腾讯 PB 级大数据计算如何做到秒级?
Posted 腾讯技术工程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了腾讯 PB 级大数据计算如何做到秒级?相关的知识,希望对你有一定的参考价值。

天穹 SuperSQL 是腾讯自研,基于统一的 SQL 语言模型,面向机器学习智能调优,提供虚拟化数据和开放式计算引擎的大数据智能融合平台。在开放融合的 Data Cloud 上,业务方可以消费完整的数据生命周期,从采集-存储-计算-分析-洞察。还能够满足位于不同数据中心、不同类型数据源的数据联合分析/即时查询的需求。
Presto 在腾讯天穹 SuperSQL 大数据生态中,定位为实现秒级大数据计算的核心服务。主要面向即席查询、交互式分析等用户场景。Presto 服务了腾讯内部的不同业务场景,包括微信支付、QQ、游戏等关键业务。日均处理数据量 PB 级,P90 查询耗时为 50s,全面提升各业务数据实时分析性能,有效助力业务增长。本篇文章将揭秘腾讯大数据在 Presto 上的核心工作,包括易用性、稳定性、性能,以及未来的主要方向等方面。
1 天穹 Presto 整体架构
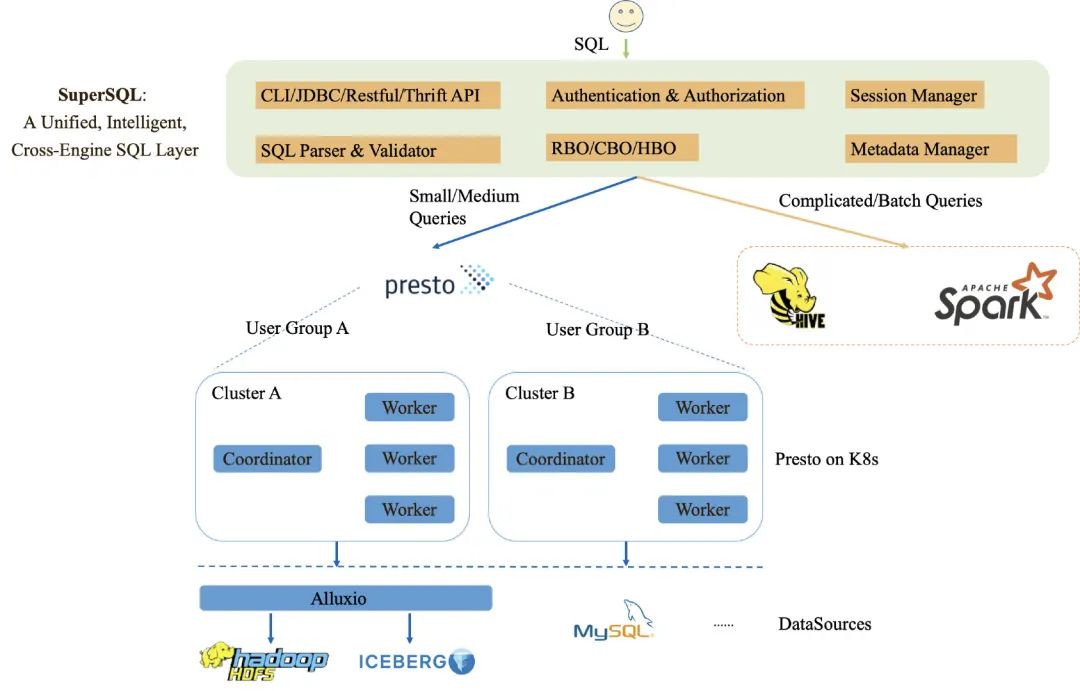
天穹 Presto 作为天穹 SuperSQL 的主要执行引擎之一,主要承担着加速用户 SQL 执行速度的角色。SuperSQL 通过智能路由(RBO/CBO/HBO)的方式,智能筛选出合适的 SQL 并分发给 Presto 执行,以加速 SQL 计算。另外,如果 Presto 执行失败,SuperSQL 也能自动 Failover 到 Hive 或 Spark 重新执行,以确保用户 SQL 能顺利执行完成,而整个过程对用户透明、无感知。
关于天穹 SuperSQL 的介绍,可以查看历史文章:「解耦」方能「专注」——腾讯天穹 SuperSQL 跨引擎计算揭秘
天穹 Presto 采用了 on K8s 容器化部署的方式,具备自动化运维、弹性伸缩等云原生能力。同时支持为不同的业务独立部署专属的 Presto 集群,以避免造成不同集群负载的相互影响。
