Kubernetes In Action :1Kubernetes介绍
Posted 沛沛老爹
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kubernetes In Action :1Kubernetes介绍相关的知识,希望对你有一定的参考价值。

1 Kubernetes介绍
本章内容涵盖
- 应用的开发和部署方式在近几年的发展趋势
- 容器如何保障应用间的隔离性,以及减少应用对部署环境的依赖性
- Docker容器如何在Kubernetes系统中应用
- Kubernetes如何提高开发人员和系统管理员的工作效率
在过去,多数的应用都是大型单体应用,以单个进程或几个进程的方式,运行于几台服务器之上。这些应用的发布周期长,而且迭代也不频繁。每个发布周期结束前,开发者会把应用程序打包后交付给运维团队,运维人员再处理部署、监控事宜,并且在硬件发生故障时手动迁移应用。
今天,大型单体应用正被逐渐分解成小的、可独立运行的组件,我们称之为微服务。微服务彼此之间解耦,所以它们可以被独立开发、部署、升级、伸缩。这使得我们可以对每一个微服务实现快速迭代,并且迭代的速度可以和市场需求变化的速度保持一致。
但是,随着部署组件的增多和数据中心的增长,配置、管理并保持系统的正常运行变得越来越困难。如果我们想要获得足够高的资源利用率并降低硬件成本,把组件部署在什么地方变得越来越难以决策。手动做所有的事情,显然不太可行。我们需要一些自动化的措施,包括自动调度、配置、监管和故障处理。这正是Kubernetes的用武之地。
Kubernetes使开发者可以自主部署应用,并且控制部署的频率,完全脱离运维团队的帮助。Kubernetes同时能让运维团队监控整个系统,并且在硬件故障时重新调度应用。系统管理员的工作重心,从监管应用转移到了监管Kubernetes,以及剩余的系统资源,因为Kubernetes会帮助监管所有的应用。注意 Kubernetes是希腊语中的“领航员”或“舵手”的意思。Kubernetes有几种不同的发音方式。许多人把它读成Koo-ber-nay-tace,还有一些人读成Koo-bernetties。不管你用哪种方式,大家都知道你指的是这个单词。
Kubernetes抽象了数据中心的硬件基础设施,使得对外暴露的只是一个巨大的资源池。它让我们在部署和运行组件时,不用关注底层的服务器。使用Kubernetes部署多组件应用时,它会为每个组件都选择一个合适的服务器,部署之后它能够保证每个组件可以轻易地发现其他组件,并彼此之间实现通信。
所以说应用Kubernetes可以给大多数场景下的数据中心带来增益,这不仅包括内部部署(on-premises)的数据中心,如果是类似云厂商提供的那种超大型数据中心,这种增益是更加明显的。通过Kubernetes,云厂商提供给开发者的是一个可部署且可运行任何类型应用的简易化云平台,云厂商的系统管理员可以不用关注这些海量应用到底是什么。
随着越来越多的大公司把Kubernetes作为它们运行应用的最佳平台,Kubernetes帮助企业标准化了无论是云端部署还是内部部署的应用交付方式。
1.2 介绍容器技术
在1.1节中,罗列了一个不全面的开发和运维团队如今所面临的问题列表,尽管你有很多解决这些问题的方式,但本书将关注如何用Kubernetes解决。
