用Python蹭别人家图片接口,做一个免费图床吧
Posted 梦想橡皮擦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用Python蹭别人家图片接口,做一个免费图床吧相关的知识,希望对你有一定的参考价值。
打开本文,相信你确实需要一个免费且稳定的图床,这篇博客就让你实现。
文章目录
⛳️ 谁家的图床
这次咱们用新浪微博来实现【免费图床应用】,通过代码实现图片上传,然后再进行移花接木,获取图片可读地址。
正式编码前,先做一下准备工作。
- 注册一个微博账号,或者用自己旧的也行;
- 安装 Python 环境;
- 安装 requests 模块。
上述后两步,作为一个合格的 Python 程序员,相信对你来说没有任何难度。
本案例不做自动化微博登录,直接获取 Cookie 信息。
⛳️ 实战编码
首先通过操作微博各个终端界面,找到最简单的图片上传接口和对应参数。
在切换到苹果设备访问时,得到如下界面,发现一个精选图片上传按钮。
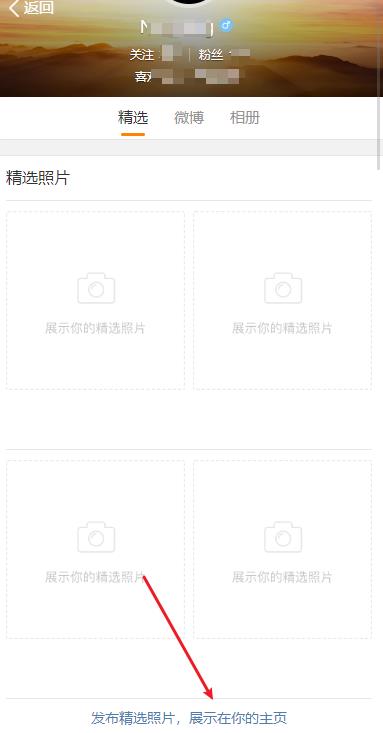
点击按钮之后,任选一张图片,得到如下接口信息。
接口地址:https://m.weibo.cn/api/statuses/uploadPic
参数表如下(关键信息自行获取即可,博客中进行打码操作):
- type: json
- pic: (二进制)
- st: 参数值位置
_spr: screen:390x844
其中 pic 是图片的二进制编码,一会实战的时候,我们可以对参数表进行删项测试,查看哪些为必填参数。
用户上传图片时,还必须携带 cookie 值,这个通过开发者工具获取即可。
⛳️ 第一轮编码
既然知道请求接口和参数了,那直接使用 requests 模块,模拟用户上传操作,查看一下效果。
import requests
def upload_img():
headers =
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (Khtml, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1",
"Cookie": "请自行复制登录之后的 Cookie"
data =
'type': 'json',
'st': 'e940df',
'_spr': 'screen:390x844',
'pic': open('./test_img.png', 'rb')
res = requests.post('https://m.weibo.cn/api/statuses/uploadPic',
data=data, headers=headers)
print(res.text)
if __name__ == '__main__':
upload_img()
本想着一次性就成功,结果得到如下信息。
"ok":0,"errno":"100015","msg":"\\u4e0d\\u5408\\u6cd5\\u7684\\u8bf7\\u6c42"
将 unicode 编码的 msg 参数转码之后,错误提示为 不合法的请求。看来没有想象中那么容易完成。
既然是请求非法,那一定是在请求头中加入了识别标记,查看请求头信息,发现如下参数。
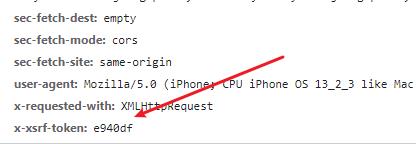
⛳️ 第二轮编码
在请求头中出现了 token 值,非常典型的加密参数,而且这个参数和代码请求中传递的 st 参数一致。那继续修改代码,在请求头中加入该参数。
import requests
def upload_img():
headers =
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1",
"Cookie": "请自行复制登录之后的 Cookie"
st = 'e940df'
headers["x-xsrf-token"] = st
data =
'type': 'json',
'st': st,
'_spr': 'screen:390x844',
'pic': open('./test_img.png', 'rb')
res = requests.post('https://m.weibo.cn/api/statuses/uploadPic',
data=data, headers=headers)
print(res.text)
结果得到的信息依旧是请求非法,那继续在请求头中增加参数。当补齐之后,发现得到的错误信息变了,具体如下所示。
headers =
"accept": "application/json, text/plain, */*",
"origin": "https://m.weibo.cn",
"referer": "https://m.weibo.cn/",
"mweibo-pwa": "1",
"x-requested-with": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1",
"Cookie": "请自行复制登录之后的 Cookie"
新的错误信息依旧是请求非法。
"ok":0,"errno":"100006","msg":"\\u8bf7\\u6c42\\u975e\\u6cd5"
⛳️ 第三轮编码
那既然增加 x-xsrf-token 还是无法得到数据,那只能多次测试上传,查看该参数变化。
再次测试之后,发现该值会动态获取,调用的接口信息如下所示。
请求地址:https://m.weibo.cn/api/config
无请求参数,微博默认是间隔一段时间自动修改该值,这里我们修改为手动触发,新版代码如下所示。
import requests
def upload_img():
headers =
"accept": "application/json, text/plain, */*",
"origin": "https://m.weibo.cn",
"referer": "https://m.weibo.cn/",
"mweibo-pwa": "1",
"x-requested-with": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1",
"Cookie": "请自行复制登录之后的 Cookie"
