广州市二手房源数据采集和可视化分析(链家二手房)Python
Posted JF Coder
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了广州市二手房源数据采集和可视化分析(链家二手房)Python相关的知识,希望对你有一定的参考价值。
使用:Jupyter,Pyecharts,pandas等
实现对爬取数据的可视化,和聚合分析使用Kmeans等
爬取链家二手房数据
注意!可能链家网站的样式有变,爬取时注意!
#author:JianFeiGan
#email:JianFeiGan@aliyun.com
#Date:2021/6/13
import urllib.request
from bs4 import BeautifulSoup
import pandas as pd
def Disguise():
#伪装浏览器访问
header = ('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64)AppleWebKit/537.36 (Khtml, like Gecko) Chrome/50.0.2661.102 Safari/537.36')
#伪装浏览器
opener = urllib.request.build_opener()
opener.addheaders = [header]
#将伪装浏览器设为全局
urllib.request.install_opener(opener)
def Get_page(url,num):
#获取网页内容
try:
#获取网页的内容,并使用BeautifulSoup解析以便后面的信息提取
page = urllib.request.urlopen(url).read()
soup = BeautifulSoup(page, 'lxml')
print('--------第%d页抓取成功--------'%num)
return soup
except urllib.request.URLError as e:
if hasattr(e,'code'):
print('错误原因:',e.code)
if hasattr(e,'reason'):
print('错误原因:',e.reason)
def Get_House_info(page):
#提取网页中的房子信息,并把信息以DataFrame的形式返回
item =
item['house_position'] = [i.get_text().strip().split('-')[0] for i in page.select('div[class="positionInfo"]')] # 位置
item['house_name'] = [i.get_text().strip().split('|')[0] for i in page.select('div[class="houseInfo"]')] # 户型
item['house_type'] = [i.get_text().strip().split('|')[1] for i in page.select('div[class="houseInfo"]')] #面积
item['house_area'] = [i.get_text().strip().split('|')[2] for i in page.select('div[class="houseInfo"]')] #朝向
item['house_interest'] = [i.get_text().strip().split('/')[0] for i in page.select('div[class="followInfo"]')] #关注人数
item['house_issuedate'] = [i.get_text().strip().split('/')[1] for i in page.select('div[class="followInfo"]')] #发布时间
item['house_price'] = [i.get_text().strip() for i in page.select('div[class="totalPrice"] span')] #房价
item['house_unit_price'] = [i.get_text().strip() for i in page.select('div[class="unitPrice"] span')] #单位价格
return pd.DataFrame(item)
def main():
#主函数
filename = 'E:\\大三下学期工作空间\\Python\\lianjia.csv'
