惨案!老板要求单体架构转型分布式踩坑!
Posted 码农突围
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了惨案!老板要求单体架构转型分布式踩坑!相关的知识,希望对你有一定的参考价值。
点击关注公众号,Java干货及时送达👇

背景
我们在聊架构风格之前先明确一个问题,什么是架构?我们为什么要选择架构?用来解决哪些问题?
什么是架构
书本定义:“软件的架构是一种抽象的结构,他由软件的各个组成部分和这些部分之间的依赖关系构成”。
我的理解是,架构就是根据业务选择合适的技术、中间件,并且按照合适的设计模式对这些模块,进行组装来满足业务特性的需求。
选择架构风格的目的
我们选择架构风格的初衷在于 “三更原则”(自己的理解) :更好地降本提效、更快地发版上线、更好地维护系统稳定性。
任何一个架构风格,都可以实现功能性需求,但是一个好的架构风格能在功能性需求之上,提升非功能性需求。那么你可能会问,什么是非功能性需求?举例:扩展性、稳定性等等。
这里将会以我认知结合踩过的坑,来给大家详细讲一下,我们是如何从单体架构演进到分布式架构。在向分布式单体架构的演进的道路上,又是如何进行的抉择,以及为什么最后同时选择了 微服务架构+分布式架构 的原因。接下来就结合一个系统来作为案例,贯穿主线讲解。
首先来讲一下,最初的单体架构的经历和转型。
单体架构
我们在系统创建之初,往往都是集中业务、单点部署系统,所有业务打一个包,快速上线。满足了业务初期的快速发版上线,而且适合中小公司没有自己的 PaaS 平台,应对初期快速迭代的业务,开发、迭代、测试、发布都是非常的便捷。那么单体架构都有什么类型呢?
单体架构类型
单体架构也分为大泥团架构、分层单体架构、模块化单体架构,他们的区别是什么呢?
大泥团单体架构:毫无分层、所有模块聚焦在一起,相互穿插(除非是你接手需要改造,否则不要创建这样的架构风格。这种大泥团架构很难拆分,到最后的下场往往都是重新搭建);
分层单体架构:普遍的选择。架构进行了简单的分层,比如传统的 MVC 三层架构;
模块化单体架构:一般是随着业务的发展,由分层单体架构演变而来,特点就是引入了多个业务模块并且提供相应的服务能力。
单体架构的优缺点
优点
应用的开发很简单
易于对应用程序大规模的更改
测试相对简单、直观
部署简单明了
横向扩展不费吹灰之力
在业务的初期,单体架构的优点,无论从哪个方面来说,都优于其他架构风格,但是随着业务的增加、耦合,单体架构的缺点也逐渐暴露出来,这个也符合“康威定律”。那么单体架构的“后期”会暴露出哪些问题呢?
缺点
代码库膨胀
过度的复杂性会吓退开发者
开发速度慢
从代码提交到实际部署的周期很长,而且容易出问题
难以扩展
系统的稳定性得不到保障
需要长期依赖某个可能过时的技术栈
单体架构的这些缺点,其实影响的还是我上面提到的“三更原则”。经过上面的铺垫,相信大家已经对单体架构风格已经有了简单的理解。
光有方法论是不行的,我们得结合项目以及代码片段来加深理解,做到真正的应用。接下来我就用一个库存系统来进行串联进行讲解。先通过这张图来了解下库存系统是用来做什么的?
创建之初,1 个服务提供商品库存维护、库存查询、库存扣减能力。
随着业务的发展,库存面向多个服务:B 端业务,平台内部业务系统、平台外部中台。C 端业务,订单商品扣减库存、网关查询库存数量。
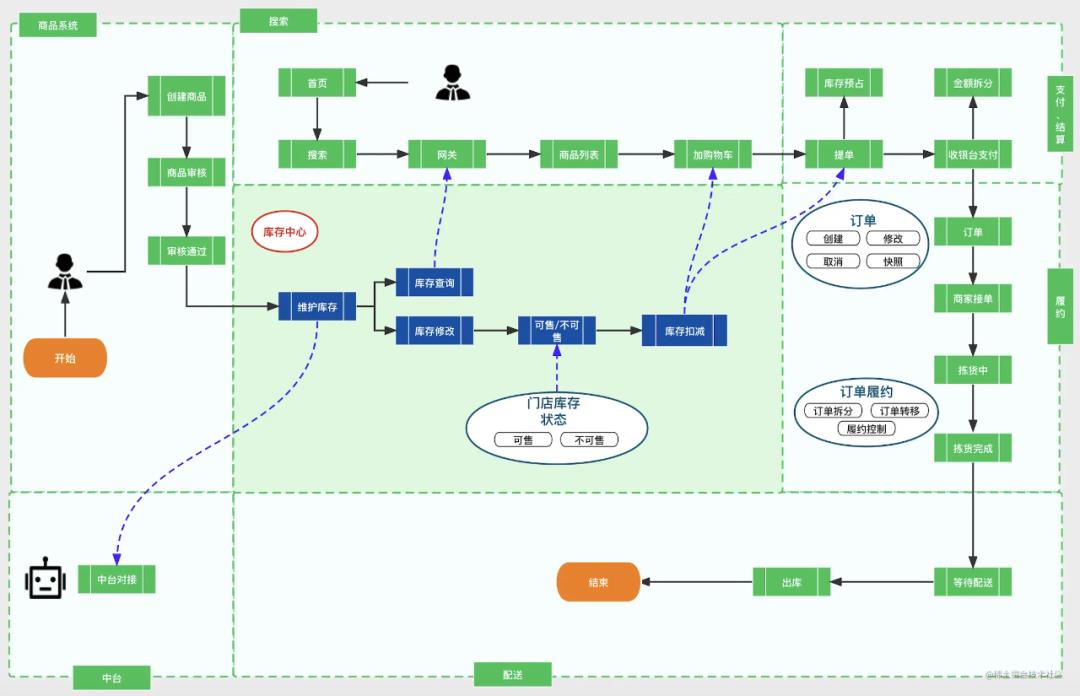
