XxlJob 负载均衡用法及实现原理详解
Posted Dream_it_possible!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了XxlJob 负载均衡用法及实现原理详解相关的知识,希望对你有一定的参考价值。
目录
上一篇讲到XxlJob 是核心调度实现, 接着看XxJob是怎么做负载均衡的?
XxlJob能支持负载均衡,也就是说一个Job可以选择多台机器使用,只要机器处于存活状态,都是有机会执行到指定的Job, XxlJob通过负载均衡策略能有效地提高任务的并发执行效率、合理利用机器资源,以达到获取最大的收益的目的。
首先看一个负载均衡的例子。
一、配置一个应用执行器
配置AppName, AppName是需要调用executor的应用,可在应用里的application.properties进行配置,比如我配置的appName是
xxl.job.executor.appname=xxl-job-user-service
那么需要在admin server后台里输入 xxl-job-user-service, 注意application.properties 配置的appName和 admin server 里配置的名称要保持一致。
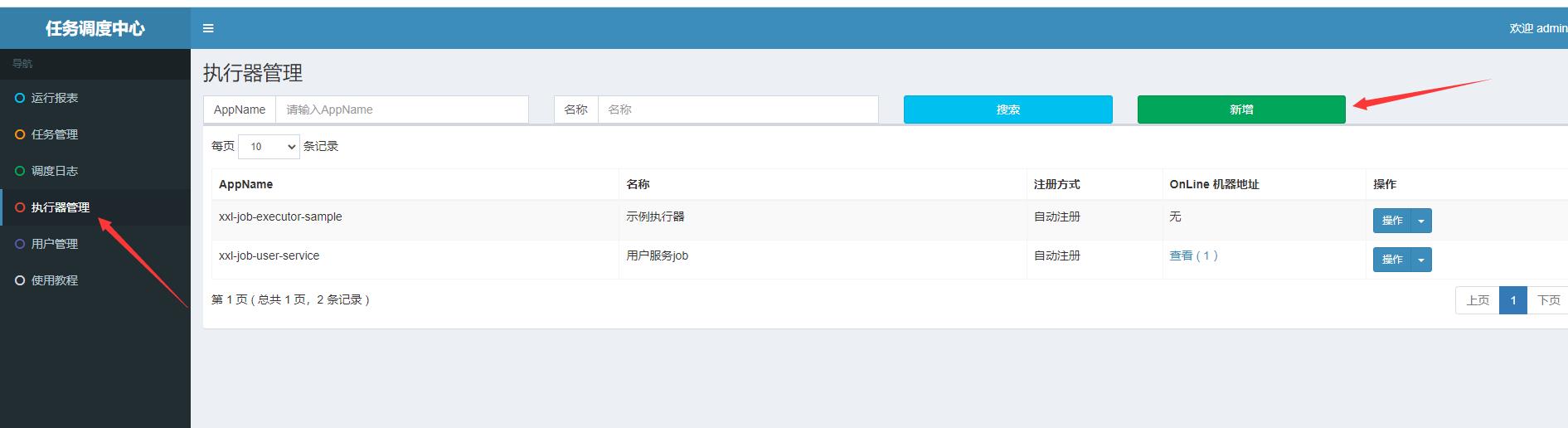
如果不保持一致,那你选择注册方式为自定注册时会出现没有ip地址的情况,也就是说无法实现自动注册。

为了更好的演示负载均衡的效果,那么需要给xxljob-user-service 再添加2个机器地址,实现3台机器负载均衡。
二、同一台机器上模拟负载均衡