得益于 Presto 的多数据源访问能力,天穹 Presto 支持对接了 Hive、Iceberg、mysql 等数据源,且为了更好地支持内部的业务,我们也扩展开发了内部的 TDW Connnector,支持访问腾讯内部的数据仓库数据(TDW,Tencent distributed Data Warehouse)。同时天穹 Presto 使用了 Alluxio 作为数据源(Hive 表、Iceberg 表)的缓存层,用于加速热点数据的访问,可有效提升 Presto 查询的效率。
2 易用性增强
2.1 Hive 语法兼容
由于部分用户习惯于使用 Hive 的语法,而 Presto 自身的语法语义与 Hive 相比又有些不同,因此天穹 Presto 在引擎侧做了兼容部分 Hive 语法语义的工作,主要包括:数值除法、数组下标取值、Hive UDF 支持、Mapjoin Hint、隐式转换等。
对于 Mapjoin Hint,其实是对应于 Presto 中的 Broadcast Join,用户通过 Mapjoin Hint 来指定多表 Join 中的需要 Broadcast(广播)的表,以此提升查询的性能,适用于大小表 Join 的场景。目前已支持在 Inner Join 和 Left Join 中使用 Mapjoin Hint。
-- Presto采用Broadcast Join,Broadcast的表为test2
select t1.b, /*+mapjoin(t2)*/ t2.b2 from test1 t1 join test2 t2 on t1.a = t2.a2;
-- Presto采用Broadcast Join,Broadcast的表为test1、test3
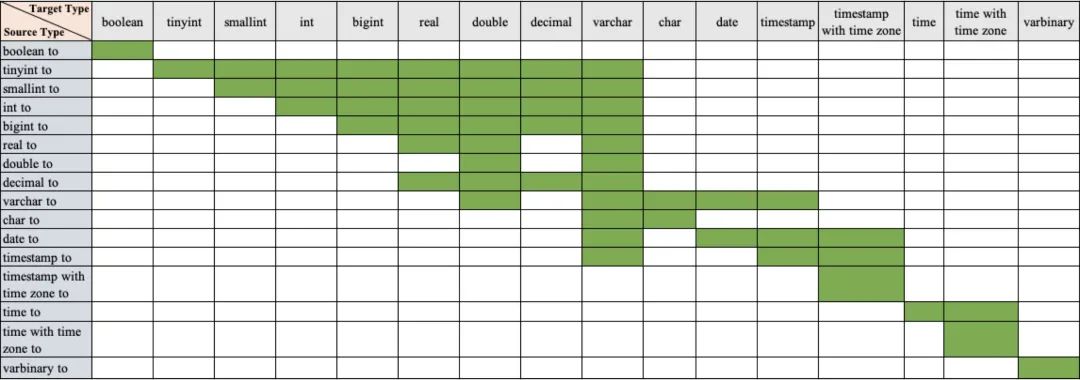
select t1.b, /*+mapjoin(t1,t3)*/ t2.b2, t3,b3 from test1 t1 join test2 t2 on t1.a = t2.a2 join test3 t3 on t1.a=t3.a3;由于原生 Presto 不支持数值类型与字符串之间的隐式转换,为了兼容部分习惯于使用隐式转换的用户,天穹 Presto 在引擎侧做了增强,以支持类似于 Hive 语法中隐式转换的功能。
天穹 Presto 隐式转换规则表如下所示:(绿色表示支持从 Source Type 到 Target Type 的隐式转换,其余空白格表示不支持类型之间的隐式转换)。
