大数据项目开发进度(实时更新)
Posted 爱做梦的鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据项目开发进度(实时更新)相关的知识,希望对你有一定的参考价值。
文章目录
前言
如果你从本文中学习到丝毫知识,那么请您点点关注、点赞、评论和收藏
大家好,我是爱做梦的鱼,我是东北大学大数据实验班大三的小菜鸡,非常渴望优秀,羡慕优秀的人。从5月25号我们开始了为期两个月的实习,我们需要做一个大型大数据项目,一个项目由三个学生+一个企业的项目经理完成。请大家持续关注我的专栏,我会每天更新。
github地址:https://github.com/233zzh/TitanDataOperationSystem
专栏:大数据案例实战——大三春招大数据开发
专栏:Spark官方文档解读【Spark2.4.5中英双语】
博客地址:子浩的博客https://blog.csdn.net/weixin_43124279
项目概述
我们采用迭代式开发的软件开发过程
项目进度
第一周0525-0529:
- 确定项目题目和项目数据来源
题目:数据分析运营系统
数据来源:易头条的部分埋点日志文件+(如果我们后续需要海量数据,我们就写个程序来生成模拟数据) - 学会使用SVN
TortoiseSVN使用教程【多图超详细】——大数据开发实习(一)
第二周0601-0605:
0601:分析需求1
系统前端展示参考:友盟
0602:编写版本一的软件需求规格说明文档(SRS)(张志浩)
《v1软件需求规格说明文档(SRS)——大数据开发实习(二)》
0603:进行系统架构设计(非细节设计阶段)、安装环境2
0604:继续安装环境2、编写版本一的架构设计文档(赵磊)
《v1架构设计文档——大数据开发实习(三)》
0605:设计系统前端界面
分配任务如下:
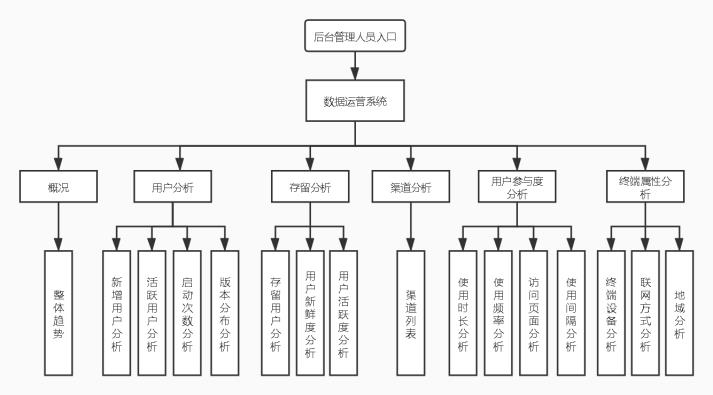
赵磊:概况、用户分析
王阔:存留分析、终端属性分析
张志浩:渠道分析、用户参与度分析
第三周0608-0612:
0608:继续设计系统界面原型