单体架构的案例——库存系统
最初的库存代码分层如下:
api:对外提供的 Dubbo 服务
common:封装了公共方法
dao:封装了数据库 DHCP 交互
domain:实体类
inner-api:系统内部 API 交互
router:废弃
rpc:上下游 RCP 交互
service:业务逻辑层
web:Web 服务层
worker:任务调度层

在最初很长的一段时间里,我们部署了两个单体服务。一个是 API 接口来保障上游的库存查询以及调用,另一个是 Web 服务的后台管理平台。这两个单体服务很好的贴合了最初的业务迭代和发版速度,但是后来随着业务的增加附加调用量的增加,单体服务的无论是从性能和稳定性都出现了较大的波动。
意料之外,情理之中的事故惨案
2015 年 6 月 26 日晚,也是一个促销活动的前夕,库存的 Web 管理平台挂了,原因就是大量库存导入,服务器的内存不足导致机器宕机。商家、运营无法通过导表的方式去维护库存数量,在这之前已经经历过了多次横向扩容。还是出现了预料之外的流量和稳定性的问题。
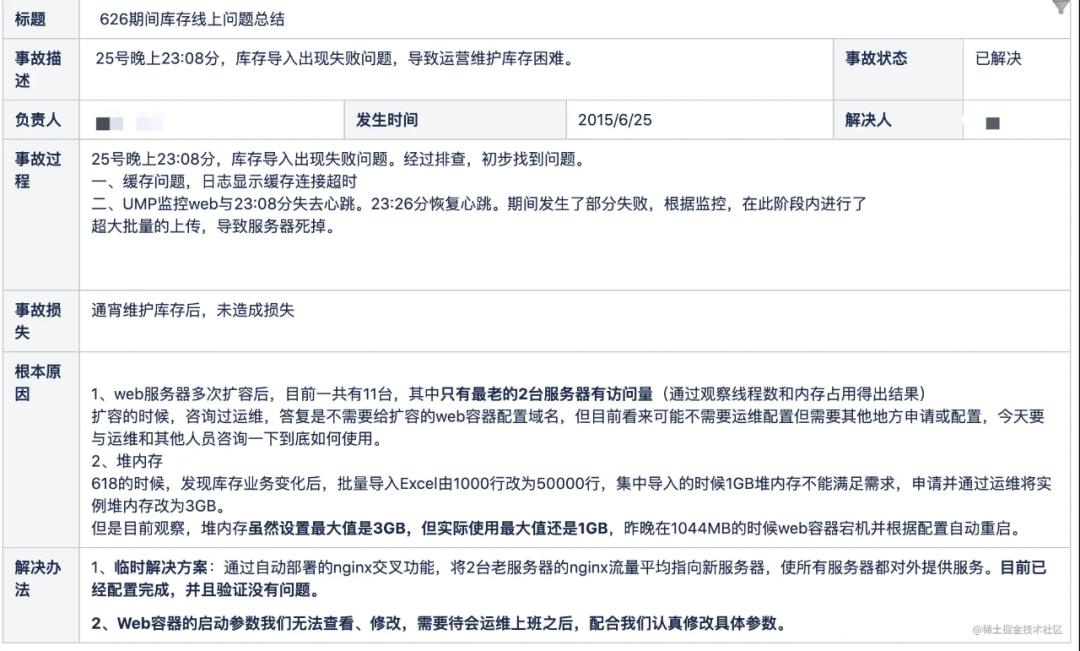
而且在接下来的大促过程当中,库存的单体服务 API 接口也承受了非常大的压力。
一方面是上游调用方有很多,比如 App 端首页中的门店网关,查询商品是否有库存,是否展示。购物车加车,也会查询商品库存的数量,提单则会对库存数量进行扣减,乃至后续的订单取消同样也会调用库存接口。
另一方面大的 KA 商家通过中台对接对库存进行操作,为了尽可能的让商家门店的库存和线上平台的库存保持一致,减少线上线下库存不一致导致的超卖、少卖。中台同步间隔时间都非常短,5 分钟~10 分钟就要全量同步一次。后续随着入驻的商家增多,这个量级增长得也非常的迅速。于是我们开启了单体服务向分布式服务演进的大门。
分布式架构
分布式架构的优缺点
优点
可用性高
可扩展性高
系统容错性高
业务代码可读性高
维护简单
这些优点正是我们当时库存系统欠缺的,尤其是其中的可用性、系统容错性,是我们系统演进迭代的首要目标。
《分布式架构体系》中描述到,分布式架构的核心理念也是按照(功能、业务、领域等)对系统进行拆分,通过合理的拆分结构,实现各业务模块的解耦,同时通过系统级容错设计,在廉价硬件基础设施上构建起高可用、可扩展的开放技术体系。
所以我们库存系统到底要按照什么进行拆分,功能?业务?领域?在拆分之前我们一定要明确设计的目标,避免目标方向错误带来的人力、成本资源的浪费。在弄清楚目标之前,我们先了解下分布式架构的缺点,通过了解这些缺点来衡量满足我们目标的前提下,需要进行哪些方面的取舍,就如 CAP 原则一样,只能满足其中的两个,AP 或者 CP。
2)分布式架构的缺点
服务多,人员对拆分后的业务模块理解要花费一些成本
技术栈升级耗费人力
分布式事务的保持
业务模块之间的 RPC 交互损耗
库存系统的特点,高可用、高并发、强数据一致性。接下来我们就来讲一下,库存是如何从单体架构向分布式架构进行的转型。
单体架构如何向分布式架构转型
因为库存面临的最大的问题是稳定性,所以我们首先针对功能进行了拆分。
1)功能拆分
这一步是相对简单的,我们梳理出库存面向服务的业务方进行服务划分。这部分无需进行太多代码的改造,一套接口通过变更不同的 group 别名,部署到不同的集群即可。
