Online DDL和Cardinality
Posted 热爱编程的大忽悠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Online DDL和Cardinality相关的知识,希望对你有一定的参考价值。
Online DDL和Cardinality
前言
本文来聊聊关于mysql索引管理方面的一些内容,首先我们先准备一张表:
CREATE DATABASE IF NOT EXISTS `test`;
USE `test`;
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
DROP TABLE IF EXISTS `order`;
CREATE TABLE `order` (
`id` bigint NOT NULL DEFAULT '' AUTO_INCREMENT COMMENT '主键',
`uid` bigint NOT NULL DEFAULT '' COMMENT '用户id',
`desc` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '' COMMENT '订单描述',
`price` int NOT NULL DEFAULT '' COMMENT '订单价格',
`creat_time` datetime NOT NULL DEFAULT '' COMMENT '订单创建时间',
PRIMARY KEY (id),
KEY (uid),
KEY (price)
) ENGINE = InnoDB AUTO_INCREMENT = 0 CHARACTER SET = 'utf8' COLLATE = 'utf8_general_ci' ROW_FORMAT = compact;
SET FOREIGN_KEY_CHECKS = 1;
我们通过存储过程插入一批数据:
DELIMITER $
CREATE PROCEDURE orderBatchInsert(IN num int)
BEGIN
DECLARE i INT(100) DEFAULT 0;
WHILE i<=num DO
INSERT INTO `order`(uid,`desc`,`price`) VALUES(i,"无",1);
SET i=i+1;
END WHILE;
END $
call orderBatchInsert(100);
我们通过下面这条sql语句来查看一些Order表中相关索引情况:
show index from order;

那么其中每一列又是什么意思呢?
- Table: 索引所在的表名
- Non_unique: 是否为非唯一索引
- Key_name: 索引名
- Seq_in_index: 索引中该列的位置
- Column_name: 索引列的名称
- Collation: 列以什么方式存储在索引中,可以是A或者NULL,B+树索引总是A,即排序的,如果使用了Heap存储引擎,并建立了Hash索引,这里就会显示NULL了,因为Hash根据Hash桶存放索引数据,而不是对数据进行排序。
- Cardinality: 索引列的区分度,表示索引中唯一值的数目的估计值。
- Sub_part: 是否是列的部分索引,例如: 我们可以对某个很长的字符串建立前缀索引,那么此时这里显示的就是前缀的长度。
- Packed: 关键字如何被压缩,没有被演示则为null。
- Null: 索引的列是否含有NULL值。
- Index_type: 索引类型,Innodb只支持B+树索引,所以这里显示的都是BTREE。
- comment: 注释
Fast Index Creation
Mysql 5.5版本之前,当我们对数据库索引进行添加或删除这类DDL操作,Mysql数据库的操作过程为:
- 首先创建一张新的临时表,表结构为通过命令ALTER TABLE新定义的结构。
- 然后把原表中数据导入到临时表。
- 接着删除原表。
- 最后把临时表重名为原来的表名。
可以发现,若用户对于一张大表进行索引的添加和删除操作,那么这会需要很长的时间。更关键的是,若有大量事务需要访问正在被修改的表,这意味着数据库服务不可用。而这对于Microsoft SQL Server或Oracle数据库的DBA来说,MySQL数据库的索 引维护始终让他们感觉非常痛苦。
InnoDB存储引擎从InnoDB 1.0.x版本开始支持一种称为 Fast Index Creation(快速索引创建)的索引创建方式—简称FIC。