0609:继续设计系统界面原型
0610:继续设计系统界面原型并完成
【迭代式开发】v1前端界面展示+代码——大数据开发实习(四)
0611:确定前端请求数据格式,设计前端所需要的数据库
【ADS层表-V1】前端页面所需的数据库设计——大数据开发实战项目(五)
0612:
- 数据库访问技术选型,从 JAP、Mybatis、JDBC Templete 中选了 JDBC Templete
- 完成了项目架构的分层
- 对前后端进行了分包
- 部分模块的类与方法进行了粗略设计
赵磊:概况(完成部分)、用户分析(未完成)
王阔:存留分析(完成部分)、终端属性分析(未完成)
张志浩:渠道分析(完成部分)、用户参与度分析(未完成)
Web设计技术选型、分层、分包以及类与方法设计——大数据开发实战项目(五)
第四周0615-0621:(周末加班)
0615:
- 继续完成剩下模块的类与方法的设计
赵磊:概况(部分完成,完成部分细节问题有待讨论、实践)、用户分析(部分完成,完成部分细节问题有待讨论、实践)
王阔:存留分析(完成,但细节问题有待讨论、实践)、终端属性分析(未完成,因为要写部分代码的demo)
张志浩:渠道分析(部分完成,完成部分细节问题有待讨论、实践)、用户参与度分析(部分完成,完成部分细节问题有待讨论、实践) - 王阔(但未完成终端属性分析模块的类与方法的设计):实现存留分析部分demo,验证可行性作为web部分代码标准
【迭代式开发v1】类与方法设计(二)——大数据开发实战项目(七)
0616:
- 张志浩、赵磊:实际去建Web前端页面所需的数据库(以前只是设计,并没有实际建表)
- 王阔:Web后端部分代码实现(注:未完成终端属性模块的类与方法设计:TerminalAttributes)
【迭代式开发v1】实际去建Web前端页面所需的数据库(以前只是设计)+Web后端部分代码实现——大数据开发实战项目(八)
0617:小组讨论确定代码注释规范+Web后端类与方法代码实现
【迭代式开发v1】Web后端类与方法代码实现——大数据开发实战项目(九)
0618:继续进行Web后端类与方法代码实现+前后端交互