res = requests.get('https://m.weibo.cn/api/config', headers=headers)
st = res.json()['data']['st']
print(st)
headers["x-xsrf-token"] = st
data =
'type': 'json',
'st': st,
'_spr': 'screen:390x844'
data =
'type': 'json',
'st': st,
'_spr': 'screen:390x844',
'pic': open('./test_img.png', 'rb')
res = requests.post('https://m.weibo.cn/api/statuses/uploadPic',
data=data, headers=headers)
print(res.text)
if __name__ == '__main__':
upload_img()
结果没有错误码了,又出现新的提示信息了。
"ok":0,"msg":"\\u4e0a\\u4f20\\u5931\\u8d25\\uff0c\\u8bf7\\u7a0d\\u540e\\u91cd\\u8bd5"
转义之后,最新的提示是上传失败,请稍后重试,看来已经接近成功了,下面的代码实现是多年爬虫编码经验实现的。
既然接口提示的仅仅是上传失败,那再次回到开发者工具中查看,通过载荷卡片,可以看到是上传的表单数据,那我们使用 data 参数是完全没有问题的,但是切换到源代码视图就会发现问题。下面是两张对比图。
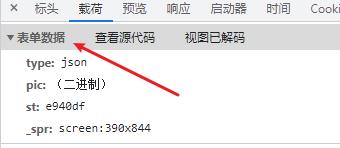

⛳️ 第四轮编码
在源代码视图中发现微博的该接口是使用的 multipart/from-data 类型数据,在 Python 中有两种方式来实现,分别如下。
- 手动创建
form-data并通过 headers 传递; - 通过
files参数传递。
那咱们采用第二种实现,在 requests 的官方手册中也是推荐该方式,使用 requests 模拟一个表单的数据格式,语法如下。
files = name: (<filename>, <file object>,<content type>, <per-part headers>)
该行代码模拟出来的 POST 数据格式恰好和刚才的图片格式一致。
Content-Disposition: form-data; name=name;filename=<filename>
Content-Type: <content type>
<file object>
--boundary
其中各参数留空,使用 None 进行占位。
所以本案例中请求参数修改为如下格式。
file =
'pic': ('test_img.png', open('./test_img.png', 'rb'), 'image/png'),
'type': (None, 'json'),
'st': (None, st),
'_spr': (None, 'screen:390x844')
同时在 requests 模块调用 POST 方法的时候,使用 files 参数,完整代码如下所示。
import requests
def upload_img():
headers =
"accept": "application/json, text/plain, */*",
"origin": "https://m.weibo.cn",
"referer": "https://m.weibo.cn/",
"mweibo-pwa": "1",
"x-requested-with": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1",
"Cookie": "请自行复制登录之后的 Cookie"
res = requests.get('https://m.weibo.cn/api/config', headers=headers)
st = res.json()['data']['st']
print(st)
headers["x-xsrf-token"] = st
data =
'type': 'json',
'st': st,
'_spr': 'screen:390x844'
# data =
# 'type': 'json',
# 'st': st,
# '_spr': 'screen:390x844',
# 'pic': open('./test_img.png', 'rb')
#
file =
'pic': ('test_img.png', open('./test_img.png', 'rb'), 'image/png'),
'type': (None, 'json'),
'st': (None, st),
'_spr': (None, 'screen:390x844')
res = requests.post('https://m.weibo.cn/api/statuses/uploadPic',
files=file, headers=headers)
print(res.text)
if __name__ == '__main__':
upload_img()
运行代码,得到最终结果,响应数据如下所示。
"pic_id":"xxxxxx","thumbnail_pic":"xxxxxxx","bmiddle_pic":"xxxxxxx","original_pic":"xxxxxx"
但是这个图床案例还没有完结,你得到的图片地址,如果直接使用浏览器访问,会被禁止(403 Forbidden),即限制了外链调用。
使用下述代码进行修复,即可外联访问。
pic_id = res.json()["pic_id"]
# 拼接图片地址
img = 'http://ww1.sinaimg.cn/large/pid.jpg'.format(pid=pic_id)
print(img)
不要问我,为什么 ww1 就可以访问到图片,这是前贤们探究出来的。
📢📢📢📢📢📢
💗 你正在阅读 【梦想橡皮擦】 的博客
👍 阅读完毕,可以点点小手赞一下
🌻 发现错误,直接评论区中指正吧
📆 橡皮擦的第 621 篇原创博客
从订购之日起,案例 5 年内保证更新
以上是关于用Python蹭别人家图片接口,做一个免费图床吧的主要内容,如果未能解决你的问题,请参考以下文章