capsule系列之Dynamic Routing Between Capsules
Posted AI蜗牛之家
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了capsule系列之Dynamic Routing Between Capsules相关的知识,希望对你有一定的参考价值。
文章目录
capsule在出现之后就除了Hinton老爷子的两个版本之外,还有例如Investigating Capsule Networks with Dynamic Routing for Text Classification这样的新作,可见capsule的很多理念都是work的,因为打算好好拜读几篇paper,做一个系列,深刻理解capsule。
本篇文章我觉得确实还是有难度的,作为一篇笔记博客,为了能够比较透彻的理解,在原文基础上参考了很多的文章,并添加了相关自己的理解,参考文献会在最后章节详细列出。
论文下载地址:zsweet github
1.背景
一个新的事物出现,必然以藏着以往事物的缺陷,那么capsule因何而生呢?
在讲胶囊网络之前,首先我们回顾一下我们熟悉的CNN:
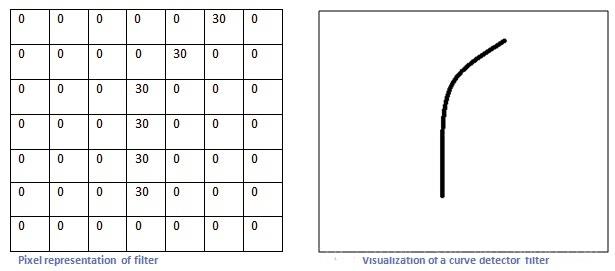
CNN做了什么事情呢? 假设这里有一个卷积核(左图),除了曲线轨迹上的值很大,其他的值都是零,所以这个卷积核对旁边这种曲线(右图)就有很高的输出,也就是说对这种曲线有很高的识别,而对其他的曲线类型输出就低。
所以比如图像分类中,一旦卷积核检测到了类似于眼睛啊、鼻子啊、嘴巴啊这种特征;从数学角度上说就,相关卷积核对鼻子、眼睛等卷积出来的值很大,那么与人脸相关的神经元就相当兴奋,最后将图像分类到人脸这一类。
所以这就导致了一个问题。如图,右边那张眼睛、鼻子、嘴巴都有了,当然我们的CNN也相当兴奋的将它归于人脸。
这就就暴露了CNN的问题:
- 组件的朝向和空间上的相对关系对它来说不重要,它只在乎有没有特征。
- CNN还有一个问题,那就是池化层。Hinton自己就说过:最大池化层表现的如此优异是一个巨大的错误,是一场灾难。诚然,从网络设计上来说,池化层不仅减少了参数,还可以避免过拟合。但是,它的确抛弃了一些信息,比如位置信息。
再比如说,下面这张图,尽管拍摄的角度不同,但你的大脑可以轻易的辨识这些都是同一对象,CNN却没有这样的能力。它不能举一反三,它只能通过扩大训练的数据量才能得到相似的能力。

2.什么是capsule
现在网上有关于capsule多数翻译成胶囊,但是我觉太缺乏学术性,知乎上的
云梦居客(文章里有详细的ppt和录播视频)大佬把它称作“矢量神经元”或者“张量神经元”,我觉得比较合适,但是很多人可能又没听说过这种说法,所以还是直接称之为capsule吧!(懒癌犯了…)
论文中说道,capsule是一个实体,那实体又是什么?一般是指能够独立存在的、作为一切属性的基础和万物本原的东西(百度百科)。capsule就是一个完整概念单元的封装,能够表征不同属性。
这次Capsule盛宴的特色是“vector in vector out”,取代了以往的“scaler in scaler out”,也就是神经元的输入输出都变成了向量,从而算是对神经网络理论的一次革命。然而真的是这样子吗?难道我们以往就没有做过“vector in vector out”的任务了吗?有,而且多的是!NLP中,一个词向量序列的输入,不就可以看成“vector in”了吗?这个词向量序列经过RNN/CNN/Attention的编码,输出一个新序列,不就是“vector out”了吗?在目前的深度学习中,从来不缺乏“vector in vector out”的案例,因此显然这不能算是Capsule的革命。
Capsule的革命在于:它提出了一种新的“vector in vector out”的传递和权重更新方案,并且这种方案在很大程度上是可解释的。
那最后,什么是capsule?