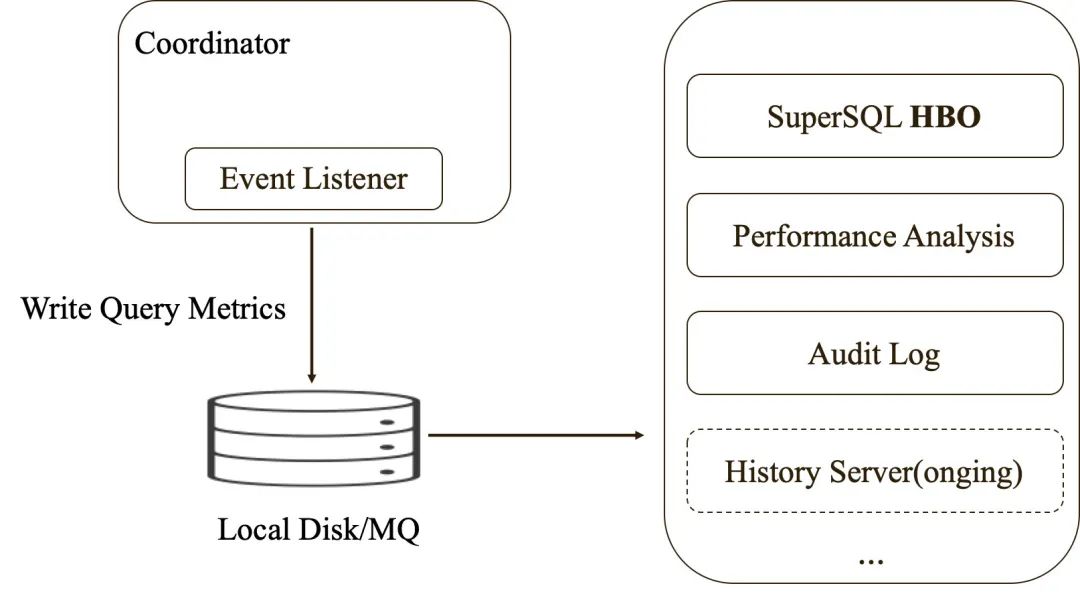
2.2 Query 运行信息持久化
Presto 的 Event Listener 提供了相关的接口,可以在查询执行完成后获取不同纬度的 Metrics 信息,比如查询执行期间各阶段的耗时、处理的数据量、内存/CPU 消耗、Stage/Task/Operator 统计信息等,天穹 Presto 扩展实现了 Event Listener 接口,将这些 Query Metrics 信息持久化到本地磁盘以及消息组件中,用于后续的问题定位、运维审计、资源统计、HBO 等。
2.3 Iceberg Connector 功能增强
腾讯天穹实时数仓-数据湖分析系统 DLA 使用了 Iceberg 作为表的数据组织格式,用户数据入湖后,可以通过 Presto Iceberg Connector 获得秒级的查询体验。天穹 Presto 也对 Iceberg Connector 做了一系列的功能增强,包括 ORC 存储格式支持(PR-16391)、Timestamp With Time Zone 类型支持、Alluxio Local Cache 支持(PR-16942)、并发写入(PR-16983)、Bugfix(PR-16959、PR-16968 )等,大部分的特性或问题修复也已贡献到了 PrestoDB 社区。
3 稳定性提升
3.1 JVM 调优
Presto 在天穹上线运行的过程中,遇到过 Worker Full GC 停顿时间过长的问题,为此天穹 Presto 将 JDK 版本升级到了 11(参考社区 issue 14873),并对 JVM 参数做了持续的调优,比如适当增大-XX:GCLockerRetryAllocationCount 参数的值(默认为 2),以增加 Full GC 的概率尽量避免 OOM 的情况发生。目前在堆内存为 180GB、CPU 96 核的硬件条件下,天穹 Presto Worker Full GC 的平均耗时从数十秒降低到了十秒以内,停顿时间大幅下降。
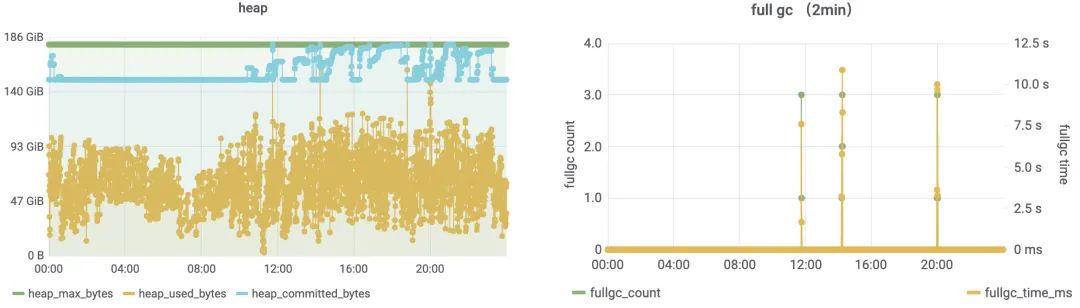
3.2 Full GC Query Killer