拆分后,不同的服务应对不同的业务方,系统错误的隔离性好,不会说出现一损俱损的局面,稳定性上也有了保障。在解决了稳定性的问题后,留给我们了一些喘气的间隔,可以有时间去进行代码的优化。因为刚才也提到了,我们只是通过分布式的集群部署来解决容错性的问题,但是代码还是一套,臃肿的代码也会拖慢我们的开发上线速度。那么接下来要进行的就是,对业务代码的解耦,这块也是难度最高的。我们是如何做的呢?
2)业务拆分
业务拆分的思路是什么呢?
以业务本身为导向,充分了解系统业务模型,划分业务边界;
业务依赖的范围,细分功能,尽量减少功能之间的重复依赖;
根据拆分功能的影响大小进行评估,拆小保大;
拆分的过程中不要修改业务逻辑,不要进行拆分之外的任何优化动作(除非是bug)。
基于上述拆分的思路,库存系统又是如何划分的业务模块呢?动了哪些代码?
3)如何划分业务模块
关于业务划分,网上有很多方法论,事件风暴法、四色建模法等等,但是万法不离其宗,那就是围绕事件。以库存系统举例:库存初始化(门店 + sku 库存创建)、库存数量维护(修改现货数量、修改可售状态)、扣减业务(购物车扣减、提单扣减、订单取消扣减)、提醒业务(缺货提醒)等。每一个事件都有独立的链路轴,以及时间线可以形成闭环。
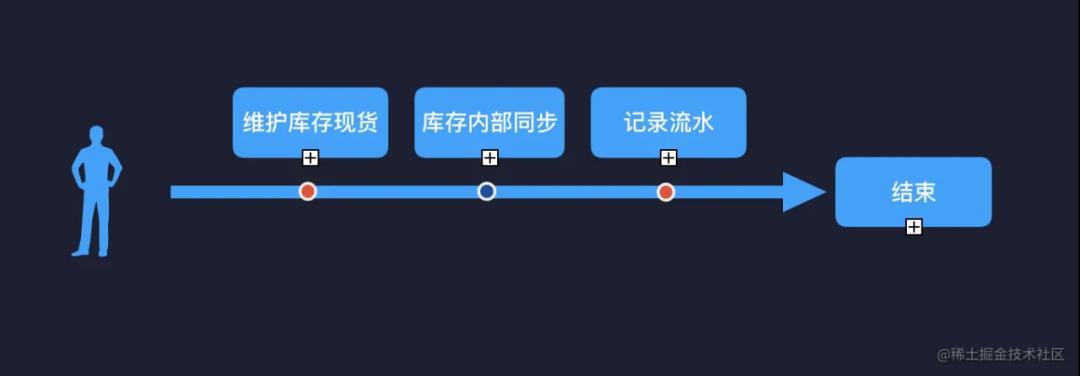
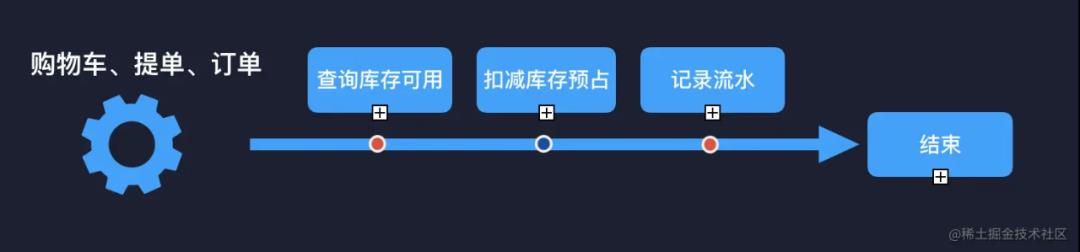
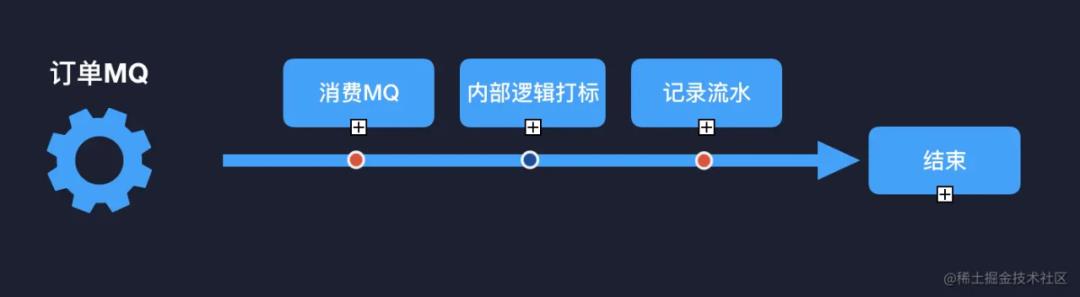
4)如何在原有模块上拆分
大多数单体架构都是面向过程的设计,domain 层充斥这个各种 DTO、VO、BO,所以在层与层的数据交互过程中,大都是经历了多次的 POJO。另外就是 Service 层充斥着和 DAO 层数据交互以及参杂了业务,而且严重违反了依赖倒置原则,整个层变得非常的沉重。这里举个例子:
同层级间相互引用
Service 层包含了太多业务逻辑,无法保障原子性
这里截取部分代码片段作为案例,来讲述下我们在拆分业务的过程中,需要做一些什么操作。
对 Service 层进行 CQS 的拆分
把业务逻辑从原有的 Service 层抽离,保障 Service 方法遵循 SRP 原则
新增业务聚合层(或者向六边形架构里提到的 adapter 转接口)来聚合 Service 层的方法
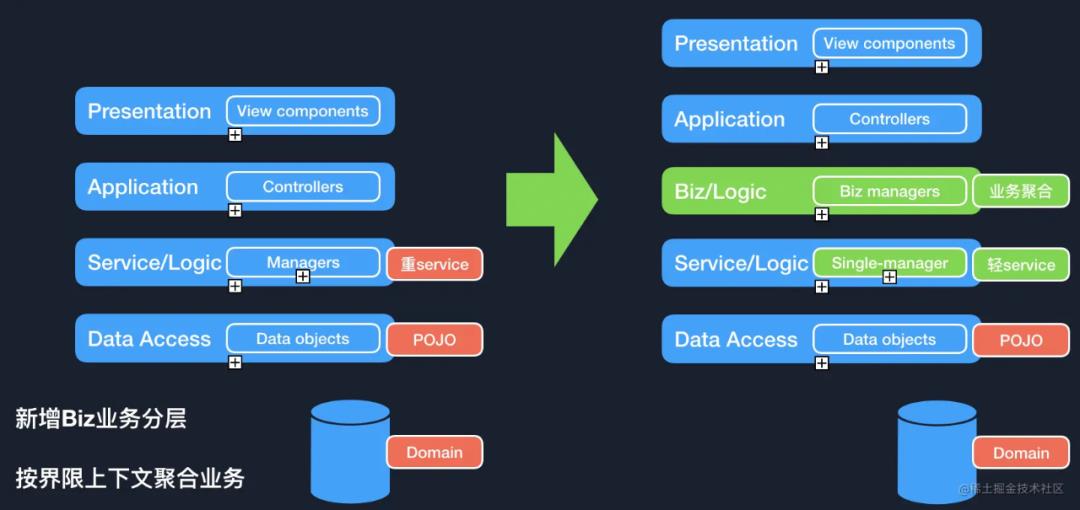
原始代码
@Service
public class SkuMainServiceImpl implements SkuMainService
private static final org.slf4j.Logger LOGGER = LoggerFactory.getLogger(SkuMainServiceImpl.class);
@Resource
private SkuMainDao skuMainDao;
@Resource
private ZkConfManagerCenterService zkConfManagerCenterService;
@Resource
private ProductImagesService productImagesService;//同级互相引用,未遵循依赖倒置
@Resource
private MqService mqServiceImpl;
@Value("$system.group.environment")
private String systemGroupEnvironment;
/**