Kubernetes使用Linux容器技术来提供应用的隔离,所以在钻研Kubernetes之前,需要通过熟悉容器的基本知识来更加深入地理解Kubernetes,包括认识到存在的容器技术分支,诸如Docker或者rkt。
1.2.1 什么是容器
在1.1.1节中,我们看到在同一台机器上运行的不同组件需要不同的、可能存在冲突的依赖库版本,或者是其他的不同环境需求。
当一个应用程序仅由较少数量的大组件构成时,完全可以接受给每个组件分配专用的虚拟机,以及通过给每个组件提供自己的操作系统实例来隔离它们的环境。但是当这些组件开始变小且数量开始增长时,如果你不想浪费硬件资源,又想持续压低硬件成本,那就不能给每个组件配置一个虚拟机了。但是这还不仅仅是浪费硬件资源,因为每个虚拟机都需要被单独配置和管理,所以增加虚拟机的数量也就导致了人力资源的浪费,因为这增加了系统管理员的工作负担。
用Linux容器技术隔离组件
开发者不是使用虚拟机来隔离每个微服务环境(或者通常说的软件进程),而是正在转向Linux容器技术。容器允许你在同一台机器上运行多个服务,不仅提供不同的环境给每个服务,而且将它们互相隔离。容器类似虚拟机,但开销小很多。
一个容器里运行的进程实际上运行在宿主机的操作系统上,就像所有其他进程一样(不像虚拟机,进程是运行在不同的操作系统上的)。但在容器里的进程仍然是和其他进程隔离的。对于容器内进程本身而言,就好像是在机器和操作系统上运行的唯一一个进程。
比较虚拟机和容器
和虚拟机比较,容器更加轻量级,它允许在相同的硬件上运行更多数量的组件。主要是因为每个虚拟机需要运行自己的一组系统进程,这就产生了除组件进程消耗以外的额外计算资源损耗。从另一方面说,一个容器仅仅是运行在宿主机上被隔离的单个进程,仅消耗应用容器消耗的资源,不会有其他进程的开销。
因为虚拟机的额外开销,导致没有足够的资源给每个应用开一个专用的虚拟机,最终会将多个应用程序分组塞进每个虚拟机。当使用容器时,正如图1.4所示,能够(也应该)让每个应用有一个容器。最终结果就是可以在同一台裸机上运行更多的应用程序。

图1.4 使用虚拟机来隔离一组应用程序与使用容器隔离单个应用程序
当你在一台主机上运行三个虚拟机的时候,你拥有了三个完全分离的操作系统,它们运行并共享一台裸机。在那些虚拟机之下是宿主机的操作系统与一个管理程序,它将物理硬件资源分成较小部分的虚拟硬件资源,从而被每个虚拟机里的操作系统使用。运行在那些虚拟机里的应用程序会执行虚拟机操作系统的系统调用,然后虚拟机内核会通过管理程序在宿主机上的物理来CPU执行x86指令。注意 存在两种类型的管理程序。第一种类型的管理程序不会使用宿主机OS,而第二种类型的会。
多个容器则会完全执行运行在宿主机上的同一个内核的系统调用,此内核是唯一一个在宿主机操作系统上执行x86指令的内核。CPU也不需要做任何对虚拟机能做那样的虚拟化(如图 1.5所示)。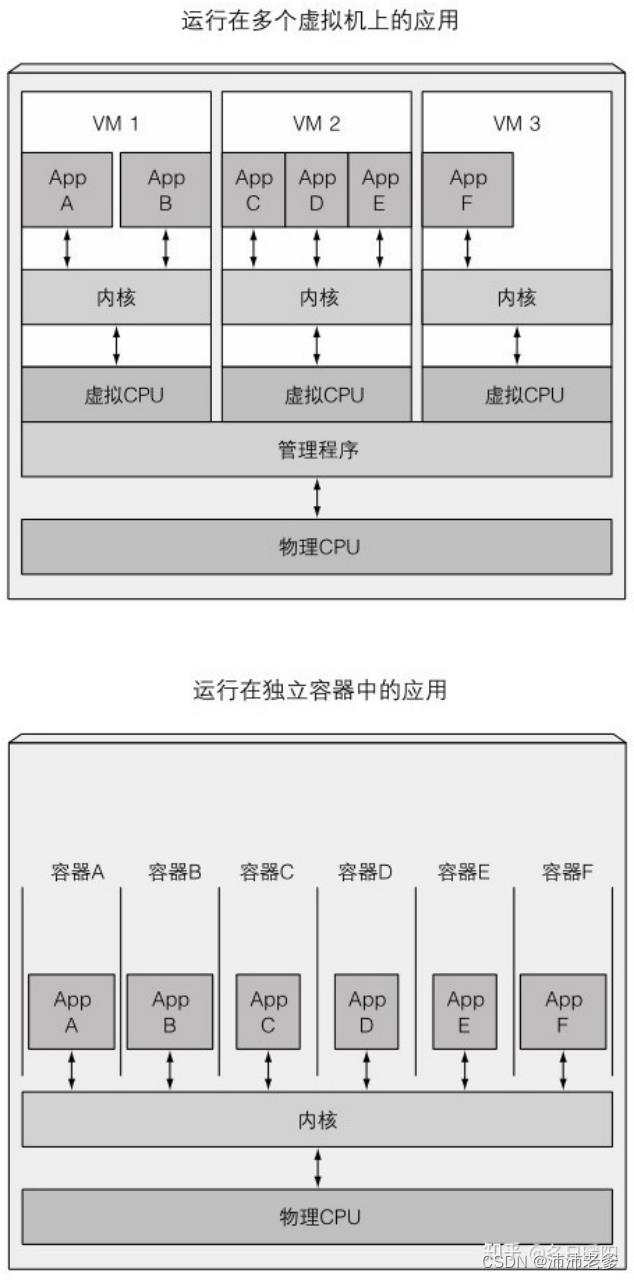
图1.5 虚拟机和容器中的应用程序对CPU的不同使用方式
