在 Image 实例上绘制新的图样,首先要创建一个 Draw 类的实例。
这里粗略介绍下 Draw 类中的基本绘画操作函数(英文都是函数名):
- 弦/弧/扇形:
chord / arc / pieslice - 椭圆:
ellipse - 线段/多段线:
line - 点:
point - 多边形:
polygon - 矩形:
rectangle - 文字:
text - 文字大小:
textsize
详细的使用说明,请看官方文档:Draw 类的各函数使用说明
画直线
Draw 类提供了 line(xy,options) 函数绘制直线。 其中 xy 表示坐标列表,它可以是任何包含
2
2
2 元组 [(x,y),…] 或者数字 [x,y,…] 的序列对象,至少包含两个坐标:
- [ ( x 1 , y 1 ) , ( x 2 , y 2 ) , … ] [(x1, y1), (x2, y2), …] [(x1,y1),(x2,y2),…] :包含若干个元组的列表
- [ x 1 , y 1 , x 2 , y 2 , … ] [x1, y1, x2, y2, …] [x1,y1,x2,y2,…] :按照顺序包含坐标信息的列表
-
[
x
1
,
y
以上是关于CTF-MISC(入门|笔记|工具)的主要内容,如果未能解决你的问题,请参考以下文章