Disguise()
house_data = []
#二手房网页总共只有100页,这里可以使用一个for循环对网址进行更新
for pg in range(1,101):
lianjia_url = 'https://gz.lianjia.com/ershoufang/pg' + str(pg) +'/'
page = Get_page(lianjia_url,pg)
if len(page) > 0:
house_info = Get_House_info(page)
#把每一页提取到的信息都存在一个list里面
house_data.append(house_info)
#对list里的DataFrame进行纵向拼接
data = pd.concat(house_data, ignore_index = True)
#将信息保存到CSV文件中
data.to_csv(filename, index = False,encoding='gbk')
print('------写入完毕------')
if __name__ == '__main__':
main()
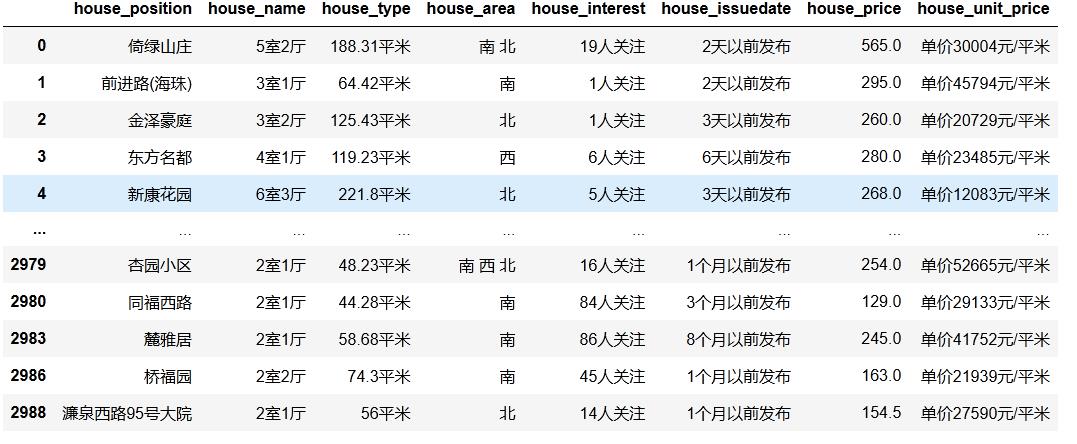
去重缺省等数据处理
#去重缺省
data = pd.read_csv(r'E:\\大三下学期工作空间\\Python\\lianjia.csv',encoding='gbk') # 导入数据
data.drop_duplicates(subset='house_position',keep='first',inplace=True) #去重
data.dropna() #去缺省
data[data.duplicated()] #显示重复行,观察结果,无重复数据
词云展示房源分布
#author:JianFeiGan
#email:JianFeiGan@aliyun.com
#Date:2021/6/13
from wordcloud import WordCloud #词云展示房源分布
import matplotlib.pyplot as plt
import pandas as pd
from pandas import DataFrame
word_list=data['house_position'].fillna('0').tolist()
new_text=''.join(word_list)
wordcloud=WordCloud(font_path='simhei.ttf',background_color="black").generate(new_text)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()

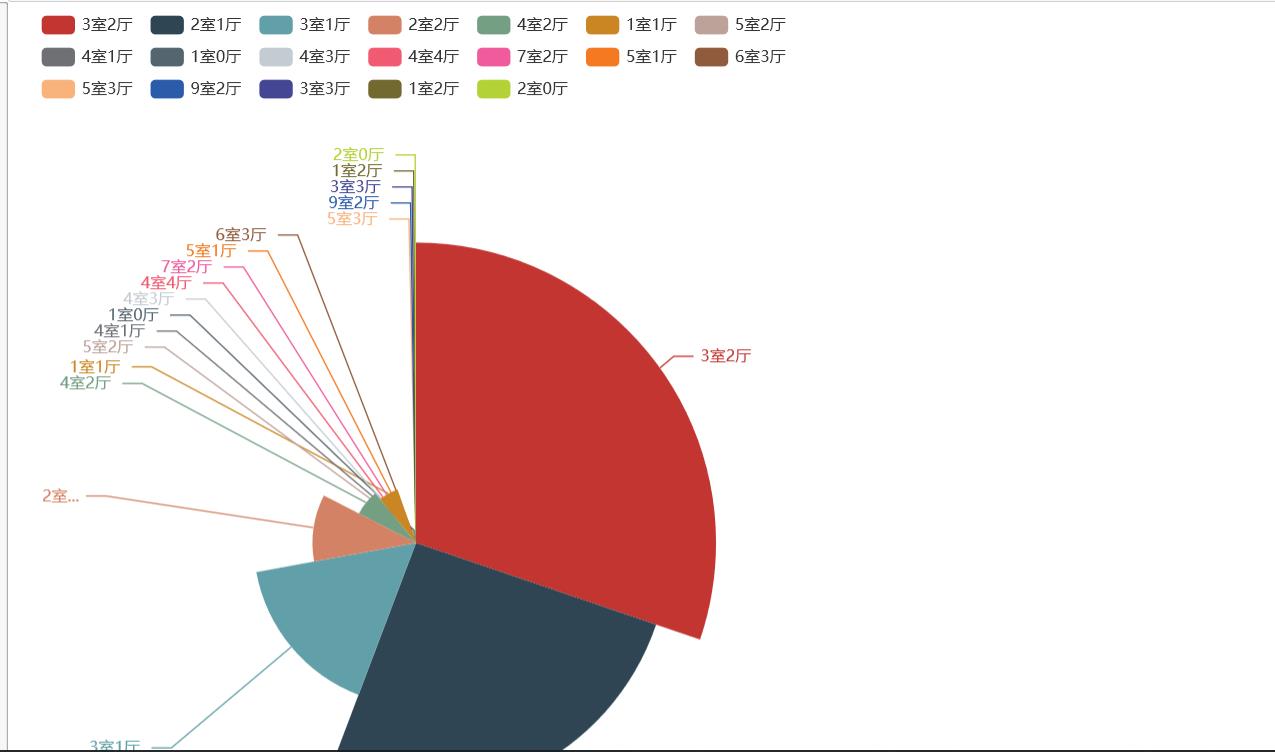
市场提供房型的规格占比
#author:JianFeiGan
#email:JianFeiGan@aliyun.com
#Date:2021/6/13
from pyecharts.charts import Pie
import pyecharts.options as opts #市场提供房型的规格占比
import numpy as np
from collections import Counter
house_name_list=data.house_name.tolist() #转换成数组
house_name_count=Counter(house_name_list)
total_house=house_name_count.most_common()
a =[]
b = []
for s in total_house:
a.append(s[0])
b.append(s[1])
#print(a)
#print(b)
(
Pie(init_opts=opts.InitOpts(width='600px',height='800px'))#默认900,600
.add(series_name='', data_pair=[(j, i) for i, j in zip(b, a)], rosetype='radius')#南丁格尔图
).render_notebook()
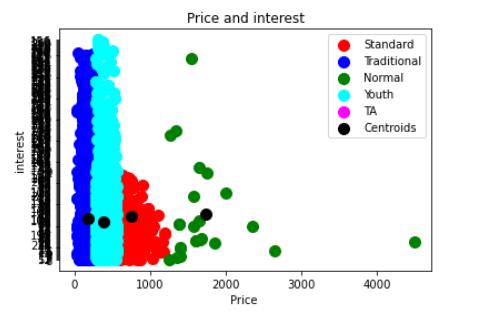
KMeans聚类分析
#author:JianFeiGan
#email:JianFeiGan@aliyun.com
#Date:2021/6/13
#聚类分析
from sklearn.cluster import KMeans