1. 环境准备
正式环境的会在多个不同的机器上部署executor, 这样就能达到ip地址不同,executor的端口相同的情况,在本地我们可以这样做。
启动三个实例,配置executor的端口为9997、9998、9999。
| appName | executor address | app port |
| xxljob-user-service | http://192.168.31.180:9997 | 8081 |
| xxljob-user-service | http://192.168.31.180:9998 | 8082 |
| xxljob-user-service | http://192.168.31.180:9999 | 8083 |
同样采用自动注册的方式。
为了便于启动,在idea里用同样的方式配置2个应用UserServiceApplication02,UserServiceApplication03。
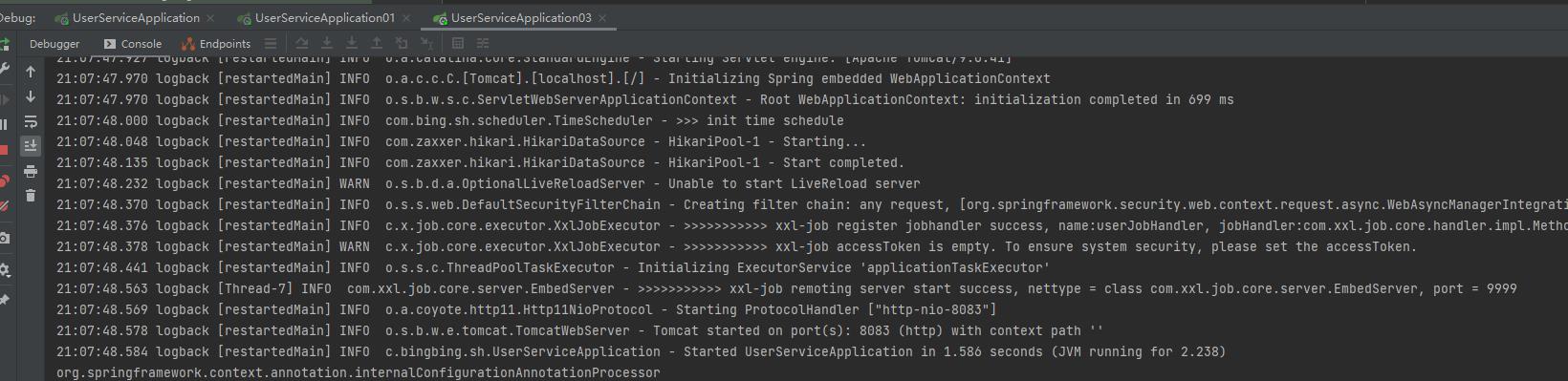
在控制台上能看到三个应用分别启动成功:
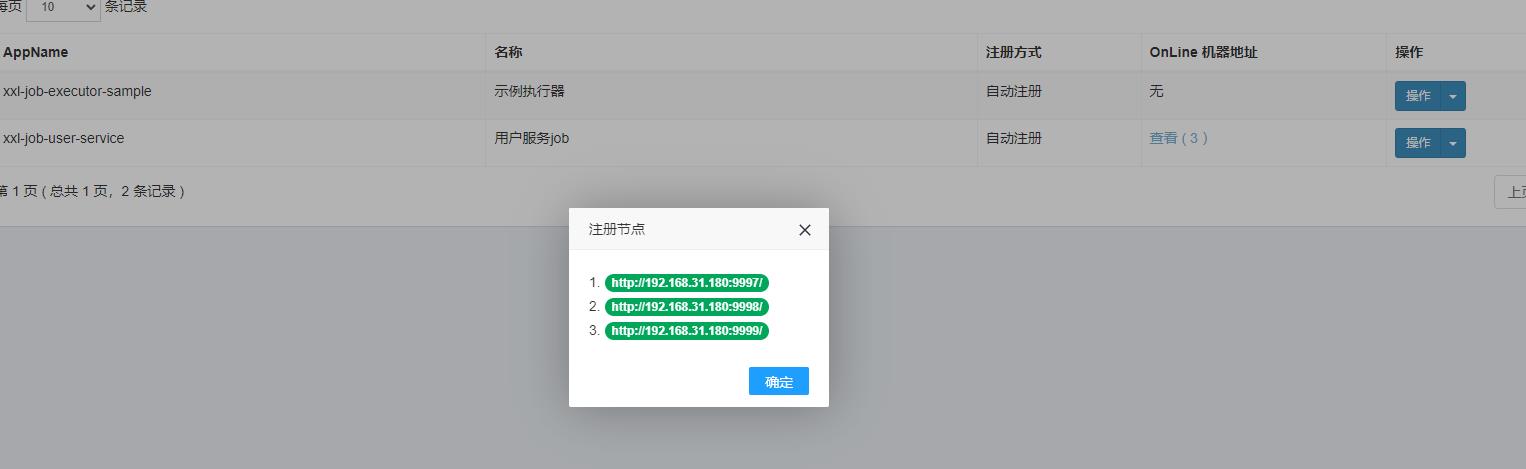
进入到XxlJob数据库, 查看xxl_job_registry表, 能发现自动多了三条记录:

6 EXECUTOR xxl-job-user-service http://192.168.31.180:9998/ 2022-04-03 21:08:22
7 EXECUTOR xxl-job-user-service http://192.168.31.180:9997/ 2022-04-03 21:08:06