Presto 的查询内存使用统计是相对比较粗粒度的,这可能会导致原生的 LowMemoryKillerPolicy 在某些情况下不能正确地 Kill 查询,天穹 Presto 在线上运行的过程中就遇到过类似的情况:Worker 堆内存已经接近用满了,但是 Presto 自身的 Memory Pools 显示还有较多的空闲内存,导致无法及时触发 LowMemoryKillerPolicy。为了尽量避免这种情况,天穹 Presto 开发了 Full GC Query Killer,该策略可以在 Worker Full GC 之后,如果 Worker 堆内存使用还是处于高值,则 Kill 掉在该 Worker 上使用最多内存的查询。需要注意的是,该策略是在应用程序层面执行的,如果 Worker 不断地 Full GC 乃至最后 OOM,那么 Full GC Query Killer 可能也得不到响应,这时候还是需要通过其他手段分析定位出 Full GC 或 OOM 的原因,以彻底解决问题。
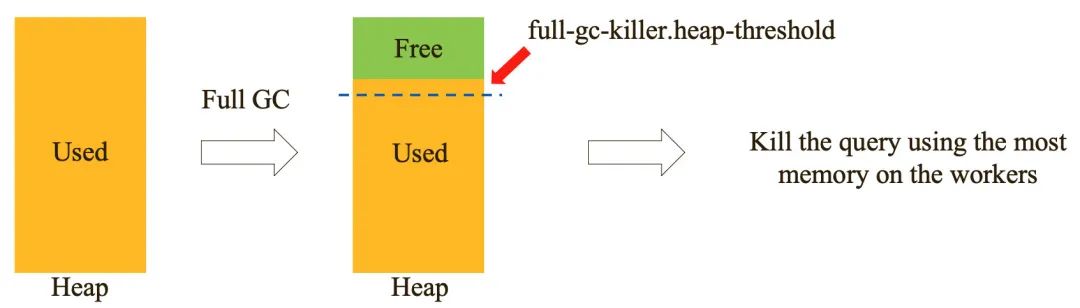
Full GC Query Killer 相关的代码也将在近期贡献至 PrestoDB 社区,欢迎大家关注。
3.3 大文件 ORC 统计信息读取优化
Presto 在读取 ORC 文件时,会先读取文件的 Stripe 统计信息,用于优化 ORC 的数据读取,但是如果 ORC 文件比较大,同时文件数量又比较多的情况下,StripeStatistics 对象会占用较多的 Worker 堆内存,这些内存对象不断累积最终极易造成 OOM。天穹 Presto 采用了以下的方案来尽量避免这个问题:对于来自同一个 ORC 大文件的 Splits,避免重复读取文件的 Stripe 统计信息。
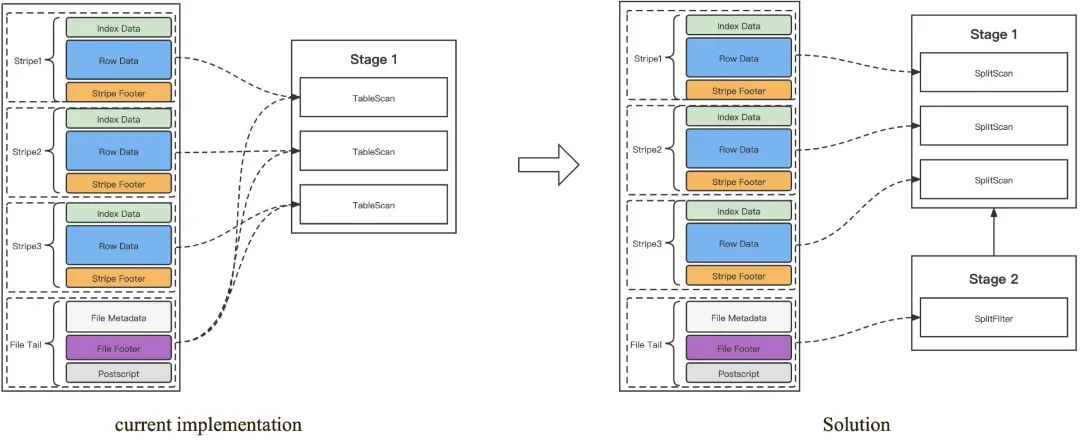
SplitFilerOperator 会先读取一次 ORC 文件的 Stripe 统计信息,生成新的 ORC Splits,新的 Splits 包含了利用 Stripe 统计信息过滤优化后的数据读取地址,后续 ORC Splits 分发至 Worker 中执行时,无需再读取 Stripe 统计信息,直接读取数据即可。
天穹内部环境测试结果显示该方案能减少50%左右的 StripeStatistics 对象内存占用,原先造成 OOM 的 ORC 查询,采用新方案的实现后也可以正常执行完成,目前正在上线生产环境中。
4 性能优化
4.1 Presto on Alluxio
