基于Hadoop的好友推荐系统项目综述
Posted 想作会飞的鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于Hadoop的好友推荐系统项目综述相关的知识,希望对你有一定的参考价值。
一、好友推荐系统项目概述
1、项目介绍
该系统利用基于密度的新型聚类算法,对给定用户基于好友推荐。本系统的开发IDE采用eclipse,使用maven构建项目,数据库选用mysql,后台技术采用Struts2+Hibernate+Spring的架构,前端使用Easyui+Ajax的技术实现前后端的数据交互,算法的主要计算任务用Hadoop Mapreduce来完成。综合来说,本系统面临的主要挑战如下:
- 如何用MapReduce来实现聚类算法;
- 如何使用JavaWeb技术实现Hadoop任务的远程提交;
- 如何实现Hadoop任务的实时监控
2、项目采用的用户数据源
本此项目的用户数据源样例如下:
<row Id="-1" Reputation="9" CreationDate="2010-07-28T16:38:27.683" DisplayName="Community" EmailHash="a007be5a61f6aa8f3e85ae2fc18dd66e" LastAccessDate="2010-07-28T16:38:27.683" Location="on the server farm" AboutMe="<p>Hi, I'm not really a person.</p>
<p>I'm a background process that helps keep this site clean!</p>
<p>I do things like</p>
<ul>
<li>Randomly poke old unanswered questions every hour so they get some attention</li>
<li>Own community questions and answers so nobody gets unnecessary reputation from them</li>
<li>Own downvotes on spam/evil posts that get permanently deleted
</ul>" Views="0" UpVotes="142" DownVotes="119" />
<row Id="2" Reputation="101" CreationDate="2010-07-28T17:09:21.300" DisplayName="Geoff Dalgas" EmailHash="b437f461b3fd27387c5d8ab47a293d35" LastAccessDate="2011-09-01T23:16:56.353" WebsiteUrl="http://stackoverflow.com" Location="Corvallis, OR" Age="34" AboutMe="<p>Developer on the StackOverflow team. Find me on</p>

<p><a href="http://www.twitter.com/SuperDalgas" rel="nofollow">Twitter</a>
<br><br>
<a href="http://blog.stackoverflow.com/2009/05/welcome-stack-overflow-valued-associate-00003/" rel="nofollow">Stack Overflow Valued Associate #00003</a> </p>
" Views="25" UpVotes="7" DownVotes="0" />
该数据源是http://stackoverflow.com/ 网站上的用户数据。该网站我就不做介绍了,程序员收藏夹必备网站之一。该网站的网页截图如下:
本次好友推荐系统建立在如下假设上:
- 用户对于一个领域问题的“偏好程度”就可以反映出该用户的价值取向,并依据此价值取向来对用户进行聚类分组。
- 这里的”偏好程度“可以使用指定的几个指标属性来评判
- 原始用户数据包含的属性有多个,从中挑选出最能符合用户观点的属性,作为该用户的“偏好程度”进行分析。
针对以上假设,对原始用户数据进行分析,挑选的代表属性如下:
- ID 用户聚类时的代表标志
- EmailHash 用户去重时的依据
- reputation 声望或者名声度
- upVotes 获得的支持数(被点赞数)
- downVotes 获得的反对数(被点踩数)
- views 浏览的次数
其中我们实现用户聚类基于如下四个属性:reputation,upVotes,downVotes,views。
二、项目的启动和初始化
1、准备
- 下载工程,项目采用Maven构建项目相关jar包,所以直接通过导入已有maven项目选项即可。该项目的所有源码已经上传至Github,链接如下:点我;
- Mysql数据库的配置,在mysql数据库中新建一个friend数据库,同时根据本地Mysql的环境更改本项目中Mysql的外部文件;
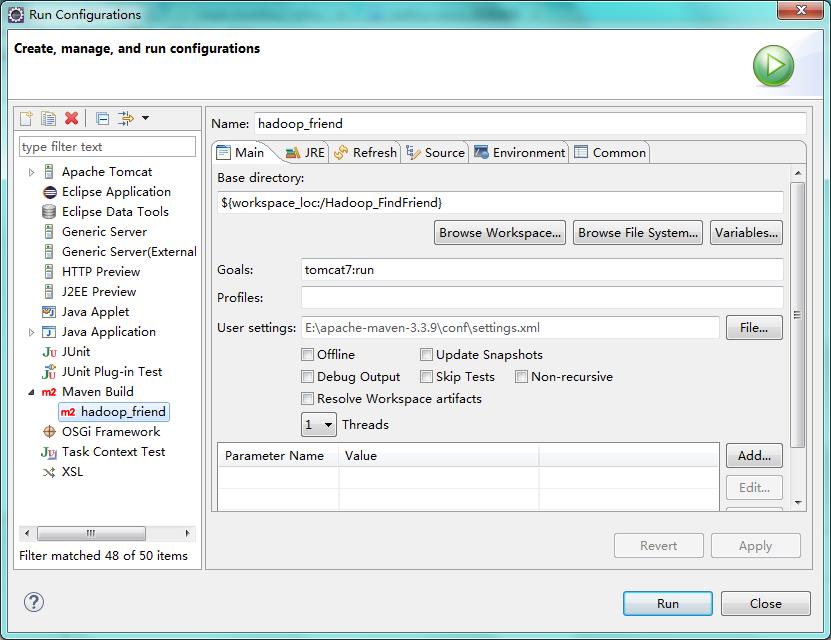
- 该项目通过tomcat-maven插件完成Web项目的运行,通过设置maven build选项即可运行项目,如下:点击Browse workspace选中该项目,在Goals中填写tomcat7:run,点击运行即可。
- 直接运行部署工程,即可在数据库中自动建立相应的表(Hibernate中的配置文件启动自动建表设置),包括:hconstants、loginuser、userdata、usergroup,其中loginuser是用户登录表,会自动初始化(默认有两个用户admin/admin、test/test),hconstants是云平台参数数据表、userdata存储原始用户数据、usergroup存储聚类分群后每个用户的组别。
- 搭建Hadoop2.x集群(伪分布式或者完全分布式都可以,本项目测试使用完全分布式),同时需要注意:设置云平台系统linux的时间和运行tomcat的机器的时间一样,因为在云平台任务监控的时候使用了时间作为监控停止的信号。
- 根据集群配置的实际情况,修改项目中关于hadoop集群配置参数的相关源码(在Util包中)。这一步非常重要,否则会导致hadoop任务提交失败。这里贴出我的Hadoop集群配置:
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://sparkproject1:9000</value>
</property>
</configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/data/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/data/datanode</value>
</property>
<property>
<name>dfs.tmp.dir</name>
<value>/usr/local/data/tmp</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>sparkproject1:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>sparkproject1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>sparkproject1:19888</value>
</property>
</configuration>
yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>sparkproject1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>sparkproject1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>sparkproject1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>sparkproject1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>sparkproject1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>sparkproject1:8088</value>
</property>
</configuration>
- 使用Eclipse的export功能把所有源码打包,然后把打包后的jar文件拷贝到hadoop集群的$HADOOP_HOME/share/hadoop/mapreduce/lib目录下面。这一步相当重要,否则项目将无法找到相关类。注意,如果搭建的是全分布集群,那么需要把这个jar包拷贝到每一个集群节点的该目录下,否则会运行时会报错,提示找不到相关类的定义。
2、启动项目
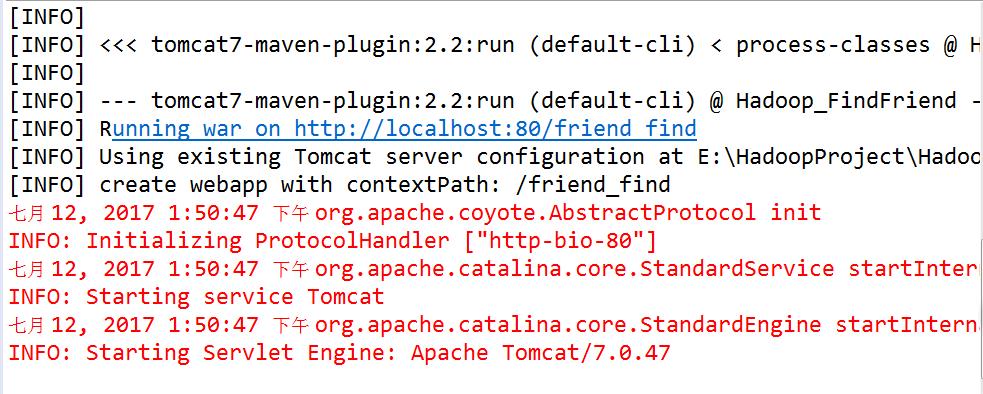
- 通过tomcat-maven插件启动项目,如下:
- 访问后台系统首页
首页链接是http://localhost/friend_find,因为在pom.xml设置了tomcat的启动端口是80,
<!-- 配置Tomcat插件 -->
<plugin>
<groupId>org.apache.tomcat.maven</groupId>
<artifactId>tomcat7-maven-plugin</artifactId>
<configuration>
<port>80</port>
<path>/friend_find</path>
</configuration>
</plugin>所以这里可以省略端口号。界面如下:

点击登录即可。
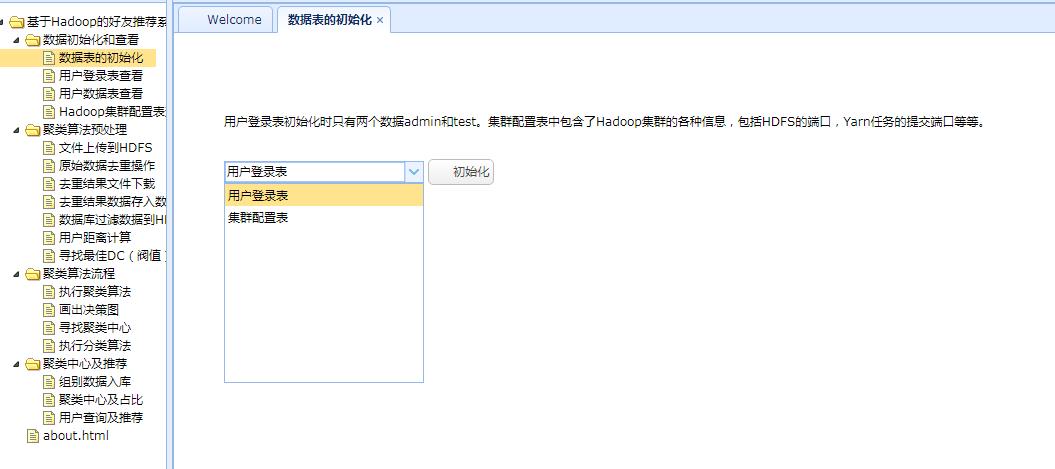
3、初始化相应的表
点击左侧”数据表的初始化“选项卡,选择对应的表,点击初始化按钮,可完成初始化。
4、查看初始化结果
点击左侧相应选项卡即可。
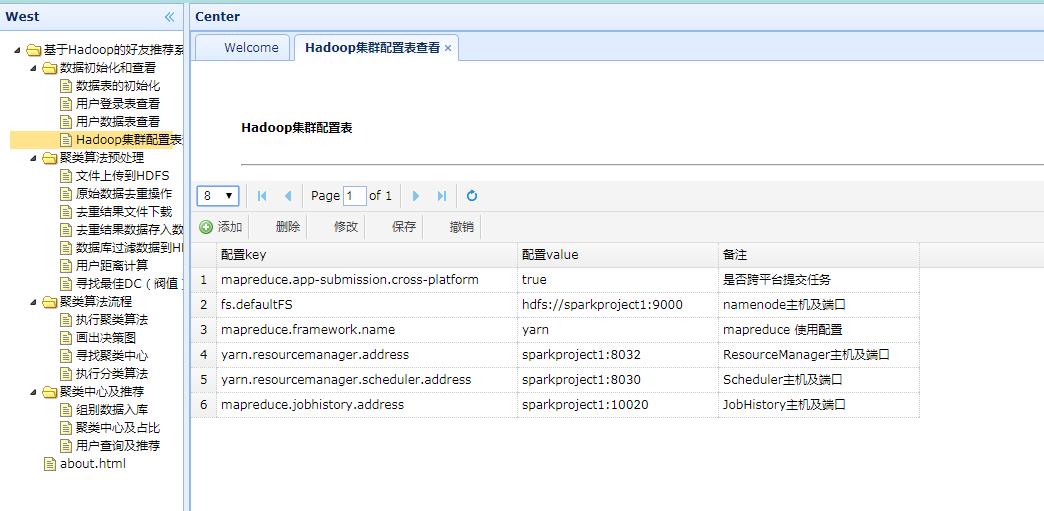
如果需要修改初始化信息,点击某一行数据,在toolbar里即可选择修改或保存等即可。
三、项目实现流程
项目实现的流程按照系统首页左边导航栏的顺序从上到下运行,完成聚类算法的各个步骤。
1、聚类算法的预处理
查看原始数据ask_ubuntu_users.xml 文件,原始数据一共有19550条记录,去除第1、2、最后一行外其他都是用户数据(第3行不是用户数据,是该网站的描述);
用户数据需要使用一个主键来唯一标示该用户,这里不是选择Id,而是使用EmailHash。假设每个EmailHash相同的账号其是同一个人,使用上面的假设后,对原始数据进行分析,发现EmailHash是有重复记录的,所以这里需要对数据进行预处理-数据去重。
- 本地文件上传到HDFS
这里我们需要把原始数据上传至HDFS方便后续MapReduce的任务运行; - 原始数据去重操作
因为原始数据可能存在一个用户注册多个账号的情况。我们假设每个EmailHash相同的账号其是同一个人,基于此我们进行去重操作。 - 去重结果文件下载
需要把数据去重的结果数据拿到本地,以便后面的数据入库操作。 - 去重结果数据存入数据库
这里没有使用xml的解析,而是直接使用字符串的解析。因为在云平台在去重操作的时候,是去掉了原XML文件的第1,2和最后一行,所以xml文件是不完整的,不能使用xml解析。所以这里直接读取文件,然后进行字符串的解析。 - 数据库过滤数据到HDFS
过滤规则 :reputation>15,upVotes>0,downVotes>0,views>0 - 用户距离计算
这里计算的是两个向量的欧式距离 - 寻找最佳DC(阀值)
根据新型聚类算法的原理需要计算最佳DC值。
2、聚类算法流程
根据新型聚类算法的基本原理,可以分为如下步骤:
1. 计算用户向量两两之间的距离;
2. 根据距离求解每个用户向量的局部密度;
3. 根据步骤1和步骤2的结果求解每个用户向量的最小距离;
4. 根据步骤2,3的结果画出决策图,并判断聚类中心的局部密度和最小距离的阈值;
5. 根据局部密度和最小距离阈值来寻找聚类中心向量;
6. 根据聚类中心向量来进行分类;
3、聚类中心及推荐
执行分类算法后的结果即可以得到聚类中心向量以及每个分群的百分比,同时根据分类的结果来对用户进行组内推荐。
四、详细开发流程
1、Hadoop好友推荐系统-项目架构搭建和用户登陆的实现
2、Hadoop好友推荐系统-数据表的初始化
3、Hadoop好友推荐系统-HDFS的文件上传和下载
4、Hadoop好友推荐系统-原始数据去重操作(包含MapReduce任务监控)
5、Hadoop好友推荐系统-去重后的数据存入数据库
6、Hadoop好友推荐系统-数据库过滤数据到HDFS
7、Hadoop好友推荐系统-用户距离计算
8、Hadoop好友推荐系统-寻找最佳DC
9、Hadoop好友推荐系统-执行聚类算法
10、Hadoop好友推荐系统-画出决策图
11、Hadoop好友推荐系统-寻找聚类中心
12、Hadoop好友推荐系统-执行分类算法
13、Hadoop好友推荐系统-组别数据入库
14、Hadoop好友推荐系统-聚类中心及占比查看
15、Hadoop好友推荐系统-推荐结果查询
五、总结
该项目基本完成了文章开头提出的三个挑战:算法的Mapreduce实现、MapReduce任务的远程提交、MapReduce任务的实时监控。但是在开发实践过程中仍然暴露出一些问题:
1、通过基于密度的新型聚类算法计算得到的最佳DC进行聚类,并不能得到理想的聚类效果。这个问题目前有待研究,事实上在该算法的原文章中作者也只是给出一个参考方法:选取一个Dc,使得每个数据点的平均邻居个数约为数据点总数的1%-2%。从某种程度上来讲,Dc的选取决定着这个聚类算法的成败,取得太大和太小都不行。如果Dc去的太大,将使得每个数据点的局部密度值都很大,导致区分度不高。极端情况是Dc的值大于所有点的最大距离值,这样算法的最终结果就是所有点都属于同一个聚类中心。如果Dc取值太小,那么同一个分组有可能被拆分为多个。极端情况是Dc比所有点的距离值都要小,这样将导致每一个点都是一个聚类中心。
2、在最后的根据分组推荐朋友阶段,并没有考虑分组内部的成员与当前用户的相关程度,仅仅是把该用户所在分组的所有成员列举出来。事实上应该按照与当前用户的相关程度进行排序,这里并未实现这个功能。
3、因为本人测试环境的限制(一台电脑上运行三个虚拟机),原数据量的大小远远不能发挥Hadoop大数据处理的特色。事实上,我的个人理解是,当我们的数据量非常非常大的时候并不是说一定要使用Hadoop来进行处理或者说Hadoop处理比单机处理要有多么好,而是此时单机系统因为磁盘和内存的限制已经无法处理这么大的文件了。如果是超级计算机,那么它的处理效率应该比Hadoop集群要快很多。这样来看,Hadoop集群相当于廉价的超级计算机。还是那句话,如果没有足够大的数据量,使用Hadoop完全就是“自讨苦吃”,它的资源消耗远比单机处理大的多。
4、本项目采用完全手动编程实现聚类算法,事实上,Hadoop生态系统早就提供了数据挖掘的相关框架:Mahout。Mahout提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。此外,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到云中。未来或可考虑将Mahout扩展到该项目中。
六、源码
本项目完整源码以上传至github,链接在这里。点我
七、相关推荐
1、关于Hadoop的使用:走向云计算系列文章总索引
2、关于本项目采用的推荐算法:基于密度的聚类算法(Clustering by fast search and find of density peaksd)
3、关于SSH框架:SSH框架学习
以上是关于基于Hadoop的好友推荐系统项目综述的主要内容,如果未能解决你的问题,请参考以下文章