8 EXECUTOR xxl-job-user-service http://192.168.31.180:9999/ 2022-04-03 21:08:19如果配置没问题,那么能在admin server的执行器菜单的执行器管理看到xxl-job-user-service 现在是有3个地址的:
2. 触发任务,选择轮询策略
进入任务管理,添加自定义任务userJobHandler
@XxlJob(value = "userJobHandler")
public void initUserHandler()
XxlJobHelper.log("user job start...");
List<String> userNames = new ArrayList<>();
userNames.add("bing");
userNames.add("zhang");
userNames.add("lian");
System.out.println(userNames);
XxlJobHelper.log("user job end...");
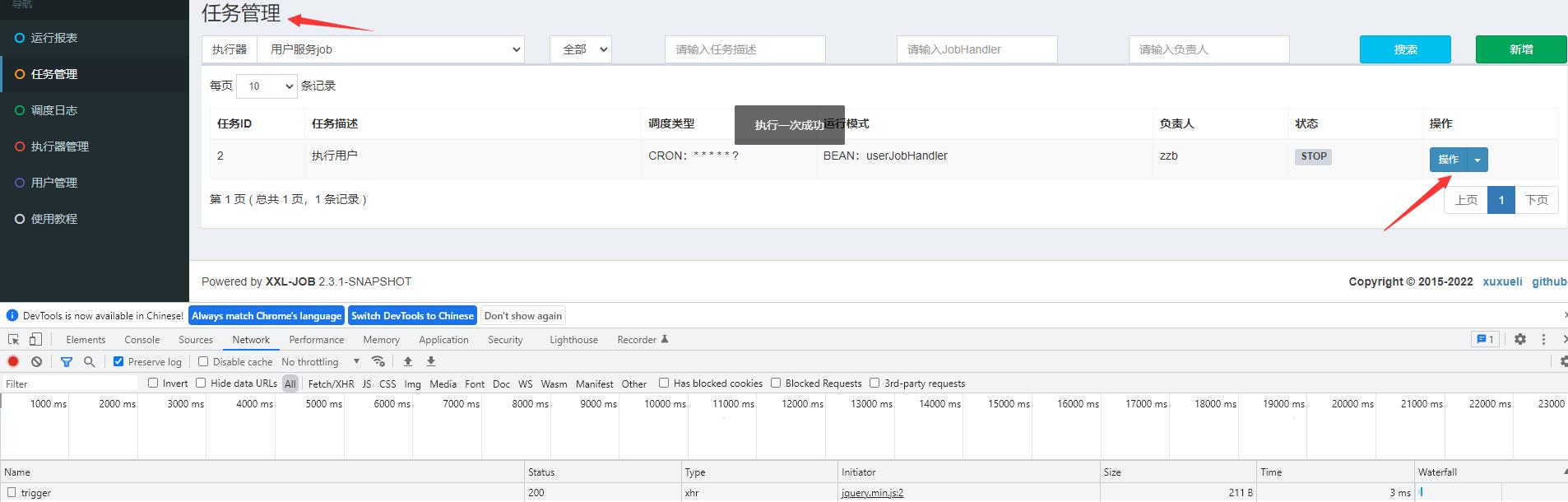 路由策略选择轮询,轮询也是负载均衡最常见的一种策略。
路由策略选择轮询,轮询也是负载均衡最常见的一种策略。
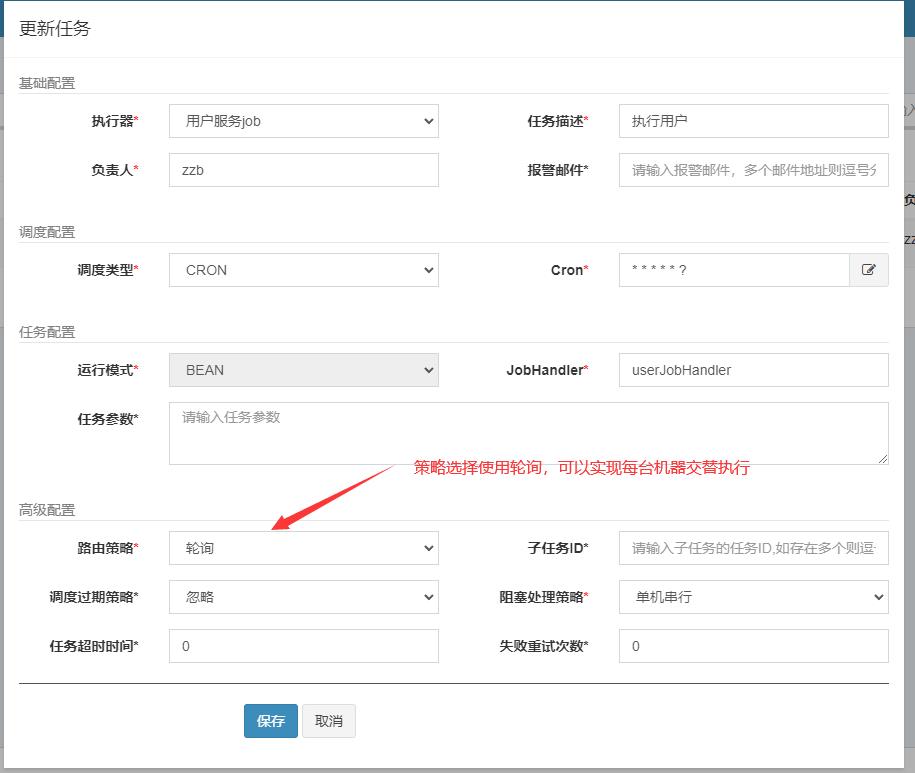
还可以选择其他策略: 随机、一致性哈希、LRU、LFU等。

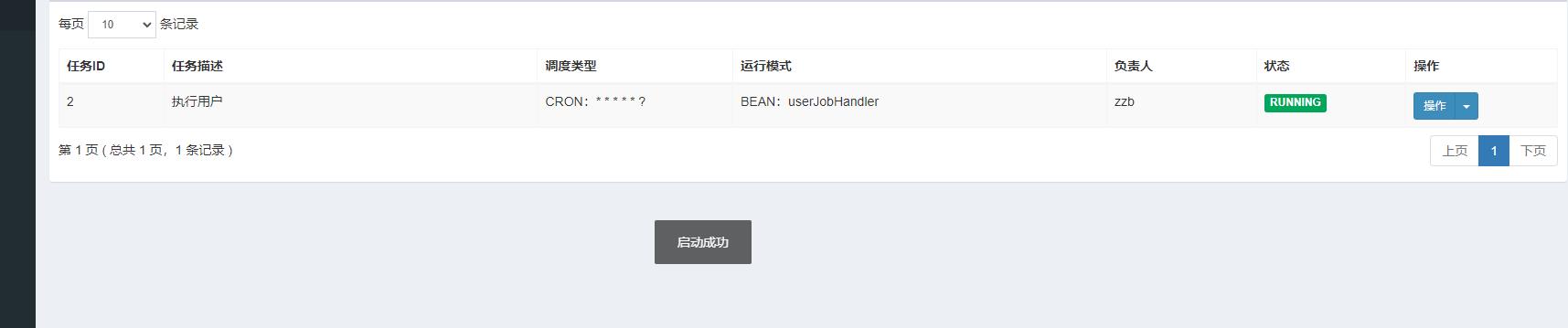
启动任务:
观察控制台打印情况,我们可以从3个应用的控制台发现,相同的打印情况,先在机器1上执行,然后机器2,接着机器3。
机器一:

机器二:

机器三:
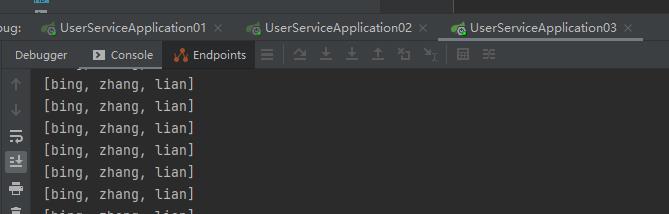
由于我设置的是每秒执行,所以我们从图片中看到的数量是不相同的,原因是我1S没法同时截图3张, 如果想观察效果可明显,可将执行的间隔设置的长一点。
3. 机器实例动态伸缩
也可以支持横向扩增机器或减少机器, 可以尝试停掉其中一个机器,或者加一个机器,发现轮询策略仍然适用。
停掉userService03, 观察结果:


查看日志,发现机器已经down掉了:

但是此时userServcie1和 userServcie2实例仍然在执行Job任务, 过一段时间后,再查看日志, 会发现不会再次调度挂掉的机器实例。

因为应用userService03停止时需要一段时间,后台线程会把数据库里的xxl_job_registry表里的address给清除掉, 后面的调度就不会再拿到address, 因此只出现了一段报红: connect refused的情况,随后继续正常执行Job。
负载均衡的效果实现了,那我接着看XxlJob是如何实现负载均衡的。
三、负载均衡原理解析
1. 根据应用名查找地址列表
在上文中,我故意设置了3个应用的名称为相同的名称, 都为xxl-job-user-service, XxlJob利用的应用名称去寻找多机器实例,我觉得有点类似于eureka的多节点的负载均衡、feign接口实现多实例负载均衡,都是通过应用名去寻找地址列表,因此这里一定要三个应用的名称一致,不管你是部署在一台机器上,还是不同的机器上,这一点至关重要,因为XxlJob在选择机器时利用AppNam 做去mysql 里查询 executor的地址列表。
