PostgreSQL 分组聚合查询中 filter 子句替换 case when
Posted 地表最强菜鸡
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PostgreSQL 分组聚合查询中 filter 子句替换 case when相关的知识,希望对你有一定的参考价值。
PG聚合操作中的filter子句是ANSI SQL标准中的关键字,并不是PG的专用SQL关键字。如果我们想了解中国、美国、日本、法国、德国、加拿大从1960~2018年中每隔十年的GDP平均值情况,我们可能会写出着这样的SQL,
select country_name, sum(case when year>=1960 and year<1970 then gdp else null end) as "1960~1969",
sum(case when year>=1970 and year<1980 then gdp else null end) as "1970~1979",
sum(case when year>=1980 and year<1990 then gdp else null end) as "1980~1989",
sum(case when year>=1990 and year<2000 then gdp else null end) as "1990~1999",
sum(case when year>=2000 then gdp else null end) as "2000~至今"
from country_gdp_year_final
where country_code in('CHN','JPN','USA','DEU','CAN','FRA') group by country_name;
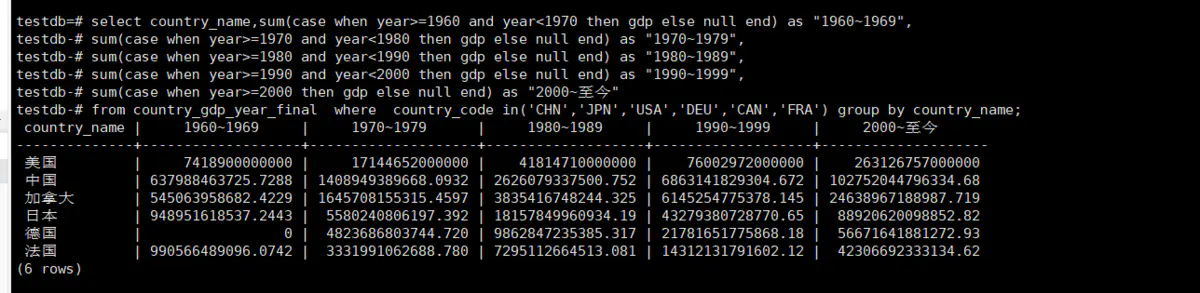
从上图可以看出美国的经济体量和我们中国的经济体量不是在一个数量级的,中国每隔十年的GDP实现一倍的增速,美国一直飞速发展时期,中国要实现美国的GDP的话粗略估计需要至少30年的时间甚至更久;
回归正题,我们今天的主角是filter子句,ANSI SQL加入filter关键词的主要目的就是替代case when子句,简化case when参与的聚合语句,增加可可读性,我们用同样的filter 子句实现上面的case when参与的聚合操作。
select country_name,
sum(gdp) filter(where year>=1960 and year<1970) as "1960~1969",
sum(gdp) filter(where year>=1970 and year<1980) as "1970~1979",
sum(gdp) filter(where year>=1980 and year<1990) as "1980~1989",
sum(gdp) filter(where year>=1990 and year<2000) as "1990~1999",
sum(gdp) filter(where year>=2000 ) as "2000~至今"
from country_gdp_year_final
where country_code in('CHN','JPN','USA','DEU','CAN','FRA') group by country_name;
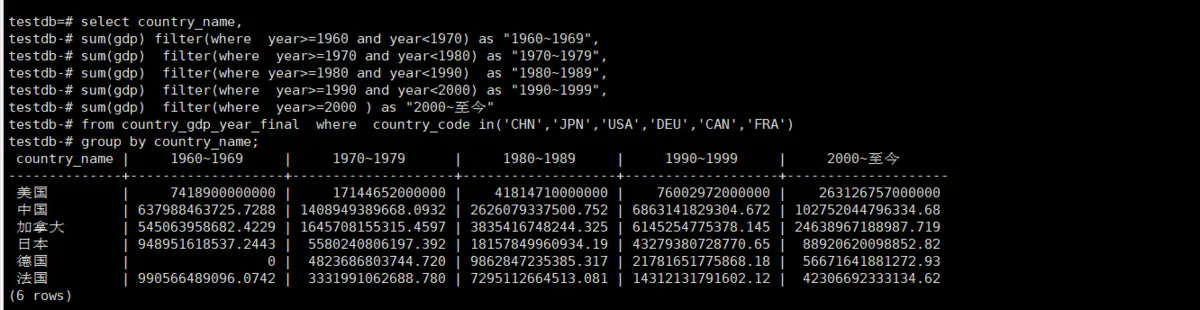
从上面的结果我们可以看出filter子句和case when 子句在聚合函数中使用是等价的,并且filter子句的可读性更好,让人一眼就能看出SQL的目的和作用,
下面我们看一下上面俩个语句的的执行计划:
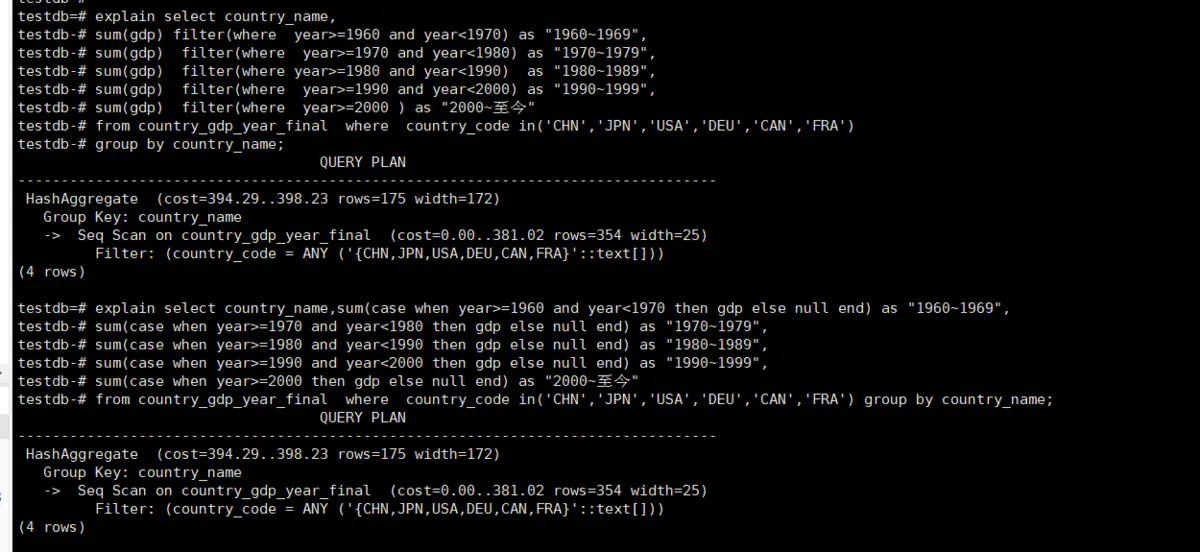