天穹 Presto on Alluxio 主要有两种部署模式:Presto on Alluxio Cluster 以及 Presto Alluxio Local Cache,前者是比较通用的一种部署方式,但是需要额外维护一套 Alluxio 集群,Presto 可以与 Alluxio 集群共部署或者分离部署,共部署的方式能有效提高本地读缓存的命中率,提升查询效率。Presto Alluxio Local Cache 则是更轻量的部署模式,无需单独的 Alluxio 集群,数据缓存在 Presto Worker 侧,运维方便,缺点是 Presto Worker 动态扩缩容的场景下缓存会失效,目前 PrestoDB 和 Alluxio 社区也在持续推进 Local Cache 的方案,相信后续会越来越完善。
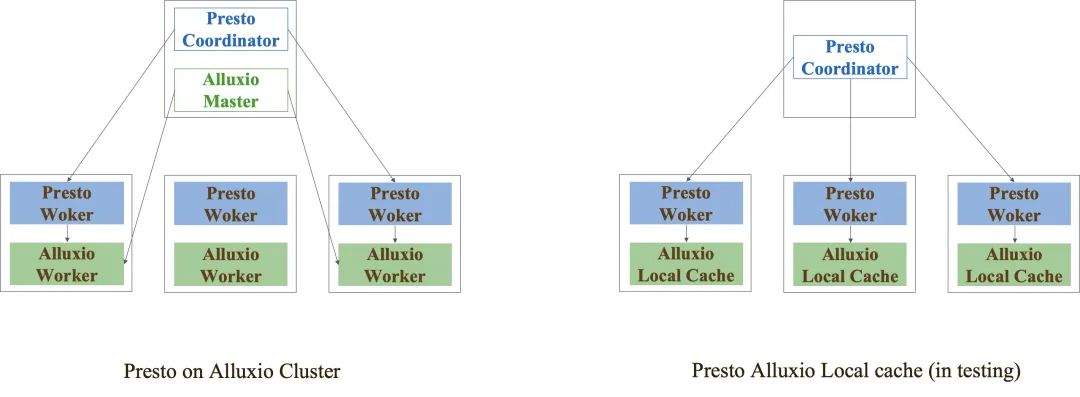
天穹 Presto 根据各业务的场景需求,对 on Alluxio 的方案做了以下增强,提高了易用性和可扩展性:
支持针对不同的 Connector 配置不同的 Alluxio 路由策略,比如 Hive Connector 和 Iceberg Connector;
在 Presto 侧,新增 Alluxio 白名单机制,支持配置访问缓存在不同 Alluxio 集群下的库表数据;
在路由前检测 Alluxio 服务的状态可用性,当 Alluxio 服务不可用时自动 Failover 至 HDFS;
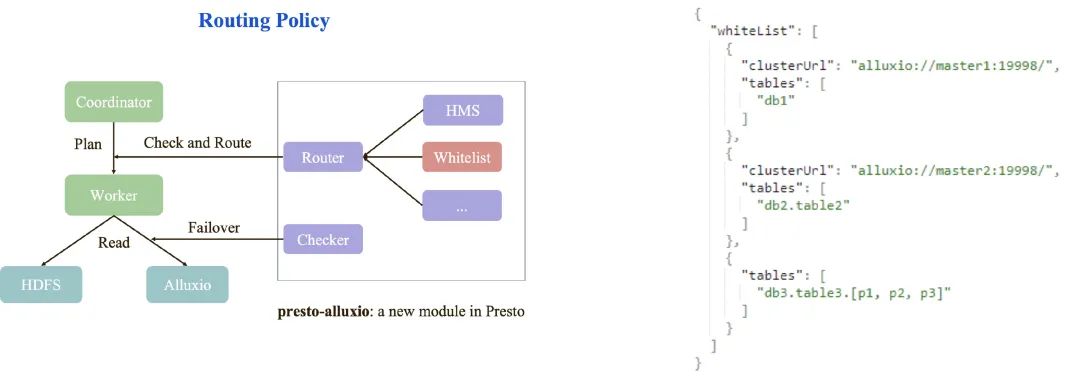
白名单配置参数说明如下:
"clusterUrl":Alluxio 集群的 url 地址,不同的集群可以配置不同的 url。
"tables":Presto 查询中涉及到的库表,如果已经在"tables"配置项中存在,则 Presto 会从对应的 Alluxio 集群中读取该库表的数据(首次从 Alluxio 中读取时,如果未有缓存,则 Alluxio 会将数据缓存下来,后续的读取会直接访问缓存),如果没有在"tables"中配置,则 Presto 会直接访问底层的 HDFS、不经过 Alluxio。"tables"支持库/表/分区级别的配置,支持通配符。
