最大回撤原理与计算-python实现
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最大回撤原理与计算-python实现相关的知识,希望对你有一定的参考价值。
参考技术A 最大回撤是指:在任一时间点向后推,产品净值到达最低点时,收益率回撤幅度的最大值。这一指标描述了投资者买入某资产可能出现的最为糟糕的情况。即,最大回撤是在每一个时间点上向后求其跌幅,然后找出最大的。从公式的第二个等式,我们首先给出最大回撤的一个直观算法
一、首先给出计算最大回撤的一个算法(先找出累计收益率的波峰点,在向后寻找最大的跌幅,即为最大回撤)
二、接着,使用np.maximum.accumulate函数计算最大回撤
接着计算沪深300指数的最大回撤
最大回撤结果为:72.30%。最大回撤开始日期为:
Timestamp('2007-10-16 00:00:00')
最大回撤结束日期为:
Timestamp('2008-11-04 00:00:00')
可以看出,直接投资指数会有较大的回撤。需要进一步地控制风险
数据标准化 (data normalization) 的原理及实现 (Python sklearn)
原理
数据正规化(data normalization)是将数据的每个样本(向量)变换为单位范数的向量,各样本之间是相互独立的.其实际上,是对向量中的每个分量值除以正规化因子.常用的正规化因子有 L1, L2 和 Max.假设,对长度为 n 的向量,其正规化因子 z 的计算公式,如下所示:

注意:Max 与无穷范数 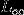 不同,无穷范数 是需要先对向量的所有分量取绝对值,然后取其中的最大值;而 Max 是向量中的最大分量值,不需要取绝对值的操作.
不同,无穷范数 是需要先对向量的所有分量取绝对值,然后取其中的最大值;而 Max 是向量中的最大分量值,不需要取绝对值的操作.
补充:一阶范数也称为曼哈顿距离(Manhanttan distance)或街区距离;二阶范数也称为欧式距离(Euclidean distance).
实现
在 Python 库 sklearn 中,有两种实现方式进行数据的正规化,这两种实现都可通过参数 norm 选择正规化因子,可选项有 \'l1\', \'l2\' 和 \'max\'.
方法一:采用 sklearn.preprocessing.Normalizer 类,其示例代码如下:
#!/usr/bin/env python
# -*- coding: utf8 -*-
# author: klchang
# Use sklearn.preprocessing.Normalizer class to normalize data.
from __future__ import print_function
import numpy as np
from sklearn.preprocessing import Normalizer
x = np.array([1, 2, 3, 4], dtype=\'float32\').reshape(1,-1)
print("Before normalization: ", x)
options = [\'l1\', \'l2\', \'max\']
for opt in options:
norm_x = Normalizer(norm=opt).fit_transform(x)
print("After %s normalization: " % opt.capitalize(), norm_x)
方法二:采用 sklearn.preprocessing.normalize 函数,其示例代码如下:
#!/usr/bin/env python
# -*- coding: utf8 -*-
# author: klchang
# Use sklearn.preprocessing.normalize function to normalize data.
from __future__ import print_function
import numpy as np
from sklearn.preprocessing import normalize
x = np.array([1, 2, 3, 4], dtype=\'float32\').reshape(1,-1)
print("Before normalization: ", x)
options = [\'l1\', \'l2\', \'max\']
for opt in options:
norm_x = normalize(x, norm=opt)
print("After %s normalization: " % opt.capitalize(), norm_x)
参考资料
1. Scikit-learn Normalization mode (L1 vs L2 & Max). https://stats.stackexchange.com/questions/225564/scikit-learn-normalization-mode-l1-vs-l2-max
2. sklearn.preprocessing.Normalizer - scikit-learn Documentation. http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.Normalizer.html
3. sklearn.preprocessing.normalize - scikit-learn Documentation. http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.normalize.html
4. scikit-learn Documentation - 4.3. Preprocessing data. http://scikit-learn.org/stable/modules/preprocessing.html
5. Norm (mathematics). https://en.wikipedia.org/w/index.php?title=Norm_(mathematics)&oldid=838245314
以上是关于最大回撤原理与计算-python实现的主要内容,如果未能解决你的问题,请参考以下文章