上一节讲到任务的启动是通过Trigger来触发的,我们跟着上节的步伐,进入到JobTriggerPoolHelper类里的addTrigger方法。
XxlJobTrigger.trigger(jobId, triggerType, failRetryCount, executorShardingParam, executorParam, addressList);进入到processTrigger方法:

executorRouteStrategyEnum获取到的枚举实例为ROUND,那么会根据枚举的实例名称去选择对应的策略。
routeAddressResult = executorRouteStrategyEnum.getRouter().route(triggerParam, group.getRegistryList());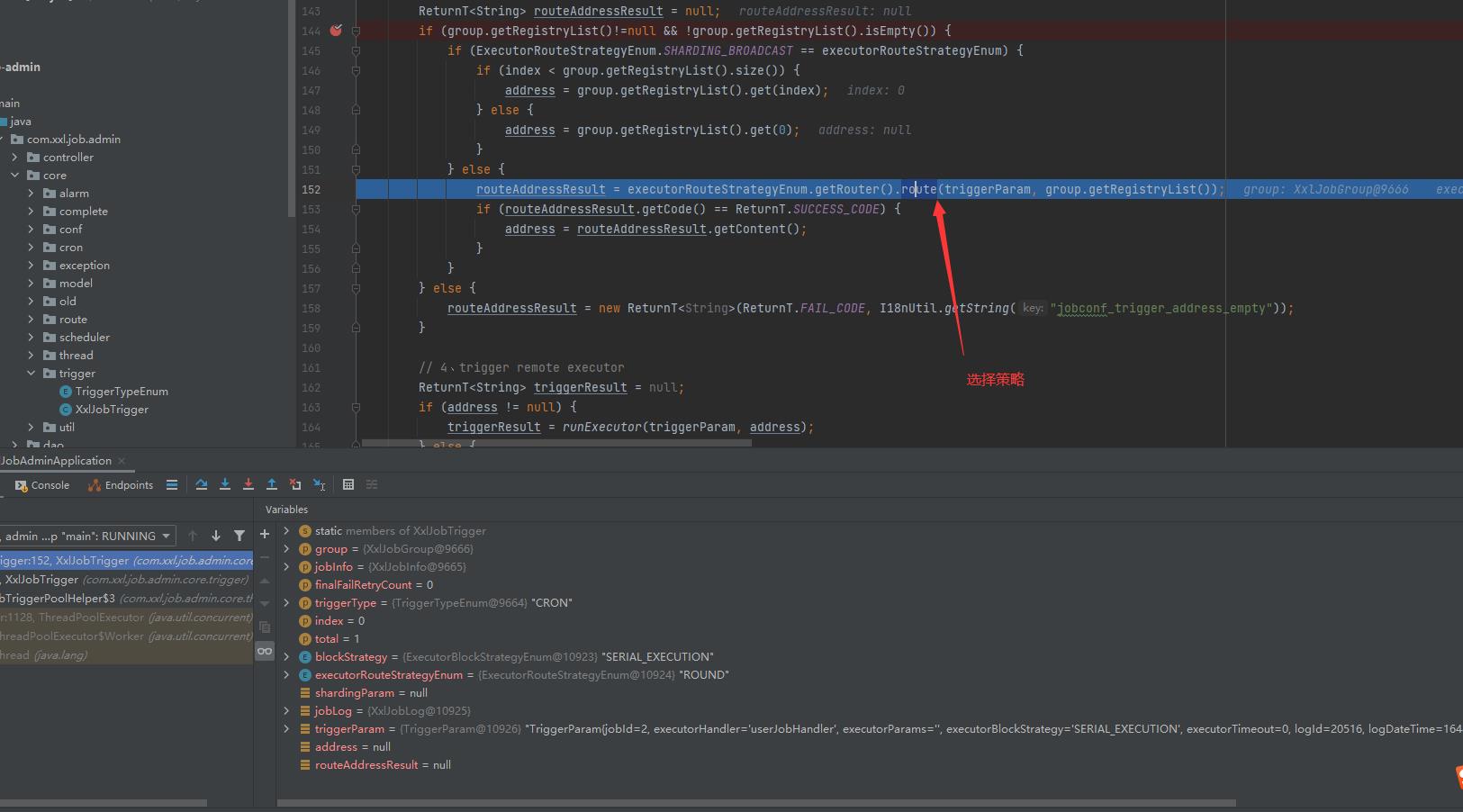 2. ExecutorRouteStrategyEnum
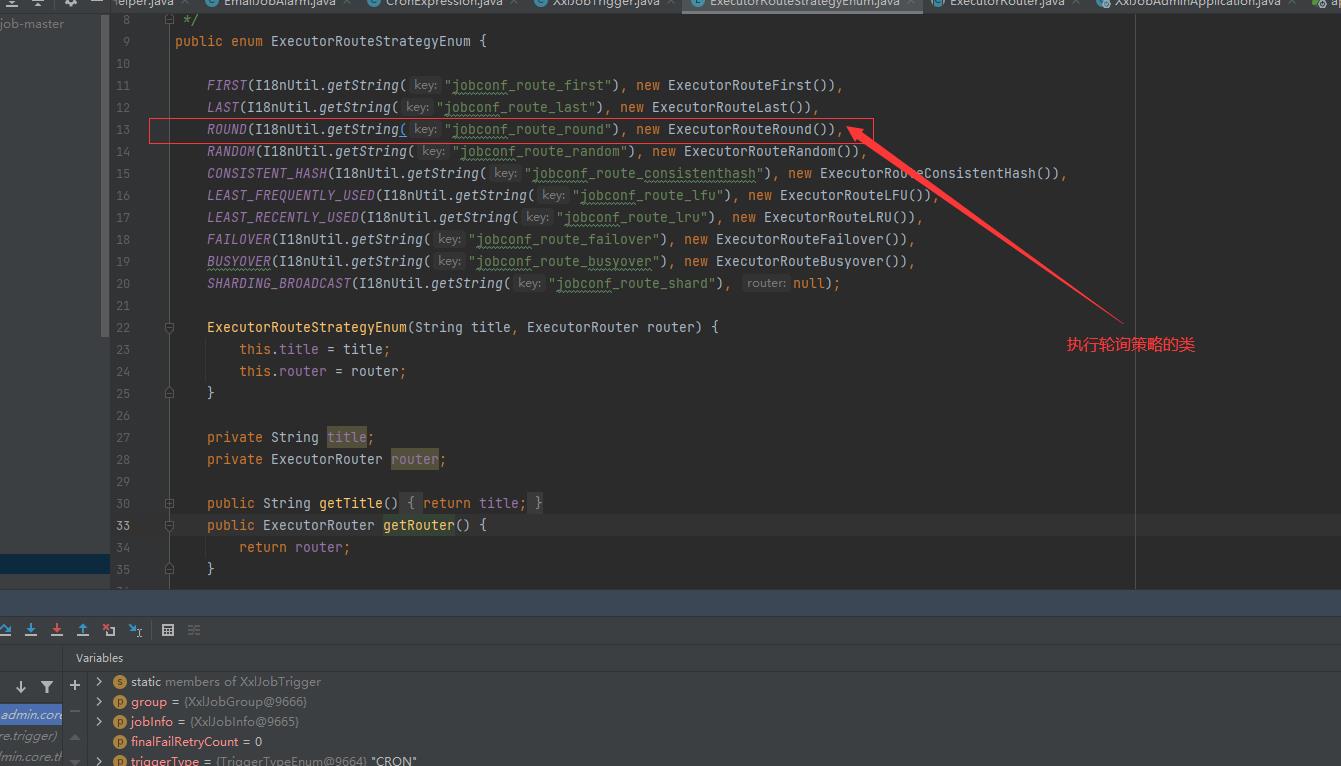
2. ExecutorRouteStrategyEnum
ExecutorRouteStrategyEnum是一个枚举类,此枚举类里根据负载均衡的策略名称来是实例化对应的策略实例类,此处的写法有点像设计模式中的策略模式,常规的策略模式会通过一个map来实例化各种策略,枚举也是一个不错的选择。
 进入到轮询的策略类ExecutorRouteRound。
