图像聚类-K均值聚类
Posted 小胖子小胖子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图像聚类-K均值聚类相关的知识,希望对你有一定的参考价值。
最近做的一个东西跟这个相关,本来希望是用深度学习对于没有标签的图像数据进行分类,但是通常情况下,深度学习是对有标签的数据进行学习,目的是用来自动提取特征,代替传统的手工提取特征。因此,比较容易想到,对于无标签又需要分类的图像数据,可以尝试先采用聚类来解决.
下面的内容是译自Jan Erik Solem的《Programming Computer Vision with Python》的第6章,该书已经由朱文涛和袁勇学长对该书进行了翻译,主要涉及相关代码和实例,可以转至http://yongyuan.name/pcvwithpython/。 我仅对其中第6章的理论进行翻译,中途穿插自己的理解。
该博文仅供交流学习,如有侵权,请联系删除。
====================================================================
第6章 图像聚类
这一章节主要介绍了几种聚类方法,显示了如何将其用在聚类图像中从而找到相似图片的组。聚类可以用于识别,用于将图像数据集进行分类,用于组织和导航。我们也关注将聚类用于图像间的相似度的可视化。
6.1 K均值聚类(K-meansClustering)
K均值是一个非常简单的聚类算法,将输入数据分到K个类中。K均值是通过循环更新类中心的初始估计值来实现的,其步骤如下:
1.初始化类重心ui, I = 1, …k, 可以通过随机初始化或者使用一些猜测的值;
2.将每一个数据点赋给距离类ci最近的中心;
3.更新中心为赋给某一类的所有数据点的平均值;
4.重复步骤2和3直至收敛。
K均值尽可能地最小化类之间的方差:
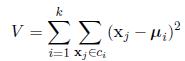
其中xj是数据向量。上面的算法是一个启发式的提炼算法,对于大多数的情况是试用的,但是不能够保证得到的结果是最好的。为了避免找到一个不好的中心的初始化的影响,该算法通常是使用不同的初始化中心运行几次。然后从这些结果中选择具有最小方差V的作为最后的结果。
该算法的主要缺陷是,类的数目需要提前确定,也就是说,我们必须一开始指定将数据聚成几类,也就是传入的参数K。这样的话,一个不恰当的选择可能就会导致很差的聚类结果。其优势是实现起来很简单,是并行化的,并且对于大范围的问题不需要任何调整就可以实现很好的结果。
SciPy聚类包
由于该书的例子都是使用python实现,因此需要介绍一些必要的包。
尽管K均值算法容易实现,但是也不是没有必要实现一下。SciPy向量量化包sciPy.cluster.vq自带一个K均值的实现。下面是它如何使用的。
让我们首先从创建一些二维样本数据来说明。

这个可以在二维下生成2个正态分布的类。为了聚类这些点,可以设置k=2运行下面的k聚类:

方差会被返回但是事实上我们不是非常需要,因为SciPy实现计算了几次运行(默认是20)然后为我们选择了有着最小方差的一个返回。现在,需要在SciPy包中确认是否每一个数据点都使用向量量化函数被赋值了。

通过检查code的值,我们可以看到是否存在不正确的赋值。为了可视化,我们可以将这些点和最后的中心都画出来。

这里函数where()是给出每一个类的索引。通过运行代码,可以得到下面的结果:
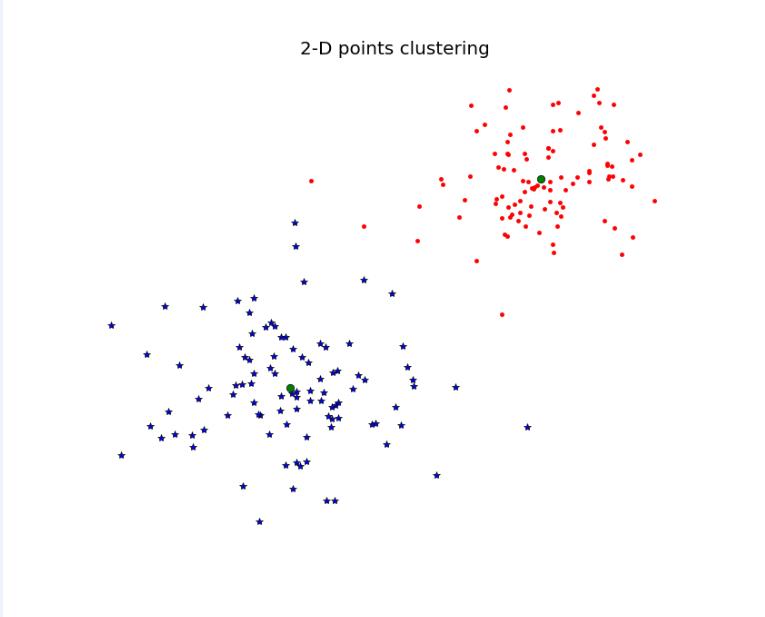
图1- 2D点的K均值聚类的样例
这是我重新跑的结果,因为书上的图不是特别清楚。其中类重心是被标记为绿色的环,预测的类别分别是蓝色的星星和红色的点点。
图像聚类
下面我们将K均值算法运用在书中前面章节提到过的字体图像中。文件selectedfontimages.zip包含66张从这个字体数据集中提取的图像(这些选择都是为了在显示类时容易观察,另住:这些数据也可以通过最开始提到的链接中下载到)。作为每一个图像的描述向量,我们将会使用映射系数,在映射到先计算好的前40个首要主成分之后。使用pickle加载模型文件,然后主成分上的图像映射和聚类就可以按照下面的代码实现:

跟之前一样,code包含了对于每一张图像的聚类赋值。在这个实例中,我们令k=4。我们也使用sciPy的whiten()函数将数据进行漂白,归一化,使得每一个特征都有单位方差。尽力改变像使用的主成分的数目和k的值这样的参数为了观察聚类结果是如何改变的。聚类可以通过下面的代码被可视化:

这里,我们对每一个类都使用一个单独的最多显示40张图像的网格窗口来显示。我们使用PyLab函数subplot()来定义这个网格。一个实例结果如下。

图2- 使用40个主成分的字体图像,k=4的K均值聚类
如果需要更多的SciPy实现的K均值的细节,可以查看参考资料http://docs.scipy.org/doc/scipy/reference/cluster.vq.html。
主成分可视化图像
为了看使用一些主成分的聚类如何实现,我们可以通过在一组主成分方向上基于它们的坐标可视化图像。其中一个方法是通过改变映射得到相关的坐标(在这个例子中,V[[0,2]]给出第一个和第三个)而映射到两个成分上。另外,映射所有的主成分,然后选出你需要的列。

为了可视化,我们将使用PIL中的ImageDraw。假设你已经有了所有的映射图像和图像列表,下面的代码将生成图3

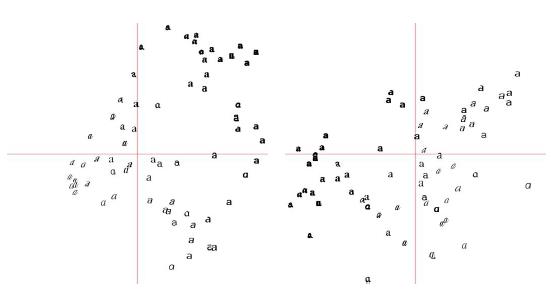
图3- 在成对主成分上的字体图像的映射。
左边是第一和第二个主成分,右边是第二和第三个
这里,我们使用了整数和地板整数运算符//,该运算符通过移除小数点后的值返回一个整数像素位置。
像这样的图说明了在40维中图像是如何被分布的,并且在选择一个好的描述符时非常有用。已经在这二维映射中的相似的字体图像的分界线可以清晰可见。
像素聚类
在这一节结束之前,我们将看一个聚类单独的像素而不是整个图像的例子。将图像区域(和像素)分组成有意义的成分叫做图像分割,这也是后面第9章的内容。将K均值算法简单的应用到像素值上是不能够得出任何有意义的东西的,除非是在非常非常简单的图像中。更加复杂的类模型(比平均像素颜色)或者空间一致性是需要来产生更加有用的结果。现在,我们将K均值应用到RGB值上,之后再考虑解决分割问题(章节9.2会有详细描述)。
下面的代码样本输入一张图像,将其减到一个更低的分辨率的版本,其中像素是原始图像区域(大小step * step的正方形网格表示)的平均值,并使用K均值聚类这些区域。
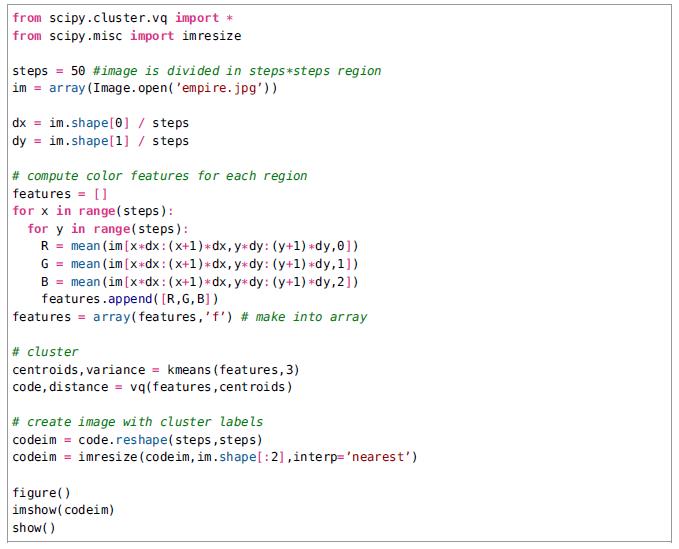
K均值的输入时一个有着steps * steps行的数组,每一个包含R,G和B的均值。为了可视化结果,我们使用SciPy的imresize()函数来显示在最初图像坐标处的steps * steps的图像。参数interp指定使用哪一种插值方式,这里我们使用最近邻,这样我们在类之间的转换时不需要引入新的像素值。
图4显示了使用50x50和100x100区域用于两个相对简单的样例图像的结果。需要注意的是,K均值标签(这个情况下是结果图像中的颜色)的顺序是任意的。正如你所看到的,尽管下采样为了只使用一些区域结果也是比较有噪的。没有空间一致性,也很难分离区域,像下面例子中的男孩和草地。
空间一致性和更好的分离将在之后被处理,与其他的图像分割算法一起。

图4-使用K均值给予它们颜色值的像素聚类。左边是原始图片,
中间是k=3和50x50分辨率的聚类结果,右边是k=3和100x100分辨率的聚类结果。
以上是关于图像聚类-K均值聚类的主要内容,如果未能解决你的问题,请参考以下文章