跨系统实时同步数据解决方案
Posted JavaEdge.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了跨系统实时同步数据解决方案相关的知识,希望对你有一定的参考价值。
数据量太大,单存储节点存不下,就只能把数据分片存储。
数据分片后,对数据的查询就没那么自由。如订单表按用户ID作为Sharding Key,就只能按用户维度查询。我是商家,我想查我店铺的订单,做不到。(强行查也不是不行,在所有分片上都查一遍,再把结果聚合,又慢又麻烦,实际意义不大)
这样的需求,普遍空间换时间。再存一份订单数据到商家订单库,然后以店铺ID作为Sharding Key分片,专门供商家查询订单。同样一份商品数据,如按关键字搜索,放在ES比mysql快几个数量级。因为数据组织方式、物理存储结构和查询方式,对查询性能影响巨大,且海量数据还会指数级地放大这性能差距。
海量数据处理都是根据业务对数据查询需求,反过来确定选择数据库、如何组织数据结构、如何分片数据,才能达到最优查询性能。一份订单数据,除了在订单库保存一份用于在线交易,还会在各种数据库中,以各种各样的组织方式存储,用于满足不同业务系统的查询需求。
如何能够做到让这么多份数据实时地保持同步?
分布式事务可解决数据一致性。可用本地消息表,把一份数据实时同步给另外两、三个数据库,这样还可以接受,太多也不行,并且对在线交易业务还有侵入性,所以分布式事务是解决不了这问题。
如何把订单数据实时、准确无误地同步到这么多异构数据。
1 Binlog+MQ=实时数据同步系统
早期大数据刚兴起,大多系统还做不到异构数据库实时同步,普遍使用ETL工具定时同步数据,在T+1时刻同步上个周期的数据,然后再做后续计算和分析。定时ETL对于一些需要实时查询数据的业务需求无能为力。所以,这种定时同步的方式,基本上都被实时同步的方式给取代。
怎么做大数据量、多个异构数据库的实时同步?利用Canal把自己伪装成一个MySQL的从库,从MySQL实时接收Binlog然后写入Redis中。把这个方法稍微改进,就用来做异构数据库的同步。
为了能够支撑下游众多的数据库,从Canal出来的Binlog数据不能直接去写下游那么多数据库:
- 写不过来
- 对每个下游数据库,它可能还有一些数据转换和过滤的工作要做。要增加一个MQ解耦上下游
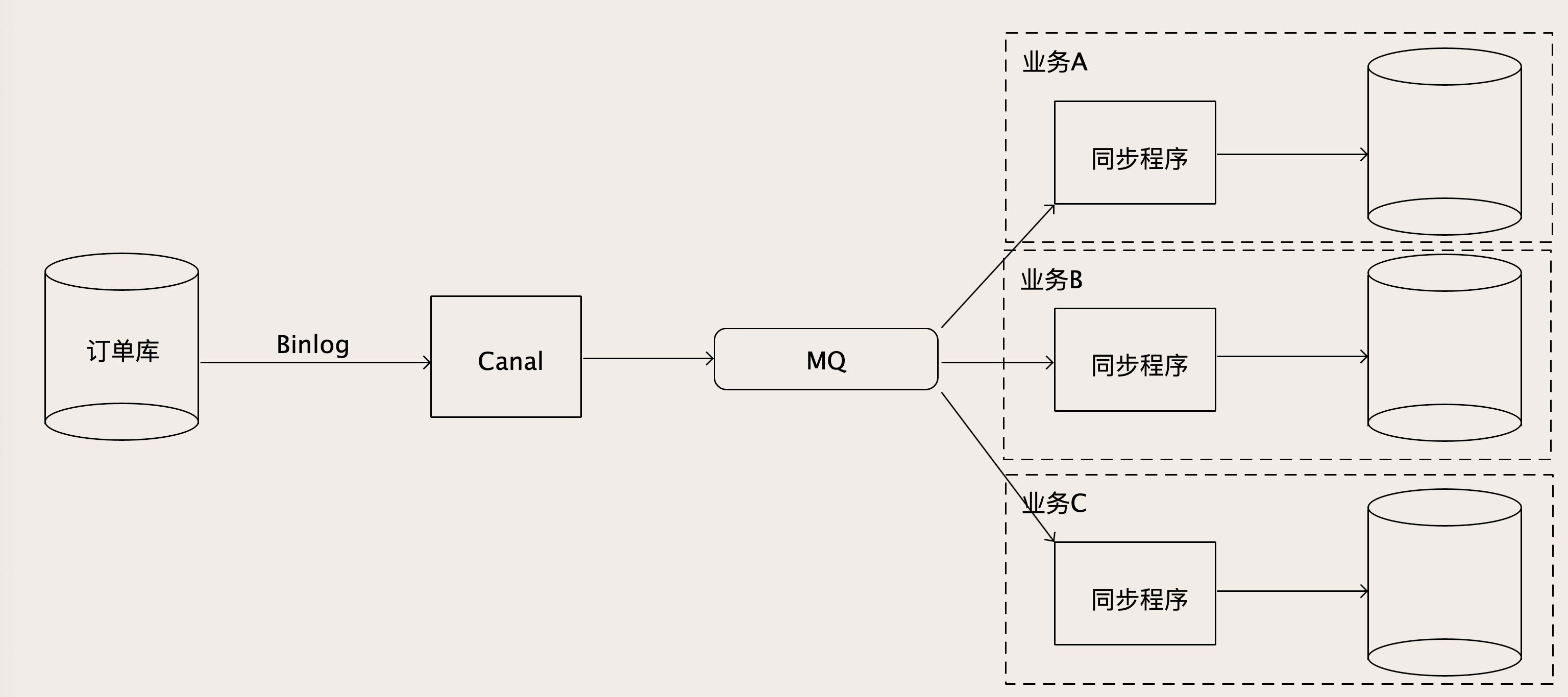
Canal从MySQL收到Binlog并解析成结构化数据之后,直接写入到MQ的一个订单Binlog主题中,然后每个要同步订单数据的业务方,都去订阅这个MQ中的订单Binlog主题,消费解析后的Binlog数据。在每个消费者自己的同步程序中,它既可以直接入库,也可以做一些数据转换、过滤或者计算之后再入库。
2 如何保证数据同步的实时性
这方法看起来不难,但易出现性能问题。有些接收Binlog消息的下游业务,数据实时性要求高,不容忍太高的同步时延。比如说,每个电商在大促的时候,都会有一个大屏幕,实时显示现有多少笔交易,交易额。