对于辅助索引的创建,InnoDB存储引擎会对创建索引的表加上一个S锁。在创建的过程中,不需要重建表,因此速度较之前提高很多,并且数据库的可用性也得到了提高。删除辅助索引操作就更简单了,InnoDB存储引擎只需更新内部视图,并将辅助索引的空间标记为可用,同时删除MySQL数据库内部视图上对该表的索引定义即可。
这里需要特别注意的是,临时表的创建路径是通过参数tmpdir进行设置的。用户必须保证tmpdir有足够的空间可以存放临时表,否则会导致创建索引失败。
由于FIC在索引的创建的过程中对表加上了S锁,因此在创建的过程中只能对该表进行读操作,若有大量的事务需要对目标表进行写操作,那么数据库的服务同样不可用。此外,FIC方式只限定于辅助索引,对于主键的创建和删除同样需要重建一张表。
Online Schema Change
Online Schema Change(在线架构改变,简称OSC)最早是由Facebook实现的一种 在线执行DDL的方式,并广泛地应用于Facebook的MySQL数据库。所谓“在线”是指在事务的创建过程中,可以有读写事务对表进行操作,这提高了原有MySQL数据库在DDL操作时的并发性。
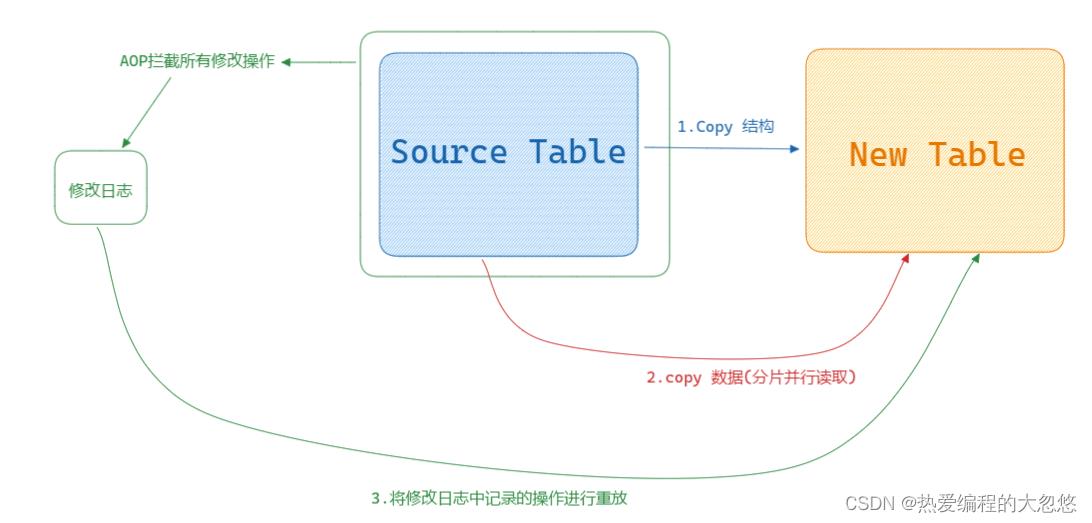
Facebook采用php脚本来现实OSC,而并不是通过修改InnoDB存储引擎源码的方式。OSC最初由 Facebook的员工 Vamsi Ponnekanti开发。此外,OSC借鉴了开源社区 之前的工具 The openarkkit toolkit oak-online-alter-table。实现OSC步骤如下:
- init,即初始化阶段,会对创建的表做一些验证工作,如检查表是否有主键,是否存在触发器或者外键等。
- createCopyTable,创建和原始表结构一样的新表。
- alterCopyTable:对创建的新表进行ALTER TABLE操作,如添加索引或列等。
- createDeltasTable,创建deltas表,该表的作用是为下一步创建的触发器所使用。之后对原表的所有DML操作会被记录到 createDeltasTable中。
- createTriggers,对原表创建 INSERT、UPDATE、DELETE操作的触发器。触发 操作产生的记录被写入到deltas表。
- startSnpshotXact,开始OSC操作的事务。
- selectTableIntoOutfile,将原表中的数据写入到新表。为了减少对原表的锁定时间,这里通过分片(chunked)将数据输出到多个外部文件,然后将外部文件的数据导入到copy表中。分片的大小可以指定,默认值是500000。
分片意味着可以并行读取,这样复制原表数据的时间会被大大缩短。
- dropNCIndexs,在导入到新表前,删除新表中所有的辅助索引。
- loadCopyTable,将导出的分片文件导入到新表。
- replayChanges,将OSC过程中原表DML操作的记录应用到新表中,这些记录被保存在 deltas表中。
- recreateNCIndexes,重新创建辅助索引。
- replayChanges,再次进行DML日志的回放操作,这些日志是在上述创建辅助索引中过程中新产生的日志。
- swapTables,将原表和新表交换名字,整个操作需要锁定2张表,不允许新的数据产生。由于改名是一个很快的操作,因此阻塞的时间非常短。
核心思路如下图所示:
Online DDL
虽然FIC可以让InnoDB存储引擎避免创建临时表,从而提高索引创建的效率。但正如前面小节所说的,索引创建时会阻塞表上的DML操作。OSC虽然解决了上述的部问题,但是还是有很大的局限性。MySQL 5.6版本开始支持Online DDL(在线数据定义)操作,其允许辅助索引创建的同时,还允许其他诸如INSERT、UPDATE, DELETE这类DML操作,这极大地提高了MySQL数据库在生产环境中的可用性。
此外,不仅是辅助索引,以下这几类DDL操作都可以通过“在线”的方式进行操作:
- 辅助索引的创建与删除
- 改变自增长值
- 添加或删除外键约束口列的重命名
通过新的ALTER TABLE语法,用户可以选择索引的创建方式:
ALTER TABLE tbl_name ADD INDEX|KEY [index_name] [index_type](index_col_name,...) [index_option]...
