ELK技术栈简介
Posted TacitusKillgore
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ELK技术栈简介相关的知识,希望对你有一定的参考价值。
ELK技术栈简介
ELK是什么
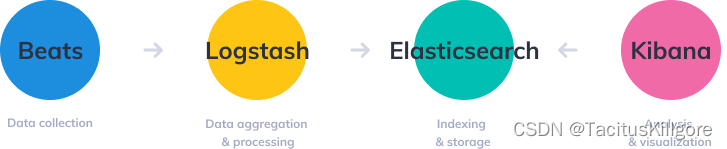
ELK 即 Elasticsearch + Logstash + Kibana,是指Elastic公司开发的三种免费开源软件。其中,Elasticsearch是一个基于Apache Lucene的RESTful风格的分布式搜索引擎,Logstash是一款轻量的日志收集、处理和分发工具,Kibana则为Elasticsearch提供了一个前端可视化界面。ELK后来被更名为Elastic Stack,并在前面三种开源软件的基础上引入了Beats,用于提供轻量级的日志收集和传输功能。
对于数据量较小的业务场景,ELK可以采用如下的经典架构进行部署:
如果是数据量较大的业务场景,则可以考虑如下的部署架构:

ELK组件
Elasticsearch
Elasticsearch(后文简称ES)最早发布于2010年,是一款基于Apache Lucene实现的分布式全文检索和分析引擎。ES完全开源免费,使用Java语言开发,被归类于NoSQL数据库。不同于传统的关系型数据库,ES以非结构化的方式存储数据,因此不支持SQL查询。在ES中检索数据最简单的方法就是使用它提供的REST API。
ES基本概念
ES中基本概念与关系型数据库的对应关系:
| ES概念 | 关系型数据库概念 |
|---|---|
| Index | Database |
| Document | Row |
| Type | Table |
| Field | Column |
ES中有以下重要的基本概念:
- Index(索引)
ES中的Index是文件的逻辑分区,类似于关系型数据中的database概念。
- Documents(文档)
Documents是Index内部存储的JSON对象,类似于关系型数据库中表里面的一行数据。Documents是ES中数据存储的基本单元。
一个Document由不同的Fields构成。每个Field都是一个键值对,其中Key是Field的名称,Value则可以是字符串、数字、布尔表达式、对象、或者数组中的任意一种数据类型。
- Fields(属性/字段)
Field即字段或属性,类似于关系型数据库中的列。Field是ES中最小的独立单位的数据。
- Types(类型)
Types被用来进一步划分相似类型的数据。每个Type代表一种唯一类型的Documents。每个Type由一个名称和一个Mapping组成。通过添加_type属性来指定Type。
⚠️ 从ES 7开始,官方将Types列为deprecated。从ES 8开始,不再支持在查询中使用Types。
- Mapping(映射)
与关系型数据库中的schema类似,ES中的Mapping用于定义Index内部的不同Types。Mapping定义了特定类型Document的Fields——数据类型(比如字符串和整数)以及Fields在ES中应该如何被索引和存储。
Mapping可以显式定义,也可以在使用模板对Document进行索引时自动生成。模板包含的设置和Mapping可以被自动应用到新的索引。
- Node(节点)
Node是指运行了单个ES实例的主机。Node是ES集群中的一个成员,可以存储数据、参与集群索引以及检索操作。
- Shards(分片)
索引大小是导致ES崩溃的常见原因。由于每个Index可以存储的Documents数量没有限制,因此索引占用的磁盘空间量可能会超过服务器的上限。一旦索引逐渐逼近该限制,索引就会开始失效。
ES的分片机制可以把一个Index内部的数据水平拆分到多个节点上。它通过将一个Index切分为多个底层物理的Lucene Index来完成索引数据的分割存储功能。每一个物理的Lucene Index称为一个分片(Shard)。每一个分片内部都是一个全功能且独立的索引,可以由ES集群中的任意一个节点存储。
ES支持通过跨分片和节点的分布式操作来提高性能。用户可以控制每个索引的分片数量,并将这些分片托管在ES集群中的任意节点上。我们可以在创建索引时定义分片的数量,但是一旦创建完成,主分片的数量就不能再修改。
- Replicas(副本)
为了能够轻松地从系统故障(例如意外停机或网络问题)中恢复,ES支持为分片创建副本。此时,原始分片被称为主分片(Primary shard),其副本称为副本分片(Replicas shard)。每个主分片可以有一个或多个副本。副本可以处理读请求,因此增加副本分片可以提高搜索性能。
副本旨在确保高可用性,所以它们不能与对应的主分片位于相同的节点上。
与分片类似,副本的数量可以在创建索引时定义。与分片不同的是,副本的数量也可以在创建索引后随时动态修改。
🍎总结一下:
- 一个ES Index集群中有多个Node。每个Node都是一个ES实例;
- 每个Node上会有多个Shard和Replicas。同一个主Shard和它对应的Replicas不会位于同一个Node上;