其实,只要把一个向量当作一个整体来看,它就是一个capsule。 你可以这样理解:神经元就是标量,胶囊就是向量,就这么粗暴!Hinton的理解是:每一个胶囊表示一个属性,而胶囊的向量则表示这个属性的“标架”。也就是说,我们以前只是用一个标量表示有没有这个特征(比如有没有羽毛),现在我们用一个向量来表示,不仅仅表示有没有,还表示“有什么样的”(比如有什么颜色、什么纹理的羽毛),如果这样理解,就是说在对单个特征的表达上更丰富了。
说到这里,我感觉有点像NLP中的词向量,以前我们只是用one hot来表示一个词,也就是表示有没有这个词而已。现在我们用词向量来表示一个词,显然词向量表达的特征更丰富,不仅可以表示有没有,还可以表示哪些词有相近含义。词向量就是NLP中的“胶囊”?这个类比可能有点牵强,但我觉得意思已经对了。
3.capsule原理和结构
在论文中,Geoffrey Hinton 介绍 Capsule 为:「Capsule 是一组神经元,其输入输出向量表示特定实体类型的实例化参数(即特定物体、概念实体等出现的概率与某些属性)。我们使用输入输出向量的长度表征实体存在的概率,向量的方向表示实例化参数(即实体的某些图形属性)。同一层级的 capsule 通过变换矩阵对更高级别的 capsule 的实例化参数进行预测。当多个预测一致时(本论文使用动态路由使预测一致),更高级别的 capsule 将变得活跃。」
Capsule 中的神经元的激活情况表示了图像中存在的特定实体的各种性质。这些性质可以包含很多种不同的参数,例如姿势(位置,大小,方向)、变形、速度、反射率,色彩、纹理等等。而输入输出向量的长度表示了某个实体出现的概率,所以它的值必须在 0 到 1 之间。
3.1.capsule结构
下面我们来看看capsule的结构。
Capsule针对着“层层递进”的目标来设计的,我们先来看一张整体的capsule结构图,更好理解:

上图展示了Capsule整体结构:Capsule层级结构与动态 Routing 的过程。
其中最下面的层级
u
i
u_i
ui共有两个 Capsule 单元,该层级传递到下一层级
v
j
v_j
vj 共有四个 Capsule。
capsule的运行流程大致如下:
- u 1 u_1 u1 和 u 2 u_2 u2 是一个向量,即含有一组神经元的 Capsule 单元,它们分别与不同的权重 W i j W_ij Wij(同样是向量,更准确来说是矩阵)相乘得出 u ^ j ∣ i \\widehat u_j|i u j∣i。例如 u 1 u_1 u1 与 W 12 W_12 W12 相乘得出预测向量 u ^ 2 ∣ 1 \\widehatu_2|1 u 2∣1。通过改变W_ij的维度也可以起到降维的作用?