ALGORITHM [=]DEFAULTIINPLACE|COPY)
LOCK [=](DEFAULT|NONE|SHARED|EXCLUSIVE)
ALGORITHM指定了创建或删除索引的算法:
- COPY 表示按照MySQL 5.1版本之前的工作模式,即创建临时表的方式
- INPLACE表示索引创建或删除操作不需要创建临时表。
- DEFAULT表示根据参数
old_alter_table来判断是通过INPLACE还是COPY的算法, 该参数的默认值为OFF,表示采用INPLACE的方式,如:

LOCK部分为索引创建或删除时对表添加锁的情况,可有的选择为:
- NONE: 执行索引创建或者删除操作时,对目标表不添加任何的锁,即事务仍然可以进行读写操作,不会收到阻塞。因此这种模式可以获得最大的并发度。
- SHARE: 这和之前的FIC类似,执行索引创建或删除操作时,对目标表加上一个S锁。对于并发地读事务,依然可以执行,但是遇到写事务,就会发生等待操作。如果存储引擎不支持SHARE模式,会返回一个错误信息。
- EXCLUSIVE: 在EXCLUSIVE模式下,执行索引创建或删除操作时,对目标表加上一个X锁。读写事务都不能进行,因此会阻塞所有的线程,这和COPY方式运行得到的状态类似,但是不需要像COPY方式那样创建一张临时表。
- DEFAULT: DEFAULT模式首先会判断当前操作是否可以使用NONE模式,若不能,则判断是否可以使用SHARE模式,最后判断是否可以使用EXCLUSIVE模式。也就是说DEFAULT会通过判断事务的最大并发性来判断执行DDL的模式。
InnoDB存储引擎实现Online DDL的原理是在执行创建或者删除操作的同时,将INSERT、UPDATE、DELETE这类DML操作日志写入到一个缓存中。待完成索引创 建后再将重做应用到表上,以此达到数据的一致性。这个缓存的大小由参数innodb_online_alter_log_max_size控制,默认的大小为128MB。若用户更新的表比较大,并且 在创建过程中伴有大量的写事务,如遇到 innodb_online_alter_log_max_size的空间不能 存放日志时,会抛出类似如下的错误:
Error:1799 SQLSTATE:HY000(ER_INNODB_ONLINE_LOG_TOO_BIG)
Message: Creating index 'idx_aaa' required more than 'innodb_online_alter_log_ max_size' bytes of modification log. Please try again.
对于这个错误,用户可以调大参数innodb_online_alter_log_max_size,以此获得更 大的日志缓存空间。此外,还可以设置ALTER TABLE的模式为SHARE,这样在执行过程中不会有写事务发生,因此不需要进行DML日志的记录。
需要特别注意的是,由于Online DDL在创建索引完成后再通过重做日志达到数据库的最终一致性,这意味着在索引创建过程中,SQL优化器不会选择正在创建中的索引。
Cardinality
什么是Cardinality
我们先思考一个问题,对于什么列添加索引能够获得最大收益,对什么列添加索引是没有意义的。
索引用来精确,快速定位某个数据,但是如果某列数据的重复度很高,例如: 性别,那么对于性别列加索引其实意义不大,相反,如果某列数据的重复度很低,则此时使用B+树索引是最适合的。
怎样查看索引是否是高选择性的呢?
