在大数据量时,K-means算法和层次聚类算法谁更有优势
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在大数据量时,K-means算法和层次聚类算法谁更有优势相关的知识,希望对你有一定的参考价值。
这个问题其实是无解的,数据不同,算法的分类效果、实际运行时间也是不同。若单从运算速度而言,k-means比层次更快。
原因是K-means是找中心,然后计算距离;层次是逐个样本逐层合并,层次的算法复杂度更高。
更重要的是,在大数量下,K-means算法和层次聚类算法的分类效果真的只能用见仁见智来形容了。 参考技术A 您好,请问您是想知道在大数据量时,K-means算法和层次聚类算法谁更有优势吗?
聚类算法K-均值聚类(K-Means)算法
走过路过不要错过
在数据挖掘中,聚类是一个很重要的概念。传统的聚类分析计算方法主要有如下几种:划分方法、层次方法、基于密度的方法、基于网格的方法、基于模型的方法等。其中K-Means算法是划分方法中的一个经典的算法。
一、K-均值聚类(K-Means)概述
1、聚类:
“类”指的是具有相似性的集合,聚类是指将数据集划分为若干类,使得各个类之内的数据最为相似,而各个类之间的数据相似度差别尽可能的大。聚类分析就是以相似性为基础,在一个聚类中的模式之间比不在同一个聚类中的模式之间具有更多的相似性。对数据集进行聚类划分,属于无监督学习。
2、K-Means:
K-Means算法是一种简单的迭代型聚类算法,采用距离作为相似性指标,从而发现给定数据集中的K个类,且每个类的中心是根据类中所有数值的均值得到的,每个类的中心用聚类中心来描述。对于给定的一个(包含n个一维以及一维以上的数据点的)数据集X以及要得到的类别数量K,选取欧式距离作为相似度指标,聚类目标实施的个类的聚类平反和最小,即最小化:
结合最小二乘法和拉格朗日原理,聚类中心为对应类别中各数据点的平均值,同时为了使算法收敛,在迭代的过程中,应使得最终的聚类中心尽可能的不变。
3、K-Means算法流程:
随机选取K个样本作为聚类中心;
计算各样本与各个聚类中心的距离;
将各样本回归于与之距离最近的聚类中心;
求各个类的样本的均值,作为新的聚类中心;
判定:若类中心不再发生变动或者达到迭代次数,算法结束,否则回到第二步。
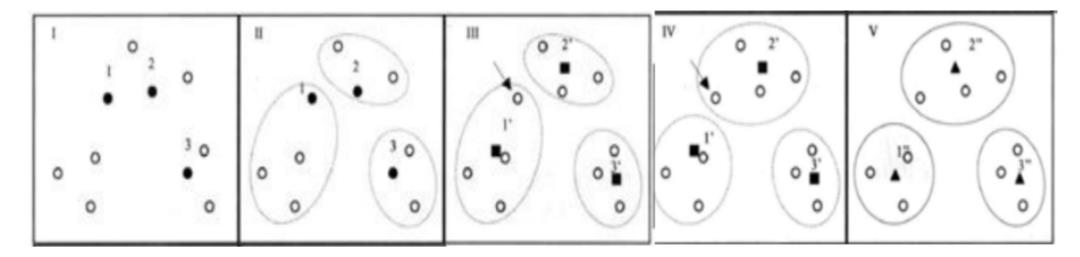
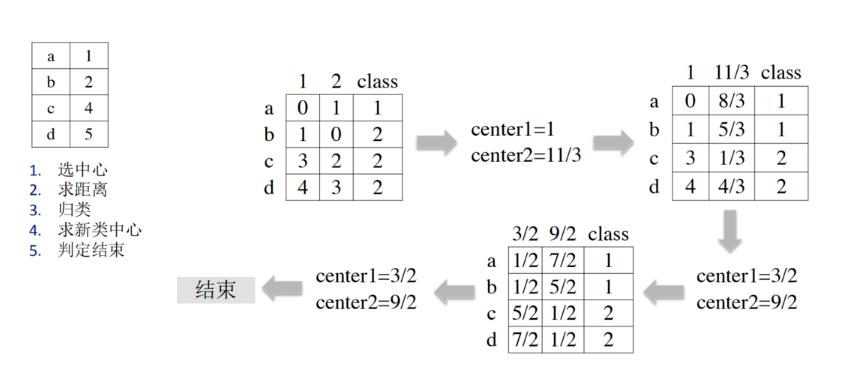
4、K-Means演示举例
将a~d四个点聚为两类:
选定样本a和b为初始聚类中心,中心值分别为1、2
2.将平面上的100个点进行聚类,要求聚为两类,其横坐标都为0~99。
Python代码演示:
import numpy as np"""任务要求:对平面上的 100 个点进行聚类,要求聚类为两类,其横坐标都为 0 到 99。"""x = np.linspace(0, 99, 100)y = np.linspace(0, 99, 100)k = 2n = len(x)dis = np.zeros([n, k+1])# 1.选择初始聚类中心center1 = np.array([x[0], y[0]])center2 = np.array([x[1], y[1]])iter_ = 100while iter_ > 0:# 2.求各个点到两个聚类中心距离for i in range(n):dis[i, 0] = np.sqrt((x[i] - center1[0])**2 + (y[i] - center1[1])**2)dis[i, 1] = np.sqrt((x[i] - center2[0])**2 + (y[i] - center2[1])**2)# 3.归类dis[i, 2] = np.argmin(dis[i,:2]) # 将值较小的下标值赋值给dis[i, 2]# 4.求新的聚类中心index1 = dis[:, 2] == 0index2 = dis[:, 2] == 1center1_new = np.array([x[index1].mean(), y[index1].mean()])center2_new = np.array([x[index2].mean(), y[index2].mean()])# 5.判定聚类中心是否发生变换if all((center1 == center1_new) & (center2 == center2_new)):# 如果没发生变换则退出循环,表示已得到最终的聚类中心breakcenter1 = center1_newcenter2 = center2_new# 6.输出结果以验证print(dis)
结果如下:
其中第 3 项代表聚类:
[[ 34.64823228 105.3589104 0. ][ 33.23401872 103.94469683 0. ][ 31.81980515 102.53048327 0. ][ 30.40559159 101.11626971 0. ][ 28.99137803 99.70205615 0. ][ 27.57716447 98.28784258 0. ][ 26.1629509 96.87362902 0. ][ 24.74873734 95.45941546 0. ][ 23.33452378 94.0452019 0. ][ 21.92031022 92.63098834 0. ][ 20.50609665 91.21677477 0. ][ 19.09188309 89.80256121 0. ][ 17.67766953 88.38834765 0. ][ 16.26345597 86.97413409 0. ][ 14.8492424 85.55992052 0. ][ 13.43502884 84.14570696 0. ][ 12.02081528 82.7314934 0. ][ 10.60660172 81.31727984 0. ][ 9.19238816 79.90306627 0. ][ 7.77817459 