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv(r'E:\\大三下学期工作空间\\Python\\lianjia.csv',encoding='gbk') # 导入数据
df.head()
S = df['house_interest'].str.slice(0,-4)
df['note'] = S #提取数字,并另加一列
X = df.iloc[:,[6,8]].values #价钱和关注人数
kmeans = KMeans(n_clusters=4,init='k-means++',random_state=42)
y_kmeans = kmeans.fit_predict(X)
y_kmeans
plt.scatter(X[y_kmeans==0,0],X[y_kmeans==0,1],s=100,c='red',label='Standard')
plt.scatter(X[y_kmeans==1,0],X[y_kmeans ==1,1],s=100,c='blue',label='Traditional')
plt.scatter(X[y_kmeans==2,0],X[y_kmeans==2,1],s=100,c='green',label='Normal')
plt.scatter(X[y_kmeans==3,0],X[y_kmeans==3,1],s=100,c='cyan',label='Youth')
plt.scatter(X[y_kmeans==4,0],X[y_kmeans==4,1],s=100,c='magenta',label='TA')
plt.scatter(kmeans.cluster_centers_[:,0],kmeans.cluster_centers_[:,1],s=100,c='black',label='Centroids') #质心位置 黑色
#prddicted_label=kmeans.predict([[1000,10]])
#print(prddicted_label)
plt.title('Price and interest')
plt.xlabel('Price ')
plt.ylabel('interest')
plt.legend()
plt.show()
#另一种聚类分析
from sklearn.cluster import KMeans
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv(r'E:\\大三下学期工作空间\\Python\\lianjia.csv',encoding='gbk') # 导入数据
data.house_type=data.house_type.str.slice(0,-3) #去除平米
#挑选出前两个维度作为x轴和y轴,你也可以选择其他维度
data01 = data.values[:,2::4] #平米 关注人数
x_axis = data.house_type.str.slice(0,-3).tolist() #平米
y_axis = data.house_interest.str.slice(0,-4).tolist() #关注人数
#print(y_axis)
#print(x_axis)
#分几类
model = KMeans(n_clusters=3)
#训练模型
model.fit(data01)
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300, #n_clusters:分成的簇数 init:初始化质心的方法 init : ‘k-means++’, ‘random’ or an ndarray
n_clusters=3, n_init=10, n_jobs=None, precompute_distances='auto', #n_init::用不同的质心初始化值运行算法的次数
random_state=None, tol=0.0001, verbose=0)
#选取数据,进行预测
#prddicted_label= model.predict([[100,900]])
#print(prddicted_label)
#预测全部数据
all_predictions = model.predict(data01)
#打印出来数据的聚类散点图
plt.scatter(x_axis, y_axis, c=all_predictions)
plt.title('Price and interest')
plt.xlabel('Interest')
plt.ylabel('Price ')
plt.show()
点赞收藏
以上是关于广州市二手房源数据采集和可视化分析(链家二手房)Python的主要内容,如果未能解决你的问题,请参考以下文章