- 预测向量和对应的「耦合系数」 c i j c_ij cij 相乘并传入特定的后一层 Capsule 单元得到 s j s_j sj。不同 Capsule 单元的输入 s j s_j sj 是所有可能传入该单元的加权和,即所有可能传入的预测向量与耦合系数的乘积和。
- 将向量 s j s_j sj投入到「squashing」非线性函数就能得出后一层 Capsule 单元的输出向量 v j v_j vj。
- 利用该输出向量 v j v_j vj 和对应预测向量 u ^ j ∣ i \\widehatu_j|i u j∣i 的乘积更新耦合系数 c i j c_ij cij,这样的迭代更新不需要应用反向传播。
其实capsule就是一个向量版的全连接层,与传统的全连接对比如下:
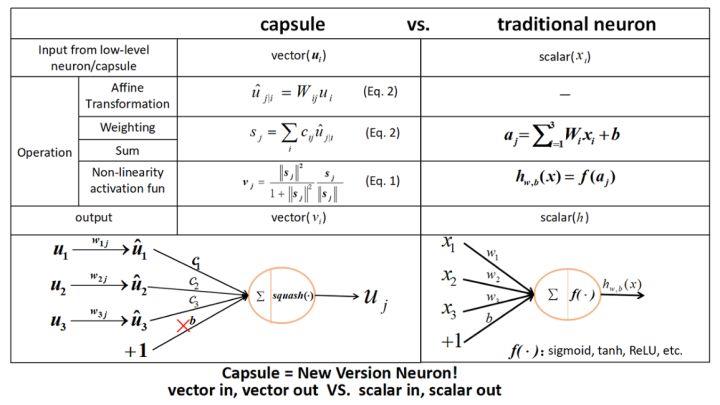
关于capsule的构建过程,我觉得苏建林的这篇文章说的挺好的,不愧是数学出身的大佬,大家可以拜读一下。
3.2.Dynamic Routing 算法
按照 Hinton 的思想,找到最好的处理路径就等价于正确处理了图像,所以在 Capsule 中加入 Routing 机制可以找到一组系数 c i j c_ij cij,它们能令预测向量 u ^ j ∣ i \\widehatu_j|i u j∣i 最符合输出向量 v j v_j vj,即最符合输出的输入向量,这样我们就找到了最好的路径。
从上面的capsule结果和运行过程可以看出,为了求 v j v_j vj需要先求 c i j c_ij cij,可是为了求 c i j c_ij cij又需要知道 v j v_j vj,这不是个鸡生蛋、蛋生鸡的问题了吗?
之前了解过EM算法的小伙伴应该有印象,可以说是特别像了,所以分类聚类虽有本质的区别,可是还是相通的啊,关于EM算法可以参考我之前的文章从最大似然到EM算法浅解
那怎么办呢?
这就需要像EM一样通过迭代的方式了,在这里起个名字叫“动态路由”(Dynamic Routing),它能够根据自身的特性来更新(部分)参数,从而初步达到了Hinton的放弃梯度下降的目标。具体的过程就是:为了得到各个vj,一开始先让它们全都等于ui的均值,然后反复迭代就好。说白了,输出是输入的聚类结果,而聚类通常都需要迭代算法,这个迭代算法就称为“动态路由”。
至于这个动态路由的细节,其实是不固定的,取决于聚类的算法,比如关于Capsule的新文章《MATRIX CAPSULES WITH EM ROUTING》就使用了Gaussian Mixture Model来聚类。
本文给出的动态路由过程如下:

这里解释下,怎么又冒出一个
b
i
j
b_ij
bij来?其实
c
i
j
c_ij
cij就是通过对
b
i
j
b_ij
bij进行softmax得来的,你可以把它看成一个东西,只不过
b
i
j
b_ij
bij是规格化了的。
Dynamic Routing的过程可以总结为:
对于所有在
l
l
l 层的 Capsule i 和在
l
+
1
l+1
l+1 层的 Capsule j,先初始化
b
i
j
b_ij
bij 等于零。然后迭代 r 次,每次先根据
b
i
b_i
bi 计算
c
i
c_i
ci,然后在利用
c
i
j
c_ij
cij 与
u
^
j
∣
i
\\widehat u_j|i
u
j∣i 计算
s
j
s_j
sj 与
v
j
v_j
vj。利用计算出来的
v
j
v_j
vj 更新
b
i
j
b_ij
bij 以进入下一个迭代循环更新
c
i
j
c_ij
cij。该 Routing 算法十分容易收敛,基本上通过 3 次迭代就能有不错的效果。
3.3.小部件
上面从上而下讲完了capule结构和routing过程,但是有些小的结构(我成为小部件)没有详述,这里整理一下。
3.3.1.为耦合系数(coupling coefficients)
c
i
j
c_ij
cij系数由动态 Routing 过程迭代地更新与确定。Capsule i 和后一层级所有 Capsule j间的耦合系数和为 1,即如图3-1-1中,
c
11
+
c
12
+
c
13
+
c
14
=
1
c_11+c_12+c_13+c_14=1
c11+c12+c13+c14=1。此外,该耦合系数由「routing softmax」决定,且 softmax 函数中的
l
o
g
i
t
s
b
i
j
logits\\ b_ij
以上是关于capsule系列之Dynamic Routing Between Capsules的主要内容,如果未能解决你的问题,请参考以下文章