0619:继续进行Web后端类与方法代码实现+前后端交互
0620:继续进行Web后端类与方法代码实现+前后端交互
0621:继续进行Web后端类与方法代码实现+前后端交互
第五周0622-0628:(周末加班)
0622:继续进行Web后端类与方法代码实现+前后端交互
0623:继续进行Web后端类与方法代码实现+前后端交互
0624:继续进行Web后端类与方法代码实现+前后端交互
(基本结束)原本打算今天把web部署到服务器上,但是第一我们服务器刚被老师重启过,我们怕有问题,第二web还不太完善,比如之前我们都是各自在本地使用mysql数据库,只建了与自己模块相关的数据库表,只对自己需要的表用代码进行了数据的模拟生成和插入,而我们之后部署到服务器,大家各自的模块就都得用同一个数据库——服务器上的数据库,所以服务器上的数据必须满足每个人的模块对数据的需求。但是我们没有那么多时间去做这个了,所以将完善web+在服务器上建库和生成并模拟数据+将web部署到服务器上任务放到周末,我们现在主要任务是数仓
0625:
- 开展数仓设计(全体成员)
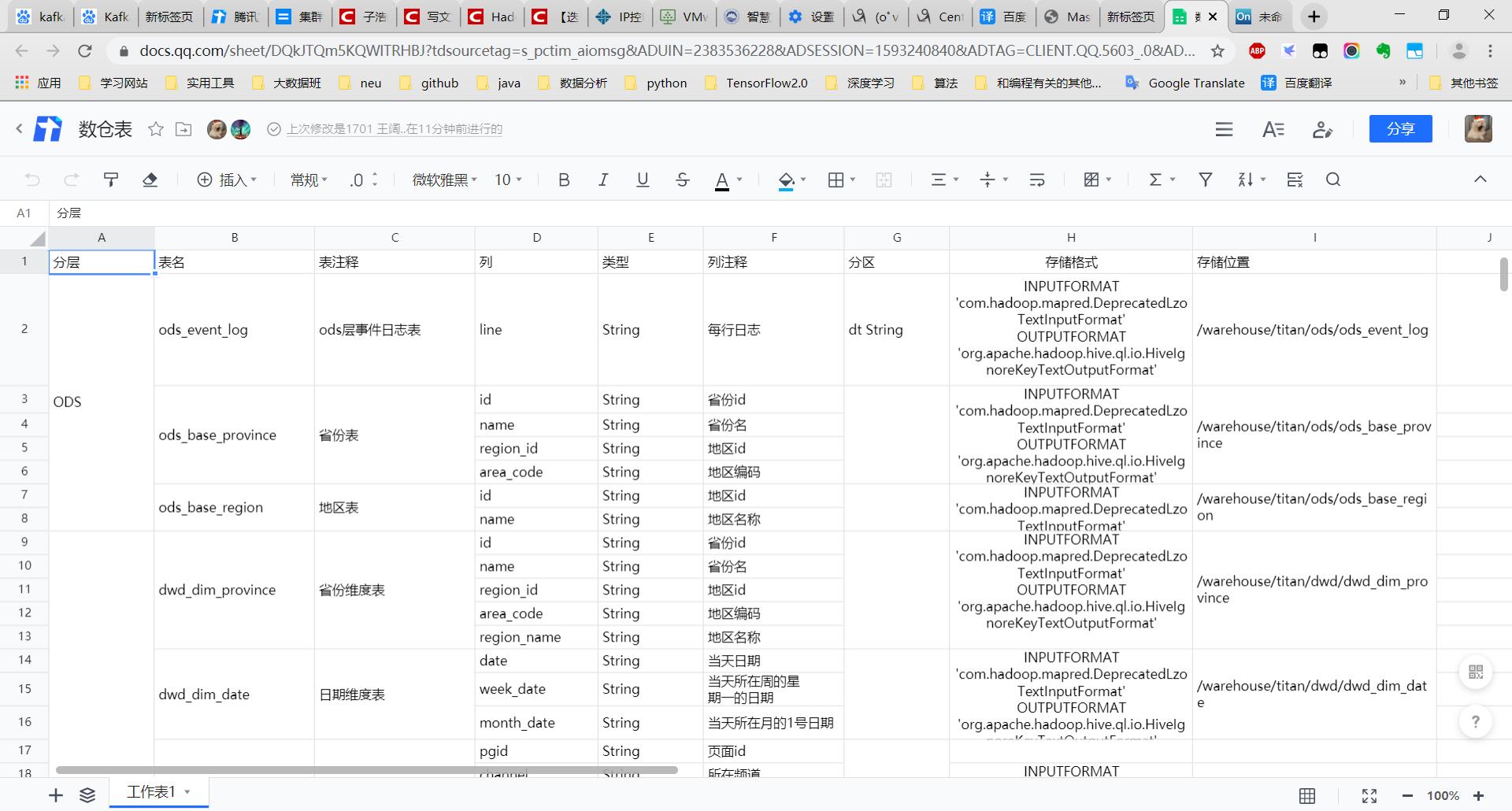
- 确定使用5层结构,ODS层–>DWD层–>DWS层–>DWT层–>ADS层
- 进行了ODS和DWD层设计
先放一个数仓设计展示图,之后补一篇博客(最近加班太多了,来不及写博客)
0626:
- 开展数仓设计(全体成员)
- 进行了部分DWS、DWT层设计
0627:
-
开展数仓设计(全体成员)
- 进行了DWT层设计,完善了ODS层、DWD层和DWS层的设计
-
因为服务器重启过,所以需要重新启动集群的环境:(张志浩+赵磊)
- 将Hadoop、Zookeeper启动了起来
-
绘制数仓各表之间的关系图(王阔)
先放一个集群启动命令+报错展示图,之后补一篇博客(最近加班太多了,来不及写博客)
0628:
- 完善web
- 因为服务器重启过,所以需要重新启动集群的环境
第六周0629-0705:(周末加班)
0629:将web部署到服务器上