虚拟机的主要好处是它们提供完全隔离的环境,因为每个虚拟机运行在它自己的Linux内核上,而容器都是调用同一个内核,这自然会有安全隐患。如果你的硬件资源有限,那当你有少量进程需要隔离的时候,虚拟机就可以成为一个选项。为了在同一台机器上运行大量被隔离的进程,容器因它的低消耗而成为一个更好的选择。记住,每个虚拟机运行它自己的一组系统服务,而容器则不会,因为它们都运行在同一个操作系统上。那也就意味着运行一个容器不用像虚拟机那样要开机,它的进程可以很快被启动。
容器实现隔离机制介绍
你可能会好奇,如果多个进程运行在同一个操作系统上,那容器到底是怎样隔离它们的。有两个机制可用:第一个是Linux命名空间,它使每个进程只看到它自己的系统视图(文件、进程、网络接口、主机名等);第二个是Linux控制组(cgroups),它限制了进程能使用的资源量(CPU、内存、网络带宽等)。
用Linux命名空间隔离进程
默认情况下,每个Linux系统最初仅有一个命名空间。所有系统资源(诸如文件系统、用户ID、网络接口等)属于这一个命名空间。但是你能创建额外的命名空间,以及在它们之间组织资源。对于一个进程,可以在其中一个命名空间中运行它。进程将只能看到同一个命名空间下的资源。当然,会存在多种类型的多个命名空间,所以一个进程不单单只属于某一个命名空间,而属于每个类型的一个命名空间。
存在以下类型的命名空间:
- Mount(mnt)
- Process ID(pid)
- Network(net)
- Inter-process communicaion(ipd)
- UTS
- User ID(user)
每种命名空间被用来隔离一组特定的资源。例如,UTS命名空间决定了运行在命名空间里的进程能看见哪些主机名和域名。通过分派两个不同的UTS命名空间给一对进程,能使它们看见不同的本地主机名。换句话说,这两个进程就好像正在两个不同的机器上运行一样(至少就主机名而言是这样的)。
同样地,一个进程属于什么Network,命名空间决定了运行在进程里的应用程序能看见什么网络接口。每个网络接口属于一个命名空间,但是可以从一个命名空间转移到另一个。每个容器都使用它自己的网络命名空间,因此每个容器仅能看见它自己的一组网络接口。
现在你应该已经了解命名空间是如何隔离容器中运行的应用的。
限制进程的可用资源
另外的隔离性就是限制容器能使用的系统资源。这通过cgroups来实现。cgroups是一个Linux内核功能,它被用来限制一个进程或者一组进程的资源使用。一个进程的资源(CPU、内存、网络带宽等)使用量不能超出被分配的量。这种方式下,进程不能过分使用为其他进程保留的资源,这和进程运行在不同的机器上是类似的。
1.2.2 Docker容器平台介绍
尽管容器技术已经出现很久,却是随着Docker容器平台的出现而变得广为人知。Docker是第一个使容器能在不同机器之间移植的系统。它不仅简化了打包应用的流程,也简化了打包应用的库和依赖,甚至整个操作系统的文件系统能被打包成一个简单的可移植的包,这个包可以被用来在任何其他运行Docker的机器上使用。
当你用Docker运行一个被打包的应用程序时,它能看见你捆绑的文件系统的内容,不管运行在开发机器还是生产机器上,它都能看见相同的文件,即使生产机器运行的是完全不同的操作系统。应用程序不会关心它所在服务器上的任何东西,所以生产服务器上是否安装了和你开发机完全相同的一组库是不需要关心的。
例如,如果你用整个红帽企业版Linux(RHEL)的文件打包了你的应用程序,不管在装有Fedora的开发机上运行它,还是在装有Debian或者其他Linux发行版的服务器上运行它,应用程序都认为它运行在RHEL中。只是内核可能不同。
