Windows下Scrapy的环境搭建
Posted 唯鹿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Windows下Scrapy的环境搭建相关的知识,希望对你有一定的参考价值。
头一次在Windows系统上装Scrapy,折腾了一会时间,此篇记录一下。
1.环境
- 操作系统:Windows 7
- Python版本:Python 3.7
- PyCharm:PyCharm 2020.1
以上是我的环境配置,仅供参考。
2.安装Anaconda
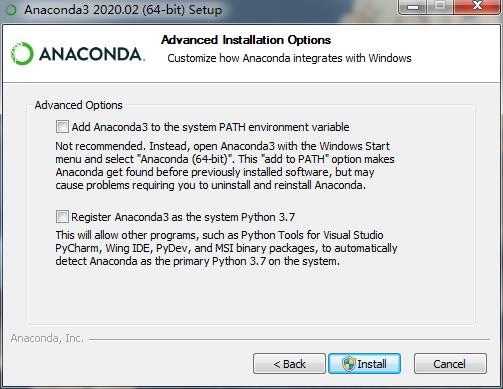
我下载的是 Anaconda3-2020.02-Windows-x86_64,安装时注意勾选添加环境变量(下图第一项)。
3.安装Scrapy
先安装Scrapy库,这里我使用PyCharm安装。
- 进入
Python Interpreter页:PyCharm-->File-->Setting-->Project-->Python Interpreter。 - 点击右上角的加号,搜索
Scrapy安装。

给Anaconda安装Scrapy,在cmd中输入:
conda install -c conda-forge scrapy
安装完成后,检查安装情况:
scrapy version
这里我遇见一个问题,报错:
Fatal error in launcher: Unable to create process using '"d:\\bld\\scrapy_15845559
97548\\_h_env\\python.exe" "E:\\Anaconda3\\Scripts\\scrapy.exe" version': ??????????
解决方法是命令前添加:python -m。
最终结果:

4.测试
用Scrapy文档的例子测试一下:
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quotes'
start_urls = [
'http://quotes.toscrape.com/tag/humor/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield
'author': quote.xpath('span/small/text()').get(),
'text': quote.css('span.text::text').get(),
next_page = response.css('li.next a::attr("href")').get()
if next_page is not None:
yield response.follow(next_page, self.parse)
将其命名为quotes_spider.py ,执行命令 scrapy runspider quotes_spider.py -o quotes.json,最终输出结果:

一切正常,可以继续开心的撸爬虫了。
PS:其实macOS也会遇到一些小问题,照着官方文档就好了。
5.参考
以上是关于Windows下Scrapy的环境搭建的主要内容,如果未能解决你的问题,请参考以下文章