http://www.superhao.top:12121/src/material/installation.html
0630:
- 研究ip-mapping算法(张志浩、赵磊)
- 将集群环境全部启动(张志浩、赵磊)
- 编写数仓部分spark任务文档(王阔)
先放ip-mapping算法的部分截图
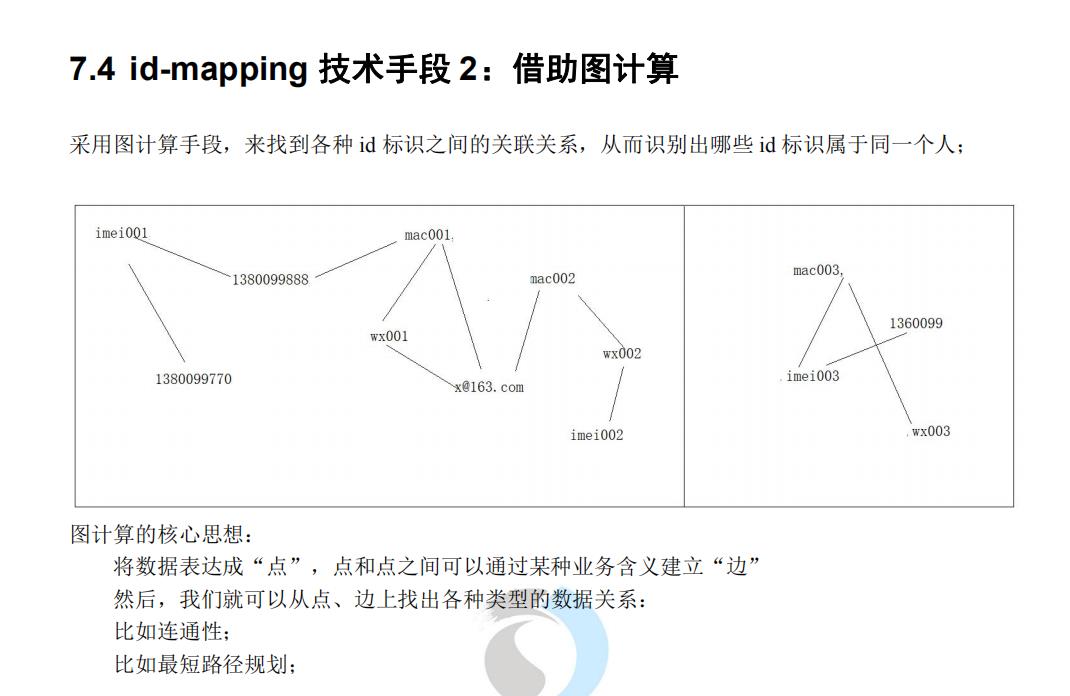
先放一个数仓表之间的关系样图,之后补一个高清图(最近加班太多了)
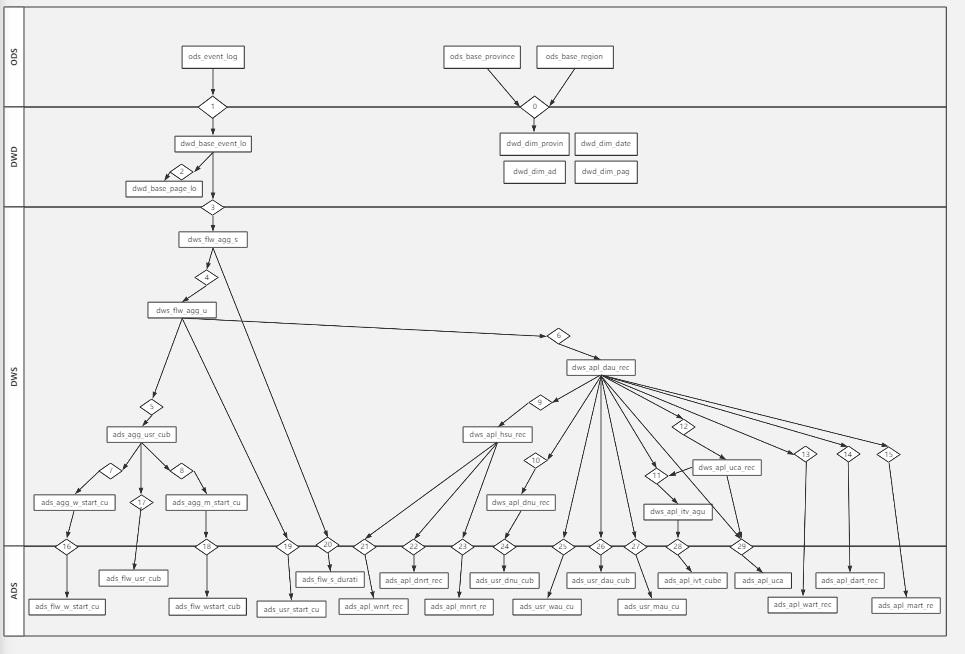
0701:
- (V1)实现ip-mapping代码初始版(spark图计算+scala)(张志浩)
- 搭建 flume 日志采集平台(赵磊)
- 编写模拟数据生成器业务逻辑(王阔)
0702:
- 分配hive表建表任务(全部成员)
- 讨论了 id-mapping 的算法原理(全部成员)
- 进一步讨论id-mapping、flume-kafka和hive任务的整合(全部成员)
- (V2)改进ip-mapping代码初始版,考虑上一日的idmp字典整合(张志浩)
- 实现模拟数据生成器(王阔)
0703:
- 构建spark任务的maven项目,构建完成,初步分包(王阔)
- 完成 hive 建表(在idea写好建表sql语句,并用idea连接hive运行sql语句进行建表)(全部成员,各自完成自己的任务)
- 在建表的过程中, hive 遇到了问题,解决问题https://blog.csdn.net/stable_zl/article/details/107111888
0704+0705:
- 小组讨论如何划分 spark 任务及实现要用到的技术
- 复习 SparkSQL
- 将模拟生成的数据通过 flume-kafka-flume 搭建的平台上传到 hdfs
第七周0706-0712:(周末加班)
0706:
- 进行spark任务项目结构设计(王阔)
- 编写示例spark任务,完成了原始数据导入脚本,json解析任务(王阔)
- 遇到的问题:spark读取hive lzo格式表遇到困难