进入到轮询的策略类ExecutorRouteRound。
3. ExecutorRouteRound
ExecutorRouteRound实现了ExecutorRouter接口的route方法,轮询的思想很简单,就是每次需要算出当前的addressList的同时,需要明确下一次的addressList是配置的一个next地址。
@Override
public ReturnT<String> route(TriggerParam triggerParam, List<String> addressList)
String address = addressList.get(count(triggerParam.getJobId())%addressList.size());
return new ReturnT<String>(address);
此行代码核心原理是每次trigger通过count()方法计算一个出一个index, 然后从addressList拿出一个地址返回。
计算server地址
接着看ExecutorRouteRound类里的另外一个方法count。
1) routeCountEachJob的key为JobId, value 为Job的执行的次数。
2) 每调用一次count, routeCountEachJob对应的JobId的value值+1。
3) 当前时间> CACHE_VALID_TIME 超过24小时,那么主动清理掉缓存,对于时间周期长的任务,可以不用考虑到负载均衡,因此可以清掉cache。
private static ConcurrentMap<Integer, AtomicInteger> routeCountEachJob = new ConcurrentHashMap<>();
private static long CACHE_VALID_TIME = 0;
private static int count(int jobId)
// cache clear
if (System.currentTimeMillis() > CACHE_VALID_TIME)
routeCountEachJob.clear();
CACHE_VALID_TIME = System.currentTimeMillis() + 1000*60*60*24;
AtomicInteger count = routeCountEachJob.get(jobId);
if (count == null || count.get() > 1000000)
// 初始化时主动Random一次,缓解首次压力
count = new AtomicInteger(new Random().nextInt(100));
else
// count++
count.addAndGet(1);
routeCountEachJob.put(jobId, count);
return count.get();
4. 小结
1) 负载均衡策略是在admin server 实现的, 可以根据配置来选择策略。
2) 负载均衡的最终目的是为了从多台机器中以比较合理的方式得到一个server address,最终使用该地址来到目标executor server上执行任务。
以上是关于XxlJob 负载均衡用法及实现原理详解的主要内容,如果未能解决你的问题,请参考以下文章