与在虚拟机中安装操作系统得到一个虚拟机镜像,再将应用程序打包到镜像里,通过分发整个虚拟机镜像到主机,使应用程序能够运行起来类似,Docker也能够达到相同的效果,但不是使用虚拟机来实现应用隔离,而是使用之前几节中提到的Linux容器技术来达到和虚拟机相同级别的隔离。容器也不使用庞大的单个虚拟机镜像,它使用较小的容器镜像。
基于Docker容器的镜像和虚拟机镜像的一个很大的不同是容器镜像是由多层构成,它能在多个镜像之间共享和征用。如果某个已经被下载的容器镜像已经包含了后面下载镜像的某些层,那么后面下载的镜像就无须再下载这些层。
Docker的概念
Docker是一个打包、分发和运行应用程序的平台。正如我们所说,它允许将你的应用程序和应用程序所依赖的整个环境打包在一起。这既可以是一些应用程序需要的库,也可以是一个被安装的操作系统所有可用的文件。Docker使得传输这个包到一个中央仓库成为可能,然后这个包就能被分发到任何运行Docker的机器上,在那儿被执行(大部分情况是这样的,但并不尽然,后面将做出解释)。
三个主要概念组成了这种情形:镜像 — Docker镜像里包含了你打包的应用程序及其所依赖的环境。它包含应用程序可用的文件系统和其他元数据,如镜像运行时的可执行文件路径。镜像仓库 — Docker镜像仓库用于存放Docker镜像,以及促进不同人和不同电脑之间共享这些镜像。当你编译你的镜像时,要么可以在编译它的电脑上运行,要么可以先上传镜像到一个镜像仓库,然后下载到另外一台电脑上并运行它。某些仓库是公开的,允许所有人从中拉取镜像,同时也有一些是私有的,仅部分人和机器可接入。容器 — Docker容器通常是一个Linux容器,它基于Docker镜像被创建。一个运行中的容器是一个运行在Docker主机上的进程,但它和主机,以及所有运行在主机上的其他进程都是隔离的。这个进程也是资源受限的,意味着它只能访问和使用分配给它的资源(CPU、内存等)
构建、分发和运行Dcoker镜像
图1.6显示了这三个概念以及它们之间的关系。开发人员首先构建一个镜像,然后把镜像推到镜像仓库中。因此,任何可以访问镜像仓库的人都可以使用该镜像。然后,他们可以将镜像拉取到任何运行着Docker的机器上并运行镜像。Docker会基于镜像创建一个独立的容器,并运行二进制可执行文件指定其作为镜像的一部分。
 图1.6 Docker镜像、镜像仓库和容器
图1.6 Docker镜像、镜像仓库和容器
对比虚拟机与Docker容器
由上文可知,Linux容器和虚拟机的确有相像之处,但容器更轻量级。现在让我们看一下Docker容器和虚拟机的具体比较(以及Docker镜像和虚拟机镜像的比较)。如图例1.7所示,相同的6个应用程序分别运行在虚拟机上和用Docker容器运行。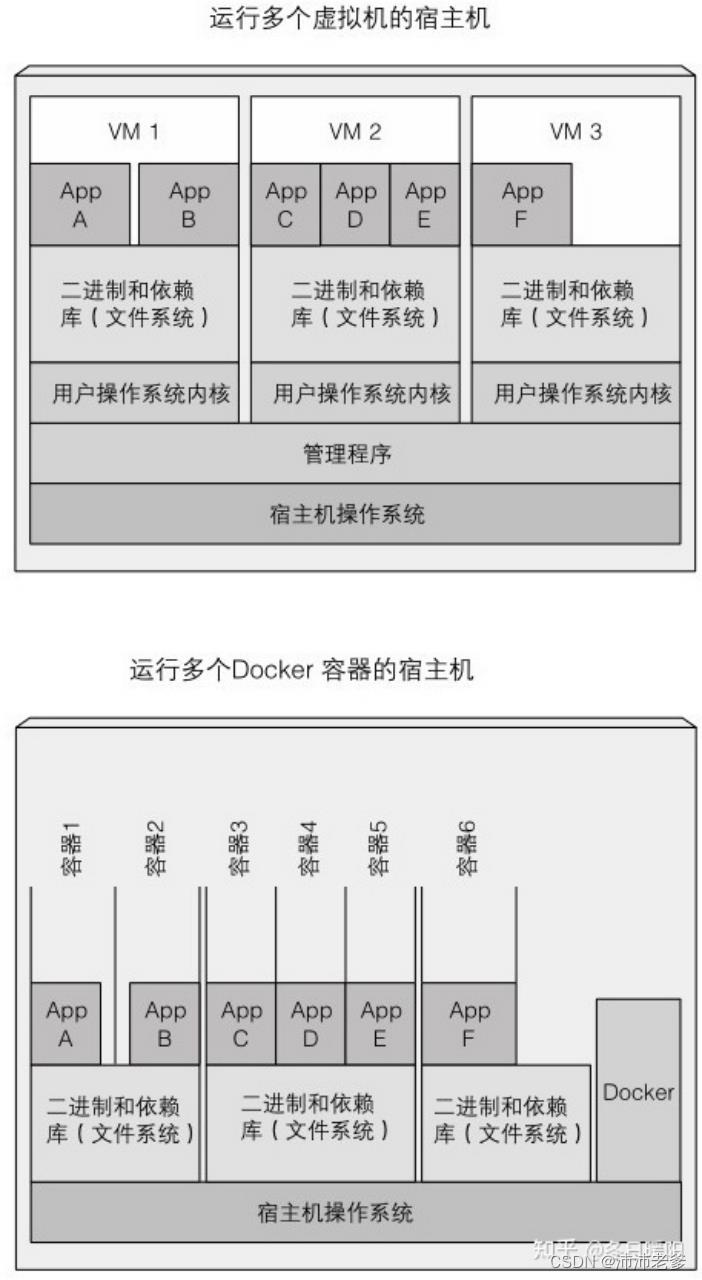
图1.7 在3个虚拟机上运行6个应用及用Docker容器运行它们 你会注意到应用A和应用B无论是运行在虚拟机上还是作为两个分离容器运行时都可以访问相同的二进制和库。在虚拟机里,这是显然的,因为两个应用都看到相同的文件系统。但是我们知道每个容器有它自己隔离的文件系统,那应用A和应用B如何共享同样的文件?