- 进行了 spark 的开发,将之前编写的 id-map 算法投入到我们的项目中实际使用(张志浩、赵磊)
0707:
- 把 idmap 做了完善,将其输入输出路径与实际的 hdfs 路径进行对应(以前是在win10本地目录写了几个txt文件进行测试)(张志浩、赵磊)
- 进行spark任务编写(各自完成所分配的spark任务,遇到问题开会讨论)
0708:
- 进行spark任务编写(各自完成所分配的spark任务,遇到问题开会讨论)
0709:
- 进行spark任务编写(各自完成所分配的spark任务,遇到问题开会讨论)
0710:
- 进行spark任务编写(各自完成所分配的spark任务,遇到问题开会讨论)
0711+0712:(这周末任务少)
- 完善spark任务
- 讨论怎么样进行数据迁移
- 学习了 sqoop 的相关知识,了解数据迁移的方法,但后来考虑到sqoop的底层依然是 mr,后选用spark jdbc做数据迁移
- 完善文档
第八周0713-0717:
0713:
- 设计数据迁移逻辑(各自完成自己所分配部分)
- 问题:讨论横表的更新方案,并且将其实现
例如赵磊的base_retention_installation_day表,该表用作留存分析-留存用户中的新用户存留展示

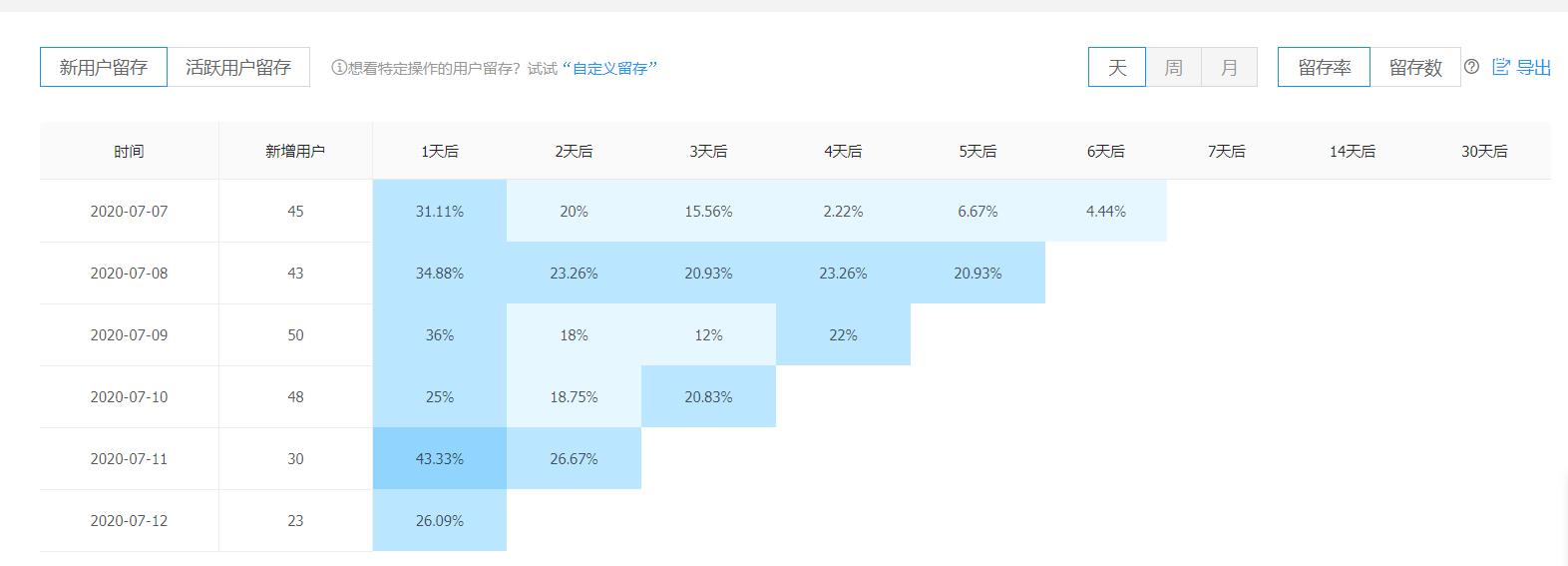
- 问题:讨论横表的更新方案,并且将其实现
0714:
- 测试写好的spark任务:因为前几天服务器集群崩了(我们需要hive数仓),所以我们写好的spark任务一直没有测试(执行)
- 补充:我们不能在win本地用idea跑spark任务,会因为hive表为lzo压缩格式而报错
0715:编写各自的ads层数仓表到mysql的数据迁移任务代码(用SparkSQL进行迁移,以前选的是sqoop,但是sqoop的底层是mapreduce,速度大大慢于spark,所以我们最终选择了SparkSQL)
0716:去集群测试我们迁移任务代码