* 问题:service层聚合了太多业务逻辑 倒置上层方法没办法统一
* @param skuMainInfoMQEntity
* @throws Exception
*/
public void editorSaveProuct(SkuMainInfoMQEntity skuMainInfoMQEntity) throws Exception
try
SkuMainBean skuMainBean = skuMainInfoMQEntity.getSkuMainBean();
if (skuMainBean == null)
throw new Exception("修改参数为空!");
SkuMainBean originalSku = this.getSkuMainBeanBySkuId(skuMainBean.getId());
if (originalSku == null)
throw new Exception("无效SkuId!");
SkuMainBean skuMainUpdate = updateIsWeightMark(skuMainBean);
SkuMainBean skuMainPre = this.get(skuMainUpdate.getId());
// 系统下架的商品 强制下架
if (skuMainPre != null && skuMainPre.getSystemFixedStatus() != null && skuMainPre.getSystemFixedStatus().equals(SystemFixedStatusEnum.SYSTEM_FIXED_STATUS_DOWN.getCode()))
skuMainUpdate.setFixedStatus(FixedStatusEnum.PRODUCT_DOWN.getCode());
boolean flag = skuMainDao.editorProduct(skuMainUpdate);
if (flag)
if (!zkConfManagerCenterService.isDefaultStoreStatisticsScore(skuMainBean.getOrgCode()))
SkuMainBean saveSkumainBean = this.get(skuMainUpdate.getId());
// 防止未查到,把缓存覆盖
if (saveSkumainBean != null)
cacheSkuMainBean(saveSkumainBean);
// 发送Sku修改MQ
sendSkuModifyMq(SkuModifyOpSourceEnum.MIX_UPDATE_SKU, originalSku, new SkuMainInfoMQEntity(skuMainUpdate));
ProductImagesBean productImagesBean = productImagesService.queryImagesBySkuId(skuMainUpdate.getId());
SkuMainInfoCheckMQEntity skuMainInfoCheckMQEntity = new SkuMainInfoCheckMQEntity();
skuMainInfoCheckMQEntity.setSkuMainBean(skuMainUpdate);