大促时,数据量大、并发高、数据库中的数据变动频繁,同步的Binlog流量也大。为保证同步实时性,整个数据同步链条上的任何一个环节,处理速度都得跟得上。
源头的订单库,若它出现繁忙,对业务的影响就不只是大屏延迟,那就影响到用户下单,这问题是数据库本身要解决,我们不考虑。
Canal和MQ这两个环节,由于没业务逻辑,性能都好。一般易成为性能瓶颈的就是消费MQ的同步程序,因为有一些业务逻辑,且若下游数据库写性能跟不上,表象也是这个同步程序处理性能上不来,消息积压在MQ。
能不能多加一些同步程序的实例数或增加线程数,通过增加并发提升处理能力?这的并发数,还真不是随便说扩容就可以就扩容。MySQL主从同步Binlog是个单线程同步过程。从库执行Binlog须按序执行,才能保证数据和主库是一样。为确保数据一致性,Binlog顺序很重要,绝对不能乱序。 严格来说,对每个MySQL实例,整个处理链条都必须是单线程串行执行,MQ主题也设置为只有1个分区(队列),才能保证数据同步过程中的Binlog严格有序,写到目标数据库的数据才正确。
那单线程处理速度上不去,消息越积压越多,不无解?办法还是有,但得和业务结合。我们并不需要对订单库所有更新操作都严格有序执行,如A、B两个订单号不同的订单,这两个订单谁先更新谁后更新不影响数据一致性。但同一订单,若更新的Binlog执行顺序错,那同步出来的订单数据真错。即只要保证每个订单的更新操作日志的顺序别乱。这种一致性为因果一致性(Causal Consistency),有因果关系的数据之间严格保证顺序,没有因果关系的数据之间的顺序无所谓。就可并行数据同步。
先根据下游同步程序的消费能力,计算出要多少并发
然后设置MQ中主题的分区(队列)数量和并发数一致。因为MQ可保证同一分区内,消息不乱序,所以把具有因果关系的Binlog都放到相同分区,就可保证同步数据因果一致性。对应订单库,相同订单号的Binlog发到同一分区。
这和数据库分片有点像?分片算法就可复用,如最简单的哈希算法,Binlog中订单号除以MQ分区总数,余数就是这条Binlog消息发往分区号。
Canal自带分区策略就支持按照指定Key,把Binlog哈希到下游的MQ中去,具体的配置Canal接入MQ的文档。
3 总结
对于海量数据,必须要按照查询方式选择数据库类型和数据的组织方式,才能达到理想的查询性能。这就需要把同一份数据,按照不同的业务需求,以不同的组织方式存放到各种异构数据库中。因为数据的来源大多都是在线交易系统的MySQL数据库,所以我们可以利用MySQL的Binlog来实现异构数据库之间的实时数据同步。
为了能够支撑众多下游数据库实时同步的需求,可通过MQ解耦上下游,Binlog先发送到MQ中,下游各业务方可以消费MQ中的消息再写入各自DB。
若下游处理能力不满足要求,可增加MQ中的分区数量实现并发同步,但要结合同步的业务数据特点,把具有因果关系的数据哈希到相同分区,避免因并发乱序而出现数据同步错误的问题。