0717:测试atlas的使用,最终失败了,atlas无法监控hive表之间的血缘关系,我们测试了一下原因:用SparkSQL操作hive表,atlas就无法监控,但是直接在hive命令好用hiveSQL操作hive表,atlas就可以监控
第九周0720-0725:(完结)
0720、0721:编写、部署azkaban任务
0722:编写PPT、录制答辩视频
0723:编写《实训阶段总结报告》和《实训总结报告》
0724:答辩(在腾讯会议和实训项目经理对线)
0724:编写《13.T01模块部署流程手册.docx》和《14.T01用户使用手册.docx》
《v1数据分析运营系统的需求分析》
1.整体趋势:
基础统计数值:包括7日平均新增用户、活跃用户等,一周内、一个月内的统计量总数,总用户数。
指定时间区间内(默认30天内每日):
新增用户、活跃用户、启动次数、累计用户
折线图,明细数据列表
Top版本环形图:新增用户、活跃用户、累计用户每个版本占比
Top渠道环形图:新增用户、活跃用户、累计用户每个渠道占比
2.用户分析:
a.新增用户:
指定时间段、指定渠道和版本,每日新增用户折线图、明细数据表格
次日存留率折线图、明细
b.活跃用户:
指定时间段、指定渠道和版本下,
活跃趋势、活跃构成、活跃粘度、分时活跃用户、周,月活跃度
c.启动次数:
指定时间段、指定渠道和版本下,每(小时、天、周、月)的启动次数
d.版本分布:
指定时间段、版本下, 每天新增用户、活跃用户、启动次数折线图
今日、昨日截至今日版本累计用户(%),新增用户,活跃用户(%),启动次数
3.留存分析:
a.留存用户
指定时间段、指定渠道和版本下,每一个时间段(天、周、月)新用户和活跃用户数在接下来一段时间(天、周、月)的留存数/留存率,以表格形式和折线形式呈现。
b.用户新鲜度:
报表展示每天活跃用户的成分构成,并提供用户成分分析控件做进一步的分析。某日的活跃用户来源于当天新增用户、1天前新增用户…30天前新增用户、30+天前新增用户。
c.用户活跃度:
报表展现每个天级时间点的当日活跃用户的活跃程度。
4.渠道分析:
a.渠道列表:
指定时间段、指定版本,各渠道新增用户、活跃用户、启动次数
5.用户参与度
a.使用时长:
指定某一天、指定渠道和版本下,单次使用时长分布柱形图,明细表格。
该天每个活跃用户使用时长分布柱形图、明细表格。
b.使用频率:
指定日期,指定版本、渠道,当日、上周、上个月使用次数分布柱形图,明细表格。
c.访问页面:
指定时间段(一天、一周、一个月)、指定渠道和版本下,访问页面分布柱形图,明细表格。
d.使用间隔:
查看任意30天内用户相邻两次启动间隔的分布情况,并可以进行版本、渠道及分群的筛选。以柱形图、明细表格形式展示。
6.终端属性:
a.设备终端:
指定时间段(一天、一周、一个月)、指定渠道和版本下 ,top10机型、分辨率、操作系统的新增用户/启动次数柱状图、明细表格。
b.网络及运营商:
指定时间段(一天、一周、一个月)、指定渠道和版本下 ,各种联网方式的新增用户/启动次数柱状图、明细表格。
c. 地域:
指定时间段(一天、一周、一个月)、指定渠道和版本下 ,各省市的新增用户/活跃用户/启动次数柱状图(top10省)、明细表格(省市)。 ↩︎所需安装环境为:
- jdk1.8.0_151、
- mysql-5.7.28、
- hadoop-3.2.1、
- flume-1.9.0、
- azkaban-3.90.0
- zookeeper-3.6.1、
- hive-3.1.2、
- spark-3.0.0
- scala-2.11.12
- kafka-2.4.1、
- (hbase-2.2.5、solar-8.5.2这两个是atlas安装的前置)
- atlas-2.0.0、
- sqoop-1.99.7
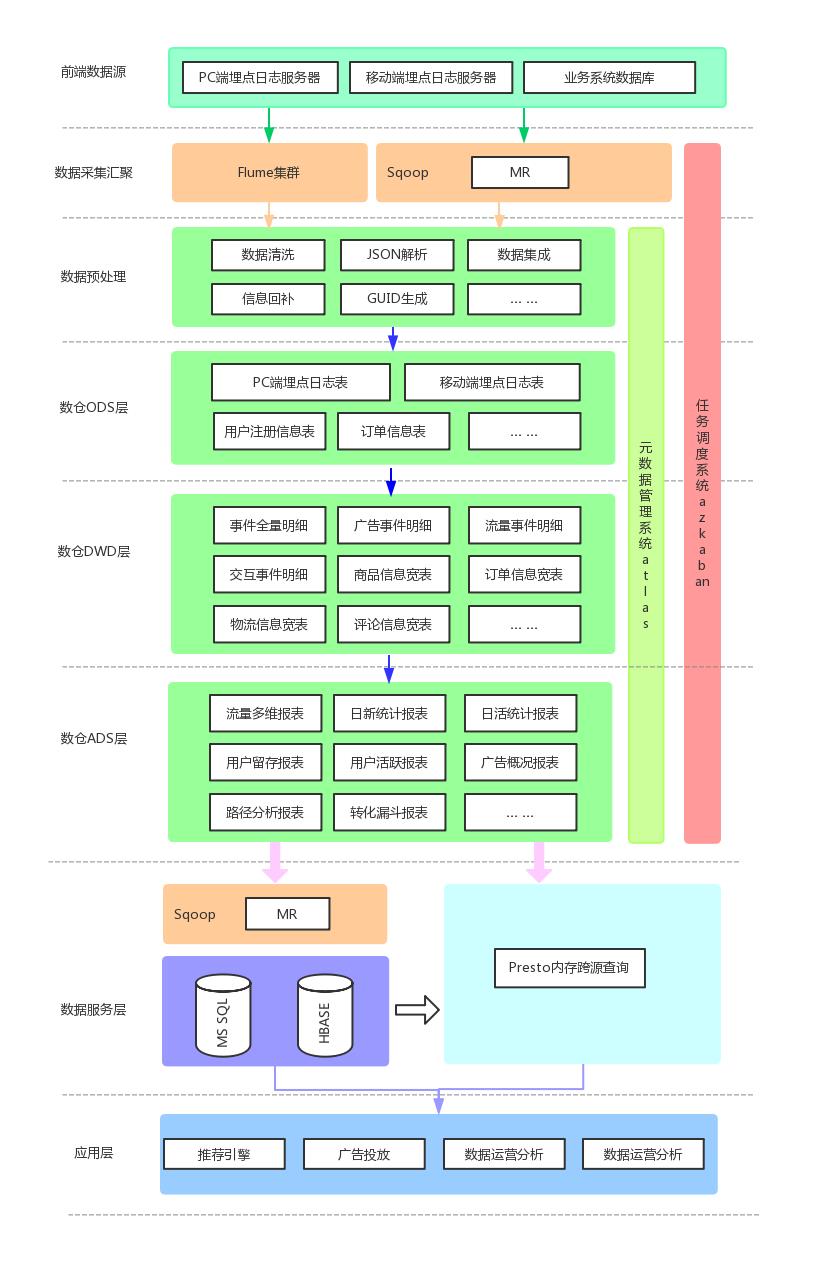
每个环境的作用:
数据采集传输:- Flume:分布式日志数据汇聚
- Kafka:实时采集(计算)的缓冲
- Sqoop:离线批量抽取数据库
数据存储:
- Mysql
- HDFS
数据计算:
- Spark
数据可视化:
- Echarts
job任务调度:
- Azkaban
元数据管理:
- Atlas
以上是关于大数据项目开发进度(实时更新)的主要内容,如果未能解决你的问题,请参考以下文章