skuMainInfoCheckMQEntity.setProductImagesBean(productImagesBean);
mqServiceImpl.sendJosMQ(skuMainInfoCheckMQEntity, MqTypeEnum.RcsKeyWordsCheck);
mqServiceImpl.sendJosMQ(skuMainInfoCheckMQEntity, MqTypeEnum.SenseKeyWordsCheck);
else
LOGGER.info("add open platform sku , not not not send mq! skuId = ", skuMainBean.getId());
catch (Exception e)
LOGGER.error("修改商品信息失败.e:", e);
throw new Exception(e);
CQS 和 SRP 的改造,拆解 GOD Classes
Read 服务
Write 服务
抽离到业务层 Business 层后
@Service
public class SkuMainBusinessServiceImpl implements SkuMainBusinessService
private static final org.slf4j.Logger LOGGER = LoggerFactory.getLogger(SkuMainBusinessServiceImpl.class);
@Resource
private ZkConfManagerCenterService zkConfManagerCenterService;
@Resource
private MqService mqService;
@Resource
private SkuMainReadservice skuMainReadservice;
@Resource
private SkuMainWriteservice skuMainWriteservice;
@Value("$system.group.environment")
private String systemGroupEnvironment;
/**
* 问题:service层聚合了太多业务逻辑 倒置上层方法没办法统一
* @param skuMainInfoMQEntity
* @throws Exception
*/
public void editorSaveProuct(SkuMainInfoMQEntity skuMainInfoMQEntity) throws Exception
try
SkuMainBean skuMainBean = skuMainInfoMQEntity.getSkuMainBean();
if (skuMainBean == null)
throw new Exception("修改参数为空!");
SkuMainBean originalSku = skuMainReadservice.getSkuMainBeanBySkuId(skuMainBean.getId());
if (originalSku == null)
throw new Exception("无效SkuId!");
SkuMainBean skuMainUpdate = skuMainWriteservice.updateIsWeightMark(skuMainBean);