可以通过SHOW INDEX结果中的列Cardinality来观察。Cardinality 值非常关键,表示索引中不重复记录数量的预估值。同时需要注意的是,Cardinality是一个预估值,而不是一个准确值,基本上用户也不可能得到一个准确的值。在实际应用中,Cardinality/n_rows_in_table应尽可能地接近1。如果非常小,那么用 户需要考虑是否还有必要创建这个索引。故在访问高选择性属性的字段并从表中取出很少一部分数据时,对这个字段添加B+树索引是非常有必要的。

上面最开始给出的例子中,我们就不应该对price字段加索引,因为price列数据完全重复。
Cardinality是如何进行统计的
数据库是怎样来统计Cardinality信息的呢?因为MySQL数据库中有各种不同的存储引擎,而每种存储引擎对于B+树索引的实现又各不相同,所以对Cardinality的统计是放在存储引擎层进行的。
此外需要考虑到的是,在生产环境中,索引的更新操作可能是非常频繁的。如果每次索引在发生操作时就对其进行Cardinality的统计,那么将会给数据库带来很大的负担。另外需要考虑的是,如果一张表的数据非常大,如一张表有50G的数据,那么统计一次Cardinality信息所需要的时间可能非常长。这在生产环境下,也是不能接受的。因此,数据库对于Cardinality的统计都是通过采样(Sample)的方法来完成的。
在InnoDB存储引擎中, Cardinality统计信息的更新发生在两个操作中: INSERT和UPDATE。根据前面的叙述,不可能在每次发生INSERT和UPDATE时就去更新Cardinality信息,这样会增加数据库系统的负荷,同时对于大表的统计,时间上也不允许数据库这样去操作。因此,InnoDB存储引擎内部对更新Cardinality信息的策略为:
- 表中1/16的数据已发生过变化。
-
stat_modified_counter>2 000 000 000
第一种策略为自从上次统计Cardinality 信息后,表中1/16的数据已经发生过变化,这时需要更新Cardinality信息。
第二种情况考虑的是,如果对表中某一行数据频繁地进行更新操作,这时表中的数据实际并没有增加,实际发生变化的还是这一行数据,则第一种更新策略就无法适用这这种情况。故在InnoDB存储引擎内部有一个计数器statmodified_counter,用来表示发生变化的次数,当stat_modified_counter大于2 000 000 000时,则同样需要更新Cardinality 信息。
接着考虑InnoDB存储引擎内部是怎样来进行Cardinality 信息的统计和更新操作的呢?同样是通过采样的方法。默认InnoDB存储引擎对8个叶子节点(Leaf Page)进行采用。采样的过程如下:
- 取得B+树索引中叶子节点的数量,记为A。
- 随机取得B+树索引中的8个叶子节点。统计每个页不同记录的个数,即为P1,P2,···,P8。
- 根据采样信息给出 Cardinality的预估值:Cardinality=(P1+P2+···+P8)*A/8
通过上述的说明可以发现,在InnoDB存储引擎中,Cardinality值是通过对8个叶子节点预估而得的,不是一个实际精确的值。再者,每次对Cardinality值的统计,都是通过随机取8个叶子节点得到的,这同时又暗示了另一个Cardinality现象,即每次得到的Cardinality 值可能是不同的。
在InnoDB 1.2版本之前,可以通过参数 innodb_stats_sample_pages用来设置统计 Cardinality时每次采样页的数量,默认值为8。同时,参数innodb_stats_method用来判断如何对待索引中出现的NULL值记录。该参数默认值为nulls_equal,表示将NULL值记录视为相等的记录。其有效值还有nulls_unequal,nulls_ignored,分别表示将NULL 值记录视为不同的记录和忽略NULL值记录。
例如某页中索引记录为NULL、NULL、1、2、2、3、3、3,在参数innodb_stats_method的默认设置下,该页的Cardinality为4;若 参数 innodb_stats_method 为nulls_unequal,则该页的Caridinality为5;若参数 innodb stats_method为 nulls_ignored,则Cardinality为3。
当执行SQL语句ANALYZE TABLE、SHOW TABLE STATUS、SHOW INDEX 以及访问INFORMATION_SCHEMA架构下的表TABLES和STATISTICS时会导致 InnoDB存储引擎去重新计算索引的Cardinality值。若表中的数据量非常大,并且表中存在多个辅助索引时,执行上述这些操作可能会非常慢。虽然用户可能并不希望去更新Cardinality 值。
InnoDB1.2版本提供了更多的参数对 Cardinality统计进行设置,这些参数如下所示:

以上是关于Online DDL和Cardinality的主要内容,如果未能解决你的问题,请参考以下文章
online ddl 工具之pt-online-schema-change封装