从上面的结果我们可以看出来俩种语句不仅结果一样而且产生的执行计划也是一致的,并且俩个语句值进行了一次权标扫描就计算出了结果,在平时的开发中,很多开发者为了实现相同的结果可能要进行五次权标扫描,很可能会写出以下的相同查询结果但是不同性能的SQL
select ff.country_name,
ff."1960~1969",
aa."1970~1979",
bb."1980~1989",
cc."1990~1999",
dd."2000~至今"
from (
select country_name, sum(gdp) as "1960~1969"
from country_gdp_year_final ff
where year>=1960 and year<1970 and country_code in('CHN','JPN','USA','DEU','CAN','FRA')
group by country_name)as ff
left join (select country_name,sum(gdp) as "1970~1979"
from country_gdp_year_final where year>=1970 and year<1980 and country_code in('CHN','JPN','USA','DEU','CAN','FRA')
group by country_name) as aa
on aa.country_name=ff.country_name
left join (select country_name,sum(gdp) as "1980~1989"
from country_gdp_year_final where year>=1980 and year<1990 and country_code in('CHN','JPN','USA','DEU','CAN','FRA')
group by country_name ) as bb o
n bb.country_name=ff.country_name
left join (select country_name,sum(gdp) as "1990~1999"
from country_gdp_year_final where year>=1990 and year<2000and country_code in('CHN','JPN','USA','DEU','CAN','FRA')
group by country_name ) as cc
on cc.country_name=ff.country_name
left join (select country_name,sum(gdp) as "2000~至今"
from country_gdp_year_final where year>=2000 and country_code in('CHN','JPN','USA','DEU','CAN','FRA')
group by country_name ) as dd
on dd.country_name=ff.country_name;
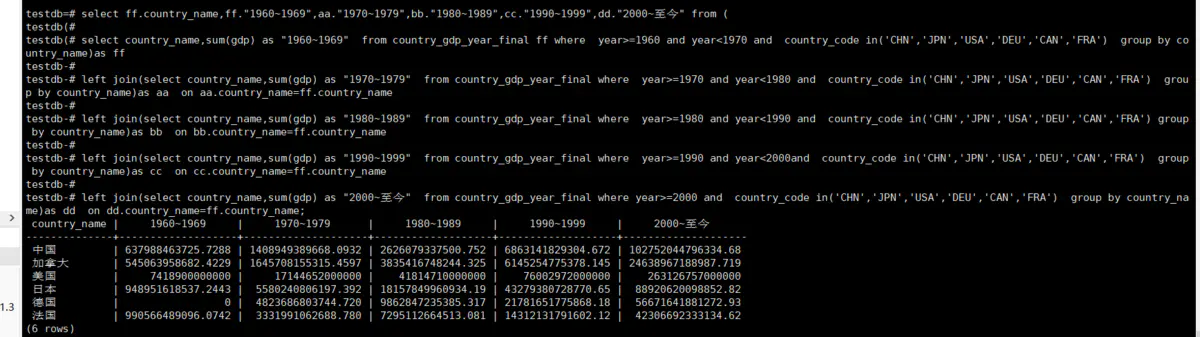
我也相信很多人开发者写出来的SQL和上面的SQL基本差不多,这种SQL不仅很长而且很难都,更致命的是这种SQL进行了五次全表扫描,在不考虑缓存命中的的情况下,这种SQL的查询时间是上面filter和case when子句的五倍,我们可以看一下这个长SQL的查询计划。
从上面的查询计划我们可以看出来经过了五次全表扫描,五次聚合,如果这个表的数据量很大,那么性能可想而知。
最后我想说的是filter适合所有的聚合函数,不仅仅是PG内置的的聚合函数,还支持安装扩展包的聚合函数,总之filter子句非常的棒!!!
以上是关于PostgreSQL 分组聚合查询中 filter 子句替换 case when的主要内容,如果未能解决你的问题,请参考以下文章