FAQ
这种数据同步架构下,若下游某同步程序或数据库问题,需要把Binlog回退到某时间点重新同步,怎么解决?
对象存储并不是基于日志来进行主从复制的。假设我们的对象存储是一主二从三个副本,采用半同步方式复制数据,也就是主副本和任意一个从副本更新成功后,就给客户端返回成功响应。主副本所在节点宕机之后,这两个从副本中,至少有一个副本上的数据是和宕机的主副本上一样的,我们需要找到这个副本作为新的主副本,才能保证宕机不丢数据。但是没有了日志,如果这两个从副本上的数据不一样,我们如何确定哪个上面的数据是和主副本一样新呢?
一般基于版本号。在Leader上,KEY每更新一次,KEY的版本号就加1,版本号作为KV的一个属性,一并复制到从节点上,通过比较版本号就可以知道哪个节点上的数据最新。
比较时间戳的方式理论可行,但实际难实现,因为它要求集群上的每个节点的时钟都必须时刻保持同步,这个要求往往非常难达到。
如果预估了分区(队列)数量之后 随着业务数据的增长 需要增加分区 提高并发 怎么去做扩容?
因为统一笔订单需要打到同一个分区上
\\1. 停掉Canel;
\\2. 等MQ中所有的消息都消费完了。
\\3. 扩容MQ分区数,增加消费者实例数量。
\\4. 重新启动Canel。
mq 可以有多个 sharding key 是订单号,这样同一个订单号就可以保证到同一个mq里边去,保证顺序,但是canal不还是必须只有一个 不会成为瓶颈?
一般Canal是不会成为瓶颈的,你想,MySQL的主从同步也是单线程的,正常情况下也都不会有延迟的。
都用mq了还能是实时同步数据嘛?一般使用MQ,也可以做到秒级延迟。
今把binlog回退到某个时间点开始重新同步,这个需要mq消费端的消费进度支持重置,重置到过去的某一个消费进度就可以。本身row格式的binlog就是幂等的,mq也要求消费者必须具备幂等性。所以,自然就支持重置。
如果应用跨云(AWS和阿里)部署,并且使用的数据库不是MySQL而是PG,有什么好方法可以实时这种跨云数据同步?PG也有WAL,和MySQL的Binlog是类似的。参考一下这个开源项目:https://github.com/debezium/debezium
下游的某个同步程序或数据库出了问题,可以抛出异常不确认消息,这样,等数据库好了,再次进行消费,不过这样性能会差点,数据也有延迟。如果不想影响多个系统共用的MQ,可以把数据再发送到某个业务系统单独的MQ中去,后续自己单独慢慢消费。
以上是关于跨系统实时同步数据解决方案的主要内容,如果未能解决你的问题,请参考以下文章
ElasticSearch实战(四十八)-Debeizum 实现 MySQL 数据实时同步方案
ElasticSearch实战(四十八)-Debeizum 实现 MySQL 数据实时同步方案
flink实时读取mongodb方案调研-实现mongodb cdc
flink实时读取mongodb方案调研-实现mongodb cdc