- 每个Shard都对应一个底层物理的Lucene Index文件;
- 每个Lucene Index都由多个Segment段文件组成。每个段文件都存储有Documents。
ES适用场景
适用场景:
- 全文检索:实现对海量数据的快速检索,自定义打分、排序机制。
- 日志分析:通过ELK技术栈对日志进行收集统计,用于业务分析和错误排查。
- 分布式文档:对json支持完善,对地理位置支持完善。
- 数据可视化:配合Kibana或Grafana从多个维度对数据做聚合分析。
主要缺点:
- 不支持事务:如果应用场景有强一致性要求,需要ES与关系型数据库结合使用。
- 不擅长关联查询:ES不擅长关系型数据库的多表关联查询,性能很差。
- 非实时数据:由
refresh_interval决定,最快1s延迟。
Logstash
Logstash可以看作是一条具备实时数据传输和过滤能力的管道(Pipeline)。不同来源的数据被采集后从管道的输入端传入,经过一定的数据过滤和标准化处理,最终从输出端被传输到不同的目的地。Logstash提供大量插件,用于解析、转换和缓存任何类型的数据。
由Logstash聚合和处理的事件(Event)需要经历三个流程阶段:收集(Collection)、处理(Processing)和分发(Dispatching),分别由输入插件(Input plugins)、过滤插件(Filter plugins)、以及输出插件(Output plugins)完成。
Input插件
Logstash能够聚合来自各种不同数据来源的日志和事件。它提供50多种分别支持不同平台、数据库和应用的输入插件来采集数据。
常见的输入数据类型有file、beats、syslog、redis、http、tcp、udp、stdin。
Filter插件
Logstash提供大量的过滤插件来对采集到的数据进行中间处理。
常见的过滤插件包括grok、date、mutate、drop、clone、geoip。其中Grok是Logstash最重要的过滤插件,它可以将文本格式的字符串转换为结构化的数据,并支持正则表达式。
Output插件
Logstash提供一系列输出插件来将采集到的数据推送到不同的目的端。如果用户没有定义output,Logstash会自动创建一个stdout输出。一个Event可以经过多个输出插件。
常见的输出组件有elasticsearch、file、graphite、statsd等。
Codecs
Codecs即编解码器,可以在Input和Output中使用。例如,在数据进入输入插件之前对数据进行解码,在数据离开输出插件之前对其进行编码。
常见的Codecs有plain、json、multiline、msgpack。
Kibana
Kibana是一个完全开源的基于浏览器的用户界面,可以用来搜索、分析和可视化存储在Elasticsearch索引中的数据。Kibana不支持与其他数据库一起使用。
Beats
Beats是一种基于Go语言开发的轻量级数据采集工具。大多数Beats都直接安装在数据源上,用于特定的数据收集目的。Beats采集到的数据会被转发到Elasticsearch或Logstash。
常见的Beats包括filebeat、topbeat、heartbeat、metricbeat、packetbeat、auditbeat、functionbeat、winlogbeat。
-
filebeat
Filebeat用于采集和发送日志文件。Filebeat可以安装在几乎任何操作系统上,包括作为Docker容器部署,还附带了针对特定平台(如Apache、mysql、Docker等)的内部模块,包含针对这些平台的默认配置和Kibana对象。 -
heartbeat
用于健康检查。 -
metricbeat
采集各种系统和平台的各种系统级度量指标。 -
packetbeat
采集服务器之间的网络包数据,可以用于应用程序和性能监控。 -
winlogbeat
专门为收集Windows事件日志而设计,可以用来分析安全事件、已安装的更新等等。
References
【1】https://elastic-stack.readthedocs.io/en/latest/introduction.html
【2】https://logz.io/learn/complete-guide-elk-stack/
【3】https://zhuanlan.zhihu.com/p/78309627
【4】https://www.jianshu.com/p/e8226138485d
【5】https://www.elastic.co/guide/en/elasticsearch/reference/6.0/_basic_concepts.html
【6】https://github.com/elastic
【7】https://logz.io/blog/10-elasticsearch-concepts/
【8】https://zhuanlan.zhihu.com/p/379656230
以上是关于ELK技术栈简介的主要内容,如果未能解决你的问题,请参考以下文章
2021年大数据ELK:集中式日志协议栈Elastic Stack简介