SkuMainBean skuMainPre = skuMainReadservice.queryDbById(skuMainUpdate.getId());
// 系统下架的商品 强制下架
if (skuMainPre != null && skuMainPre.getSystemFixedStatus() != null && skuMainPre.getSystemFixedStatus().equals(SystemFixedStatusEnum.SYSTEM_FIXED_STATUS_DOWN.getCode()))
skuMainUpdate.setFixedStatus(FixedStatusEnum.PRODUCT_DOWN.getCode());
boolean flag = skuMainWriteservice.editorProduct(skuMainUpdate);
if (flag)
if (!zkConfManagerCenterService.isDefaultStoreStatisticsScore(skuMainBean.getOrgCode()))
SkuMainBean saveSkumainBean = skuMainservice.queryDbById(skuMainUpdate.getId());
// 防止未查到,把缓存覆盖
if (saveSkumainBean != null)
skuMainWriteservice.cacheSkuMainBean(saveSkumainBean);
// 发送Sku修改MQ
skuMainWriteservice.sendSkuModifyMq(SkuModifyOpSourceEnum.MIX_UPDATE_SKU, originalSku, new SkuMainInfoMQEntity(skuMainUpdate));
else
LOGGER.info("add open platform sku , not not not send mq! skuId = ", skuMainBean.getId());
catch (Exception e)
LOGGER.error("修改商品信息失败.e:", e);
throw new Exception(e);
构建好的业务层
拆分小结
拆分到这里,业务层的划分基本就比较清晰了。而且在这个增量整合底层代码的过程中,面向过程的业务线也都梳理的比较清晰了,底层方法也都提取到了业务层收口,通过接口对外提供服务。那么接下来我们要面临的问题就是,如何对具体的读写进行拆分。
基于 CQRS 打造分布式服务
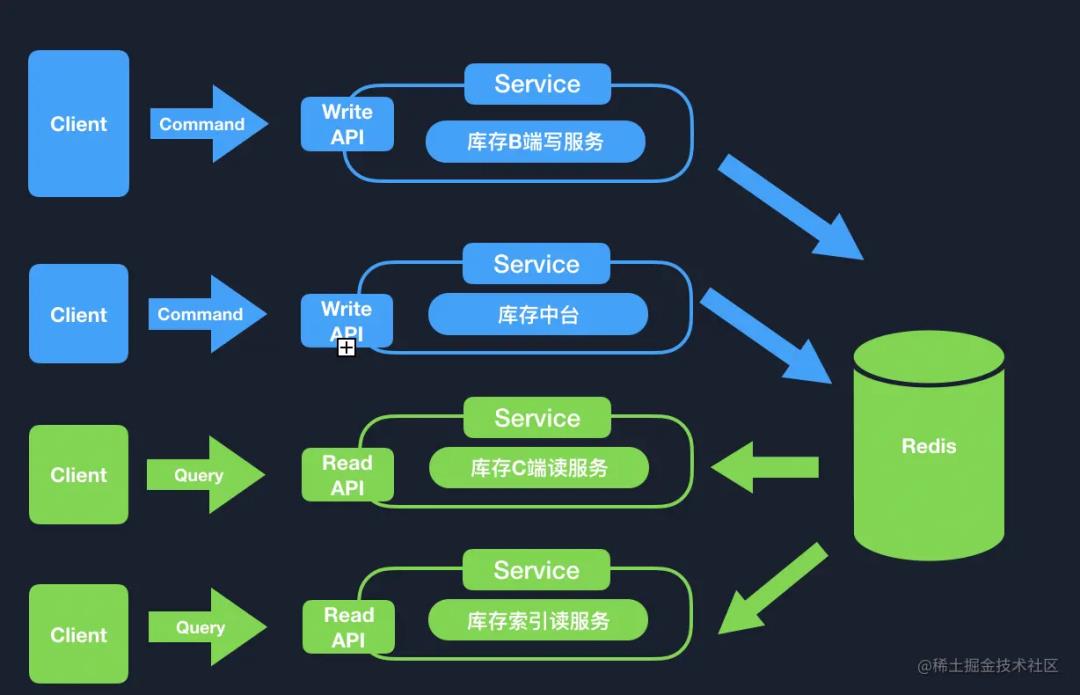
上面我们也提到了,进行了整体功能的拆分,并没有对具体的读写服务的拆分。在面向服务的场景下,功能里也是分读服务、写服务。那么我们有什么原则来指导读写服务的分离么?那就是 CQRS 的思想:命令职责查询分离,不单单指代码,同样也是适用于服务。
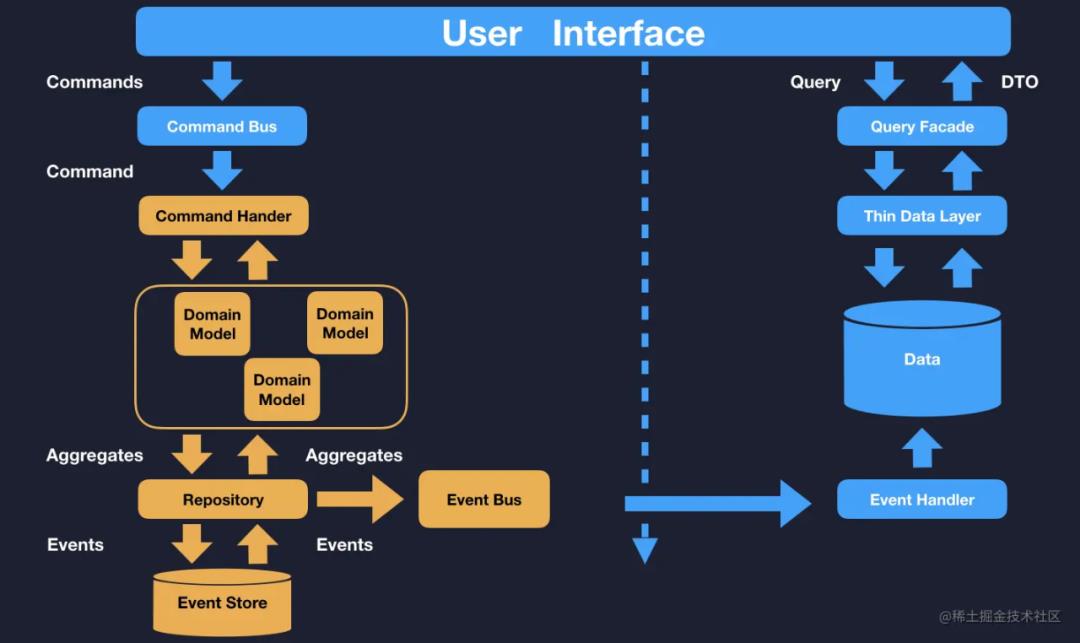
优先拆分读还是优先拆分写
建议从拆分读开始,因为读服务相对于写服务简单一些,而且更容易提高系统对外服务的稳定性,写服务的流程相对底层改动比较大,测试的周期也会比较长。在前期,动写服务系统出问题的概率会比较大,所以综合稳定性、扩展性来说,优先拆分读服务是一个比较好的选择。
CQRS 的思想适合所有业务场景吗?