78.48885271 0. ][ 6.36396103 77.07463915 0. ][ 4.94974747 75.66042559 0. ][ 3.53553391 74.24621202 0. ][ 2.12132034 72.83199846 0. ][ 0.70710678 71.4177849 0. ][ 0.70710678 70.00357134 0. ][ 2.12132034 68.58935778 0. ][ 3.53553391 67.17514421 0. ][ 4.94974747 65.76093065 0. ][ 6.36396103 64.34671709 0. ][ 7.77817459 62.93250353 0. ][ 9.19238816 61.51828996 0. ][ 10.60660172 60.1040764 0. ][ 12.02081528 58.68986284 0. ][ 13.43502884 57.27564928 0. ][ 14.8492424 55.86143571 0. ][ 16.26345597 54.44722215 0. ][ 17.67766953 53.03300859 0. ][ 19.09188309 51.61879503 0. ][ 20.50609665 50.20458146 0. ][ 21.92031022 48.7903679 0. ][ 23.33452378 47.37615434 0. ][ 24.74873734 45.96194078 0. ][ 26.1629509 44.54772721 0. ][ 27.57716447 43.13351365 0. ][ 28.99137803 41.71930009 0. ][ 30.40559159 40.30508653 0. ][ 31.81980515 38.89087297 0. ][ 33.23401872 37.4766594 0. ][ 34.64823228 36.06244584 0. ][ 36.06244584 34.64823228 1. ][ 37.4766594 33.23401872 1. ][ 38.89087297 31.81980515 1. ][ 40.30508653 30.40559159 1. ][ 41.71930009 28.99137803 1. ][ 43.13351365 27.57716447 1. ][ 44.54772721 26.1629509 1. ][ 45.96194078 24.74873734 1. ][ 47.37615434 23.33452378 1. ][ 48.7903679 21.92031022 1. ][ 50.20458146 20.50609665 1. ][ 51.61879503 19.09188309 1. ][ 53.03300859 17.67766953 1. ][ 54.44722215 16.26345597 1. ][ 55.86143571 14.8492424 1. ][ 57.27564928 13.43502884 1. ][ 58.68986284 12.02081528 1. ][ 60.1040764 10.60660172 1. ][ 61.51828996 9.19238816 1. ][ 62.93250353 7.77817459 1. ][ 64.34671709 6.36396103 1. ][ 65.76093065 4.94974747 1. ][ 67.17514421 3.53553391 1. ][ 68.58935778 2.12132034 1. ][ 70.00357134 0.70710678 1. ][ 71.4177849 0.70710678 1. ][ 72.83199846 2.12132034 1. ][ 74.24621202 3.53553391 1. ][ 75.66042559 4.94974747 1. ][ 77.07463915 6.36396103 1. ][ 78.48885271 7.77817459 1. ][ 79.90306627 9.19238816 1. ][ 81.31727984 10.60660172 1. ][ 82.7314934 12.02081528 1. ][ 84.14570696 13.43502884 1. ][ 85.55992052 14.8492424 1. ][ 86.97413409 16.26345597 1. ][ 88.38834765 17.67766953 1. ][ 89.80256121 19.09188309 1. ][ 91.21677477 20.50609665 1. ][ 92.63098834 21.92031022 1. ][ 94.0452019 23.33452378 1. ][ 95.45941546 24.74873734 1. ][ 96.87362902 26.1629509 1. ][ 98.28784258 27.57716447 1. ][ 99.70205615 28.99137803 1. ][101.11626971 30.40559159 1. ][102.53048327 31.81980515 1. ][103.94469683 33.23401872 1. ][105.3589104 34.64823228 1. ]]Process finished with exit code 0
以上代码结果中每个值的第一项和第二项分别代表到第一个聚类中心和第二个聚类中心的距离。


了解更多java后端架构知识以及最新面试宝典

看完本文记得给作者点赞+在看哦~~~大家的支持,是作者源源不断出文的动力
出处:https://www.cnblogs.com/jojop/p/14018088.html
以上是关于在大数据量时,K-means算法和层次聚类算法谁更有优势的主要内容,如果未能解决你的问题,请参考以下文章