天穹 Presto on Alluxio 方案上线后,部分现网查询业务得到了20%~ 30%的性能提升,数据读取的耗时波动幅度变小、查询性能也更加稳定。
4.2 Presto on K8s
Presto on K8s 是业界通用的一种部署模式,可以参考社区的presto-kubernetes-operator,天穹 Presto 根据自身的业务情况做了相应的适配改造, 整体的部署架构图如下所示:
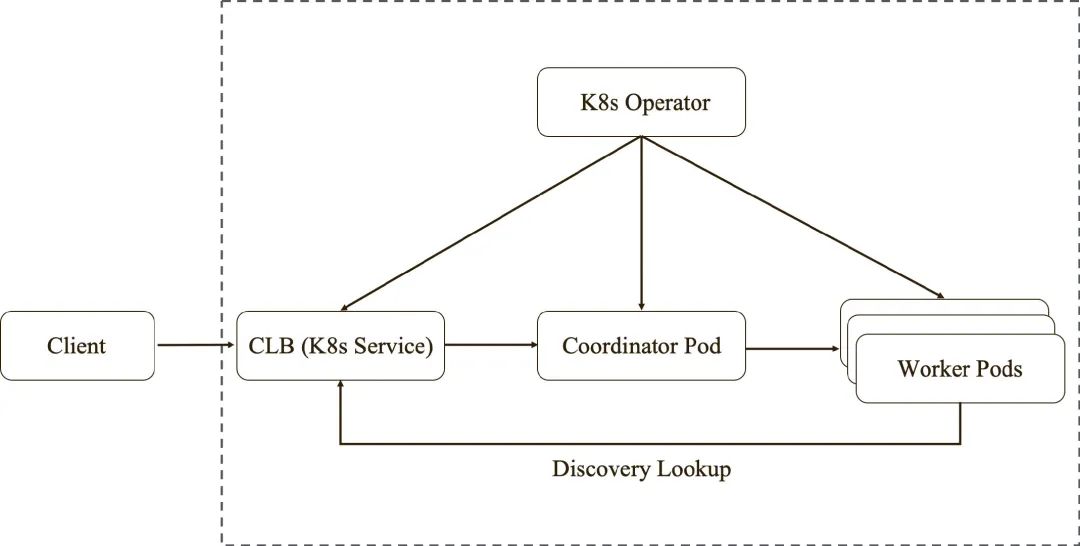
每个 Presto 集群前端会部署一个 CLB 腾讯云负载均衡服务,对外提供统一的访问域名地址。CLB 后端挂载 Coordinator Pod,Worker 通过 CLB 地址向 Coordinator 注册,客户端也通过 CLB 访问 Presto。
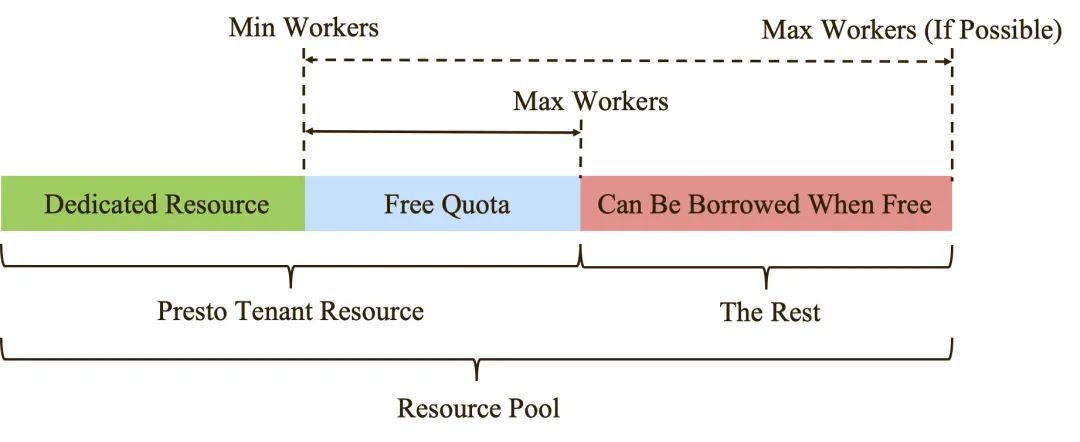
天穹 Presto 集群有单独的租户资源,能保证集群的资源下限(Dedicated Resource),通过 K8s HPA Controller 感知 Presto Worker 的 CPU 和内存资源使用情况,实现 Worker Pod 的动态扩缩容。当白天 Presto 任务量较多需要更多资源时,可以动态扩容 Worker 至租户的资源上限,如果其他业务租户有空闲的资源,也可以继续"借用"。当晚上 Presto 集群空闲时,可以动态缩容 Worker,将资源释放给其他业务租户使用,使资源池的利用率最大化。
4.3 Count Distinct Rewrite
Presto 的 Count Distinct 实现在某些场景下会造成数据倾斜的问题,影响查询的性能,比如在 Left Join 之后再做 Count Distinct,由于 Presto use_mark_distinct 规则的作用,会在 Left Join 之后做一次 Repartitioning,然后在下一个 Stage 做 MarkDistinct,如果 Repartitioning 阶段的 Partition Key 有较多重复值,那么就会造成下一个 Stage 出现数据倾斜的问题,影响 MarkDistinct 算子的执行速度。如果能将 Count Distinct 改写成 Grouping Sets,由于 Group By 会在 Repartitioning 前做预聚合,所以能有效消除上述的数据倾斜问题。社区也有类似的 issue 12024,但是从该 issue 的讨论内容来看,还并未有较完善的解决方案。