以库存系统举例,我们就按照 CQRS 的思想复刻一版,看看会出现什么问题。
每一次修改同步库存写入任务表
schedule 任务读取任务表
把任务表的修改数据同步到 Read 服务中的 Redis 中
在这个过程中,存在两个问题:
大数据量任务同步的问题:也就是 Event Bus 同步 Redis 的数据同步速度问题。
延迟问题:库存要求实时性非常高,如果因为任务积压导致的延迟,会让库存陷入困境之中。大量的库存数量不对导致的超卖、超卖会瞬间击溃业务。
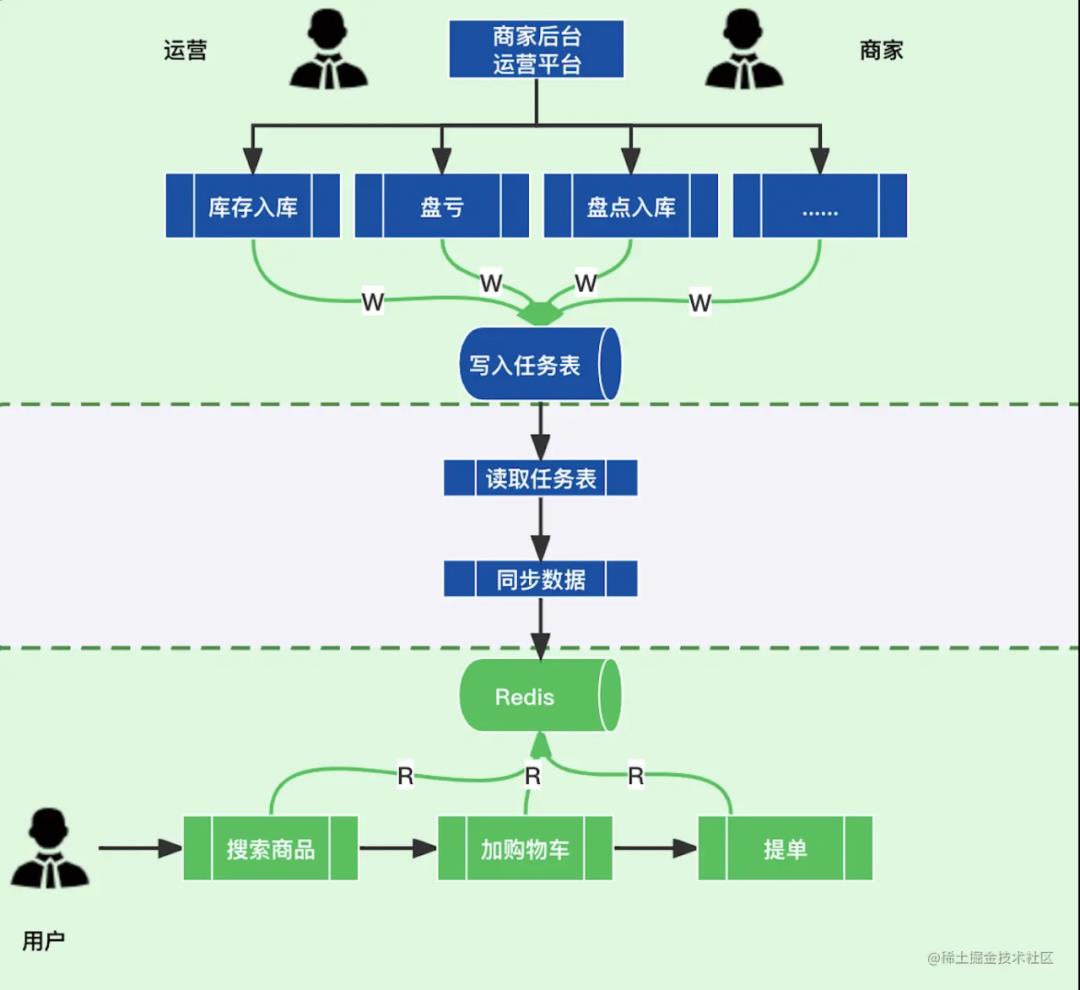
所以每一个架构、每一种思想都是要结合业务去分析。我们可以借鉴 CQRS 的命令查询职责分离,在面对业务系统部署的时候,不要死板的遵循固有的模式,要对现有的风格做出一定的取舍。所以,我们在应对库存业务的时候,基于 CQRS 的风格创建出了库存独有的 CQRS-StockCenter。
CQRS 的活学活用:CQRS-StockCenter
business 业务层写入命令
writeService 服务写入读服务 Redis
MQ 消息作为异步数据补全写入 mysql 备份、写入流水
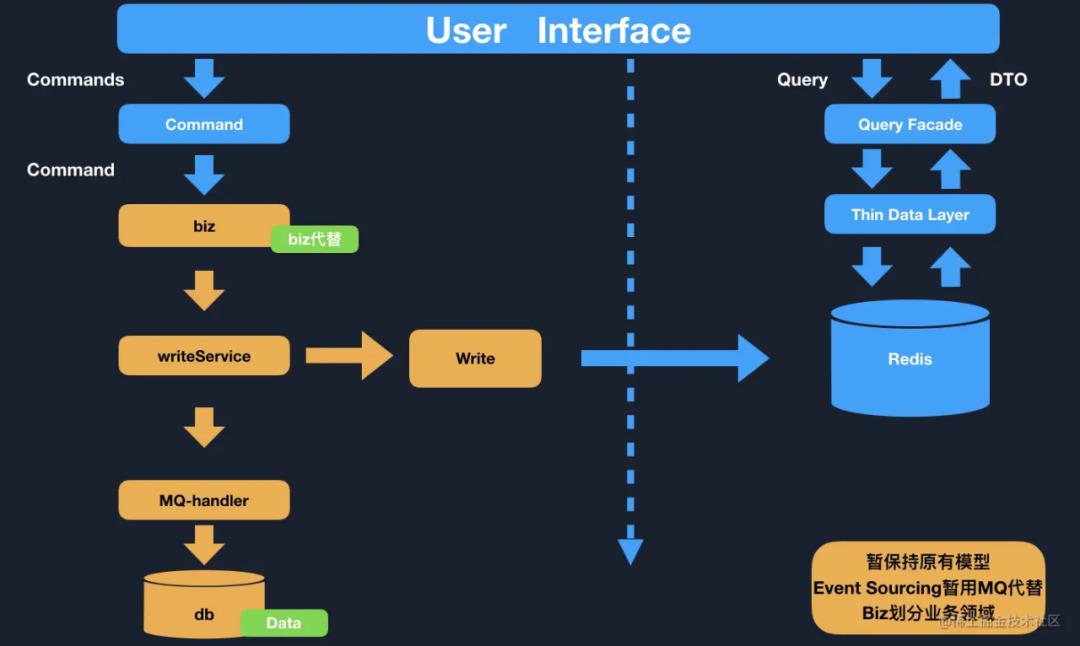
库存通过这套设计强依赖了 Redis 来作为库存查询、修改的中间件。保障了数据的强一致性。库存在原有的服务上,分离了读写,保障了系统的 CQRS 命令职责查询分离。
分布式事务
大家都知道事务。简单来说,事务由一组关联操作构成,A->B->C ,如果执行到C报错了,那么要回滚 B->A。