镜像层
前面已经说过Docker镜像由多层构成。不同镜像可能包含完全相同的层,因为这些Docker镜像都是基于另一个镜像之上构建的,不同的镜像都能使用相同的父镜像作为它们的基础镜像。这提升了镜像在网络上的分发效率,当传输某个镜像时,因为相同的层已被之前的镜像传输,那么这些层就不需要再被传输。
层不仅使分发更高效,也有助于减少镜像的存储空间。每一层仅被存一次,当基于相同基础层的镜像被创建成两个容器时,它们就能够读相同的文件。但是如果其中一个容器写入某些文件,另外一个是无法看见文件变更的。因此,即使它们共享文件,仍然彼此隔离。这是因为容器镜像层是只读的。容器运行时,一个新的可写层在镜像层之上被创建。容器中进程写入位于底层的一个文件时,此文件的一个拷贝在顶层被创建,进程写的是此拷贝。
容器镜像可移植性的限制
理论上,一个容器镜像能运行在任何一个运行Docker的机器上。但有一个小警告——一个关于运行在一台机器上的所有容器共享主机Linux内核的警告。如果一个容器化的应用需要一个特定的内核版本,那它可能不能在每台机器上都工作。如果一台机器上运行了一个不匹配的Linux内核版本,或者没有相同内核模块可用,那么此应用就不能在其上运行。
虽然容器相比虚拟机轻量许多,但也给运行于其中的应用带来了一些局限性。虚拟机没有这些局限性,因为每个虚拟机都运行自己的内核。
还不仅是内核的问题。一个在特定硬件架构之上编译的容器化应用,只能在有相同硬件架构的机器上运行。不能将一个x86架构编译的应用容器化后,又期望它能运行在ARM架构的机器上。你仍然需要一台虚拟机来做这件事情。
1.2.3 rkt——一个Docker的替代方案
Docker是第一个使容器成为主流的容器平台。Docker本身并不提供进程隔离,实际上容器隔离是在Linux内核之上使用诸如Linux命名空间和cgroups之类的内核特性完成的,Docker仅简化了这些特性的使用。
在Docker成功后,开放容器计划(OCI)就开始围绕容器格式和运行时创建了开放工业标准。Docker是计划的一部分,rkt(发音为“rock-it”)则是另外一个Linux容器引擎。
和Docker一样,rkt也是一个运行容器的平台,它强调安全性、可构建性并遵从开放标准。它使用OCI容器镜像,甚至可以运行常规的Docker容器镜像。
这本书只集中于使用Docker作为Kubernetes的容器,因为它是Kubernetes最初唯一支持的容器类型。最近Kubernetes也开始支持rkt及其他的容器类型。
在这里提到rkt的原因是,不应该错误地认为Kubernetes是一个专为Docker容器设计的容器编排系统。实际上,在阅读这本书的过程中,你将会认识到Kubernetes的核心远不止是编排容器。容器恰好是在不同集群节点上运行应用的最佳方式。有了这些认识,终于可以深入探讨本书所讲的核心内容——Kubernetes了。
1.3 Kubernetes介绍
我们已经展示了,随着系统可部署组件的数量增长,把它们都管理起来会变得越来越困难。需要一个更好的方式来部署和管理这些组件,并支持基础设施的全球性伸缩,谷歌可能是第一个意识到这一点的公司。谷歌等全球少数几个公司运行着成千上万的服务器,而且在如此海量规模下,不得不处理部署管理的问题。这推动着他们找出解决方案使成千上万组件的管理变得有效且成本低廉。
1.3.1 初衷
这些年来,谷歌开发出了一个叫Borg的内部系统(后来还有一个新系统叫Omega),应用开发者和系统管理员管理那些数以千计的应用程序和服务都受益于它的帮助。除了简化开发和管理,它也帮助他们获得了更高的基础设施利用率,在你的组织如此庞大时,这很重要。当你运行成千上万台机器时,哪怕一丁点的利用率提升也意味着节约了数百万美元,所以,开发这个系统的动机是显而易见的。