目前我们通过天穹 SuperSQL 来实现 Count Distinct 单列/多列到 Grouping Sets 的改写,无需改动 Presto 的代码,经过改写优化后,在某些用户场景下,能获得2 ~ 3 倍的查询性能提升。
4.4 Optimized Repartitioning
天穹 Presto 每天的业务查询 Exchange 的数据量达到了上百 PB 级别,为了提升 Repartitioning 阶段的性能,我们在生产环境中启用了社区的 Optimized Repartitioning 特性:
set session optimized_repartitioning=true; 参考 PR-13183
开启后,PartitionedOutputOperator 算子整体的CPU 消耗减少了 50%,P90 查询耗时降低了 19%,某些用户场景下的查询性能提升接近 2 倍,节省了资源的同时性能也得到了较大的提升。
5 总结 & 未来工作
天穹 SuperSQL的 vision 是通过构建大数据智能融合平台,将异构的计算引擎/异构的存储服务、计算的自动智能优化、流批一体的统一以及自治的系统运维纳入内部,给使用者提供简单统一的逻辑入口和虚拟化的视图方案,使得用户能够从繁杂的技术细节中解脱出来,专注于业务逻辑的实现。未来在 Presto 的工作主要有:语法扩展(临时表/视图的支持等)、运维增强(History Server、高可用)、自适应执行(运行在不同硬件规格的机器上)、内核性能提升、数据源 Connector 扩展增强等,在支撑好腾讯内部各业务需求的同时,也会积极拥抱和回馈开源社区,本篇文章的大部分内容,我们也在 2021 年 12 月举行的 PrestoCon 大会上做了分享PrestoCon-2021,欢迎大家持续关注。
联系我们
如果你对 SuperSQL 感兴趣,欢迎联系我们探讨技术。同时我们长期欢迎志同道合的大数据人才加入,欢迎咨询。联系方式:yikonchen@tencent.com
#有料程序员 直播#
对谈中年鹅厂工程师
工作20年依然保持少年般的热情

点击预约,观看直播
以上是关于腾讯 PB 级大数据计算如何做到秒级?的主要内容,如果未能解决你的问题,请参考以下文章