对于本地事务来说,这个相对很简单,如果你用了事务型数据库比如 MySQL,并且不涉及多个数据源的情况下,保障事务的 ACID 非常的容易。但是我们这里要提到的就是分布式事务。
系统拆分后,由于每个服务是一个独立的模块,负责一块业务,那么在整个业务轴的流程下,各个服务节点的跨系统事务回滚成为了一个难题。
业界也有一些方案,比如 JTA(Java Transaction API 即 Java 事务 API)和 JTS(Java Transaction Service 即 Java 事务服务),为 J2EE 平台提供了分布式事务服务。
但是,这种需要满足 XA(两阶段提交)的标准非常的重。而且现在的业务多样性,很多数据库比如 MongoDB,并不支持 XA 的标准分布式事务,一些流行的中间件,比如 RabbitMQ 和 Kafka 也不支持分布式事务。
转自:树洞君,
链接:juejin.cn/post/712188516006834998
(完)码农突围资料链接1、卧槽!字节跳动《算法中文手册》火了,完整版 PDF 开放下载!
2、计算机基础知识总结与操作系统 PDF 下载
3、艾玛,终于来了!《LeetCode Java版题解》.PDF
4、Github 10K+,《LeetCode刷题C/C++版答案》出炉.PDF
欢迎添加鱼哥个人微信:smartfish2020,进粉丝群或围观朋友圈以上是关于惨案!老板要求单体架构转型分布式踩坑!的主要内容,如果未能解决你的问题,请参考以下文章