在保守Borg和Omega秘密数十年之后,2014年,谷歌开放了Kubernetes,一个基于Borg、Omega及其他谷歌内部系统实践的开源系统。
1.3.2 深入浅出地了解Kubernetes
Kubernetes是一个软件系统,它允许你在其上很容易地部署和管理容器化的应用。它依赖于Linux容器的特性来运行异构应用,而无须知道这些应用的内部详情,也不需要手动将这些应用部署到每台机器。因为这些应用运行在容器里,它们不会影响运行在同一台服务器上的其他应用,当你是为完全不同的组织机构运行应用时,这就很关键了。这对于云供应商来说是至关重要的,因为它们在追求高硬件可用率的同时也必须保障所承载应用的完全隔离。
Kubernetes使你在数以千计的电脑节点上运行软件时就像所有这些节点是单个大节点一样。它将底层基础设施抽象,这样做同时简化了应用的开发、部署,以及对开发和运维团队的管理。
通过Kubernetes部署应用程序时,你的集群包含多少节点都是一样的。集群规模不会造成什么差异性,额外的集群节点只是代表一些额外的可用来部署应用的资源
Kubernetes的核心功能
图1.8展示了一幅最简单的Kubernetes系统图。整个系统由一个主节点和若干个工作节点组成。开发者把一个应用列表提交到主节点,Kubernetes会将它们部署到集群的工作节点。组件被部署在哪个节点对于开发者和系统管理员来说都不用关心。
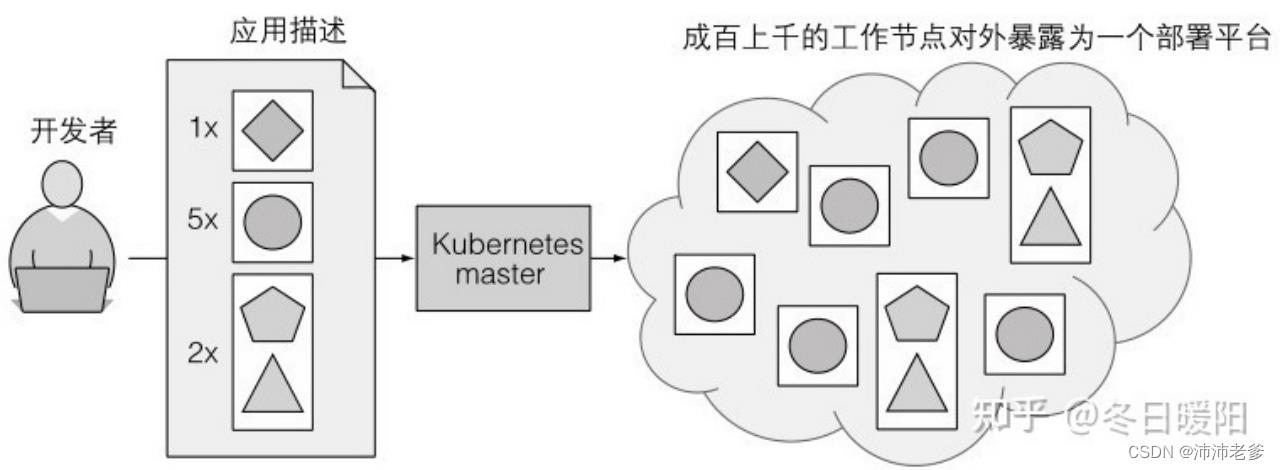 图1.8 Kubernetes暴露整个数据中心作为单个开发平台
图1.8 Kubernetes暴露整个数据中心作为单个开发平台
开发者能指定一些应用必须一起运行,Kubernetes将会在一个工作节点上部署它们。其他的将被分散部署到集群中,但是不管部署在哪儿,它们都能以相同的方式互相通信。
帮助开发者聚焦核心应用功能
Kubernetes可以被当作集群的一个操作系统来看待。它降低了开发者不得不在他们的应用里实现一些和基础设施相关服务的心智负担。他们现在依赖于Kubernetes来提供这些服务,包括服务发现、扩容、负载均衡、自恢复,甚至领导者的选举。应用程序开发者因此能集中精力实现应用本身的功能而不用浪费时间思索怎样集成应用与基础设施。
帮助运维团队获取更高的资源利用率
Kubernetes将你的容器化应用运行在集群的某个地方,并提供信息给应用组件来发现彼此并保证它们的运行。因为你的应用程序不关心它运行在哪个节点上,Kubernetes能在任何时间迁移应用并通过混合和匹配应用来获得比手动调度高很多的资源利用率。
1.3.3 Kubernetes集群架构
我们已经以上帝视角看到了Kubernetes的架构,现在让我们近距离看一下Kubernetes集群由什么组成。在硬件级别,一个Kubernetes集群由很多节点组成,这些节点被分成以下两种类型:
- 主节点,它承载着Kubernetes控制和管理整个集群系统的控制面板
- 工作节点,它们运行用户实际部署的应用
图1.9展示了运行在这两组节点上的组件,接下来进一步解释。
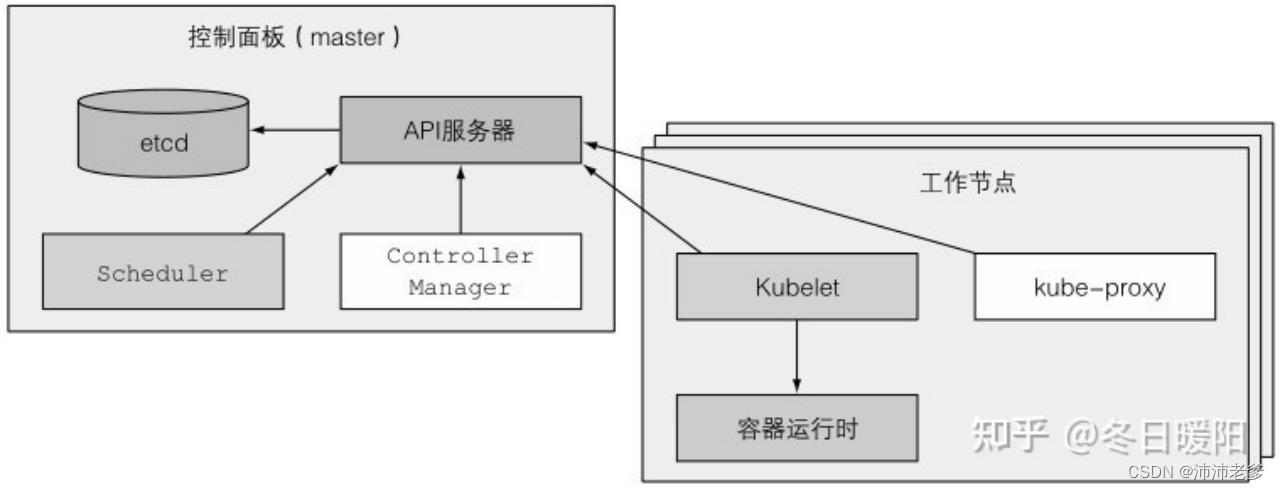 图1.9 组成一个Kubernetes集群的组件
图1.9 组成一个Kubernetes集群的组件
控制面板
控制面板用于控制集群并使它工作。它包含多个组件,组件可以运行在单个主节点上或者通过副本分别部署在多个主节点以确保高可用性。这些组件是:
- Kubernetes API服务器,你和其他控制面板组件都要和它通信
- Scheculer,它调度你的应用(为应用的每个可部署组件分配一个工作节点)
- Controller Manager,它执行集群级别的功能,如复制组件、持续跟踪工作节点、处理节点失败等
- etcd,一个可靠的分布式数据存储,它能持久化存储集群配置
控制面板的组件持有并控制集群状态,但是它们不运行你的应用程序。这是由工作节点完成的。
工作节点
工作节点是运行容器化应用的机器。运行、监控和管理应用服务的任务是由以下组件完成的:
- Docker、rtk或其他的容器类型
- Kubelet,它与API服务器通信,并管理它所在节点的容器Kubernetes Service
- Proxy(kube-proxy),它负责组件之间的负载均衡网络流量
我们将在第11章中详细解释所有这些组件。笔者不喜欢先解释事物是如何工作的,然后再解释它的功能并教人们如何使用它。就像学习开车,你不想知道引擎盖下是什么,你首先想要学习怎样从A点开到B点。只有在你学会了如何做到这一点后,你才会对汽车如何使这成为可能产生兴趣。毕竟,知道引擎盖下面是什么,可能在有一天它抛锚后你被困在路边时,会帮助你让车再次移动。
1.3.4 在Kubernetes中运行应用
为了在Kubernetes中运行应用,首先需要将应用打包进一个或多个容器镜像,再将那些镜像推送到镜像仓库,然后将应用的描述发布到Kubernetes API服务器。
该描述包括诸如容器镜像或者包含应用程序组件的容器镜像、这些组件如何相互关联,以及哪些组件需要同时运行在同一个节点上和哪些组件不需要同时运行等信息。此外,该描述还包括哪些组件为内部或外部客户提供服务且应该通过单个IP地址暴露,并使其他组件可以发现。
描述信息怎样成为一个运行的容器
当API服务器处理应用的描述时,调度器调度指定组的容器到可用的工作节点上,调度是基于每组所需的计算资源,以及调度时每个节点未分配的资源。然后,那些节点上的Kubelet指示容器运行时(例如Docker)拉取所需的镜像并运行容器。

图1.10 Kubernetes体系结构的基本概述和在它之上运行的应用程序
仔细看图1.10以更好地理解如何在Kubernetes中部署应用程序。应用描述符列出了四个容器,并将它们分为三组(这些集合被称为pod,我们将在第3章中解释它们是什么)。前两个pod只包含一个容器,而最后一个包含两个。这意味着两个容器都需要协作运行,不应该相互隔离。在每个pod旁边,还可以看到一个数字,表示需要并行运行的每个pod的副本数量。在向Kubernetes提交描述符之后,它将把每个pod的指定副本数量调度到可用的工作节点上。节点上的Kubelets将告知Docker从镜像仓库中拉取容器镜像并运行容器。
保持容器运行
一旦应用程序运行起来,Kubernetes就会不断地确认应用程序的部署状态始终与你提供的描述相匹配。例如,如果你指出你需要运行五个web服务器实例,那么Kubernetes总是保持正好运行五个实例。如果实例之一停止了正常工作,比如当进程崩溃或停止响应时,Kubernetes将自动重启它。
同理,如果整个工作节点死亡或无法访问,Kubernetes将为在故障节点上运行的所有容器选择新节点,并在新选择的节点上运行它们。
扩展副本数量
当应用程序运行时,可以决定要增加或减少副本量,而Kubernetes将分别增加附加的或停止多余的副本。甚至可以把决定最佳副本数目的工作交给Kubernetes。它可以根据实时指标(如CPU负载、内存消耗、每秒查询或应用程序公开的任何其他指标)自动调整副本数。
命中移动目标
我们已经说过,Kubernetes可能需要在集群中迁移你的容器。当它们运行的节点失败时,或者为了给其他容器腾出地方而从节点移除时,就会发生这种情况。如果容器向运行在集群中的其他容器或者外部客户端提供服务,那么当容器在集群内频繁调度时,它们该如何正确使用这个容器?当这些容器被复制并分布在整个集群中时,客户端如何连接到提供服务的容器呢?
为了让客户能够轻松地找到提供特定服务的容器,可以告诉Kubernetes哪些容器提供相同的服务,而Kubernetes将通过一个静态IP地址暴露所有容器,并将该地址暴露给集群中运行的所有应用程序。这是通过环境变量完成的,但是客户端也可以通过良好的DNS查找服务IP。kube-proxy将确保到服务的连接可跨提供服务的容器实现负载均衡。服务的IP地址保持不变,因此客户端始终可以连接到它的容器,即使它们在集群中移动。
1.3.5 使用Kubernetes的好处
如果在所有服务器上部署了Kubernetes,那么运维团队就不需要再部署应用程序。因为容器化的应用程序已经包含了运行所需的所有内容,系统管理员不需要安装任何东西来部署和运行应用程序。在任何部署Kubernetes的节点上,Kubernetes可以在不需要系统管理员任何帮助的情况下立即运行应用程序。
简化应用程序部署 由于Kubernetes将其所有工作节点公开为一个部署平台,因此应用程序开发人员可以自己开始部署应用程序,不需要了解组成集群的服务器。
实际上,现在所有节点都是一组等待应用程序使用它们的计算资源。开发人员通常不关心应用程序运行在哪个服务器上,只要服务器能够为应用程序提供足够的系统资源即可。
在某些情况下,开发人员确实关心应用程序应该运行在哪种硬件上。如果节点是异构的,那么你将会发现你希望某些应用程序在具有特定功能的节点上运行,并在其他的节点上运行其他应用程序。例如,你的一个应用程序可能需要在使用ssd而不是HDDs的系统上运行,而其他应用程序在HDDs上运行良好。在这种情况下,你显然希望确保特定的应用程序总是被调度到有SSD的节点上。
在不使用Kubernetes的情况下,系统管理员将选择一个具有SSD的特定节点,并在那里部署应用程序。但是当使用Kubernetes时,与其选择应用程序应该运行在某一特定节点上,不如告诉Kubernetes只在具有SSD的节点中进行选择。你将在第3章学到如何做到这一点。
更好地利用硬件
通过在服务器上装配Kubernetes,并使用它运行应用程序而不是手动运行它们,你已经将应用程序与基础设施分离开来。当你告诉Kubernetes运行你的应用程序时,你在让它根据应用程序的资源需求描述和每个节点上的可用资源选择最合适的节点来运行你的应用程序。
通过使用容器,不再用把这个应用绑定到一个特定的集群节点,而允许应用程序在任何时候都在集群中自由迁移,所以在集群上运行的不同应用程序组件可以被混合和匹配来紧密打包到集群节点。这将确保节点的硬件资源得到尽可能好的利用。
可以随时在集群中移动应用程序的能力,使得Kubernetes可以比人工更好地利用基础设施。人类不擅长寻找最优的组合,尤其是当所有选项的数量都很大的时候,比如当你有许多应用程序组件和许多服务器节点时,所有的组件可以部署在所有的节点上。显然,计算机可以比人类更好、更快地完成这项工作。
健康检查和自修复
在服务器发生故障时,拥有一个允许在任何时候跨集群迁移应用程序的系统也很有价值。随着集群大小的增加,你将更频繁地处理出现故障的计算机组件。
Kubernetes监控你的应用程序组件和它们运行的节点,并在节点出现故障时自动将它们重新调度到其他节点。这使运维团队不必手动迁移应用程序组件,并允许团队立即专注于修复节点本身,并将其修好送回到可用的硬件资源池中,而不是将重点放在重新定位应用程序上。
如果你的基础设施有足够的备用资源来允许正常的系统运行,即使故障节点没有恢复,运维团队甚至不需要立即对故障做出反应,比如在凌晨3点。他们可以睡得很香,在正常的工作时间再处理失败的节点。
自动扩容
使用Kubernetes来管理部署的应用程序,也意味着运维团队不需要不断地监控单个应用程序的负载,以对突发负载峰值做出反应。如前所述,可以告诉Kubernetes监视每个应用程序使用的资源,并不断调整每个应用程序的运行实例数量。
如果Kubernetes运行在云基础设施上,在这些基础设施中,添加额外的节点就像通过云供应商的API请求它们一样简单,那么Kubernetes甚至可以根据部署的应用程序的需要自动地将整个集群规模放大或缩小。
简化应用部署
前一节中描述的特性主要对运维团队有利。但是开发人员呢?Kubernetes是否也给他们带来什么好处?这毋庸置疑。
如果你回过头来看看,应用程序开发和生产流程中都运行在同一个环境中,这对发现bug有很大的影响。我们都同意越早发现一个bug,修复它就越容易,修复它需要的工作量也就越少。由于是在开发阶段就修复bug,所以这意味着他们的工作量减少了。
还有一个事实是,开发人员不需要实现他们通常会实现的特性。这包括在集群应用中发现服务和对端。这是由Kubernetes来完成的而不是应用。通常,应用程序只需要查找某些环境变量或执行DNS查询。如果这还不够,应用程序可以直接查询Kubernetes API服务器以获取该信息和其他信息。像这样查询Kubernetes API服务器,甚至可以使开发人员不必实现诸如复杂的集群leader选举机制。
作为最后一个关于Kubernetes带来什么的例子,还需要考虑到开发者们的信心增加。当他们知道,新版本的应用将会被推出时Kubernetes可以自动检测一个应用的新版本是否有问题,如果是则立即停止其滚动更新,这种信心的增强通常会加速应用程序的持续交付,这对整个组织都有好处。
1.4 本章小结
在这个介绍性章节中,你已经看到了近年来应用程序的变化,以及它们现在如何变得更难部署和管理。我们已经介绍了Kubernetes,并展示了它如何与Docker或其他容器平台一起帮助部署和管理应用程序及其运行的基础设施。你已经学到了:
- 单体应用程序更容易部署,但随着时间的推移更难维护,并且有时难以扩展。
- 基于微服务的应用程序体系结构使每个组件的开发更容易,但是很难配置和部署它们作为单个系统工作。
- Linux容器提供的好处与虚拟机差不多,但它们轻量许多,并且允许更好地利用硬件。
- 通过允许更简单快捷地将容器化应用和其操作系统环境一起管理,Docker改进了现有的Linux容器技术。
- Kubernetes将整个数据中心暴露为用于运行应用程序的单个计算资源。
- 开发人员可以通过Kubernetes部署应用程序,而无须系统管理员的帮助。
- 通过让Kubernetes自动地处理故障节点,系统管理员可以睡得更好。
在下一章中,你将通过构建一个应用程序并在Docker和Kubernetes中运行它,来上手实践。
以上是关于Kubernetes In Action :1Kubernetes介绍的主要内容,如果未能解决你的问题,请参考以下文章